Recognition: no theorem link
GaitProtector: Impersonation-Driven Gait De-Identification via Training-Free Diffusion Latent Optimization
Pith reviewed 2026-05-13 06:34 UTC · model grok-4.3
The pith
Impersonation in diffusion latent space de-identifies gait, dropping recognition accuracy to 15% with limited utility loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
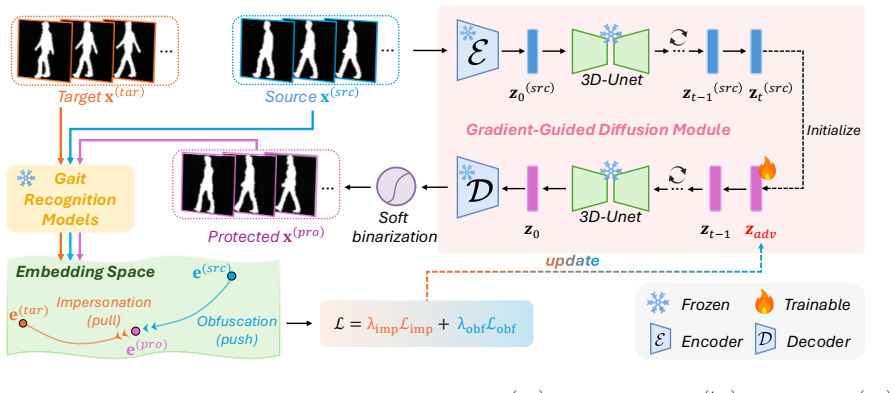
GaitProtector treats de-identification as simultaneous repulsion from the source identity and attraction to a target identity by optimizing the latent codes of a pretrained 3D video diffusion model after inverting the input silhouette sequence, yielding protected gaits that confuse recognizers yet retain motion quality for applications such as scoliosis assessment.
What carries the argument
Training-free optimization of diffusion latent trajectories guided by an adversarial objective that combines source obfuscation and target impersonation under the model's structural prior.
If this is right
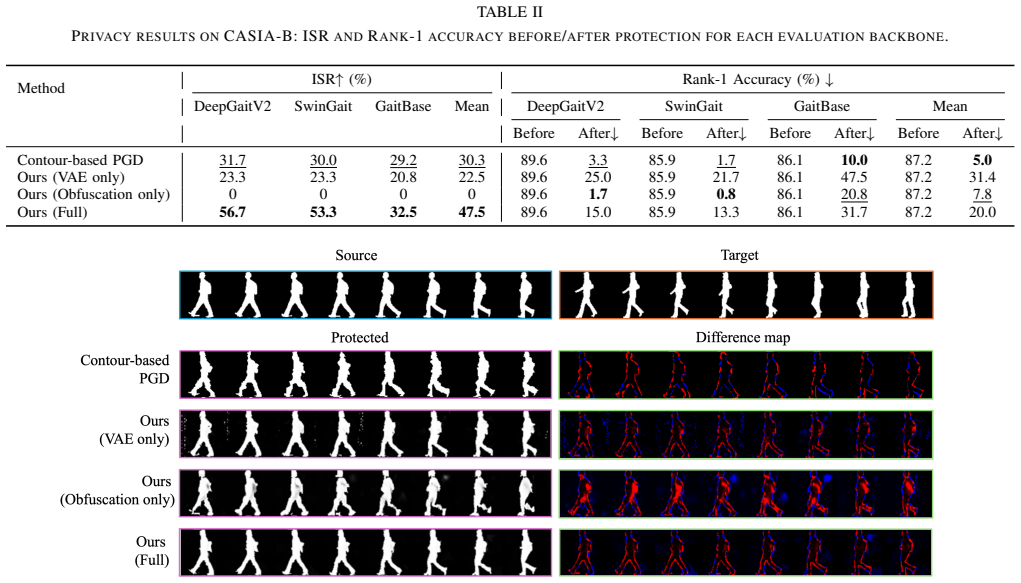
- Impersonation succeeds against black-box recognizers 56.7 percent of the time.
- Rank-1 accuracy on CASIA-B falls from 89.6 percent to 15.0 percent.
- Protected sequences keep good visual and temporal quality.
- Scoliosis diagnostic accuracy holds at 74.2 percent down from 91.4 percent.
- No per-dataset generator retraining is required.
Where Pith is reading between the lines
- The approach may apply to de-identifying other video biometrics using similar pretrained priors.
- Choosing different target identities could allow tunable privacy strength.
- Real-world deployment in cameras could enable privacy-preserving analytics without retraining models.
