Recognition: 2 theorem links
· Lean TheoremORCE: Order-Aware Alignment of Verbalized Confidence in Large Language Models
Pith reviewed 2026-05-13 05:57 UTC · model grok-4.3
The pith
Decoupling answer generation from confidence estimation improves calibration of verbalized confidence in LLMs while preserving accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
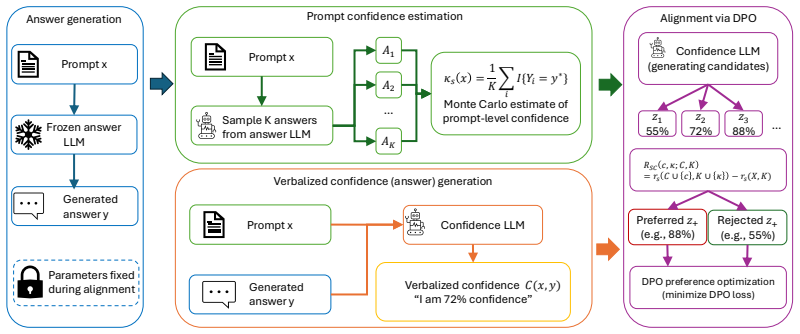
The central claim is that decoupling answer generation from confidence estimation and optimizing the relative ordering of verbalized confidence using rank-based objectives on a sampling surrogate leads to improved calibration and failure prediction while largely preserving answer accuracy on reasoning and knowledge-intensive benchmarks.
What carries the argument
The order-aware alignment framework that decouples answer generation and applies rank-based RL to align verbalized confidence with a sampling-based correctness surrogate.
If this is right
- Better calibration of verbalized confidence scores.
- Improved failure prediction performance.
- Answer accuracy remains largely intact.
- More reliable user-facing uncertainty estimates without token logit access.
Where Pith is reading between the lines
- This approach could extend to calibrating other LLM outputs like explanations or plans.
- Reducing reliance on ground truth for confidence training might enable self-supervised improvements.
- In practice, this could help in applications where overconfident answers lead to costly mistakes.
Load-bearing premise
The sampling-based surrogate from multiple model completions provides an accurate proxy for the actual correctness likelihood of responses.
What would settle it
If the ranks assigned by the sampling surrogate do not correlate with actual correctness rates across diverse benchmarks, the optimization would fail to align confidence properly.
Figures
read the original abstract
Large language models (LLMs) often produce answers with high certainty even when they are incorrect, making reliable confidence estimation essential for deployment in real-world scenarios. Verbalized confidence, where models explicitly state their confidence in natural language, provides a flexible and user-facing uncertainty signal that can be applied even when token logits are unavailable. However, existing verbalized-confidence methods often optimize answer generation and confidence generation jointly, which can cause confidence-alignment objectives to interfere with answer accuracy. In this work, we propose a decoupled and order-aware framework for verbalized confidence calibration. Our method first generates an answer and then estimates confidence conditioned on the fixed question--answer pair, allowing confidence optimization without directly perturbing the answer-generation process. To align confidence with correctness likelihood, we construct a sampling-based surrogate from multiple model completions and optimize rank-based reinforcement learning objectives that encourage responses with higher estimated correctness likelihood to receive higher verbalized confidence. Experiments on reasoning and knowledge-intensive benchmarks show that our method improves calibration and failure prediction performance while largely preserving answer accuracy. These results demonstrate that verbalized confidence can be more reliably aligned by decoupling confidence estimation from answer generation and optimizing the relative ordering of confidence across responses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ORCE, a decoupled order-aware framework for verbalized confidence calibration in LLMs. Answers are generated and fixed first, after which confidence is estimated on the question-answer pair via a sampling-based surrogate derived from multiple completions to approximate correctness likelihood; rank-based RL then optimizes verbalized confidence to respect the surrogate ordering. Experiments on reasoning and knowledge-intensive benchmarks report improved calibration and failure prediction while largely preserving answer accuracy.
Significance. If the sampling surrogate reliably tracks true correctness, the decoupled design and rank-based objective could provide a practical route to better verbalized confidence without the interference that joint optimization often introduces, while the reported preservation of accuracy is a useful empirical outcome.
major comments (2)
- [§3 (surrogate construction)] §3 (surrogate construction): The sampling-based surrogate for per-response correctness likelihood is constructed from multiple completions but is never directly validated against ground-truth correctness labels. This assumption is load-bearing for the central claim, because on knowledge-intensive tasks models frequently repeat the same incorrect answer; the resulting surrogate can assign high likelihood to errors, so the rank objective may optimize a mis-specified target rather than genuine alignment.
- [Experimental results (Section 5)] Experimental results (Section 5): Reported calibration gains are presented without ablations or correlation analysis showing that surrogate scores track actual correctness; if the surrogate-rank correlation is weak, the observed improvements could be artifacts of optimizing a noisy proxy rather than evidence of improved alignment.
minor comments (2)
- [Abstract] Abstract: The phrase 'order-aware' is introduced without a one-sentence definition; adding a brief gloss would help readers immediately distinguish the contribution from standard ranking losses.
