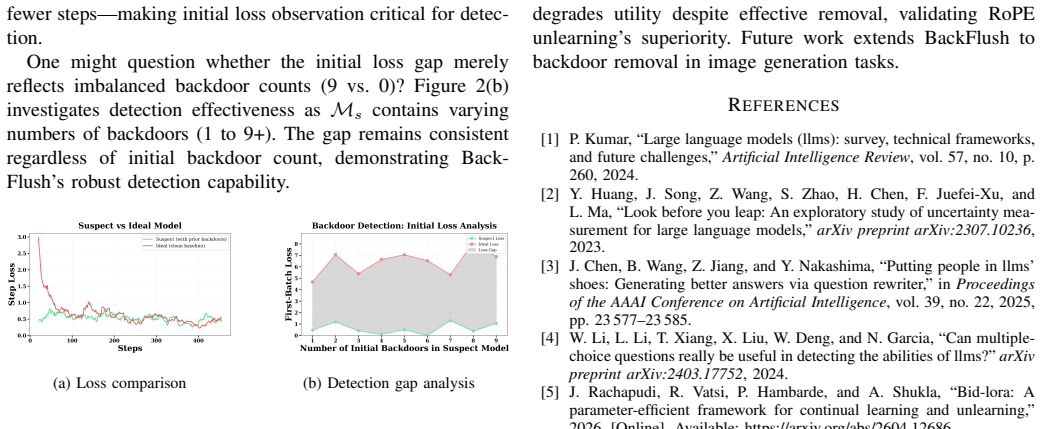
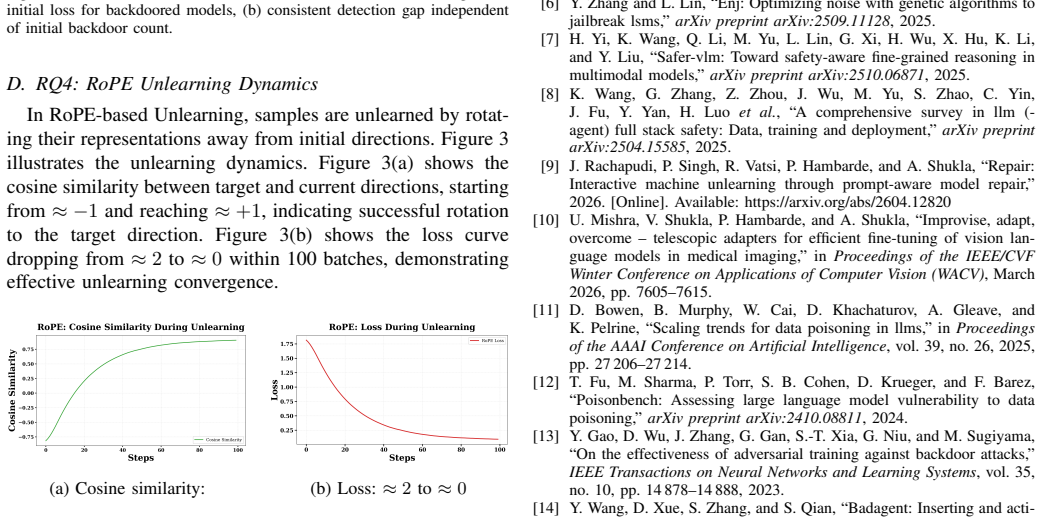
Recognition: unknown
BackFlush: Knowledge-Free Backdoor Detection and Elimination with Watermark Preservation in Large Language Models
Pith reviewed 2026-05-14 20:57 UTC · model grok-4.3
The pith
BackFlush detects unknown backdoors in LLMs by amplifying susceptibility and flushes them via embedding rotation while preserving watermarks and clean accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that injecting auxiliary data and then applying unlearning eliminates pre-existing backdoors (Backdoor Flushing Phenomenon) and that susceptibility amplification permits constant-time detection independent of vocabulary size (Backdoor Susceptibility Amplification). RoPE Unlearning performs rotation-based parameter editing on embeddings to remove backdoors while leaving watermarking intact. Across multiple trigger types and architectures, the resulting models show approximately 1 percent attack success rate, approximately 99 percent clean accuracy, and watermark performance comparable to clean baselines, outcomes not simultaneously achieved by existing methods.
What carries the argument
RoPE Unlearning, a rotation-based parameter editing technique that rotates embeddings to selectively eliminate backdoors without damaging watermarks.
If this is right
- Backdoors can be detected and removed without any prior knowledge of the trigger or payload.
- Watermark verification remains functional after the defense is applied.
- Model utility on clean inputs stays comparable to an uncompromised baseline.
- Detection runs in time independent of vocabulary size.
- The same pipeline works across varied trigger designs and LLM architectures.
