Recognition: 2 theorem links
· Lean TheoremRouters Learn the Geometry of Their Experts: Geometric Coupling in Sparse Mixture-of-Experts
Pith reviewed 2026-05-13 05:15 UTC · model grok-4.3
The pith
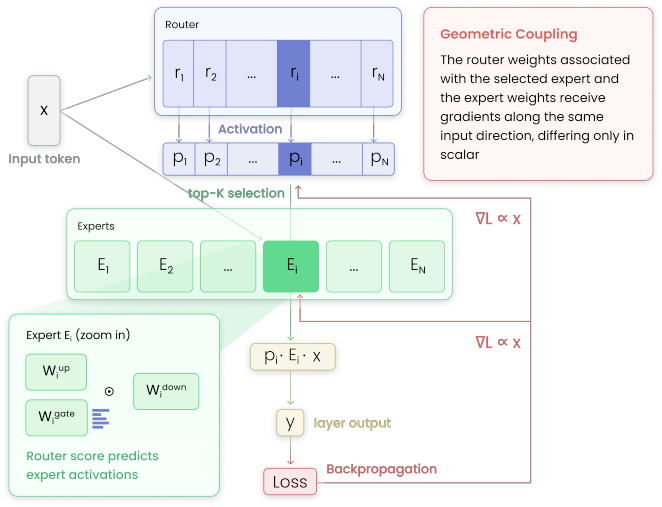
In SMoE models, routers and experts align their weight directions through shared gradient updates for each token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
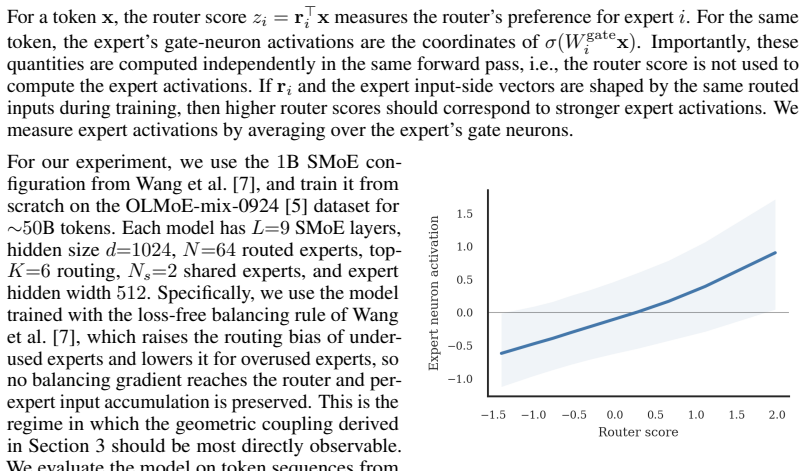
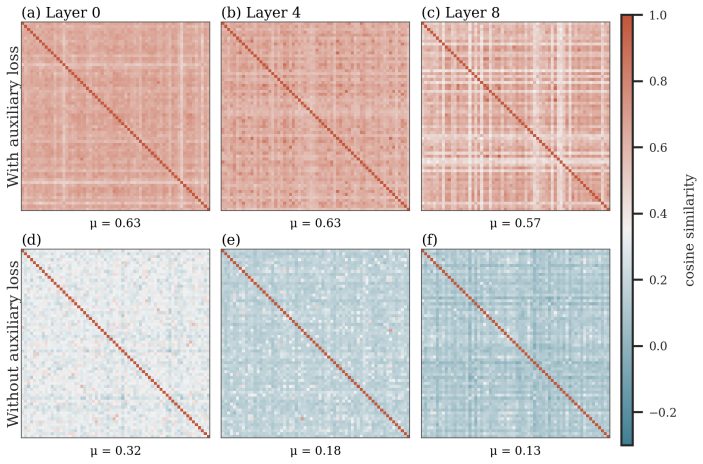
For a given token, the router weights for the selected expert and the expert weights processing it receive gradients along the same input direction, differing only in scalar coefficients. Thus, matched router-expert directions accumulate the same routed token history. This coupling is observed empirically as higher router scores predicting stronger expert activations. Auxiliary load balancing losses disrupt the structure by spreading gradients, increasing similarity between router directions nearly threefold. A parameter-free online K-means router, assigning based on cosine similarity to expert averages, maintains the coupling and shows the lowest load imbalance with modest perplexity cost.
