Recognition: 2 theorem links
· Lean TheoremElastic Attention Cores for Scalable Vision Transformers
Pith reviewed 2026-05-13 05:57 UTC · model grok-4.3
The pith
Vision transformers can learn rich visual representations without any direct patch-to-patch interactions by routing everything through a small set of learned core tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VECA shows that effective visual-semantic representations emerge when patch tokens exchange information exclusively through a small, learned set of core embeddings that are initialized from scratch and updated across layers, producing linear O(N) complexity for fixed core count C while preserving competitive accuracy on both classification and dense prediction tasks.
What carries the argument
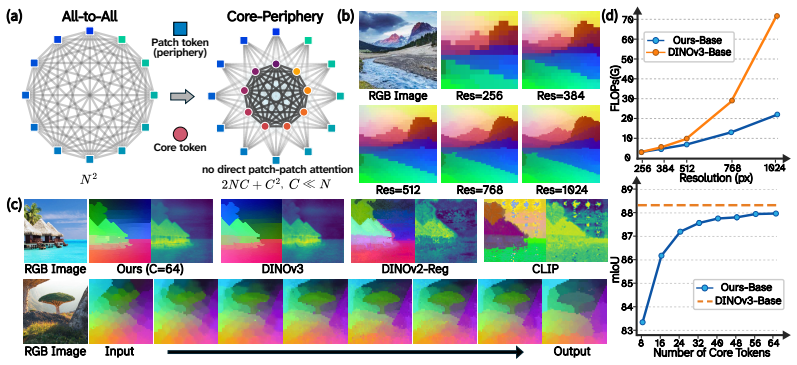
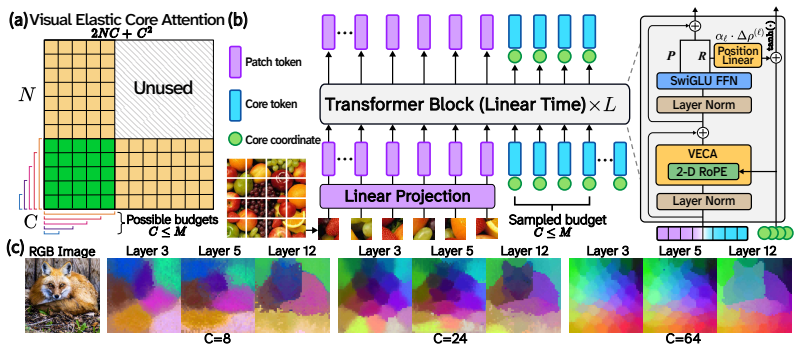
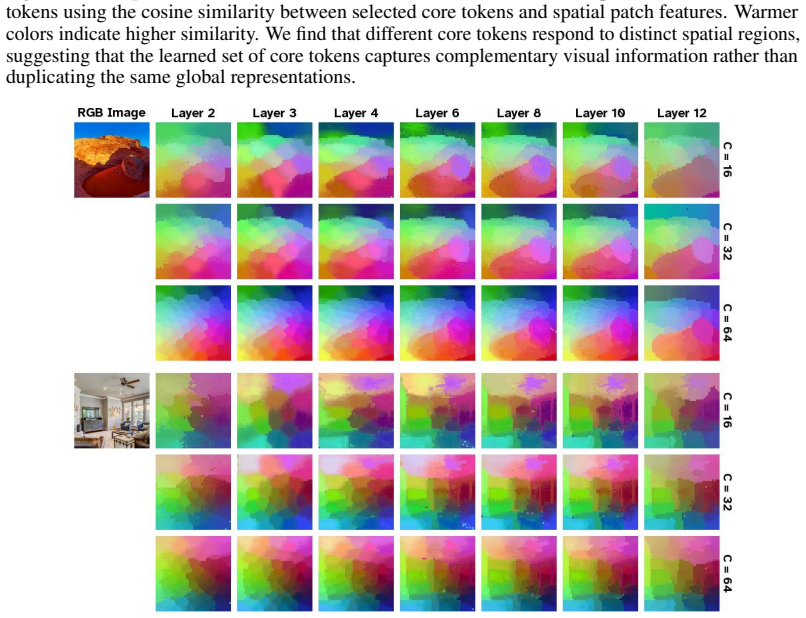
Visual Elastic Core Attention (VECA), in which a fixed set of C learned core tokens functions as the sole communication interface: every patch token attends only to the cores, and the cores attend to all patches, with the cores being propagated and updated layer by layer.
