Recognition: no theorem link
EgoForce: Forearm-Guided Camera-Space 3D Hand Pose from a Monocular Egocentric Camera
Pith reviewed 2026-05-13 05:19 UTC · model grok-4.3
The pith
EgoForce recovers absolute 3D hand poses from a monocular egocentric camera by guiding with a differentiable forearm representation and unified transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
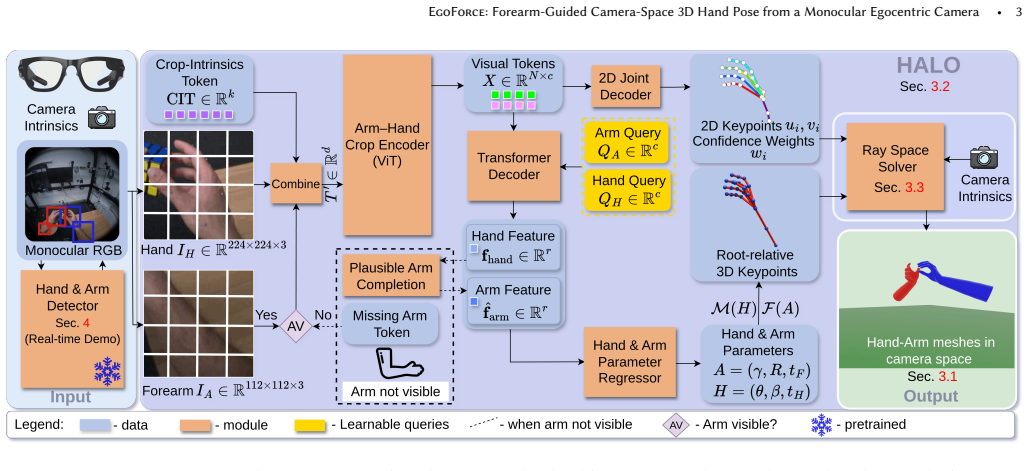
EgoForce is a monocular 3D hand reconstruction framework that recovers robust, absolute 3D hand pose and its position from the user's camera-space viewpoint. It achieves this across fisheye, perspective, and distorted wide-FOV camera models with a single unified network by combining a differentiable forearm representation that stabilizes hand pose, a unified arm-hand transformer that predicts both hand and forearm geometry, and a ray space closed-form solver that enables absolute 3D pose recovery.
What carries the argument
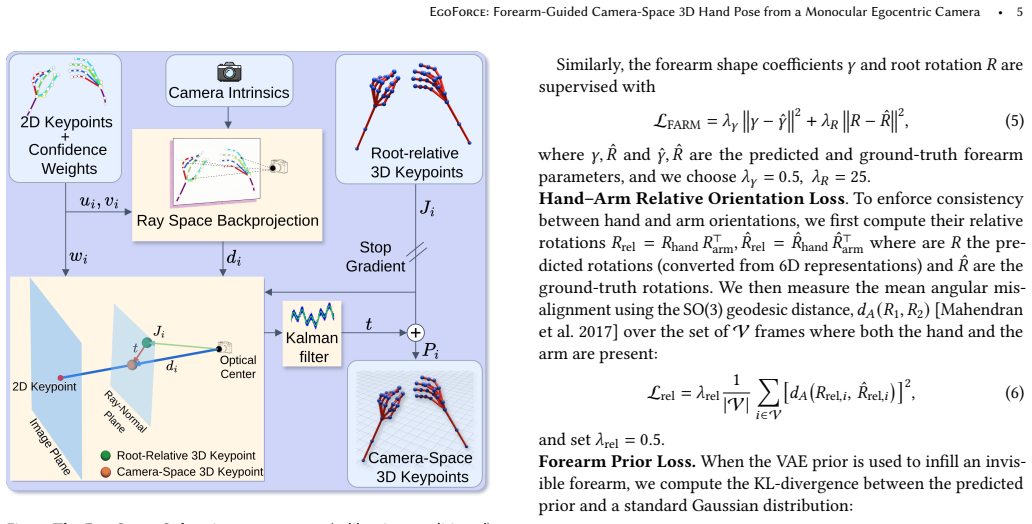
Differentiable forearm representation integrated into a unified arm-hand transformer, together with a ray space closed-form solver, that resolves depth-scale ambiguity to enable absolute 3D recovery.