What carries the argument
The geometric coupling between router and expert, in which their weight vectors for matched pairs are updated along identical input directions.
Load-bearing premise
The geometric coupling is the key mechanism enabling effective expert specialization and load balance in SMoE models.
What would settle it
A model where the router-expert gradient directions are artificially decoupled, such as by modifying the gradient flow, would show worse load balance and performance if the claim holds.
Figures

read the original abstract
Sparse Mixture-of-Experts (SMoE) models enable scaling language models efficiently, but training them remains challenging, as routing can collapse onto few experts and auxiliary load-balancing losses can reduce specialization. Motivated by these hurdles, we study how routing decisions in SMoEs are formed mechanistically. First, we reveal a geometric coupling between routers and their corresponding experts. For a given token, the router weights for the selected expert and the expert weights processing it receive gradients along the same input direction, differing only in scalar coefficients. Thus, matched router--expert directions accumulate the same routed token history. This theoretical coupling also appears empirically in routing dynamics. In a $1$B SMoE trained from scratch, higher router scores predict stronger expert neuron activations, showing that routing decisions are mirrored inside the selected expert. Next, we analyze the effects of auxiliary load balancing on the router--expert geometric coupling, showing that such losses break this structure by spreading input-directed gradients across router weights, making distinct router directions nearly three times more similar to each other. Last, we demonstrate the centrality of geometric coupling for effective routing with a parameter-free online K-Means router, in which each expert maintains a running average of the hidden states routed to it and tokens are assigned based on cosine similarity. Compared with auxiliary-loss and loss-free balancing, this router achieves the lowest load imbalance with only a modest perplexity increase, indicating that geometric coupling captures a substantial part of what the router learns. Overall, our results explain how routers form assignment geometry that supports an effective division of labor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that sparse MoE routers and experts exhibit a geometric coupling: for a routed token, the router column and the corresponding expert's first-layer weights receive gradients proportional to the same input vector x, so matched directions accumulate identical token histories. This is derived from standard gradient flow, observed empirically in a 1B model (higher router scores predict stronger expert activations), shown to be disrupted by auxiliary load-balancing losses (router directions become ~3x more similar), and used to motivate a parameter-free online K-Means router (running per-expert averages + cosine assignment) that yields the lowest load imbalance with only modest perplexity increase.
Significance. If the coupling is load-bearing for specialization and the K-Means results can be attributed to it rather than explicit clustering, the work supplies a mechanistic explanation for routing collapse and auxiliary-loss side-effects, plus a practical router design. The gradient derivation, 1B-scale empirical check, and parameter-free router are concrete strengths that advance understanding of MoE training dynamics.
major comments (2)
- [K-Means router demonstration (final paragraph of abstract)] The final claim that the K-Means router's load-balance results demonstrate the centrality of geometric coupling rests on the untested assumption that gains arise from mimicking gradient alignment rather than from the explicit clustering procedure (running averages of routed hidden states and cosine-similarity assignment). Because the K-Means router has no router parameters or gradients, its success does not directly test whether preserving the coupling structure is necessary or sufficient. Additional controls (e.g., a non-gradient router without explicit clustering) are required to support this interpretation.
- [Empirical validation in 1B SMoE] The empirical statement that 'higher router scores predict stronger expert neuron activations' in the 1B model lacks reported measurement details, statistical controls, sample sizes, or significance tests. Without these, it is difficult to evaluate how strongly the observation supports the geometric-coupling hypothesis.
minor comments (2)
- [Auxiliary-loss analysis] The abstract states that auxiliary losses make 'distinct router directions nearly three times more similar'; specify the similarity metric, the exact section/figure where the factor of three is computed, and whether it is averaged over layers or tokens.