If this is right
- Image resolution can increase without a quadratic explosion in attention cost, since only the linear term in N remains.
- Nested training along the core axis lets a single model deliver a continuous range of accuracy-compute operating points at inference.
- The full set of N patch tokens is retained rather than collapsed into a small bottleneck, preserving spatial information for dense tasks.
- The same core-periphery pattern can be stacked or combined with other efficient attention variants without reintroducing quadratic scaling.
Where Pith is reading between the lines
- The approach suggests that many sequence-modeling domains may benefit from replacing all-to-all attention with learned hub-and-spoke communication structures.
- Because cores are learned from scratch rather than derived from the input, they may act as a form of implicit global memory that could transfer across tasks or datasets.
- Varying C during training and testing offers a practical knob for deploying the same weights on devices with different speed-accuracy requirements.
Load-bearing premise
A small fixed set of learned core tokens can capture and propagate all necessary visual-semantic information across patches without any direct patch-to-patch interactions.
What would settle it
Train VECA and a standard quadratic ViT on the same high-resolution dense-prediction benchmark with matched parameter count; if VECA accuracy remains within a few percent of the ViT while using far less compute, the claim is supported; a large gap would falsify it.
Figures




read the original abstract
Vision Transformers (ViTs) achieve strong data-driven scaling by leveraging all-to-all self-attention. However, this flexibility incurs a computational cost that scales quadratically with image resolution, limiting ViTs in high-resolution domains. Underlying this approach is the assumption that pairwise token interactions are necessary for learning rich visual-semantic representations. In this work, we challenge this assumption, demonstrating that effective visual representations can be learned without any direct patch-to-patch interaction. We propose VECA (Visual Elastic Core Attention), a vision transformer architecture that uses efficient linear-time core-periphery structured attention enabled by a small set of learned cores. In VECA, these cores act as a communication interface: patch tokens exchange information exclusively through the core tokens, which are initialized from scratch and propagated across layers. Because the $N$ image patches only directly interact with a resolution invariant set of $C$ learned "core" embeddings, this yields linear complexity $O(N)$ for predetermined $C$, which bypasses quadratic scaling. Compared to prior cross-attention architectures, VECA maintains and iteratively updates the full set of $N$ input tokens, avoiding a small $C$-way bottleneck. Combined with nested training along the core axis, our model can elastically trade off compute and accuracy during inference. Across classification and dense tasks, VECA achieves performance competitive with the latest vision foundation models while reducing computational cost. Our results establish elastic core-periphery attention as a scalable alternative building block for Vision Transformers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VECA (Visual Elastic Core Attention), a Vision Transformer architecture that replaces all-to-all self-attention with a core-periphery structure: a small fixed set of C learned core tokens serves as the sole communication interface, so that the N image patches interact only via patch-to-core and core-to-patch attention. This yields O(NC) complexity per layer (linear in N for fixed C), maintains the full set of N tokens across layers, and supports nested training for elastic compute-accuracy trade-offs at inference. The central claim is that effective visual representations for both classification and dense prediction can be learned without any direct patch-to-patch interactions, achieving performance competitive with recent vision foundation models while avoiding quadratic scaling.
