Recognition: 2 theorem links
· Lean TheoremCAAFC: Chronological Actionable Automated Fact-Checker for misinformation / non-factual hallucination detection and correction
Pith reviewed 2026-05-13 04:38 UTC · model grok-4.3
The pith
CAAFC detects and corrects factual errors and hallucinations in claims, conversations, and dialogues using primary sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAAFC surpasses state-of-the-art AFC and hallucination detection systems across multiple benchmark datasets. It operates on claims, conversations, and dialogues to detect factual errors and hallucinations, corrects them by providing actionable justifications supported by primary information sources, and updates evidence and knowledge bases by incorporating recent and contextual information when necessary.
What carries the argument
The CAAFC framework, which follows a chronological and actionable process for detecting, correcting, and updating facts based on primary sources.
If this is right
- CAAFC applies to conversational formats such as dialogues in addition to isolated claims.
- It delivers corrections accompanied by justifications from primary sources.
- The framework can update its evidence and knowledge bases with new information.
- This leads to enhanced reliability in automated fact verification processes.
Where Pith is reading between the lines
- If integrated with generative AI tools, it could reduce the occurrence of hallucinations in real-time outputs.
- Testing on live news streams with evolving facts would reveal how well it incorporates recent information.
- Similar chronological updating could be applied to other verification tasks like checking scientific claims against latest papers.
Load-bearing premise
The framework can reliably access primary sources and add recent information without introducing new factual errors.
What would settle it
Compare CAAFC's outputs and corrections on a collection of recent claims against independent professional fact-checker results to see if they match in accuracy and source support.
Figures


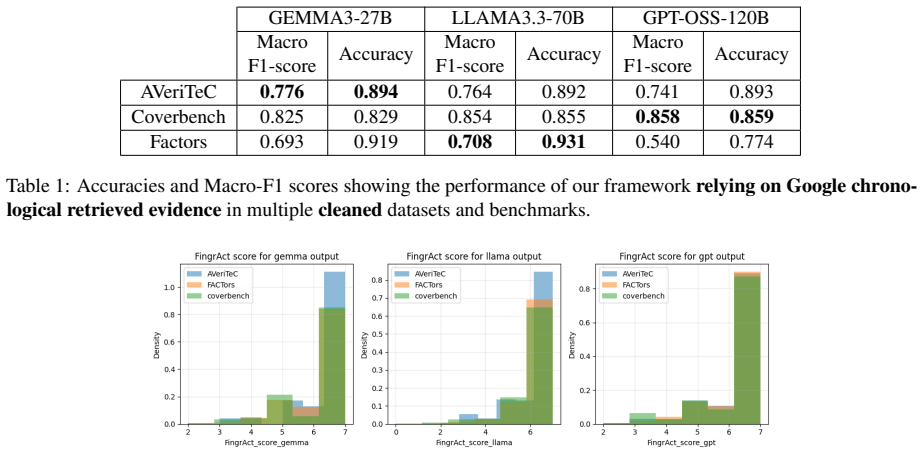






read the original abstract
With the vast amount of content uploaded every hour, along with the AI generated content that can include hallucinations, Automated Fact-Checking (AFC) has become increasingly vital, as it is infeasible for human fact-checkers to manually verify the sheer volume of information generated online. Professional fact-checkers have identified several gaps in existing AFC systems, noting a misalignment between how these systems operate and how fact-checking is performed in practice. In this paper, we introduce CAAFC (Chronological Actionable Automated Fact-Checker), a frame-work designed to bridge these gaps. It surpasses SOTA AFC and hallucination detection systems across multiple benchmark datasets. CAAFC operates on claims, conversations, and dialogues, enabling it not only to detect factual errors and hallucinations, but also to correct them by providing actionable justifications supported by primary information sources. Furthermore, CAAFC can update evidence and knowledge bases by incorporating recent and contextual information when necessary, thereby enhancing the reliability of fact verification.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAAFC (Chronological Actionable Automated Fact-Checker), a framework for detecting and correcting factual errors and hallucinations in claims, conversations, and dialogues. It claims to surpass state-of-the-art AFC and hallucination detection systems across multiple benchmark datasets, provide actionable justifications backed by primary sources, and dynamically update evidence and knowledge bases with recent contextual information to better align with professional fact-checking practices.