If this is right
- State-of-the-art accuracy on egocentric 3D hand pose benchmarks.
- Up to 28% reduction in camera-space MPJPE on the HOT3D dataset compared to prior methods.
- Consistent results across fisheye, perspective, and distorted wide-FOV camera configurations.
- Elimination of the need for costly device-specific training datasets for new head-mounted devices.
Where Pith is reading between the lines
- Consumer AR/VR devices could deploy hand tracking more easily without collecting large custom datasets for each hardware variant.
- Similar forearm guidance might improve other monocular egocentric estimations such as full-body or object pose tracking.
- Integration with existing VR systems could enable more natural hand-centric interactions in telepresence without additional sensors.
Load-bearing premise
That the forearm representation and arm-hand transformer together provide sufficient information to resolve depth-scale ambiguity for accurate absolute 3D hand poses across diverse camera models.
What would settle it
An experiment where the reported MPJPE reduction on HOT3D is not observed or where performance degrades significantly on a previously unseen head-mounted camera model.
Figures















read the original abstract
Reconstructing the absolute 3D pose and shape of the hands from the user's viewpoint using a single head-mounted camera is crucial for practical egocentric interaction in AR/VR, telepresence, and hand-centric manipulation tasks, where sensing must remain compact and unobtrusive. While monocular RGB methods have made progress, they remain constrained by depth-scale ambiguity and struggle to generalize across the diverse optical configurations of head-mounted devices. As a result, models typically require extensive training on device-specific datasets, which are costly and laborious to acquire. This paper addresses these challenges by introducing EgoForce, a monocular 3D hand reconstruction framework that recovers robust, absolute 3D hand pose and its position from the user's (camera-space) viewpoint. EgoForce operates across fisheye, perspective, and distorted wide-FOV camera models using a single unified network. Our approach combines a differentiable forearm representation that stabilizes hand pose, a unified arm-hand transformer that predicts both hand and forearm geometry from a single egocentric view, mitigating depth-scale ambiguity, and a ray space closed-form solver that enables absolute 3D pose recovery across diverse head-mounted camera models. Experiments on three egocentric benchmarks show that EgoForce achieves state-of-the-art 3D accuracy, reducing camera-space MPJPE by up to 28% on the HOT3D dataset compared to prior methods and maintaining consistent performance across camera configurations. For more details, visit the project page at https://dfki-av.github.io/EgoForce.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EgoForce, a monocular framework for absolute 3D hand pose and shape reconstruction from egocentric RGB images captured by head-mounted cameras. It proposes a differentiable forearm representation to stabilize pose, a unified arm-hand transformer to predict hand and forearm geometry jointly, and a ray-space closed-form solver to recover absolute 3D coordinates. The method claims to operate across fisheye, perspective, and distorted wide-FOV models using a single network without device-specific training data. Experiments on three egocentric benchmarks report state-of-the-art camera-space MPJPE, with up to 28% reduction on HOT3D and consistent cross-configuration performance.
Significance. If the cross-camera robustness and absolute recovery claims hold, the work would be significant for practical AR/VR and egocentric interaction systems by lowering the barrier of device-specific data collection. The forearm-guided stabilization and ray-space solver represent a concrete attempt to address depth-scale ambiguity in a unified manner, which could influence future monocular egocentric pipelines if the technical details are clarified.
major comments (2)
- [Abstract / Methods] Abstract and methods (ray-space solver description): The claim that the closed-form ray-space solver enables absolute 3D recovery across fisheye, perspective, and wide-FOV models without per-device training is load-bearing for the generalization result, yet the abstract provides no explicit mechanism for incorporating nonlinear distortion (e.g., equidistant or polynomial models) into the solver. This leaves open whether the solver assumes known intrinsics per model or relies on implicit learning that would require device-specific data, directly affecting the weakest assumption identified in the review.