- [Theoretical derivation] Clarify the precise notation for router weights (columns vs. rows) and expert first-layer weights when stating that gradients are 'along the same input direction, differing only in scalar coefficients.'
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments on our manuscript. We address each major comment point by point below, and we plan to revise the paper to strengthen the claims as suggested.
read point-by-point responses
-
Referee: [K-Means router demonstration (final paragraph of abstract)] The final claim that the K-Means router's load-balance results demonstrate the centrality of geometric coupling rests on the untested assumption that gains arise from mimicking gradient alignment rather than from the explicit clustering procedure (running averages of routed hidden states and cosine-similarity assignment). Because the K-Means router has no router parameters or gradients, its success does not directly test whether preserving the coupling structure is necessary or sufficient. Additional controls (e.g., a non-gradient router without explicit clustering) are required to support this interpretation.
Authors: We acknowledge that the K-Means router, being parameter-free, does not directly involve the gradient coupling mechanism during its operation. However, its design is motivated by and directly implements the geometric alignment: each expert maintains a running average of the hidden states it receives, which are the very directions that the coupling causes the router and expert to align on, and assignment is performed via cosine similarity to these averages. This setup preserves the directional matching without needing auxiliary losses. That said, the referee correctly identifies that to more rigorously demonstrate the centrality of the coupling, additional controls are warranted. In the revised manuscript, we will include results from a baseline non-gradient router that uses random assignment (or a static clustering without online averaging of hidden states) to compare load balance and perplexity. This will help clarify whether the benefits stem specifically from the geometric clustering aspect. We believe this will support our interpretation while addressing the concern. revision: yes
-
Referee: [Empirical validation in 1B SMoE] The empirical statement that 'higher router scores predict stronger expert neuron activations' in the 1B model lacks reported measurement details, statistical controls, sample sizes, or significance tests. Without these, it is difficult to evaluate how strongly the observation supports the geometric-coupling hypothesis.
Authors: We agree that the empirical section would benefit from more precise reporting. The observation comes from evaluating the correlation between the router's output score for a given expert and the activation strength (measured as the L2 norm of the post-activation or the dot product with the expert's weight vector) on a held-out set of tokens. In the revision, we will specify: the exact definition of 'stronger expert neuron activations', the number of tokens and experts sampled (e.g., 10,000 tokens across all experts), the correlation coefficient value, and any statistical significance (such as p-values from a linear regression or Spearman rank correlation). We will also include error bars or confidence intervals where appropriate. These additions will make the support for the geometric-coupling hypothesis more quantifiable and transparent. revision: yes
Circularity Check
No significant circularity; coupling derived from standard backprop and K-Means test is independent
full rationale
The geometric coupling is obtained by applying the chain rule to the standard SMoE forward and loss computation: router column update is proportional to the routed token x and expert first-layer rows receive backpropagated scalars times the same x. This is a direct algebraic consequence of gradient flow with no fitted parameters, self-referential definitions, or ansatz smuggled via citation. The parameter-free online K-Means router is constructed explicitly as running-average centroid maintenance plus cosine assignment; its reported load-balance results are therefore an external empirical probe rather than a prediction forced by the coupling equations. No load-bearing step reduces by construction to its own inputs, and no self-citation chain is invoked to justify uniqueness or forbid alternatives. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- running average per expert