Significance. If the superiority claims and correction mechanisms hold under rigorous evaluation, the work could meaningfully advance automated fact-checking by addressing gaps between existing systems and real-world professional practices, particularly in handling dynamic information and AI-generated hallucinations through chronological processing and primary-source grounding.
major comments (2)
- [Abstract] Abstract: The central claim that CAAFC 'surpasses SOTA AFC and hallucination detection systems across multiple benchmark datasets' is unsupported by any performance metrics, baseline comparisons, evaluation protocols, or results tables, rendering the superiority assertion impossible to assess.
- [Abstract] Abstract: The description of CAAFC's ability to detect errors, correct them with 'actionable justifications supported by primary information sources,' and update knowledge bases lacks any methodological details, system architecture, retrieval mechanisms, or verification algorithms, which are load-bearing for evaluating the reliability of primary-source access and error-free updates.
minor comments (1)
- [Abstract] The abstract contains a hyphenated 'frame-work' that should be corrected to 'framework' for standard spelling.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, agreeing where the abstract can be strengthened for clarity and self-containment while noting that the full manuscript provides the supporting details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that CAAFC 'surpasses SOTA AFC and hallucination detection systems across multiple benchmark datasets' is unsupported by any performance metrics, baseline comparisons, evaluation protocols, or results tables, rendering the superiority assertion impossible to assess.
Authors: We agree that the abstract, being a high-level summary, does not embed the specific metrics, tables, or protocol details. The full manuscript includes these in the Experiments section, with quantitative comparisons against SOTA AFC and hallucination detection baselines across the cited benchmark datasets, along with the evaluation protocols used. To make the abstract more self-contained and directly address this concern, we will revise it to incorporate key performance highlights and a concise reference to the evaluation setup. revision: yes
-
Referee: [Abstract] Abstract: The description of CAAFC's ability to detect errors, correct them with 'actionable justifications supported by primary information sources,' and update knowledge bases lacks any methodological details, system architecture, retrieval mechanisms, or verification algorithms, which are load-bearing for evaluating the reliability of primary-source access and error-free updates.
Authors: The abstract is intentionally concise and focuses on capabilities rather than implementation specifics. The manuscript details the system architecture, chronological action processing, primary-source retrieval mechanisms, verification algorithms, and dynamic knowledge-base update procedures in the Methodology and Implementation sections. We acknowledge that a brief methodological overview in the abstract would improve accessibility and will revise the abstract to include a short description of these core components. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents CAAFC as a descriptive framework for chronological actionable fact-checking and hallucination correction. No equations, derivations, fitted parameters, or self-referential constructions appear in the provided text. Claims of surpassing SOTA rest on benchmark performance rather than any internal reduction to inputs by definition or self-citation chains. The work is self-contained as a system proposal with no load-bearing steps that collapse to tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Professional fact-checkers have identified gaps in existing AFC systems regarding misalignment with practical workflows.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearCAAFC is a module based frame-work with six modules using quantized LLMs... The Extractor Segmentor... Primary Chronological Evidence Retriever... Fact-Checker... Actionable Justifier... Actionability Evaluator... Justification Revisory
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCAAFC extract timestamped, ordered and updated evidence from the web... directive search... Google AI Mode... chronologically ordered evidence
Reference graph
Works this paper leans on
-
[1]
FinGrAct: A framework for FINe-GRrained evaluation of ACTionability in explainable automatic fact-checking. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 9882–9901, Suzhou, China. Association for Com- putational Linguistics. Eleni Fysikoudi, Sharid Loáiciga, and Asad Sayeed
work page 2025
-
[2]
InProceedings of the First BabyLM Workshop, pages 488–495
Active curriculum language modeling over a hybrid pre-training method. InProceedings of the First BabyLM Workshop, pages 488–495. Zhijiang Guo, Michael Schlichtkrull, and Andreas Vla- chos. 2022. A survey on automated fact-checking. Transactions of the association for computational linguistics, 10:178–206. Nannan Huang and Xiuzhen Zhang. 2021. Evaluation ...