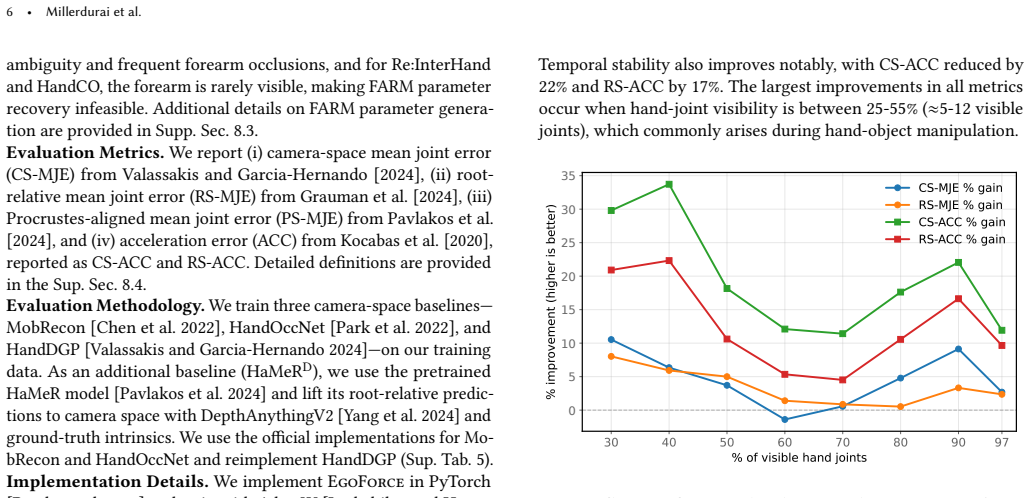
- [Experiments] Experiments section: The reported up to 28% MPJPE reduction on HOT3D and consistent performance across camera configurations are central to the SOTA claim, but the abstract lacks ablations isolating the forearm representation and unified transformer contributions, as well as error bars or training data details. Without these, it is not possible to confirm that the gains are not due to post-hoc tuning or dataset-specific factors, undermining verification of the cross-configuration robustness.
minor comments (1)
- [Abstract] The project page link is provided but no supplementary material or code release is mentioned in the abstract; including a link to reproducible implementation would strengthen the submission.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments help clarify key aspects of our claims regarding generalization and experimental validation. We address each major comment point by point below with explanations and commitments to revisions where they improve the manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods (ray-space solver description): The claim that the closed-form ray-space solver enables absolute 3D recovery across fisheye, perspective, and wide-FOV models without per-device training is load-bearing for the generalization result, yet the abstract provides no explicit mechanism for incorporating nonlinear distortion (e.g., equidistant or polynomial models) into the solver. This leaves open whether the solver assumes known intrinsics per model or relies on implicit learning that would require device-specific data, directly affecting the weakest assumption identified in the review.
Authors: We appreciate the referee highlighting the need for explicit clarification on this central mechanism. The ray-space solver is a closed-form geometric method that takes the network's predictions (2D image-plane locations of hand joints and forearm parameters) and lifts them to absolute camera-space 3D coordinates by casting rays according to the camera's intrinsic model. This explicitly incorporates nonlinear distortion parameters (equidistant fisheye, polynomial, or perspective) using the known intrinsics provided at inference time; no implicit learning or device-specific retraining is involved. The network itself is trained once on mixed egocentric data and produces outputs in a normalized image space that is independent of the specific distortion. This is fully detailed in Section 3.3. To strengthen the abstract's presentation of the generalization claim, we will add a brief clause noting that the solver uses known camera intrinsics to handle diverse distortion models. revision: yes
-
Referee: [Experiments] Experiments section: The reported up to 28% MPJPE reduction on HOT3D and consistent performance across camera configurations are central to the SOTA claim, but the abstract lacks ablations isolating the forearm representation and unified transformer contributions, as well as error bars or training data details. Without these, it is not possible to confirm that the gains are not due to post-hoc tuning or dataset-specific factors, undermining verification of the cross-configuration robustness.
