Recognition: 2 theorem links
· Lean TheoremStochastic block coordinate and function alternation for multi-objective optimization and learning
Pith reviewed 2026-05-13 03:18 UTC · model grok-4.3
The pith
Alternating between objectives and variable blocks cuts per-iteration cost in multi-objective stochastic optimization while matching single-objective convergence rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes a stochastic block-coordinate and function-alternation framework for multi-objective problems. In each iteration the method selects one objective and one variable block, then takes a stochastic gradient step on that block alone. Prescribing the number of steps allocated to each objective controls exploration along the Pareto front. Under standard stochastic smoothness assumptions the framework recovers the classical convergence rates of single-objective stochastic gradient methods in convex, non-convex, and Polyak-Lojasiewicz settings.
What carries the argument
The stochastic block-coordinate and function alternation mechanism, which cycles through objectives while restricting each stochastic gradient update to a single variable block.
If this is right
- Per-iteration arithmetic cost scales only with the size of one variable block and one objective rather than all blocks and all objectives.
- Users can directly allocate more gradient steps to objectives they wish to emphasize or to improve coverage of the Pareto front.
- The same O(1/sqrt(T)) non-convex and O(1/T) convex rates hold as in ordinary stochastic gradient descent.
- The scheme applies immediately to large-scale machine-learning models whose loss is a sum of several task-specific terms.
Where Pith is reading between the lines
- The alternation pattern may combine naturally with variance-reduction or momentum techniques to obtain faster rates in non-convex regimes.
- In distributed or federated learning the variable blocks could correspond to data shards or model partitions without changing the convergence argument.
- Sequential focus on individual objectives could produce more diverse Pareto approximations than simultaneous weighted-gradient methods.
Load-bearing premise
Alternating the active objective and restricting updates to one variable block does not destroy the descent or smoothness properties that single-objective stochastic gradient proofs rely on.
What would settle it
A controlled quadratic multi-objective test problem where the alternation method, run with the same total gradient evaluations, fails to match the convergence rate of the corresponding non-alternating multi-gradient method.
Figures
read the original abstract
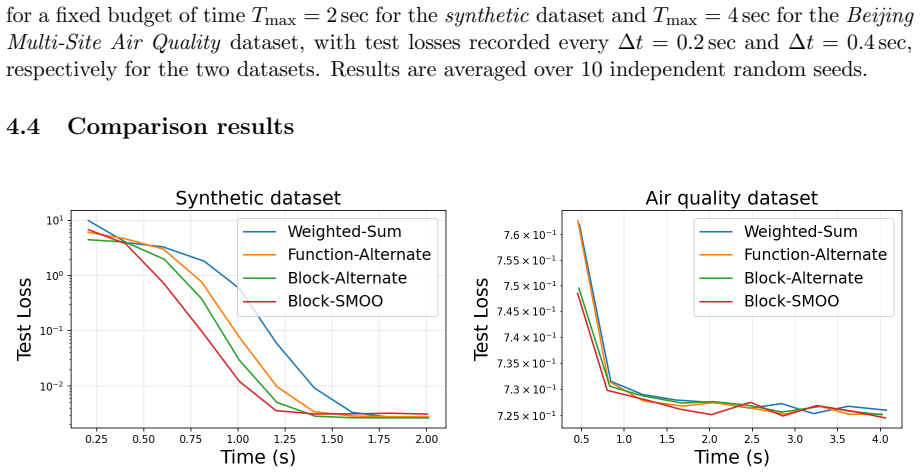
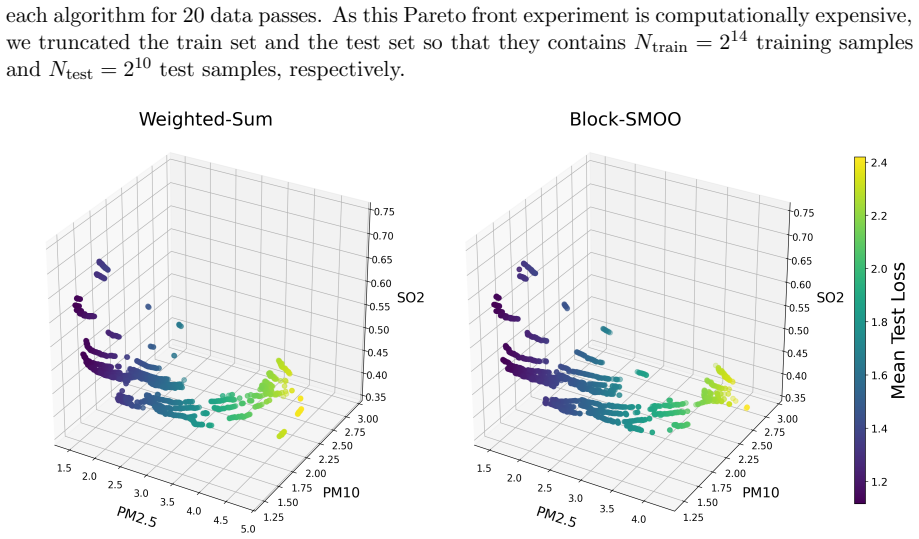
Multi-objective optimization is central to many engineering and machine learning applications, where multiple objectives must be optimized in balance. While multi-gradient based optimization methods combine these objectives in each step, such methods require computing gradients with respect to all variables at every iteration, resulting in high computational costs in large-scale settings. In this work, we propose a framework that simultaneously alternates the optimization of each objective and the (stochastic) gradient update with respect to each variable block. Our framework reduces per-iteration computational cost while enabling exploration of the Pareto front by allocating a prescribed number of gradient steps to each objective. We establish rigorous convergence guarantees across several stochastic smooth settings, including convex, non-convex, and Polyak-Lojasiewicz conditions, recovering classical convergence rates of single-objective methods. Numerical experiments demonstrate that our framework outperforms non-alternating methods on multi-target regression and produces a competitive Pareto front approximation, highlighting its computational efficiency and practical effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a stochastic block-coordinate and function-alternation framework for multi-objective optimization. It alternates gradient steps across objectives and variable blocks to reduce per-iteration cost relative to full multi-gradient methods while allowing controlled exploration of the Pareto front via a prescribed allocation of steps per objective. The central claims are rigorous convergence guarantees in stochastic smooth convex, non-convex, and Polyak-Łojasiewicz regimes that recover the classical rates of single-objective SGD, together with numerical evidence on multi-target regression showing improved efficiency and competitive Pareto approximation.
Significance. If the convergence analysis is valid without hidden interaction assumptions, the work would provide a practical, lower-cost alternative to existing multi-objective gradient methods for large-scale ML tasks. Recovering single-objective rates under alternation is a strong potential contribution, as is the explicit mechanism for Pareto exploration; however, the significance hinges on whether the alternation preserves descent properties without additional coordination or dissimilarity bounds.
major comments (2)
- [Abstract and §3] Abstract and §3 (Convergence Analysis): the claim that classical single-objective SGD rates are recovered in the non-convex and PL regimes requires that the composite alternation sequence remains a valid stochastic descent direction. The analysis must therefore establish either a shared step-size rule across objectives, a bound on gradient dissimilarity between objectives, or a Lyapunov function that absorbs cross terms; none of these are indicated in the abstract and their absence would make the effective per-objective step size inconsistent when objectives conflict or have differing Lipschitz constants, undermining rate recovery.
- [§4] §4 (PL setting): the Polyak-Łojasiewicz inequality is stated for individual objectives, yet the alternation produces a composite update sequence. The proof must derive that this sequence satisfies a PL inequality (or an equivalent descent lemma) with a constant independent of the alternation schedule; without an explicit handling of the cross-objective terms introduced by alternation, the claimed linear rate cannot be guaranteed.
minor comments (2)
- [§2] Notation for the alternation schedule (how many steps are allocated to each objective and how blocks are chosen) should be introduced earlier and used consistently in the convergence statements.