-
[3]
Mark Rothermel, Tobias Braun, Marcus Rohrbach, and Anna Rohrbach
Temporal graph network: Hallucination detec- tion in multi-turn conversation.arXiv e-prints, pages arXiv–2601. Mark Rothermel, Tobias Braun, Marcus Rohrbach, and Anna Rohrbach. 2024. InFact: A strong baseline for automated fact-checking. InProceedings of the Seventh Fact Extraction and VERification Workshop (FEVER), pages 108–112, Miami, Florida, USA. As-...
work page 2024
-
[4]
Prefer sources that: • Produce original data • Hold legal, scientific, or operational authority • Are required for real-world systems to function
-
[5]
Rank sources by authority strength, not popularity
-
[6]
Distinguish between measurement authority, regulatory authority, and theo- retical authority
-
[7]
Avoid secondary explainers, media articles, and encyclopedias
-
[8]
the claim: {claim} Figure 5: Prompt used for extracting primary sources
Your output should be a list of primary sources and the justification for their selection. the claim: {claim} Figure 5: Prompt used for extracting primary sources. Role: You are a fact-checking assistant. Your task is to analyze a claim and determine the truthfulness of its sub-components based on the provided evidence. You are given a list of sub-claims,...
-
[9]
Compare each subclaim with the provided evidence
-
[10]
Base your judgment only on the given evidence
Check whether the evidence supports, contradicts, or does not mention the subclaim. Base your judgment only on the given evidence. Do not rely on prior knowledge
-
[11]
true" if The evidence directly supports the subclaim. -
Assign one of three labels to each subclaim: - "true" if The evidence directly supports the subclaim. - "false" if The evidence directly contradicts the subclaim. - "unverifiable" if The evidence is insufficient, unclear, or unrelated to verify the subclaim
-
[12]
Your output is a json object containing only three fields which are the sub- claim, label, and the explanation. Here is an example of the output format: {"subclaims": [{"text": "First subclaim here.","label": "true | false | unverifi- able","justification": "Brief explanation of how the evidence supports, contra- dicts, or fails to verify this subclaim."}...
-
[13]
Here is an example of the whole process: sub-claims: [’Paris is the capital of Germany’, ’Paris has the Eiffel Tower.’] evidence: Paris is the capital of France. The Eiffel Tower is located in Paris. output: {"subclaims": [{"text": "Paris is the capital of Germany.","label": "false","justification": "The evidence states Paris is the capital of France, not...
-
[14]
Your output is restricted to the json format mentioned in step 4
Do not add the instructions or anything from the prompt. Your output is restricted to the json format mentioned in step 4. claim: {claim} evidence: {evidence} Figure 6: Prompt used by the fact-checker module You are given a claim, evidence (reference information used to judge the claim), and a JSON object. The json object contains the claim divided into s...
-
[15]
Clearly reference which subclaims strengthen or weaken the claim
-
[16]
Explain how the evidence supports or contradicts the claim at a structural level
-
[17]
Highlight any gaps or uncertainties caused by unverifiable subclaims
-
[18]
Describe how false subclaims impact the credibility of the overall claim
-
[19]
Provides a corrected version of the whole claim
-
[20]
Only analyze and integrate what is already in the JSON object
Do not rewrite or re-evaluate the subclaims. Only analyze and integrate what is already in the JSON object
-
[21]
Here is an example of the whole process: claim: Paris is the capital of Germany and it has the Eiffel Tower. evidence: Paris is the capital of France. The Eiffel Tower is located in Paris. json object: "subclaims": ["text": "Paris is the capital of Germany.","label": "false","justification": "The evidence states Paris is the capital of France, not Germany...