Significance. If the empirical claims hold, the work supplies a concrete, resolution-invariant building block that removes the quadratic bottleneck of standard ViT attention while preserving the full token set. The direct derivation of linear complexity from the bipartite routing rule and the nested-training mechanism for elastic inference are clear strengths. The result would be relevant to high-resolution vision and resource-constrained deployment, provided the core bottleneck demonstrably preserves the necessary spatial and semantic relations.
major comments (3)
- [§3] §3 (Architecture): the claim that iterative patch-to-core and core-to-patch attention recovers the expressivity of full self-attention for visual semantics lacks any capacity argument, derivation, or proof that arbitrary higher-order patch dependencies can be mediated exactly through the fixed C-dimensional bottleneck. The bipartite structure is stated to propagate information, but no analysis shows the composition of updates equals the function class of all-to-all attention.
- [Experiments] Experiments on dense tasks (e.g., segmentation or detection sections): local spatial structure must survive repeated compression through the C cores; the manuscript supplies no targeted ablations, attention-map visualizations, or controlled comparisons that isolate whether fine-grained locality is preserved or lost relative to standard self-attention baselines.
- [Experiments] Table/figure reporting quantitative results: the abstract asserts competitive performance on classification and dense tasks, yet the provided manuscript excerpt contains no numerical tables, baselines, error bars, or ablation details; the central empirical claim therefore rests on unverified assertions until these are supplied.
minor comments (2)
- [§3] Notation for core initialization and propagation across layers is described only in prose; an explicit update equation would clarify whether cores are re-initialized or carried forward.
- [Introduction] The term 'elastic' is used for both the core-periphery routing and the nested training schedule; a single sentence distinguishing the two usages would avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below, providing clarifications and indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Architecture): the claim that iterative patch-to-core and core-to-patch attention recovers the expressivity of full self-attention for visual semantics lacks any capacity argument, derivation, or proof that arbitrary higher-order patch dependencies can be mediated exactly through the fixed C-dimensional bottleneck. The bipartite structure is stated to propagate information, but no analysis shows the composition of updates equals the function class of all-to-all attention.
Authors: We agree that the manuscript does not contain a formal capacity argument, derivation, or proof establishing that the bipartite core-periphery updates exactly recover the function class of all-to-all self-attention. The work is primarily empirical, demonstrating that competitive visual representations can be learned via the learned cores as an information bottleneck. We will revise §3 to include an explicit discussion of this limitation, clarifying that the architecture relies on iterative mediation through the cores rather than claiming theoretical equivalence, and we will note this as an avenue for future theoretical analysis. revision: partial
-
Referee: [Experiments] Experiments on dense tasks (e.g., segmentation or detection sections): local spatial structure must survive repeated compression through the C cores; the manuscript supplies no targeted ablations, attention-map visualizations, or controlled comparisons that isolate whether fine-grained locality is preserved or lost relative to standard self-attention baselines.
Authors: We recognize the need for explicit verification that fine-grained locality survives the core bottleneck. The full manuscript includes attention visualizations and ablations for dense tasks, but we will add new targeted ablations and controlled comparisons (e.g., locality metrics and direct baseline contrasts) in the revision to isolate preservation of spatial structure. revision: yes
-
Referee: [Experiments] Table/figure reporting quantitative results: the abstract asserts competitive performance on classification and dense tasks, yet the provided manuscript excerpt contains no numerical tables, baselines, error bars, or ablation details; the central empirical claim therefore rests on unverified assertions until these are supplied.