Load-bearing premise
The pretrained 3D diffusion model gives a prior that keeps optimized gaits structurally close to real human motion in body shape and dynamics.
What would settle it
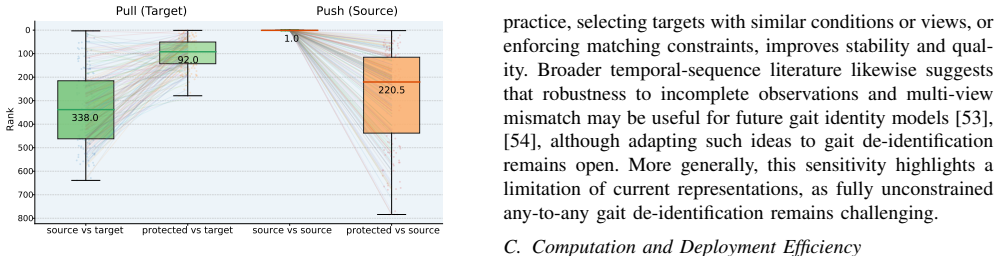
Running the optimization on CASIA-B and finding that Rank-1 accuracy stays above 40 percent or that scoliosis diagnostic accuracy falls below 60 percent would show the method does not deliver the claimed balance.
Figures

read the original abstract
Conventional gait de-identification methods often encounter an inherent trade-off: they either provide insufficient identity suppression or introduce spatiotemporal distortions that impede structure-sensitive downstream applications. We propose GaitProtector, an impersonation-driven gait de-identification framework that formulates privacy protection as a unified objective with two tightly coupled components: (i) obfuscation, which repels the protected gait from the source identity, and (ii) impersonation, which attracts it toward a selected target identity. The target identity serves as a semantic anchor that biases optimization toward structurally plausible gait patterns under the pretrained diffusion prior, helping preserve dominant body shape and motion dynamics. We instantiate this idea through a training-free diffusion latent optimization pipeline. Instead of retraining a generator for each dataset, we invert each input silhouette sequence into the latent trajectory of a pretrained 3D video diffusion model and iteratively optimize latent codes with a differentiable adversarial objective to synthesize protected gaits. Experiments on the CASIA-B dataset show that GaitProtector achieves a 56.7% impersonation success rate under black-box gait recognition and reduces Rank-1 identification accuracy from 89.6% to 15.0%, while maintaining favorable visual and temporal quality. We further evaluate downstream utility on the Scoliosis1K dataset, where diagnostic accuracy decreases only from 91.4% to 74.2%. To the best of our knowledge, this work is the first to leverage pretrained 3D diffusion priors in a training-free manner for silhouette-based gait de-identification.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
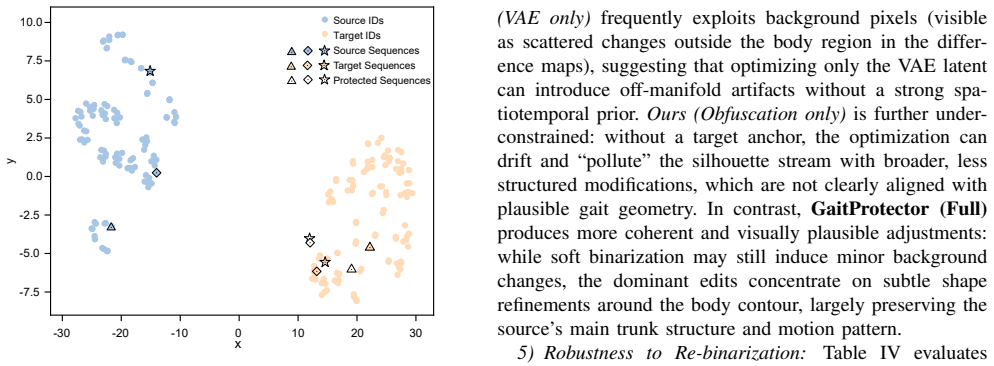
No significant circularity; empirical results on external benchmarks
full rationale
The paper describes a training-free diffusion latent optimization pipeline for gait de-identification but provides no equations, derivations, or fitted parameters whose outputs are then relabeled as predictions. Reported metrics (56.7% impersonation success, Rank-1 drop from 89.6% to 15.0%, diagnostic retention at 74.2%) are presented strictly as experimental outcomes on the independent CASIA-B and Scoliosis1K datasets. No self-citation chain, ansatz smuggling, or self-definitional reduction appears in the supplied text; the method's plausibility claim rests on the external pretrained model's behavior rather than any internal redefinition of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained 3D video diffusion model encodes a prior over structurally plausible gait patterns
Reference graph
Works this paper leans on
-
[1]
O. Bar-Tal, H. Chefer, O. Tov, C. Herrmann, R. Paiss, S. Zada, A. Ephrat, J. Hur, G. Liu, A. Raj, et al. Lumiere: A space-time diffusion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[2]
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis. Align your latents: High-resolution video syn- thesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563– 22575, 2023
work page 2023
-
[3]
W. Chai, X. Guo, G. Wang, and Y . Lu. Stablevideo: Text-driven consistency-aware diffusion video editing. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 23040–23050, 2023
work page 2023
- [4]
-
[5]