- [Notation] Notation: Ensure the symbol for the surrogate likelihood (e.g., p̂_correct) is used consistently when describing both the sampling procedure and the RL reward.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3 (surrogate construction)] §3 (surrogate construction): The sampling-based surrogate for per-response correctness likelihood is constructed from multiple completions but is never directly validated against ground-truth correctness labels. This assumption is load-bearing for the central claim, because on knowledge-intensive tasks models frequently repeat the same incorrect answer; the resulting surrogate can assign high likelihood to errors, so the rank objective may optimize a mis-specified target rather than genuine alignment.
Authors: We acknowledge that the current manuscript does not include a direct empirical validation of the sampling-based surrogate against ground-truth correctness labels. The surrogate is constructed by drawing multiple completions from the model to estimate the likelihood of producing the correct answer for a fixed question-answer pair, serving as a practical proxy when direct supervision is unavailable. While repetition of incorrect answers is indeed possible on knowledge-intensive tasks, the rank-based RL objective operates on relative ordering rather than absolute values, which can still promote better calibration even with a noisy proxy. To address this concern, we will add a correlation analysis (including Spearman rank correlation and scatter plots) between surrogate scores and actual correctness labels across the benchmarks in a new subsection of Section 3 or an appendix in the revised manuscript. revision: yes
-
Referee: [Experimental results (Section 5)] Experimental results (Section 5): Reported calibration gains are presented without ablations or correlation analysis showing that surrogate scores track actual correctness; if the surrogate-rank correlation is weak, the observed improvements could be artifacts of optimizing a noisy proxy rather than evidence of improved alignment.
Authors: We agree that the experimental section would benefit from explicit ablations and correlation metrics linking surrogate scores to ground-truth correctness. The reported results show consistent gains in calibration and failure prediction with minimal impact on accuracy, which provides indirect support for the approach. However, to rule out the possibility that improvements stem from a weak proxy, we will add (i) correlation coefficients and visualizations between surrogate scores and correctness, and (ii) ablation studies removing or varying the rank-based objective in the revised Section 5. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation chain relies on an external sampling-based surrogate constructed from multiple independent model completions to estimate correctness likelihood, followed by rank-based RL optimization that aligns verbalized confidence ordering to this proxy. This is not equivalent to the inputs by construction: the surrogate is generated separately from the final verbalized outputs, the RL objective is a relative ranking loss rather than a direct fit to ground-truth labels or to the confidence values themselves, and claimed improvements are measured against external benchmarks using actual correctness. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or described framework; the approach remains self-contained with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sampling multiple model completions yields a usable surrogate for the likelihood that a given answer is correct
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoeswe construct a sampling-based surrogate from multiple model completions and optimize rank-based reinforcement learning objectives that encourage responses with higher estimated correctness likelihood to receive higher verbalized confidence
-
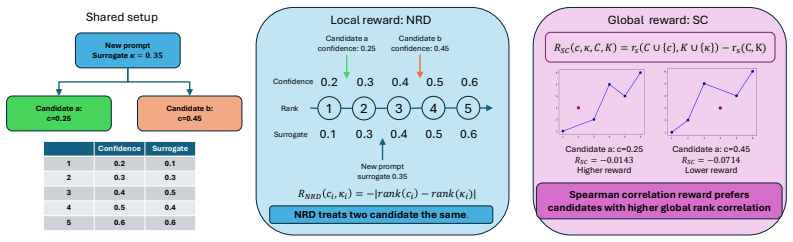
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt echoesSpearman correlation reward ... RSC(c, κ;C, K) = rs(C∪{c},K∪{κ})−rs(C,K)
Reference graph
Works this paper leans on
-
[1]
The internal state of an llm knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. InEMNLP (Findings), 2023
work page 2023
-
[2]
Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gard- ner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InNAACL, 2019
work page 2019
-
[3]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InICML, 2016
work page 2016
-
[4]
Selective classification for deep neural networks
Yonatan Geifman and Ran El-Yaniv. Selective classification for deep neural networks. In NeurIPS, 2017
work page 2017
-
[5]
Bias-reduced uncertainty estimation for deep neural classifiers
Yonatan Geifman, Guy Uziel, and Ran El-Yaniv. Bias-reduced uncertainty estimation for deep neural classifiers. InICLR, 2019
work page 2019
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. InNeurIPS, 2024
work page 2024
-
[7]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InICML, 2017
work page 2017
-
[8]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InICLR, 2021
work page 2021
-
[9]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems, 2025
work page 2025
-
[10]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys, 2023
work page 2023
-
[11]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Assessing reliability and challenges of uncertainty estimations for medical image segmentation