Authors: We agree that isolating component contributions and providing statistical details are essential for verifying the source of the reported gains. Ablations isolating the differentiable forearm representation and the unified arm-hand transformer are already presented in the experiments section (Section 4.4), with quantitative breakdowns showing their individual effects on camera-space accuracy. Error bars (standard deviation over three random seeds) are included in the main results tables and figures, and training data details—including dataset sizes, camera models, and splits—are described in Section 4.1. Note that space constraints preclude placing full ablations in the abstract; they belong in the experiments section. To further address the concern, we will add a compact training-data summary table and ensure error bars are explicitly referenced in the text discussing cross-configuration results. These changes will make it easier to confirm that the up to 28% MPJPE reduction on HOT3D and consistent performance arise from the proposed components rather than dataset-specific factors. revision: partial
Circularity Check
No significant circularity in EgoForce derivation
full rationale
The paper introduces novel architectural components (differentiable forearm representation, unified arm-hand transformer, ray-space closed-form solver) to address depth-scale ambiguity and enable unified handling across camera models. These are presented as new mechanisms rather than reductions of outputs to fitted inputs or self-citations. SOTA claims rest on external benchmark experiments (HOT3D and others) that provide independent validation, with no equations or steps in the abstract reducing predictions to prior fits by construction. The framework is self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A differentiable forearm representation stabilizes hand pose estimation
- domain assumption A unified arm-hand transformer can predict both hand and forearm geometry from a single egocentric view
Reference graph
Works this paper leans on
-
[1]
Introducing HOT3D: An Egocentric Dataset for 3D Hand and Object Tracking , author=. arXiv preprint arXiv:2406.09598 , year=
-
[2]
and Hilliges, Otmar , booktitle =
Fan, Zicong and Taheri, Omid and Tzionas, Dimitrios and Kocabas, Muhammed and Kaufmann, Manuel and Black, Michael J. and Hilliges, Otmar , booktitle =
-
[3]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Kwon, Taein and Tekin, Bugra and St\"uhmer, Jan and Bogo, Federica and Pollefeys, Marc , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
work page 2021
-
[4]
Pavlakos, Georgios and Shan, Dandan and Radosavovic, Ilija and Kanazawa, Angjoo and Fouhey, David and Malik, Jitendra , booktitle=. Reconstructing Hands in 3
-
[5]
WiLoR: End-to-end 3D Hand Localization and Reconstruction in-the-wild , author=. 2024 , eprint=
work page 2024
-
[6]
27th International Conference on Neural Information Processing (ICONIP) , year =
MobileHand: Real-time 3D Hand Shape and Pose Estimation from Color Image , author =. 27th International Conference on Neural Information Processing (ICONIP) , year =
- [7]
- [8]
-
[9]
arXiv preprint arXiv:2501.02973 , year=
HaWoR: World-Space Hand Motion Reconstruction from Egocentric Videos , author=. arXiv preprint arXiv:2501.02973 , year=
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vibe: Video inference for human body pose and shape estimation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Deformer: Dynamic fusion transformer for robust hand pose estimation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Beyond static features for temporally consistent 3d human pose and shape from a video , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
ACM Transactions on Graphics, (Proc
Embodied Hands: Modeling and Capturing Hands and Bodies Together , author =. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia) , volume =. 2017 , month_numeric =
work page 2017
-
[14]
RTMDet: An Empirical Study of Designing Real-Time Object Detectors , author=. 2022 , eprint=
work page 2022
-
[15]
European Conference on Computer Vision , pages=
3D hand pose estimation in everyday egocentric images , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
End-to-end recovery of human shape and pose , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[17]
European Conference on Computer Vision (ECCV) , year =
Moon, Gyeongsik and Lee, Kyoung Mu , title =. European Conference on Computer Vision (ECCV) , year =
-
[18]
The IEEE Conference on International Conference on Computer Vision (ICCV) , year =
Moon, Gyeongsik and Chang, Juyong and Lee, Kyoung Mu , title =. The IEEE Conference on International Conference on Computer Vision (ICCV) , year =
-
[19]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Towards accurate alignment in real-time 3d hand-mesh reconstruction , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[20]
Proceedings of Computer Vision and Pattern Recognition (