- [Experiments] Experiments section: the Pareto-front comparison would benefit from reporting the number of function evaluations rather than iterations alone, to make the computational-cost claim quantitative.
Simulated Author's Rebuttal
We are grateful to the referee for the detailed feedback on our manuscript. The comments highlight important aspects of the convergence analysis that we have addressed by providing additional clarifications and minor revisions to the relevant sections.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Convergence Analysis): the claim that classical single-objective SGD rates are recovered in the non-convex and PL regimes requires that the composite alternation sequence remains a valid stochastic descent direction. The analysis must therefore establish either a shared step-size rule across objectives, a bound on gradient dissimilarity between objectives, or a Lyapunov function that absorbs cross terms; none of these are indicated in the abstract and their absence would make the effective per-objective step size inconsistent when objectives conflict or have differing Lipschitz constants, undermining rate recovery.
Authors: Thank you for this insightful comment. In the full analysis presented in Section 3, we do employ a shared step-size rule determined by the global Lipschitz constant (the maximum over all objectives), which ensures consistency across the alternation. The proof constructs a suitable Lyapunov function that accounts for the cross terms arising from objective alternation by leveraging the smoothness of each objective and the controlled alternation schedule. This allows us to recover the classical rates without additional dissimilarity assumptions. We have revised the abstract to explicitly mention the use of a unified step-size and added a clarifying remark in §3 regarding the handling of cross-objective interactions. revision: yes
-
Referee: [§4] §4 (PL setting): the Polyak-Łojasiewicz inequality is stated for individual objectives, yet the alternation produces a composite update sequence. The proof must derive that this sequence satisfies a PL inequality (or an equivalent descent lemma) with a constant independent of the alternation schedule; without an explicit handling of the cross-objective terms introduced by alternation, the claimed linear rate cannot be guaranteed.
Authors: We agree that this point requires explicit treatment. In the proof of Theorem 4.1 in §4, we derive a composite descent lemma by combining the individual PL inequalities with bounds on the update differences due to alternation. Specifically, we show that the sequence satisfies a PL-like inequality with a constant that scales with the number of objectives and the alternation frequency but remains independent of the particular ordering within the schedule. The cross terms are controlled using the step-size restriction and the PL parameter. To make this more transparent, we have inserted an intermediate lemma (Lemma 4.2) that explicitly handles these terms and have updated the proof accordingly. revision: yes
Circularity Check
No circularity detected; analysis extends standard SGD theory
full rationale
The abstract and reader's summary indicate that convergence guarantees are derived by recovering classical single-objective stochastic gradient rates under convex, non-convex, and PL conditions. This is presented as an extension of existing stochastic optimization theory rather than a self-referential construction. No self-definitional steps, fitted inputs renamed as predictions, load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the provided text. The central claim of rate recovery is grounded in standard assumptions on smoothness and stochastic gradients, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Objective functions are smooth and stochastic gradients are unbiased estimators with bounded variance.
- ad hoc to paper The alternation schedule and step-size rules can be chosen to satisfy the conditions of classical single-objective analyses.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearOur framework reduces per-iteration computational cost while enabling exploration of the Pareto front by allocating a prescribed number of gradient steps to each objective. We establish rigorous convergence guarantees... recovering classical convergence rates of single-objective methods.
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclearTheorem 3.1... E[||∇Fm(x̄)||²] ≤ 2/sqrt(T) (E[Fm(x0)-F*] + ...)