Authors: The referee's observation applies to the limited excerpt provided for review. The complete manuscript contains full tables reporting quantitative results on classification and dense tasks, with baselines, standard deviations, and ablation details. We will ensure these tables are prominently featured and clearly linked to all empirical claims in the revised version. revision: no
Circularity Check
No circularity: linear complexity follows directly from architecture definition
full rationale
The paper defines VECA via core-periphery routing where each of N patches attends exclusively to a fixed set of C cores (and cores attend back to patches). The stated O(N) complexity is obtained by direct operation counting on this bipartite structure for predetermined C; it is not a fitted prediction or self-referential claim. No equations reduce any performance result to the inputs by construction, no uniqueness theorems are imported via self-citation, and no ansatz is smuggled in. The claim that cores suffice to propagate visual semantics is presented as an empirical hypothesis validated by experiments rather than a definitional necessity. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- C (number of cores)
axioms (1)
- domain assumption A small fixed set of learned cores can serve as a sufficient communication bottleneck for all visual information exchange.
invented entities (1)
-
learned core embeddings
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearpatch tokens exchange information exclusively through the core tokens... yields linear complexity O(N) for predetermined C
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearcore-periphery structured attention... graph diameter of 2
Reference graph
Works this paper leans on
-
[1]
Ilya O Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, et al. Mlp-mixer: An all-mlp architecture for vision.Advances in neural information processing systems, 34: 24261–24272, 2021
work page 2021
-
[2]
Hugo Touvron, Piotr Bojanowski, Mathilde Caron, Matthieu Cord, Alaaeldin El-Nouby, Edouard Grave, Gautier Izacard, Armand Joulin, Gabriel Synnaeve, Jakob Verbeek, et al. Resmlp: Feedforward networks for image classification with data-efficient training.IEEE transactions on pattern analysis and machine intelligence, 45(4):5314–5321, 2022
work page 2022
-
[3]
Pay attention to mlps.Advances in neural information processing systems, 34:9204–9215, 2021
Hanxiao Liu, Zihang Dai, David So, and Quoc V Le. Pay attention to mlps.Advances in neural information processing systems, 34:9204–9215, 2021
work page 2021
-
[4]
Fnet: Mixing tokens with fourier transforms
James Lee-Thorp, Joshua Ainslie, Ilya Eckstein, and Santiago Ontanon. Fnet: Mixing tokens with fourier transforms. InProceedings of the 2022 Conference of the north American chapter of the Association for Computational Linguistics: human language technologies, pages 4296–4313, 2022
work page 2022
-
[5]
Yongming Rao, Wenliang Zhao, Zheng Zhu, Jie Zhou, and Jiwen Lu. Gfnet: Global filter networks for visual recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(9):10960–10973, 2023
work page 2023
-
[6]
Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks.Advances in neural information processing systems, 29, 2016
work page 2016
-
[7]
Md Amirul Islam, Sen Jia, and Neil DB Bruce. How much position information do convolutional neural networks encode?arXiv preprint arXiv:2001.08248, 2020
-
[8]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[9]
Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks?Advances in neural information processing systems, 34:12116–12128, 2021
work page 2021
-
[10]
How do vision transformers work?arXiv preprint arXiv:2202.06709, 2022
Namuk Park and Songkuk Kim. How do vision transformers work?arXiv preprint arXiv:2202.06709, 2022
-
[11]
Rethinking vision transformers for mobilenet size and speed
Yanyu Li, Ju Hu, Yang Wen, Georgios Evangelidis, Kamyar Salahi, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Rethinking vision transformers for mobilenet size and speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16889– 16900, 2023
