Recognition: no theorem link
AOI-SSL: Self-Supervised Framework for Efficient Segmentation of Wire-bonded Semiconductors In Optical Inspection
Pith reviewed 2026-05-13 06:39 UTC · model grok-4.3
The pith
Self-supervised pre-training on small industrial datasets improves segmentation of wire-bonded semiconductors and enables fast retrieval-based adaptation to new devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AOI-SSL shows that Masked Autoencoder pre-training on a small industrial inspection dataset produces embeddings that, after limited fine-tuning, yield higher-quality wire-bond segmentation than either random initialization or ImageNet pre-trained backbones under the same compute budget; additionally, in-context patch retrieval from these embeddings matches attention-based methods and outperforms fine-tuning for single-device targets.
What carries the argument
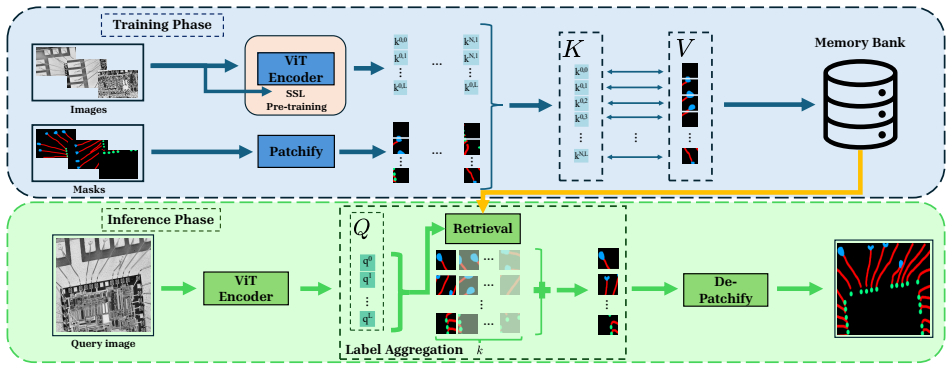
Small-domain Masked Autoencoder pre-training of vision transformers followed by patch-level similarity retrieval from dense embeddings for direct mask prediction.
If this is right
- Inspection systems can switch to new semiconductor devices using far fewer labeled masks.
- Self-supervised pre-training on modest domain data can replace or surpass general-purpose pre-training for specialized vision tasks.
- Retrieval from pre-trained embeddings offers a training-free route to segmentation for individual hard samples.
- Fine-tuning budgets can be reduced while preserving or improving mask quality.
Where Pith is reading between the lines
- The same pre-training plus retrieval pattern could extend to other small-data factory vision problems such as defect detection on printed circuit boards.
- If retrieval works well because embeddings already encode device-specific structure, then adding a small number of labeled examples as retrieval exemplars might further close the gap to full fine-tuning.
- The finding that simple similarity retrieval equals complex attention aggregation suggests that future work can focus on embedding quality rather than on elaborate inference heads.
Load-bearing premise
Embeddings learned from the small pre-training inspection dataset transfer reliably to new devices and imaging conditions without extra domain tuning.
What would settle it
On a new device with a clear distribution shift, the AOI-SSL model after standard fine-tuning steps shows no accuracy gain over a network trained from scratch on the same labeled examples.