J. Dong, R. Z. Moayedi, Y .-S. Ong, and S.-M. Moosavi-Dezfooli. Allies teach better than enemies: Inverse adversaries for robust knowl- edge distillation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
work page 2026
-
[6]
J. Dong, C. Zhang, X. Qu, Z. Ma, P. Koniusz, and Y .-S. Ong. Robust superalignment: Weak-to-strong robustness generalization for vision- language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[7]
Y . Dong, F. Liao, T. Pang, H. Su, J. Zhu, X. Hu, and J. Li. Boosting adversarial attacks with momentum. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 9185– 9193, 2018
work page 2018
-
[8]
C. Fan, S. Hou, J. Liang, C. Shen, J. Ma, D. Jin, Y . Huang, and S. Yu. Opengait: A comprehensive benchmark study for gait recognition towards better practicality.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[9]
C. Fan, J. Liang, C. Shen, S. Hou, Y . Huang, and S. Yu. Opengait: Re- visiting gait recognition towards better practicality. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9707–9716, 2023
work page 2023
- [10]
- [11]
-
[12]
Y . Fu, S. Meng, S. Hou, X. Hu, and Y . Huang. Gpgait: Generalized pose-based gait recognition. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 19595–19604, 2023
work page 2023
-
[13]
LTX-Video: Realtime Video Latent Diffusion
Y . HaCohen, N. Chiprut, B. Brazowski, D. Shalem, D. Moshe, E. Richardson, E. Levin, G. Shiran, N. Zabari, O. Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Z. He, W. Wang, J. Dong, and T. Tan. Temporal sparse adversarial attack on sequence-based gait recognition.Pattern Recognition, 133:109028, 2023
work page 2023
- [17]
- [18]
- [19]
- [20]
-
[21]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
work page 2022
-
[22]
H. Hukkel ˚as and F. Lindseth. Deepprivacy2: Towards realistic full- body anonymization. InProceedings of the IEEE/CVF winter confer- ence on applications of computer vision, pages 1329–1338, 2023
work page 2023
-
[23]
H. Hukkel ˚as, M. Smebye, R. Mester, and F. Lindseth. Realistic full- body anonymization with surface-guided gans. InProceedings of the IEEE/CVF Winter conference on Applications of Computer Vision, pages 1430–1440, 2023
work page 2023
-
[24]
M. Jia, H. Yang, D. Huang, and Y . Wang. Attacking gait recognition systems via silhouette guided gans. InProceedings of the 27th ACM international conference on multimedia, pages 638–646, 2019
work page 2019
-
[25]
J. Li, J. Dong, J. Lai, and X. Xie. Imperceptible diffusion modification for facial privacy protection.Neurocomputing, 649:130614, 2025
work page 2025
-
[26]
J. Li, K. Xu, X. Jiang, and T. Sun. Sparse silhouette jump: Adversarial attack targeted at binary image for gait privacy protection. In2024 IEEE 23rd International Conference on Trust, Security and Privacy in Computing and Communications (TrustCom), pages 1336–1342. IEEE, 2024
work page 2024
-
[27]
J. Li, Y . Zhang, Y . Zeng, C. Ye, W. Xu, X. Ben, F.-Y . Wang, and J. Zhang. Rethinking appearance-based deep gait recognition: Reviews, analysis, and insights from gait recognition evolution.IEEE Transactions on Neural Networks and Learning Systems, 2025
work page 2025
- [28]
- [29]
-
[30]
Y . Li, S. Meng, C. Yang, W. Feng, J. Liu, Z. An, Y . Wang, and Y . Tian. A comprehensive survey of interaction techniques in 3d scene generation.Authorea Preprints, 2026
work page 2026
-
[31]
B. Lin, S. Zhang, and X. Yu. Gait recognition via effective global-local feature representation and local temporal aggregation. InProceedings of the IEEE/CVF international conference on computer vision, pages 14648–14656, 2021
work page 2021
-
[32]
J. Liu, W. Liu, J. T. W. En, C. Chen, P. S. Tan, and Y .-S. Ong. Op- timal transport-based distributional pairing in transfer multiobjective optimization.IEEE Transactions on Evolutionary Computation, 2025
work page 2025
-
[33]
Z. Luo, D. Chen, Y . Zhang, Y . Huang, L. Wang, Y . Shen, D. Zhao, J. Zhou, and T. Tan. Videofusion: Decomposed diffusion models for high-quality video generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2023