work page 2023
-
[12]
Which transformer to favor: a comparative analysis of efficiency in vision transformers
Tobias Christian Nauen, Sebastian Palacio, Federico Raue, and Andreas Dengel. Which transformer to favor: a comparative analysis of efficiency in vision transformers. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 6955–6966. IEEE, 2025
work page 2025
-
[13]
Core-periphery structure in networks.SIAM Journal on Applied mathematics, 74(1):167–190, 2014
M Puck Rombach, Mason A Porter, James H Fowler, and Peter J Mucha. Core-periphery structure in networks.SIAM Journal on Applied mathematics, 74(1):167–190, 2014
work page 2014
-
[14]
Identification of core-periphery structure in networks.Physical Review E, 91(3):032803, 2015
Xiao Zhang, Travis Martin, and Mark EJ Newman. Identification of core-periphery structure in networks.Physical Review E, 91(3):032803, 2015
work page 2015
-
[15]
A method of matrix analysis of group structure.Psychome- trika, 14(2):95–116, 1949
R Duncan Luce and Albert D Perry. A method of matrix analysis of group structure.Psychome- trika, 14(2):95–116, 1949
work page 1949
-
[16]
Learning ordered representations with nested dropout
Oren Rippel, Michael Gelbart, and Ryan Adams. Learning ordered representations with nested dropout. InInternational Conference on Machine Learning, pages 1746–1754. PMLR, 2014. 11
work page 2014
-
[17]
Yixuan Wei, Han Hu, Zhenda Xie, Zheng Zhang, Yue Cao, Jianmin Bao, Dong Chen, and Baining Guo. Contrastive learning rivals masked image modeling in fine-tuning via feature distillation.arXiv preprint arXiv:2205.14141, 2022
-
[18]
Am-radio: Agglomerative vision foundation model reduce all domains into one
Mike Ranzinger, Greg Heinrich, Jan Kautz, and Pavlo Molchanov. Am-radio: Agglomerative vision foundation model reduce all domains into one. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12490–12500, 2024
work page 2024
-
[19]
Jinghuan Shang, Karl Schmeckpeper, Brandon B May, Maria Vittoria Minniti, Tarik Kelestemur, David Watkins, and Laura Herlant. Theia: Distilling diverse vision foundation models for robot learning.arXiv preprint arXiv:2407.20179, 2024
-
[20]
Unic: Universal classification models via multi-teacher distillation
Mert Bülent Sarıyıldız, Philippe Weinzaepfel, Thomas Lucas, Diane Larlus, and Yannis Kalan- tidis. Unic: Universal classification models via multi-teacher distillation. InEuropean Conference on Computer Vision, pages 353–371. Springer, 2024
work page 2024
-
[21]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
Shlomo Zilberstein. Using anytime algorithms in intelligent systems.AI magazine, 17(3):73–73, 1996
work page 1996
-
[23]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ra- manujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, et al. Matryoshka representation learning.Advances in Neural Information Processing Systems, 35:30233–30249, 2022
work page 2022
-
[24]
Triangular dropout: variable network width without retraining.arXiv preprint arXiv:2205.01235, 2022
Edward W Staley and Jared Markowitz. Triangular dropout: variable network width without retraining.arXiv preprint arXiv:2205.01235, 2022
-
[25]
Distributional Principal Autoencoders
Xinwei Shen and Nicolai Meinshausen. Distributional principal autoencoders.arXiv preprint arXiv:2404.13649, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Matthew Ho, Xiaosheng Zhao, and Benjamin D Wandelt. Ordered embeddings and intrin- sic dimensionalities with information-ordered bottlenecks.Machine Learning: Science and Technology, 6(3):035010, 2025
work page 2025
-
[27]
A pca-like autoencoder.arXiv preprint arXiv:1904.01277, 2019
Saïd Ladjal, Alasdair Newson, and Chi-Hieu Pham. A pca-like autoencoder.arXiv preprint arXiv:1904.01277, 2019
-
[28]
Runtime configurable deep neural networks for energy-accuracy trade-off