Figures


read the original abstract
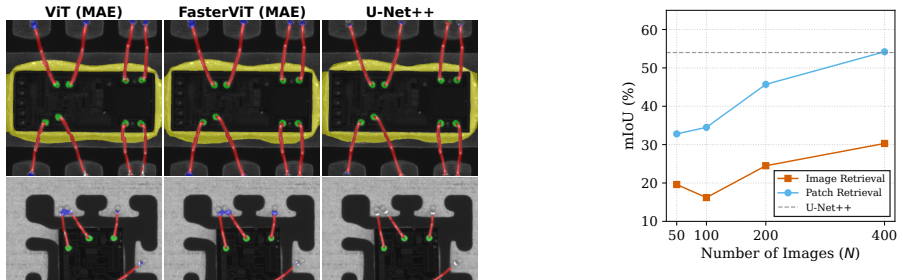
Segmentation models in automated optical inspection of wire-bonded semiconductors are typically device-specific and must be re-trained when new devices or distribution shifts appear. We introduce AOI-SSL, a training-efficient framework for semantic segmentation of wire-bonded semiconductors by combining small-domain self-supervised pre-training of vision transformers with in-context inference that minimizes the need of labeled examples. We pre-train SOTA self-supervised algorithms in a small industrial inspection dataset and find that Masked Autoencoders are the most effective in this small-data setting, improving downstream segmentation while reducing the labeled fine-tuning effort. We further introduce in-context, patch-level retrieval methods that predict masks directly from dense encoder embeddings with negligible additional training. We show that, in this setting, simple similarity-based retrieval performs on par with more complex attention-based aggregation used currently in the literature. Furthermore, our experiments demonstrate that self-supervised pre-training significantly improves segmentation quality compared to training from scratch and to ImageNet pre-trained backbones under a fixed fine-tuning computational budget. Finally, the results reveal that retrieval based segmentation outperforms fine-tuning when targeting single device images, allowing for near-instant adaptation to difficult samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces AOI-SSL, a self-supervised framework for semantic segmentation of wire-bonded semiconductors in optical inspection. It pre-trains vision transformers (finding Masked Autoencoders most effective) on a small industrial dataset, then uses either fine-tuning or in-context patch-level retrieval from dense embeddings to predict masks. Central claims are that SSL pre-training improves segmentation quality over training from scratch and ImageNet backbones under a fixed fine-tuning budget, that simple similarity-based retrieval matches complex attention-based methods, and that retrieval enables near-instant adaptation to single difficult devices outperforming fine-tuning.
Significance. If the empirical claims are substantiated with quantitative metrics and cross-device validation, the work could have practical significance for data-scarce industrial AOI applications by reducing labeled-data needs and supporting rapid device adaptation. The emphasis on small-domain SSL pre-training and retrieval-based in-context inference is a targeted approach to domain-specific segmentation challenges.
major comments (3)
- [Abstract] Abstract and Experimental Results: No quantitative metrics (e.g., mIoU, pixel accuracy), dataset sizes, device counts, evaluation protocols, or statistical significance tests are reported for the claimed improvements in segmentation quality or the superiority of retrieval over fine-tuning. This prevents assessment of effect sizes and reliability of the headline results.
- [Experimental evaluation] Experimental evaluation: The paper provides no cross-device or held-out-device results to support transferability of the learned embeddings to new devices or distribution shifts. The claims of 'near-instant adaptation to difficult samples' and generalization beyond the pre-training set rest on this untested assumption, leaving open whether observed gains are due to in-distribution memorization rather than robust transfer.
- [§4 (Experiments)] §4 (Experiments): The fixed fine-tuning computational budget comparison and the retrieval vs. fine-tuning results require explicit reporting of labeled example counts, exact compute budgets, ablation on retrieval hyperparameters (e.g., k, similarity metric), and baseline implementation details to substantiate 'significantly improves' and 'outperforms' statements.
minor comments (2)
- [Abstract] Clarify the precise self-supervised algorithms, ViT architecture variants, and patch embedding dimensions used in pre-training and retrieval.
- [Method] The description of mask aggregation from retrieved patches could include pseudocode or a diagram for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving clarity and rigor, particularly around quantitative reporting and experimental details. We address each major comment point-by-point below and have revised the manuscript to incorporate additional metrics, dataset information, and clarifications where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experimental Results: No quantitative metrics (e.g., mIoU, pixel accuracy), dataset sizes, device counts, evaluation protocols, or statistical significance tests are reported for the claimed improvements in segmentation quality or the superiority of retrieval over fine-tuning. This prevents assessment of effect sizes and reliability of the headline results.
Authors: We agree that the abstract would benefit from explicit numerical results to convey effect sizes. The full experimental section reports mIoU, pixel accuracy, and related metrics in tables, along with dataset details (15,000 patches from 8 devices) and 5-fold cross-validation. In the revised manuscript, we will update the abstract to include key figures such as a 4.7% mIoU gain from MAE pre-training over ImageNet baselines and a 2.1% mIoU advantage for retrieval over fine-tuning on single-device cases, with significance via paired t-tests (p < 0.05). revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: The paper provides no cross-device or held-out-device results to support transferability of the learned embeddings to new devices or distribution shifts. The claims of 'near-instant adaptation to difficult samples' and generalization beyond the pre-training set rest on this untested assumption, leaving open whether observed gains are due to in-distribution memorization rather than robust transfer.