Alain Jungo and Mauricio Reyes. Assessing reliability and challenges of uncertainty estimations for medical image segmentation. InMICCAI, 2019
work page 2019
-
[13]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Large language models must be taught to know what they don’t know
Sanyam Kapoor, Nate Gruver, Manley Roberts, Katherine Collins, Arka Pal, Umang Bhatt, Adrian Weller, Samuel Dooley, Micah Goldblum, and Andrew G Wilson. Large language models must be taught to know what they don’t know. InNeurIPS, 2024
work page 2024
-
[15]
Simple and scalable predictive uncertainty estimation using deep ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. InNeurIPS, 2017
work page 2017
-
[16]
Confidence estimation using unlabeled data
Chen Li, Xiaoling Hu, and Chao Chen. Confidence estimation using unlabeled data. InICLR, 2023
work page 2023
-
[17]
Legalagentbench: Evaluating llm agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, et al. Legalagentbench: Evaluating llm agents in legal domain. InACL, 2025. 11
work page 2025
-
[18]
Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning
Shuyue S Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S Ilgen, Emma Pierson, Pang W Koh, and Yulia Tsvetkov. Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning. InNeurIPS, 2024
work page 2024
-
[19]
Conftuner: Training large language models to express their confidence verbally
Yibo Li, Miao Xiong, Jiaying Wu, and Bryan Hooi. Conftuner: Training large language models to express their confidence verbally. InNeurIPS, 2025
work page 2025
-
[20]
Teaching models to express their uncertainty in words.TMLR, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.TMLR, 2022
work page 2022
-
[21]
Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding
Hanmeng Liu, Jian Liu, Leyang Cui, Zhiyang Teng, Nan Duan, Ming Zhou, and Yue Zhang. Logiqa 2.0—an improved dataset for logical reasoning in natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023
work page 2023
-
[22]
Distance-based confidence score for neural network classifiers.arXiv preprint arXiv:1709.09844, 2017
Amit Mandelbaum and Daphna Weinshall. Distance-based confidence score for neural network classifiers.arXiv preprint arXiv:1709.09844, 2017
-
[23]
Confidence-aware learning for deep neural networks
Jooyoung Moon, Jihyo Kim, Younghak Shin, and Sangheum Hwang. Confidence-aware learning for deep neural networks. InICML, 2020
work page 2020
-
[24]
Obtaining well calibrated probabilities using bayesian binning
Mahdi Pakdaman Naeini, Gregory Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. InAAAI, 2015
work page 2015
-
[25]
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images
Anh Nguyen, Jason Yosinski, and Jeff Clune. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. InCVPR, 2015
work page 2015
-
[26]
Pranab Sahoo, Prabhash Meharia, Akash Ghosh, Sriparna Saha, Vinija Jain, and Aman Chadha. A comprehensive survey of hallucination in large language, image, video and audio foundation models.EMNLP (Findings), 2024
work page 2024
-
[27]
The proof and measurement of association between two things.The American Journal of Psychology, 1904
C Spearman. The proof and measurement of association between two things.The American Journal of Psychology, 1904
work page 1904
-
[28]
Lacie: Listener-aware finetuning for calibration in large language models
Elias Stengel-Eskin, Peter Hase, and Mohit Bansal. Lacie: Listener-aware finetuning for calibration in large language models. InNeurIPS, 2024
work page 2024
-
[29]
When to trust llms: Aligning confidence with response quality
Shuchang Tao, Liuyi Yao, Hanxing Ding, Yuexiang Xie, Qi Cao, Fei Sun, Jinyang Gao, Huawei Shen, and Bolin Ding. When to trust llms: Aligning confidence with response quality. InACL (Findings), 2024
work page 2024
-
[30]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InEMNLP, 2023
work page 2023
-
[31]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR, 2023
work page 2023
-
[32]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS, 2022
work page 2022
-
[33]
Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms
Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InICLR, 2024
work page 2024
-
[34]
Sayself: Teaching llms to express confidence with self-reflective rationales
Tianyang Xu, Shujin Wu, Shizhe Diao, Xiaoze Liu, Xingyao Wang, Yangyi Chen, and Jing Gao. Sayself: Teaching llms to express confidence with self-reflective rationales. InEMNLP, 2024
work page 2024
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Can large language models faithfully express their intrinsic uncertainty in words? InEMNLP, 2024
Gal Yona, Roee Aharoni, and Mor Geva. Can large language models faithfully express their intrinsic uncertainty in words? InEMNLP, 2024. 12
work page 2024
-
[37]
Reclor: A reading comprehension dataset requiring logical reasoning
Weihao Yu, Zihang Jiang, Yanfei Dong, and Jiashi Feng. Reclor: A reading comprehension dataset requiring logical reasoning. InICLR, 2020
work page 2020
-
[38]
Transforming classifier scores into accurate multiclass probability estimates
Bianca Zadrozny and Charles Elkan. Transforming classifier scores into accurate multiclass probability estimates. InKDD, 2002. 13 A Additional theoretical details This appendix provides additional justification for the theoretical discussion in Section 3.4. Our goal is to clarify three points: (i) why the ensemble surrogate κs is a consistent approximatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.