Reference graph
Works this paper leans on
-
[1]
S. Bandyopadhya, S. K. Pal, and B. Aruna. Multiobjective GAs, quantitative indices, and pattern classification.IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 34:2088–2099, 2004
work page 2088
-
[2]
S. Bechikh, R. Datta, and A. Gupta, editors.Recent Advances in Evolutionary Multi- Objective Optimization, volume 20. Springer, New York, 2016
work page 2016
-
[3]
A. Beck and L. Tetruashvili. On the convergence of block coordinate descent type methods. SIAM J. Optim., 23:2037–2060, 2013
work page 2037
-
[4]
D. P. Bertsekas. Nonlinear programming.J. Oper. Res. Soc., 48:334–334, 1997
work page 1997
- [5]
-
[6]
E. K. Browning and M. A. Zupan.Microeconomics: Theory and Applications. Wiley, Hoboken, 2020
work page 2020
-
[7]
X. Cai, C. Song, S. Wright, and J. Diakonikolas. Cyclic block coordinate descent with variance reduction for composite nonconvex optimization.International Conference on Machine Learning, 202:3469–3494, 2023. 19
work page 2023
-
[8]
L. Chen, H. Fernando, Y. Ying, and T. Chen. Three-Way Trade-Off in Multi-Objective Learning: Optimization, Generalization and Conflict-Avoidance.Advances in Neural In- formation Processing Systems, 36:70045–70093, 2023
work page 2023
- [9]
-
[10]
C. C. Coello. Evolutionary multi-objective optimization: A historical view of the field. IEEE Computational Intelligence Magazine, 1:28–36, 2006
work page 2006
-
[11]
K. H. Cuevas.Cyclic stochastic optimization: Generalizations, convergence, and applica- tions in multi-agent systems. PhD thesis, The Johns Hopkins University, 2017
work page 2017
-
[12]
A. L. Cust´ odio, J. A. Madeira, A. I. F. Vaz, and L. N. Vicente. Direct multisearch for multiobjective optimization.SIAM J. Optim., 21:1109–1140, 2011
work page 2011
-
[13]
S. De, A. Yadav, D. Jacobs, and T. Goldstein. Automated Inference with Adaptive Batches. International Conference on Artificial Intelligence and Statistics, 54:1504–1513, 2017
work page 2017
-
[14]
K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan. A fast and elitist multiobjective genetic algorithm: NSGA-II.IEEE Transactions on Evolutionary Computation, 6:182–197, 2002
work page 2002
-
[15]
J. A. D´ esid´ eri. Multiple-gradient descent algorithm (MGDA) for multiobjective optimiza- tion.C. R. Math. Acad. Sci. Paris, 350:313–318, 2012
work page 2012
- [16]
-
[17]
Ehrgott.Multicriteria Optimization, volume 491
M. Ehrgott.Multicriteria Optimization, volume 491. Springer Science & Business Media, Berlin, 2005
work page 2005
-
[18]
H. Fernando, H. Shen, M. Liu, S. Chaudhury, K. Murugesan, and T. Chen. Mitigating gradient bias in multi-objective learning: A provably convergent approach.International Conference on Learning Representation, 2023
work page 2023
-
[19]
H. Fernando, L. Chen, S. Lu, P. Chen, M. Liu, S. Chaudhury, K. Murugesan, G. Liu, M. Wang, and T. Chen. Variance reduction can improve trade-off in multi-objective learn- ing.IEEE International Conference on Acoustics, Speech and Signal Processing, pages 6975–6979, 2024
work page 2024
-
[20]
E. H. Fukuda and L. M. G. Drummond. A survey on multiobjective descent methods. Pesquisa Operacional, 34:585–620, 2014
work page 2014
-
[21]
S. Gass and T. Saaty. The computational algorithm for the parametric objective function. Nav. Res. Logist. Q., 2:39–45, 1955
work page 1955
-
[22]