work page 2023
-
[34]
J. Ma, H. Luo, Z. Huang, D. Jin, R. Wang, J. A. Briffa, N. Poh, and S. Yu. Passersby-anonymizer: Safeguard the privacy of passersby in social videos. In2024 IEEE International Joint Conference on Biometrics (IJCB), pages 1–10. IEEE, 2024
work page 2024
- [35]
-
[36]
L. v. d. Maaten and G. Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(Nov):2579–2605, 2008
work page 2008
-
[37]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
C. Meng, Y . He, Y . Song, J. Song, J. Wu, J.-Y . Zhu, and S. Er- mon. SDEdit: Guided image synthesis and editing with stochastic differential equations. InInternational Conference on Learning Representations, 2022
work page 2022
- [39]
-
[40]
S. Moon, M. Kim, Z. Qin, Y . Liu, and D. Kim. Anonymization for skeleton action recognition. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 15028–15036, 2023
work page 2023
-
[41]
A. Sepas-Moghaddam and A. Etemad. Deep gait recognition: A sur- vey.IEEE transactions on pattern analysis and machine intelligence, 45(1):264–284, 2022
work page 2022
-
[42]
C. Shen, S. Yu, J. Wang, G. Q. Huang, and L. Wang. A comprehensive survey on deep gait recognition: Algorithms, datasets, and challenges. IEEE Transactions on Biometrics, Behavior, and Identity Science, 2024
work page 2024
-
[43]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations, 2021
work page 2021
- [44]
-
[45]
N.-D. T. Tieu, H. H. Nguyen, H.-Q. Nguyen-Son, J. Yamagishi, and I. Echizen. An approach for gait anonymization using deep learning. In2017 IEEE workshop on information forensics and security (WIFS), pages 1–6. IEEE, 2017
work page 2017
-
[46]
N.-D. T. Tieu, H. H. Nguyen, H.-Q. Nguyen-Son, J. Yamagishi, and I. Echizen. Spatio-temporal generative adversarial network for gait anonymization.Journal of Information Security and Applications, 46:307–319, 2019
work page 2019
-
[47]
Towards Accurate Generative Models of Video: A New Metric & Challenges
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michal- ski, and S. Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[48]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[49]
P. Yang, H. Jing, N. Zheng, and Y . Ma. Instrucrobo: Object-centric multi-instruction decoupling model for explainable robotic manipula- tion.Engineering Applications of Artificial Intelligence, 2026
work page 2026
-
[50]
P. Yang, H. Jing, N. Zheng, and Y . Ma. Unihoi: Unified human-object interaction understanding via unified token space. InAAAI, 2026
work page 2026
- [51]
-
[52]
D. Ye, C. Fan, J. Ma, X. Liu, and S. Yu. Biggait: Learning gait representation you want by large vision models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 200–210, 2024
work page 2024
-
[53]
C. Yu, F. Wang, Z. Shao, T. Qian, Z. Zhang, W. Wei, Z. An, Q. Wang, and Y . Xu. Ginar+: A robust end-to-end framework for multivariate time series forecasting with missing values.IEEE Transactions on Knowledge and Data Engineering, 2025
work page 2025
-
[54]
C. Yu, F. Wang, C. Yang, Z. Shao, T. Sun, T. Qian, W. Wei, Z. An, and Y . Xu. Merlin: Multi-view representation learning for robust multivariate time series forecasting with unfixed missing rates. In ACM SIGKDD, 2025
work page 2025
-
[55]
S. Yu, D. Tan, and T. Tan. A framework for evaluating the effect of view angle, clothing and carrying condition on gait recognition. In18th international conference on pattern recognition (ICPR’06), volume 4, pages 441–444. IEEE, 2006
work page 2006
- [56]
- [57]
- [58]
-
[59]
Z. Zhou, J. Liang, Z. Peng, C. Fan, F. An, and S. Yu. Gait patterns as biomarkers: A video-based approach for classifying scoliosis. In International conference on medical image computing and computer- assisted intervention, pages 284–294. Springer, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.