Mueller, Franziska and Bernard, Florian and Sotnychenko, Oleksandr and Mehta, Dushyant and Sridhar, Srinath and Casas, Dan and Theobalt, Christian , title =. Proceedings of Computer Vision and Pattern Recognition (
-
[21]
Proceedings of the European conference on computer vision (ECCV) , pages=
Hand pose estimation via latent 2.5 d heatmap regression , author=. Proceedings of the European conference on computer vision (ECCV) , pages=
-
[22]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Zhou, Yuxiao and Habermann, Marc and Xu, Weipeng and Habibie, Ikhsanul and Theobalt, Christian and Xu, Feng , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Neural voting field for camera-space 3D hand pose estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Park, JoonKyu and Oh, Yeonguk and Moon, Gyeongsik and Choi, Hongsuk and Lee, Kyoung Mu , title =. Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[25]
Valassakis, Eugene and Garcia-Hernando, Guillermo , booktitle=
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Camera-Space Hand Mesh Recovery via Semantic Aggregationand Adaptive 2D-1D Registration , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[27]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[28]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Spectral graphormer: Spectral graph-based transformer for egocentric two-hand reconstruction using multi-view color images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatial-temporal parallel transformer for arm-hand dynamic estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[30]
Applied Intelligence , volume=
Enhancing 3D hand pose estimation using SHaF: synthetic hand dataset including a forearm , author=. Applied Intelligence , volume=. 2024 , publisher=
work page 2024
-
[31]
and Pons-Moll, Gerard and Black, Michael J
Mahmood, Naureen and Ghorbani, Nima and Troje, Nikolaus F. and Pons-Moll, Gerard and Black, Michael J. , booktitle =. 2019 , month_numeric =
work page 2019
-
[32]
IEEE International Conference on Computer Vision (ICCV) , year =
Christian Zimmermann, Duygu Ceylan, Jimei Yang, Bryan Russel, Max Argus and Thomas Brox , title =. IEEE International Conference on Computer Vision (ICCV) , year =
-
[33]
Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology , pages=
TouchInsight: Uncertainty-aware Rapid Touch and Text Input for Mixed Reality from Egocentric Vision , author=. Proceedings of the 37th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[34]
SIGGRAPH Asia 2022 conference papers , pages=
UmeTrack: Unified multi-view end-to-end hand tracking for VR , author=. SIGGRAPH Asia 2022 conference papers , pages=
work page 2022
-
[35]
IEEE Transactions on Visualization and Computer Graphics , volume=
Controllers or bare hands? a controlled evaluation of input techniques on interaction performance and exertion in virtual reality , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2023 , publisher=
work page 2023
-
[36]
ACM SIGGRAPH 2022 Conference Proceedings , pages=
Neuralpassthrough: Learned real-time view synthesis for vr , author=. ACM SIGGRAPH 2022 Conference Proceedings , pages=
work page 2022
-
[37]
arXiv preprint arXiv:2503.05456 , year=
PinchCatcher: Enabling Multi-selection for Gaze+ Pinch , author=. arXiv preprint arXiv:2503.05456 , year=
-
[38]
Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pages=
Atatouch: Robust finger pinch detection for a vr controller using rf return loss , author=. Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems , pages=
work page 2021
-
[39]
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=
Uni-slam: Uncertainty-aware neural implicit slam for real-time dense indoor scene reconstruction , author=. 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , pages=. 2025 , organization=
work page 2025
-
[40]
Army Personnel: Summary Statistics , author =
1988 Anthropometric Survey of U.S. Army Personnel: Summary Statistics , author =. 1989 , number =
work page 1988
-
[41]
International Conference on Learning Representations (ICLR) , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. International Conference on Learning Representations (ICLR) , year =
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Learning structured output representation using deep conditional generative models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Vitpose: Simple vision transformer baselines for human pose estimation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[44]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Keypoint transformer: Solving joint identification in challenging hands and object interactions for accurate 3d pose estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[45]
Ridge regression: Biased estimation for nonorthogonal problems , author=. Technometrics , volume=. 1970 , publisher=
work page 1970
-
[46]
Proceedings of the IEEE international conference on computer vision , pages=
Real-time hand tracking under occlusion from an egocentric rgb-d sensor , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[47]