S. Ghadimi and G. Lan. Stochastic first-and zeroth-order methods for nonconvex stochastic programming.SIAM J. Optim., 23:2341–2368, 2013. 20
work page 2013
- [23]
-
[24]
L. Grippo and M. Sciandrone. On the convergence of the block nonlinear Gauss–Seidel method under convex constraints.Oper. Res. Lett., 26:127–136, 2000
work page 2000
- [25]
-
[26]
Y. V. Haimes. On a bicriterion formulation of the problems of integrated system identifi- cation and system optimization.IEEE Transactions on Systems, Man, and Cybernetics, 1: 296–297, 1971
work page 1971
-
[27]
A. J. Izenman. Reduced-rank regression for the multivariate linear model.J. Multivariate Anal., 5:248–264, 1975
work page 1975
-
[28]
T. Jiang and L. Xiao. Stochastic approximation with block coordinate optimal stepsizes. arXiv preprint arXiv:2507.08963, 2025
-
[29]
R. A. Johnson and D. W. Wichern.Applied Multivariate Statistical Analysis. Pearson Prentice Hall, Saddle River, 2002
work page 2002
- [30]
- [31]
-
[32]
J. Liu, S. Wright, C. Re, V. Bittorf, and S. Sridhar. An asynchronous parallel stochastic coordinate descent algorithm.International Conference on Machine Learning, 32:469–477, 2014
work page 2014
- [33]
- [34]
- [35]
-
[36]
R. T. Marler and J. S. Arora. Survey of multi-objective optimization methods for engineer- ing.Struct. Multidiscip. Optim., 26:369–395, 2004
work page 2004
-
[37]
Miettinen.Nonlinear Multiobjective Optimization, volume 12
K. Miettinen.Nonlinear Multiobjective Optimization, volume 12. Springer Science & Busi- ness Media, New York, 2012
work page 2012
-
[38]
A. Nemirovski, A. Juditsky, G. Lan, and A. Shapiro. Robust stochastic approximation approach to stochastic programming.SIAM J. Optim., 19:1574–1609, 2009. 21
work page 2009
- [39]
-
[40]
B. T. Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 4:1–17, 1964
work page 1964
-
[41]
M. Quentin, P. Fabrice, and J. A. D´ esid´ eri. A stochastic multiple gradient descent algorithm. European J. Oper. Res., 271:808 – 817, 2018
work page 2018
-
[42]
M. Razaviyayn, M. Hong, and Z. Luo. A unified convergence analysis of block successive minimization methods for nonsmooth optimization.SIAM J. Optim., 23:1126–1153, 2013
work page 2013
- [43]
-
[44]
G. C. Reinsel and R. P. Velu.Multivariate Reduced-rank Regression. Springer, New York, 1998
work page 1998
-
[45]
S. Shalev-Shwartz, Y. Singer, and N. Srebro. Pegasos: Primal estimated sub-gradient solver for SVM.International Conference on Machine Learning, pages 807–814, 2007
work page 2007
- [46]
- [47]
-
[48]
Z. Wen, D. Goldfarb, and K. Scheinberg. Block coordinate descent methods for semidefinite programming.Handbook on Semidefinite, Conic and Polynomial Optimization, pages 533– 564, 2012
work page 2012
-
[49]
S. J. Wright. Coordinate descent algorithms.Math. Program., 151:3–34, 2015
work page 2015
- [50]
-
[51]
Y. Yang, M. Pesavento, Z. Luo, and B. Ottersten. Inexact block coordinate descent algo- rithms for nonsmooth nonconvex optimization.IEEE Transactions on Signal Processing, 68:947–961, 2019
work page 2019
- [52]
-
[53]
S. Zhang. Beijing Multi-Site Air-Quality Data. UCI Machine Learning Repository, 2019
work page 2019
-
[54]
S. Zhou, W. Zhang, J. Jiang, W. Zhong, J. Gu, and W. Zhu. On the convergence of stochastic multi-objective gradient manipulation and beyond.Advances in Neural Infor- mation Processing Systems, 35:38103–38115, 2022. 22
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.