Hokchhay Tann, Soheil Hashemi, R Iris Bahar, and Sherief Reda. Runtime configurable deep neural networks for energy-accuracy trade-off. InProceedings of the eleventh IEEE/acm/ifip International Conference on Hardware/Software Codesign and System Synthesis, pages 1–10, 2016
work page 2016
-
[29]
Nestednet: Learning nested sparse structures in deep neural networks
Eunwoo Kim, Chanho Ahn, and Songhwai Oh. Nestednet: Learning nested sparse structures in deep neural networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8669–8678, 2018
work page 2018
-
[30]
Slimmable neural networks.arXiv preprint arXiv:1812.08928, 2018
Jiahui Yu, Linjie Yang, Ning Xu, Jianchao Yang, and Thomas Huang. Slimmable neural networks.arXiv preprint arXiv:1812.08928, 2018
-
[31]
Once-for-all: Train one network and specialize it for efficient deployment,
Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once-for-all: Train one network and specialize it for efficient deployment.arXiv preprint arXiv:1908.09791, 2019
-
[32]
Mojtaba Valipour, Mehdi Rezagholizadeh, Hossein Rajabzadeh, Parsa Kavehzadeh, Marzieh Tahaei, Boxing Chen, and Ali Ghodsi. Sortednet: A scalable and generalized framework for training modular deep neural networks.arXiv preprint arXiv:2309.00255, 2023
-
[33]
Subnetwork-to-go: Elastic neural network with dynamic training and customizable inference
Kai Li and Yi Luo. Subnetwork-to-go: Elastic neural network with dynamic training and customizable inference. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6775–6779. IEEE, 2024. 12
work page 2024
-
[34]
Yitian Zhang, Huseyin Coskun, Xu Ma, Huan Wang, Ke Ma, Xi Chen, Derek H Hu, and Yun Fu. Slicing vision transformer for flexible inference.Advances in Neural Information Processing Systems, 37:42649–42671, 2024
work page 2024
-
[35]
Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit Dhillon, Yulia Tsvetkov, Hannaneh Hajishirzi, Sham Kakade, Ali Farhadi, and Prateek Jain. Matformer: Nested transformer for elastic inference.Advances in Neural Information Processing Systems, 37: 140535–140564, 2024
work page 2024
-
[36]
Flextron: Many-in-one flexible large language model.arXiv preprint arXiv:2406.10260, 2024
Ruisi Cai, Saurav Muralidharan, Greg Heinrich, Hongxu Yin, Zhangyang Wang, Jan Kautz, and Pavlo Molchanov. Flextron: Many-in-one flexible large language model.arXiv preprint arXiv:2406.10260, 2024
-
[37]
Branchynet: Fast inference via early exiting from deep neural networks
Surat Teerapittayanon, Bradley McDanel, and Hsiang-Tsung Kung. Branchynet: Fast inference via early exiting from deep neural networks. In2016 23rd International Conference on Pattern Recognition (ICPR), pages 2464–2469. IEEE, 2016
work page 2016
-
[38]
Blockdrop: Dynamic inference paths in residual networks
Zuxuan Wu, Tushar Nagarajan, Abhishek Kumar, Steven Rennie, Larry S Davis, Kristen Grauman, and Rogerio Feris. Blockdrop: Dynamic inference paths in residual networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8817– 8826, 2018
work page 2018
-
[39]
Fastbert: a self- distilling bert with adaptive inference time
Weijie Liu, Peng Zhou, Zhiruo Wang, Zhe Zhao, Haotang Deng, and Qi Ju. Fastbert: a self- distilling bert with adaptive inference time. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 6035–6044, 2020
work page 2020
-
[40]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[41]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Uni- versal transformers.arXiv preprint arXiv:1807.03819, 2018
work page internal anchor Pith review arXiv 2018
-
[42]
Accelerating optimization via differentiable stopping time.arXiv preprint arXiv:2505.22509, 2025
Zhonglin Xie, Yiman Fong, Haoran Yuan, and Zaiwen Wen. Accelerating optimization via differentiable stopping time.arXiv preprint arXiv:2505.22509, 2025
-
[43]
Ahmadreza Jeddi, Marco Ciccone, and Babak Taati. Loopformer: Elastic-depth looped trans- formers for latent reasoning via shortcut modulation.arXiv preprint arXiv:2602.11451, 2026
-
[44]
Token Merging: Your ViT But Faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster.arXiv preprint arXiv:2210.09461, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[45]