axioms (1)
- standard math Gradient updates follow standard backpropagation through the network
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearFor a given token, the router weights for the selected expert and the expert weights processing it receive gradients along the same input direction, differing only in scalar coefficients. Thus, matched router–expert directions accumulate the same routed token history.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclearparameter-free online K-Means router... each expert maintains a running average of the hidden states routed to it and tokens are assigned based on cosine similarity
Reference graph
Works this paper leans on
-
[1]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017. URL https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity, 2022. URLhttps://arxiv.org/abs/2101.03961
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding, 2020. URLhttps://arxiv.org/abs/2006.16668
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
-
[6]
On the representation collapse of sparse mixture of experts, 2022
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, Heyan Huang, and Furu Wei. On the representation collapse of sparse mixture of experts, 2022. URLhttps://arxiv.org/abs/2204.09179
-
[7]
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts.arXiv preprint arXiv:2408.15664, 2024
-
[8]
Stablemoe: Stable routing strategy for mixture of experts, 2022
Damai Dai, Li Dong, Shuming Ma, Bo Zheng, Zhifang Sui, Baobao Chang, and Furu Wei. Stablemoe: Stable routing strategy for mixture of experts, 2022. URLhttps://arxiv.org/abs/2204.08396
- [9]
-
[10]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need, 2017. URL https://arxiv.org/abs/1706. 03762. 10
work page 2017
-
[11]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y . Wu, Zhenda Xie, Y . K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models, 2024. URLhttps://arxiv.org/abs/2401.06066
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
A closer look into mixture-of-experts in large language models, 2025
Ka Man Lo, Zeyu Huang, Zihan Qiu, Zili Wang, and Jie Fu. A closer look into mixture-of-experts in large language models, 2025. URLhttps://aclanthology.org/2025.findings-naacl.251/
work page 2025
-
[14]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. St-moe: Designing stable and transferable sparse expert models, 2022. URL https: //arxiv.org/abs/2202.08906
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Advancing expert specialization for better moe.arXiv preprint arXiv:2505.22323, 2025
Hongcan Guo, Haolang Lu, Guoshun Nan, Bolun Chu, Jialin Zhuang, Yuan Yang, Wenhao Che, Xinye Cao, Sicong Leng, Qimei Cui, and Xudong Jiang. Advancing expert specialization for better moe.arXiv preprint arXiv:2505.22323, 2025
-
[16]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL https://jmlr.org/papers/v21/ 20-074.html
work page 2020
-
[17]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, Shawn Presser, and Connor Leahy. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020. URL https: //arxiv.org/abs/2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[18]
Junzhuo Li, Bo Wang, Xiuze Zhou, Peijie Jiang, Jia Liu, and Xuming Hu. Decoding knowledge attribution in mixture-of-experts: A framework of basic-refinement collaboration and efficiency analysis. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 22431–22446, 2025
work page 2025
-
[19]
Dokania, Adel Bibi, and Philip Torr
Xingyi Yang, Constantin Venhoff, Ashkan Khakzar, Christian Schroeder de Witt, Puneet K. Dokania, Adel Bibi, and Philip Torr. Mixture of experts made intrinsically interpretable. InProceedings of the 42nd International Conference on Machine Learning, 2025
work page 2025
-
[20]
The expert strikes back: Interpreting mixture-of-experts language models at expert level
Jeremy Herbst, Jae Hee Lee, and Stefan Wermter. The expert strikes back: Interpreting mixture-of-experts language models at expert level. InProceedings of the 43rd International Conference on Machine Learning,
-
[21]