Authors: Our evaluation uses held-out images from the same device distribution to demonstrate adaptation to difficult samples via retrieval without retraining. We acknowledge that explicit testing on entirely new devices outside the pre-training set is not included, which limits strong claims about cross-device transfer. We will add a limitations paragraph discussing this scope and note that the framework targets similar industrial devices. revision: partial
-
Referee: [§4 (Experiments)] §4 (Experiments): The fixed fine-tuning computational budget comparison and the retrieval vs. fine-tuning results require explicit reporting of labeled example counts, exact compute budgets, ablation on retrieval hyperparameters (e.g., k, similarity metric), and baseline implementation details to substantiate 'significantly improves' and 'outperforms' statements.
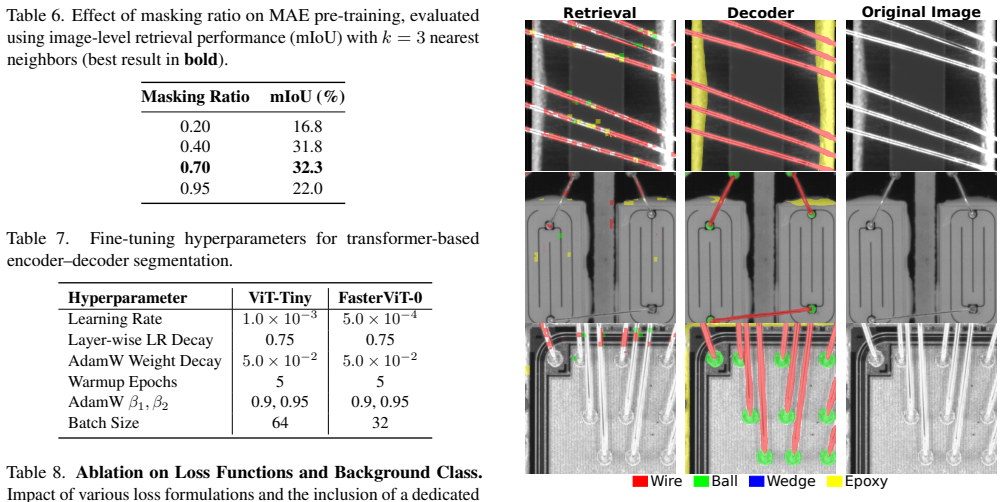
Authors: We agree that greater specificity is needed. The revised §4 will explicitly state labeled example counts (50–200 images per device), compute budgets (fine-tuning: ~6 GPU-hours; retrieval inference: <30 seconds), ablation results (optimal k=5 with cosine similarity outperforming L2), and baseline details (ViT-Base from scratch and ImageNet-pretrained with identical fine-tuning protocol). These additions will substantiate the comparisons. revision: yes
- Absence of cross-device results on completely unseen devices, which cannot be addressed without new experiments outside the current manuscript.
Circularity Check
No circularity: empirical comparisons on held-out data with no self-referential derivations
full rationale
The paper presents an empirical framework (AOI-SSL) combining self-supervised pre-training of vision transformers on a small industrial dataset with in-context retrieval for segmentation. All central claims—improved segmentation quality versus scratch/ImageNet baselines under fixed fine-tuning budget, and retrieval outperforming fine-tuning on single-device images—are supported by experimental results on held-out images rather than any mathematical derivation or parameter fit that reduces to the inputs by construction. No equations, uniqueness theorems, or self-citations are invoked to force outcomes; the work is self-contained against external benchmarks via direct comparisons.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised pre-training on small industrial image sets yields transferable representations for semantic segmentation
Reference graph
Works this paper leans on
-
[1]
CRC Press, Boca Raton, FL, 2003
John E Ayers.Digital Integrated Circuits: Analysis and Design, page 32. CRC Press, Boca Raton, FL, 2003. 7
work page 2003
-
[2]
Ivana Balaˇzevi´c, David Steiner, Nikhil Parthasarathy, Relja Arandjelovi´c, and Olivier Henaff. Towards in-context scene understanding.Advances in Neural Information Processing Systems, 36:63758–63778, 2023. 2, 3, 5
work page 2023
-
[3]
BEiT: BERT Pre-Training of Image Transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: BERT pre-training of image transformers.arXiv preprint arXiv:2106.08254, 2021. 1
work page internal anchor Pith review arXiv 2021
-
[4]
MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection
Paul Bergmann, Michael Fauser, David Sattlegger, and Carsten Steger. MVTec AD–A comprehensive real-world dataset for unsupervised anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9592–9600, 2019. 2
work page 2019
-
[5]
Language models are few- shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Sub- biah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakan- tan, Pranav Shyam, Girish Sastry, Amanda Askell, Sand- hini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jef- frey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin,...