Adaptive computation with elastic input sequence
Fuzhao Xue, Valerii Likhosherstov, Anurag Arnab, Neil Houlsby, Mostafa Dehghani, and Yang You. Adaptive computation with elastic input sequence. InInternational Conference on Machine Learning, pages 38971–38988. PMLR, 2023
work page 2023
-
[46]
Ali Hojjat, Janek Haberer, Soren Pirk, and Olaf Landsiedel. Thinkingvit: Matryoshka thinking vision transformer for elastic inference.arXiv preprint arXiv:2507.10800, 2025
-
[47]
Elastic MoE: Unlocking the Inference-Time Scalability of Mixture-of-Experts
Naibin Gu, Zhenyu Zhang, Yuchen Feng, Yilong Chen, Peng Fu, Zheng Lin, Shuohuan Wang, Yu Sun, Hua Wu, Weiping Wang, et al. Elastic moe: Unlocking the inference-time scalability of mixture-of-experts.arXiv preprint arXiv:2509.21892, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Yaoxiang Wang, Qingguo Hu, Yucheng Ding, Ruizhe Wang, Yeyun Gong, Jian Jiao, Yelong Shen, Peng Cheng, and Jinsong Su. Training matryoshka mixture-of-experts for elastic inference- time expert utilization.arXiv preprint arXiv:2509.26520, 2025
-
[49]
A- vit: Adaptive tokens for efficient vision transformer
Hongxu Yin, Arash Vahdat, Jose M Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. A- vit: Adaptive tokens for efficient vision transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10809–10818, 2022
work page 2022
-
[50]
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification.Advances in neural information processing systems, 34:13937–13949, 2021. 13
work page 2021
-
[51]
Wenbo Hu, Zi-Yi Dou, Liunian H Li, Amita Kamath, Nanyun Peng, and Kai-Wei Chang. Matryoshka query transformer for large vision-language models.Advances in Neural Information Processing Systems, 37:50168–50188, 2024
work page 2024
-
[52]
Efficient attention: Attention with linear complexities.arXiv preprint arXiv:1812.01243, 2018
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with linear complexities.arXiv preprint arXiv:1812.01243, 2018
-
[53]
Transformers are rnns: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. InInternational Conference on Machine Learning, pages 5156–5165. PMLR, 2020
work page 2020
-
[54]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers.arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[55]
Michael Zhang, Kush Bhatia, Hermann Kumbong, and Christopher Ré. The hedgehog & the porcupine: Expressive linear attentions with softmax mimicry.arXiv preprint arXiv:2402.04347, 2024
-
[56]
RACE Attention: A Strictly Linear-Time Attention Layer for Training on Outrageously Large Contexts
Sahil Joshi, Agniva Chowdhury, Amar Kanakamedala, Ekam Singh, Evan Tu, and Anshumali Shrivastava. Replacing softmax similarity with a sharpened angular similarity: Theory and practice of scaling to billion-context attention.arXiv preprint arXiv:2510.04008, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Zeros: Zero-sum linear attention for efficient transformers.arXiv preprint arXiv:2602.05230, 2026
Jiecheng Lu, Xu Han, Yan Sun, Viresh Pati, Yubin Kim, Siddhartha Somani, and Shihao Yang. Zeros: Zero-sum linear attention for efficient transformers.arXiv preprint arXiv:2602.05230, 2026
-
[58]
Linformer: Self-Attention with Linear Complexity
Sinong Wang, Belinda Z Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity.arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[59]
Nyströmformer: A nyström-based algorithm for approximating self-attention
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nyströmformer: A nyström-based algorithm for approximating self-attention. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 14138–14148, 2021
work page 2021
-
[60]
Reformer: The Efficient Transformer
Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review arXiv 2001
-
[61]
Manzil Zaheer, Guru Guruganesh, Kumar Avinava Dubey, Joshua Ainslie, Chris Alberti, Santi- ago Ontanon, Philip Pham, Anirudh Ravula, Qifan Wang, Li Yang, et al. Big bird: Transformers for longer sequences.Advances in neural information processing systems, 33:17283–17297, 2020