Boan Liu, Liang Ding, Li Shen, Keqin Peng, Yu Cao, Dazhao Cheng, and Dacheng Tao. Diversifying the mixture-of-experts representation for language models with orthogonal optimizer, 2024. URL https: //arxiv.org/abs/2310.09762
-
[22]
Dick, Yuan Cheng, Fan Yang, Tun Lu, Chun Zhang, and Li Shang
Ruijun Huang, Fang Dong, Xin Zhang, Hengjie Cao, Zhendong Huang, Anrui Chen, Jixian Zhou, Mengyi Chen, Yifeng Yang, Mingzhi Dong, Yujiang Wang, Jinlong Hou, Qin Lv, Robert P. Dick, Yuan Cheng, Fan Yang, Tun Lu, Chun Zhang, and Li Shang. Sd-moe: Spectral decomposition for effective expert specialization, 2026. URLhttps://arxiv.org/abs/2602.12556
-
[23]
On the benefits of learning to route in mixture-of-experts models, 2023
Nishanth Dikkala et al. On the benefits of learning to route in mixture-of-experts models, 2023. URL https://aclanthology.org/2023.emnlp-main.583/
work page 2023
-
[24]
Ang Lv, Jin Ma, Yiyuan Ma, and Siyuan Qiao. Coupling experts and routers in mixture-of-experts via an auxiliary loss.arXiv preprint arXiv:2512.23447, 2025
-
[25]
Branch-train-mix: Mixing expert llms into a mixture-of-experts llm, 2024
Sainbayar Sukhbaatar, Olga Golovneva, Vasu Sharma, Hu Xu, Xi Victoria Lin, Baptiste Rozière, Jacob Kahn, Daniel Li, Wen tau Yih, Jason Weston, and Xian Li. Branch-train-mix: Mixing expert llms into a mixture-of-experts llm, 2024. URLhttps://arxiv.org/abs/2403.07816
-
[26]
Dense training, sparse inference: Rethinking training of mixture-of-experts language models, 2024
Bowen Pan, Yikang Shen, Haokun Liu, Mayank Mishra, Gaoyuan Zhang, Aude Oliva, Colin Raffel, and Rameswar Panda. Dense training, sparse inference: Rethinking training of mixture-of-experts language models, 2024. URLhttps://arxiv.org/abs/2404.05567. 11
-
[27]
Grouter: Decoupling routing from representation for accelerated moe training, 2026
Yuqi Xu, Rizhen Hu, Zihan Liu, Mou Sun, and Kun Yuan. Grouter: Decoupling routing from representation for accelerated moe training, 2026. URLhttps://arxiv.org/abs/2603.06626
-
[28]
Emoe: Eigenbasis-guided routing for mixture-of-experts, 2026
Anzhe Cheng, Shukai Duan, Shixuan Li, Chenzhong Yin, Mingxi Cheng, Shahin Nazarian, Paul Thompson, and Paul Bogdan. Emoe: Eigenbasis-guided routing for mixture-of-experts, 2026. URL https://arxiv. org/abs/2601.12137
-
[29]
Anzhe Cheng, Shukai Duan, Shixuan Li, Chenzhong Yin, Mingxi Cheng, Heng Ping, Tamoghna Chat- topadhyay, Sophia I Thomopoulos, Shahin Nazarian, Paul Thompson, and Paul Bogdan. Ermoe: Eigen- reparameterized mixture-of-experts for stable routing and interpretable specialization, 2025. URL https://arxiv.org/abs/2511.10971
-
[30]
Grassmannian mixture-of-experts: Concentration- controlled routing on subspace manifolds, 2026
Ibne Farabi Shihab, Sanjeda Akter, and Anuj Sharma. Grassmannian mixture-of-experts: Concentration- controlled routing on subspace manifolds, 2026. URLhttps://arxiv.org/abs/2602.17798
-
[31]
Self-routing: Parameter-free expert routing from hidden states, 2026
Jama Hussein Mohamud, Drew Wagner, and Mirco Ravanelli. Self-routing: Parameter-free expert routing from hidden states, 2026. URLhttps://arxiv.org/abs/2604.00421
-
[32]
Latent prototype routing: Achieving near-perfect load balancing in mixture-of-experts, 2025
Jiajie Yang. Latent prototype routing: Achieving near-perfect load balancing in mixture-of-experts, 2025. URLhttps://arxiv.org/abs/2506.21328
-
[33]
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics, 9: 53–68, 2021
work page 2021
-
[34]
Monkey jump: Moe-style peft for efficient multi-task learning, 2026
Nusrat Jahan Prottasha, Md Kowsher, Chun-Nam Yu, Chen Chen, and Ozlem Garibay. Monkey jump: Moe-style peft for efficient multi-task learning, 2026. URLhttps://arxiv.org/abs/2601.06356. A Theoretical foundation: the geometric alignment principle To better understand the meaning of the router and expert weights, we analyzed how these weights are updated dur...
-
[35]
Through the Hadamard gate (linear in W up i x):Since hi =g i ⊙W up i x and gi does not depend onW up i , ∂L ∂(W up i x) = ∂L ∂hi ⊙g i ∈R df f (15) 3.Final matrix gradient (outer product with input): ∂L ∂W up i = ∂L ∂(W up i x) xT ∈R df f×d (16) 12 Table 2: Mathematical notations and setup parameters. Category Notation Description Dimension InputxThe input...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.