On the continuity of rotation representations in neural networks. 2019 IEEE , author=. CVF Conference on Computer Vision and Pattern Recognition (CVPR) , volume=
work page 2019
-
[48]
Proceedings of the IEEE international conference on computer vision workshops , pages=
3d pose regression using convolutional neural networks , author=. Proceedings of the IEEE international conference on computer vision workshops , pages=
-
[49]
arXiv preprint arXiv:2011.07252 , year=
Ego2hands: A dataset for egocentric two-hand segmentation and detection , author=. arXiv preprint arXiv:2011.07252 , year=
-
[50]
HOT3D: Hand and Object Tracking in 3D from Egocentric Multi-View Videos , author=. 2025 , eprint=
work page 2025
-
[51]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Single-to-dual-view adaptation for egocentric 3d hand pose estimation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[53]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Project Aria: A New Tool for Egocentric Multi-Modal AI Research , author=. 2023 , eprint=
work page 2023
- [55]
-
[56]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[57]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
work page 2019
-
[58]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Linear pose estimation from points or lines , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2003 , publisher=
work page 2003
-
[59]
2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003
Using many cameras as one , author=. 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings. , volume=. 2003 , organization=
work page 2003
-
[60]
Deep Residual Learning for Image Recognition , author=. 2015 , eprint=
work page 2015
-
[61]
Computer Vision and Pattern Recognition (CVPR) , year =
HOnnotate: A method for 3D Annotation of Hand and Object Poses , author=. Computer Vision and Pattern Recognition (CVPR) , year =
-
[62]
Computer Vision and Pattern Recognition (CVPR) , year=
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[63]
arXiv preprint arXiv:2406.12219 , year=
PCIE\_EgoHandPose Solution for EgoExo4D Hand Pose Challenge , author=. arXiv preprint arXiv:2406.12219 , year=
-
[64]
Computer Vision and Pattern Recognition (CVPR) , year=
Learning 3d human dynamics from video , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[65]
German Conference on Pattern Recognition (DAGM ) , year=
Contrastive representation learning for hand shape estimation , author=. German Conference on Pattern Recognition (DAGM ) , year=
-
[66]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Depth anything v2 , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[67]
arXiv preprint arXiv:2501.08329 , year=
Predicting 4d hand trajectory from monocular videos , author=. arXiv preprint arXiv:2501.08329 , year=
-
[68]
European Conference on Computer Vision (ECCV) , year=
Mlphand: real time multi-view 3d hand reconstruction via mlp modeling , author=. European Conference on Computer Vision (ECCV) , year=
-
[69]
Computer Vision and Pattern Recognition (CVPR) , year=
Dyn-hamr: Recovering 4d interacting hand motion from a dynamic camera , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[70]
Nationwide stature estimation from forearm length measurements in Montenegrin adolescents , author=. Int. j. morphol , volume=
-
[71]
Analysis of hand-forearm anthropometric components in assessing handgrip and pinch strengths of school-aged children and adolescents: a partial least squares (PLS) approach , author=. BMC pediatrics , volume=. 2021 , publisher=
work page 2021
-
[72]
European Conference on Computer Vision (ECCV) , year=
Upnp: An optimal o (n) solution to the absolute pose problem with universal applicability , author=. European Conference on Computer Vision (ECCV) , year=
-
[73]
Computer Vision and Pattern Recognition (CVPR) , year=
End-to-end learnable geometric vision by backpropagating pnp optimization , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[74]
Computer Vision and Pattern Recognition (CVPR) , year=
AnyCalib: On-manifold learning for model-agnostic single-view camera calibration , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[75]
Unity Real-Time Development Platform , year =
-
[76]
International Conference on 3D Vision (3DV) , year=
3D Pose Estimation of Two Interacting Hands from a Monocular Event Camera , author=. International Conference on 3D Vision (3DV) , year=
-
[77]
International Journal of Computer Vision (IJCV) , year=
Millerdurai, Christen and Akada, Hiroyasu and Wang, Jian and Luvizon, Diogo and Pagani, Alain and Stricker, Didier and Theobalt, Christian and Golyanik, Vladislav , title=. International Journal of Computer Vision (IJCV) , year=
-
[78]
Computer Vision and Pattern Recognition (CVPR) , year=
EventEgo3D: 3D Human Motion Capture from Egocentric Event Streams , author=. Computer Vision and Pattern Recognition (CVPR) , year=
-
[79]
The Computational Geometry Algorithms Library , author =
-
[80]
Menelaos Karavelas , subtitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.