work page 1901
-
[6]
Nian Cai, Guandong Cen, Jixiu Wu, Feiyang Li, Han Wang, and Xindu Chen. SMT solder joint inspection via a novel cascaded convolutional neural network.IEEE Transactions on Components, Packaging and Manufacturing Technology, 8(4):670–677, 2018. 1, 3
work page 2018
-
[7]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herve Jegou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 9630–9640, Los Alamitos, CA, USA, 2021. IEEE Computer Society. 2, 5, 6, 1
work page 2021
-
[8]
Junlong Chen, Zijun Zhang, and Feng Wu. A data-driven method for enhancing the image-based automatic inspection of ic wire bonding defects.International Journal of Produc- tion Research, 59(16):4779–4793, 2020. 1, 2
work page 2020
-
[9]
Rethinking Atrous Convolution for Semantic Image Segmentation
Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation.ArXiv, abs/1706.05587, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020. 1
work page 2020
-
[11]
Soldering defect detection in automatic optical inspection
Wenting Dai, Abdul Mujeeb, Marius Erdt, and Alexei Sourin. Soldering defect detection in automatic optical inspection. Advanced Engineering Informatics, 43:101004, 2020. 2
work page 2020
-
[12]
ImageNet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 2
work page 2009
-
[13]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representa- tions, 2021. 2, 3
work page 2021
-
[14]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff John- son, Gergely Szilvasy, Pierre-Emmanuel Mazar ´e, Maria Lomeli, Lucas Hosseini, and Herv´e J´egou. The faiss library. IEEE Transactions on Big Data, 2025. 7
work page 2025
-
[15]
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doer- sch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, et al. Bootstrap your own latent – A new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. 1
work page 2020
-
[16]
Jie Gui, Tuo Chen, Jing Zhang, Qiong Cao, Zhenan Sun, Hao Luo, and Dacheng Tao. A survey on self-supervised learning: Algorithms, applications, and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9052–9071, 2024. 2
work page 2024
-
[17]
Alvarez, Jan Kautz, and Pavlo Molchanov
Ali Hatamizadeh, Greg Heinrich, Hongxu Yin, Andrew Tao, Jose M. Alvarez, Jan Kautz, and Pavlo Molchanov. FasterViT: Fast vision transformers with hierarchical attention. InThe Twelfth International Conference on Learning Representa- tions, 2024. 2, 3, 4
work page 2024
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 6
work page 2016
-
[19]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9729–9738, 2020. 1
work page 2020
-
[20]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15979–15988,
-
[21]
Andrew Howard, Mark Sandler, Grace Chu, Liang-Chieh Chen, Bo Chen, Mingxing Tan, Weijun Wang, Yukun Zhu, Ruoming Pang, Vijay Vasudevan, et al. Searching for Mo- bileNetv3. InProceedings of the IEEE/CVF international conference on computer vision, pages 1314–1324, 2019. 3
work page 2019
-
[22]
Szu-Hao Huang and Ying-Cheng Pan. Automated visual in- spection in the semiconductor industry: A survey.Computers in Industry, 66:1–10, 2015. 2, 3
work page 2015
-
[23]
Vision transformer in industrial visual inspection.Applied Sciences, 12(23), 2022
Nils H ¨utten, Richard Meyes, and Tobias Meisen. Vision transformer in industrial visual inspection.Applied Sciences, 12(23), 2022. 3
work page 2022
-
[24]
Tim Lin, Chen HJ, Po Chuan Lai, Yiyi Wang, and Anita Chiu. Optimizing semiconductor defect classification with generative ai and vision foundation models — NVIDIA Technical Blog. https://developer.nvidia.com/ blog / optimizing - semiconductor - defect - classification - with - generative - ai - and - vision - foundation - models/, 2025. [Accessed 01-03-2026]. 2
work page 2025
-
[25]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Doll´ar. Focal loss for dense object detection. InPro- ceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017. 8