work page 2020
-
[62]
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E Peters, and Arman Cohan. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[63]
Aurko Roy, Mohammad Saffar, Ashish Vaswani, and David Grangier. Efficient content-based sparse attention with routing transformers.Transactions of the Association for Computational Linguistics, 9:53–68, 2021
work page 2021
-
[64]
Star attention: Efficient llm inference over long sequences, arXiv preprint arXiv:2411.17116, 2024
Shantanu Acharya, Fei Jia, and Boris Ginsburg. Star attention: Efficient llm inference over long sequences.arXiv preprint arXiv:2411.17116, 2024
-
[65]
Synthesizer: Rethinking self-attention for transformer models
Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. Synthesizer: Rethinking self-attention for transformer models. InInternational Conference on Machine Learning, pages 10183–10192. PMLR, 2021
work page 2021
-
[66]
Set transformer: A framework for attention-based permutation-invariant neural networks
Juho Lee, Yoonho Lee, Jungtaek Kim, Adam Kosiorek, Seungjin Choi, and Yee Whye Teh. Set transformer: A framework for attention-based permutation-invariant neural networks. In International Conference on Machine Learning, pages 3744–3753. PMLR, 2019
work page 2019
-
[67]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InInternational Conference on Machine Learning, pages 4651–4664. PMLR, 2021. 14
work page 2021
-
[68]
Perceiver io: A general architecture for structured inputs & outputs.ICLR, 2022
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.ICLR, 2022
work page 2022
-
[69]
Latte: Latent attention for linear time transformers
Rares Dolga, Lucas Maystre, Marius Cobzarenco, and David Barber. Latte: Latent attention for linear time transformers. 2024
work page 2024
-
[70]
Xuezhe Ma, Xiang Kong, Sinong Wang, Chunting Zhou, Jonathan May, Hao Ma, and Luke Zettlemoyer. Luna: Linear unified nested attention.Advances in Neural Information Processing Systems, 34:2441–2453, 2021
work page 2021
-
[71]
Arsha Nagrani, Shan Yang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun. Attention bottlenecks for multimodal fusion.Advances in neural information processing systems, 34:14200–14213, 2021
work page 2021
-
[72]
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah A Smith, and Lingpeng Kong. Random feature attention.arXiv preprint arXiv:2103.02143, 2021
-
[73]
Kazuki Irie, Imanol Schlag, Róbert Csordás, and Jürgen Schmidhuber. Going beyond linear transformers with recurrent fast weight programmers.Advances in neural information processing systems, 34:7703–7717, 2021
work page 2021
-
[74]
Albert Gu, Karan Goel, Ankit Gupta, and Christopher Ré. On the parameterization and initialization of diagonal state space models.Advances in neural information processing systems, 35:35971–35983, 2022
work page 2022
-
[75]
Abc: Attention with bounded-memory control
Hao Peng, Jungo Kasai, Nikolaos Pappas, Dani Yogatama, Zhaofeng Wu, Lingpeng Kong, Roy Schwartz, and Noah A Smith. Abc: Attention with bounded-memory control. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7469–7483, 2022
work page 2022
-
[76]
Fine-tuning pre-trained transformers into decaying fast weights
Huanru Henry Mao. Fine-tuning pre-trained transformers into decaying fast weights. In Proceedings of the 2022 conference on empirical methods in natural language processing, pages 10236–10242, 2022
work page 2022
-
[77]
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training.arXiv preprint arXiv:2312.06635, 2023
-
[78]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[79]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[80]
arXiv preprint arXiv:2404.07904 , year=
Zhen Qin, Songlin Yang, Weixuan Sun, Xuyang Shen, Dong Li, Weigao Sun, and Yiran Zhong. Hgrn2: Gated linear rnns with state expansion.arXiv preprint arXiv:2404.07904, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.