-
[22]
Your output is restricted to the json format mentioned in step 7
Do not add the instructions or anything from the prompt. Your output is restricted to the json format mentioned in step 7. claim: {claim} evidence: {evidence} json object: {json_object} Figure 7: Prompt used by the actionable justifier module Role:You are an expert fact-checking editor. Your task is to improve the actionability of justifications by explic...
-
[23]
3.Preserve all correct reasoning already present
Clearly highlight previously unmentioned errors in the original justification. 3.Preserve all correct reasoning already present. 4.Do not introduce new facts or evidence beyond what is implied by the feed- back
-
[24]
Use clear, concise, and structured language suitable for professional fact- checking reports
-
[25]
Produce a single revised justification
-
[26]
Ensure the reasoning clearly connects errors, corrections, final verdict. 8. Avoid meta-commentary (e.g., “the feedback says. . . ”). Original Justification: {justification} Feedback on Missing Errors and Corrections: {feedback} Figure 8: Prompt for justification revisory A.4 Automation of evidence update To fully automate the evidence inspection method- ...
work page 2018
-
[27]
Compare the two evidences only with respect to the given claim
-
[28]
Select one of the following as the better evidence: -"evidence_1" - "evidence_2" -"tie" (use only if they are equally strong) 3. Provide a concise but clear justification
-
[29]
If the reason is not “more context” or “more updated information”, use "other" and explain briefly
-
[30]
Your output is only restricted to the json format mentioned
Do not add the instructions or anything from the prompt. Your output is only restricted to the json format mentioned
-
[31]
Output Format (JSON only): { "better_evidence": "evidence_1 | evidence_2 | tie", "reason_category": "more_context | more_updated_information | other", "reason": "Brief explanation justifying why this evidence is better for assessing the claim." } claim: {claim} evidence 1: {evidence1} evidence 2: {evidence2} Figure 9: Prompt for evidence comparison to the...
work page 2018
- [32]
-
[33]
Indexing: The information gathered by the crawlers is analyzed, and the content is stored in Google’s massive index (a digital library). This process involves understanding the page’s content, images, and key elements like title tags and headings. 3
-
[34]
Ranking: When a user enters a search query, Google’s ranking systems sort through the in- 2https://www.semrush.com/blog/Google-search-a lgorithm/ 3https://blog.photobiz.com/blog-post/breaking -down-Googles-search-algorithm dexed pages and order them based on rele- vance and quality to that specific query and user context. 4 Key Ranking signalsWhile Google...
-
[35]
The content should use relevant keywords naturally in headings, body text, and title tags
Relevance and Search Intent: Google first es- tablishes the intent behind a user’s query (e.g., informational, navigational, transactional) and prioritizes pages that are most likely to satisfy that intent. The content should use relevant keywords naturally in headings, body text, and title tags
-
[36]
Content Quality and E-E-A-T: High-quality, original, and helpful content is crucial. Google emphasizes E-E-A-T (Experience, Ex- pertise, Authoritativeness, and Trustworthi- ness), especially for sensitive topics ("Your Money or Your Life" topics). Content that offers unique insights, is well-researched, and regularly updated tends to rank higher
-
[37]
Backlinks (Authority): Backlinks, or links from other websites to a page, act as "votes of confidence." Links from established, high- authority websites significantly boost a page’s perceived credibility and authority
-
[38]
Context and Personalization: Results are cus- tomized based on the user’s location, lan- guage, device type, and search history to pro- vide the most relevant information. AI on Google Search summarizes search engine results. Google has integrated Gemini 3 Pro into its search experience to summarize complex infor- mation. 5 It changes search from a list o...
work page 2020
-
[39]
Misleading interpretation: The claim is mis- leading because Biden took a hypothetical sce- nario from a statistical model and presented it as a concrete and achievable reality. The study, conducted by Columbia University’s Mailman School of Public Health, estimated that if social distancing and other mitigation efforts had begun just one week earlier, th...