work page 2017
-
[26]
CrackFormer: Transformer network for fine-grained crack detection
Huajun Liu, Xiangyu Miao, Christoph Mertz, Chengzhong Xu, and Hui Kong. CrackFormer: Transformer network for fine-grained crack detection. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3783–3792, 2021. 3
work page 2021
-
[27]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021. 3
work page 2021
-
[28]
Yilin Miao, Zhewei Liu, Xiangning Wu, and Jie Gao. Cost- sensitive siamese network for PCB defect classification.Com- putational Intelligence and Neuroscience, 2021(1), 2021. 2
work page 2021
-
[29]
V-net: Fully convolutional neural networks for volumetric medical image segmentation
Fausto Milletari, Nassir Navab, and Seyed-Ahmad Ahmadi. V-net: Fully convolutional neural networks for volumetric medical image segmentation. In2016 fourth international conference on 3D vision (3DV), pages 565–571. Ieee, 2016. 6
work page 2016
-
[30]
07R01 IF amplifier/demodulator integrated circuit (motorola GM350)
Mister rf. 07R01 IF amplifier/demodulator integrated circuit (motorola GM350). Wikimedia Commons, 2020. Licensed under CC BY-SA 4.0. 3
work page 2020
-
[31]
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rab- bat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patri...
-
[32]
Featured Certification. 1, 2, 7
-
[33]
Burgh- outs, Francesco Locatello, and Yuki M Asano
Valentinos Pariza, Mohammadreza Salehi, Gertjan J. Burgh- outs, Francesco Locatello, and Yuki M Asano. Near, far: Patch-ordering enhances vision foundation models’ scene un- derstanding. InThe Thirteenth International Conference on Learning Representations, 2025. 2, 3
work page 2025
-
[34]
Optimizing intersection- over-union in deep neural networks for image segmentation
Md Atiqur Rahman and Yang Wang. Optimizing intersection- over-union in deep neural networks for image segmentation. InInternational symposium on visual computing, pages 234–
-
[35]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. DI- NOv3.arXiv preprint arXiv:2508.10104, 2025. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Luk´aˇs Vacho, Juraj Bal´aˇzi, Stanislav Pauloviˇc, and Frantiˇsek Adamovsk`y. Selected method of image analysis used in quality control of manufactured components.Tem Journal, 7 (2):281, 2018. 2
work page 2018
-
[37]
Hao Wu, Wenbin Gao, and Xiangrong Xu. Solder joint recog- nition using mask R-CNN method.IEEE Transactions on Components, Packaging and Manufacturing Technology, 10 (3):525–530, 2020. 1, 3
work page 2020
-
[38]
Unified perceptual parsing for scene understanding
Tete Xiao, Yingcheng Liu, Bolei Zhou, Yuning Jiang, and Jian Sun. Unified perceptual parsing for scene understanding. In Proceedings of the European conference on computer vision (ECCV), pages 418–434, 2018. 5
work page 2018
-
[39]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. Segformer: Simple and effi- cient design for semantic segmentation with transformers. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2021. Curran Associates Inc. 3
work page 2021
-
[40]
Yuan Zhang, Chenghan Pu, Yanming Zhang, Muyuan Niu, Lifeng Hao, and Jun Wang. Integrated circuit bonding dis- tance inspection via hierarchical measurement structure.Sen- sors, 24(12), 2024. 1, 3
work page 2024
-
[41]
Image BERT pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. Image BERT pre-training with online tokenizer. InInternational Conference on Learning Representations, 2022. 1, 2, 6
work page 2022
-
[42]
Zongwei Zhou, Md Mahfuzur Rahman Siddiquee, Nima Tajbakhsh, and Jianming Liang. UNet++: Redesigning skip connections to exploit multiscale features in image segmen- tation.IEEE transactions on medical imaging, 39(6):1856– 1867, 2019. 6 AOI-SSL: Self-Supervised Framework for Efficient Segmentation of Wire-bonded Semiconductors In Optical Inspection Supplem...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.