-
[40]
Extrapolation issues: Biden’s figure of 160,000 was a projection based on the study’s early findings, and it expanded a narrow hy- pothetical to a broader, unsubstantiated claim about total preventable deaths
-
[41]
Model limitations: Statistical models rely on many assumptions. The Columbia study did not account for all the FACTors involved in a complex public health crisis, and it is impos- sible to know exactly how many lives would have been saved with a different response. " In the “false” claim category, in 27 instances, all three models consistently predicted t...
work page 2023
- [42]
-
[43]
Side-by-Side Testing: Humans compare two different AI responses 7 to the same prompt and vote on which is more helpful and accu- rate to refine the underlying algorithms. In addition Google deploys several "live" systems work to maintain reliability: • Knowledge Graph Cross-Referencing: For factual queries, the system can cross-check claims against Google...
work page 2024
-
[44]
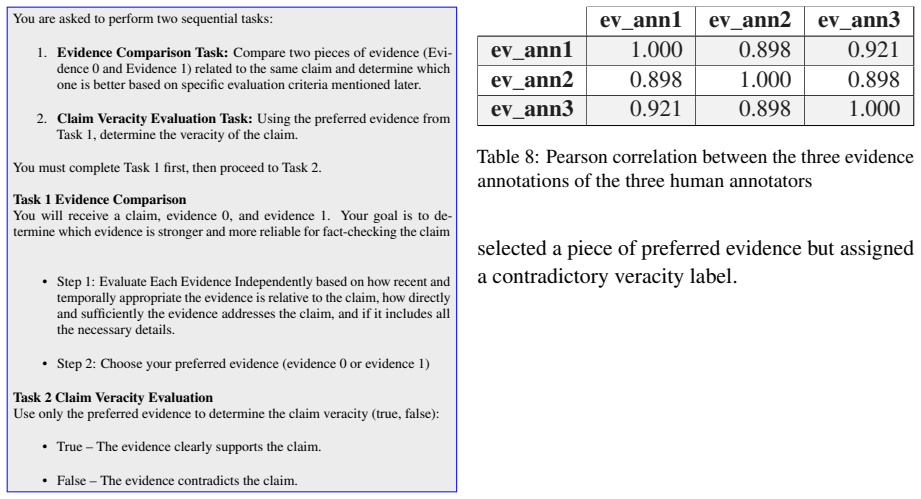
Clear Annotation Guidelines – annotators have strict, well-defined rules. In addition, there is a direct channel (emails) for them to You are asked to perform two sequential tasks:
-
[45]
Evidence Comparison Task:Compare two pieces of evidence (Evi- dence 0 and Evidence 1) related to the same claim and determine which one is better based on specific evaluation criteria mentioned later
-
[46]
You must complete Task 1 first, then proceed to Task 2
Claim Veracity Evaluation Task:Using the preferred evidence from Task 1, determine the veracity of the claim. You must complete Task 1 first, then proceed to Task 2. Task 1 Evidence Comparison You will receive a claim, evidence 0, and evidence 1. Your goal is to de- termine which evidence is stronger and more reliable for fact-checking the claim • Step 1:...
-
[47]
Objective or Easy-to-Classify Data – Tasks with minimal ambiguity (e.g., labeling with ’0, or ’ labels like "true and false") often lead to high agreement
-
[48]
A recruitment email was sent to postgraduate students and three annotators volunteered for this task
Annotators with similar backgrounds tend to agree more than crowd-sourced annotators. A recruitment email was sent to postgraduate students and three annotators volunteered for this task. Given this, we can assert that their annotations were conducted solely based on their understanding of the provided instructions. Next, we evaluate agreement between the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.