Where Pith is reading between the lines
- The approach could allow safe reuse of models downloaded from public repositories without trusted training histories.
- Similar rotation edits might apply to other embedding-space tampering such as prompt injection patterns.
- Testing on multimodal models would reveal whether the flushing phenomenon generalizes beyond text-only LLMs.
Load-bearing premise
The Backdoor Flushing Phenomenon and Backdoor Susceptibility Amplification are assumed to apply to unknown backdoors regardless of trigger type or model architecture.
What would settle it
A backdoor that remains active with high attack success rate after RoPE Unlearning is applied, or a watermark whose verification accuracy drops substantially while the backdoor is removed.
Figures

read the original abstract
In recent trends, one can observe Large Language Models (LLMs) are exposed to backdoor attacks where vicious triggers added during training or model editing to elicit harmful outputs on specific input patterns while maintaining clean performance on normal inputs. Legitimate watermarks used as ownership signatures share similar mechanisms to backdoors, creating a critical challenge: detecting and eliminating unknown backdoors without compromising watermark integrity. Existing defenses require prior knowledge of triggers or their payloads, depend on clean reference models, or sacrifice model utility without preserving the watermark. To address these limitations we introduce BackFlush and its variants, a unified framework for backdoor detection and elimination while preserving watermarks. We establish two novel observations: Backdoor Flushing Phenomenon, where injecting and unlearning auxiliary data eliminates pre established backdoors, and Backdoor Susceptibility Amplification, enabling constant time detection independent of vocabulary size. BackFlush employs Rotation based Parameter Editing (RoPE) Unlearning, a technique that preserves watermarks while eliminating backdoors by rotating the embeddings. Comprehensive evaluation across diverse trigger types over different architectures demonstrates BackFlush achieves approximately 1%Attack Success Rate (ASR), approximately 99% clean accuracy (CACC), and preserved watermarking capabilities in the realm where no existing method simultaneously provides these alongside maintaining model utility comparable to clean baselines. Codes are available at https://github.com/JagadeeshAI/BackFlush IJCNN.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BackFlush, a unified framework for detecting and eliminating unknown backdoors in large language models while preserving watermarks. It relies on two novel observations: the Backdoor Flushing Phenomenon, where injecting and unlearning auxiliary data removes pre-established backdoors, and Backdoor Susceptibility Amplification for constant-time detection. The method uses Rotation based Parameter Editing (RoPE) Unlearning to rotate embeddings, achieving approximately 1% attack success rate (ASR), 99% clean accuracy (CACC), and preserved watermarking capabilities across diverse triggers and architectures, with code available on GitHub.
Significance. If the empirical results hold generally, this would be a significant contribution to LLM security, offering a knowledge-free approach that balances backdoor removal, watermark preservation, and model utility—properties not simultaneously achieved by existing defenses that often require trigger knowledge or clean references.
major comments (3)
- [Abstract] Abstract: the strong numerical claims of approximately 1% ASR and 99% CACC are stated without reference to experimental details, baselines, ablation studies, or statistical tests, which is load-bearing for verifying the central performance and superiority assertions.
- [Backdoor Flushing Phenomenon] Backdoor Flushing Phenomenon description: the claim that auxiliary-data injection eliminates arbitrary unknown backdoors lacks any derivation, invariant, or analysis showing why this holds when an adversary designs the backdoor to resist such flushing; this underpins the knowledge-free guarantee.
- [RoPE Unlearning] RoPE Unlearning: the assertion that embedding rotation selectively removes backdoors while preserving watermarks (despite shared mechanisms) provides no distinguishing invariant or mechanism, risking that the ~1% ASR / watermark-preservation outcome is specific to the tested trigger types rather than general.
minor comments (1)
- [Abstract] Abstract: the provided GitHub URL contains a space (https://github.com/JagadeeshAI/BackFlush IJCNN.git) and should be corrected for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below and will revise the manuscript accordingly to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the strong numerical claims of approximately 1% ASR and 99% CACC are stated without reference to experimental details, baselines, ablation studies, or statistical tests, which is load-bearing for verifying the central performance and superiority assertions.
Authors: We agree that the abstract would benefit from additional context. In the revision, we will add brief references to the experimental setup (models, datasets, and multiple runs with reported standard deviations) and direct readers to the relevant sections detailing baselines, ablations, and statistical tests. revision: yes
-
Referee: [Backdoor Flushing Phenomenon] Backdoor Flushing Phenomenon description: the claim that auxiliary-data injection eliminates arbitrary unknown backdoors lacks any derivation, invariant, or analysis showing why this holds when an adversary designs the backdoor to resist such flushing; this underpins the knowledge-free guarantee.
Authors: The phenomenon is presented as an empirical observation validated across diverse attacks and architectures in our experiments. We will add a dedicated analysis subsection discussing robustness to potential adversarial designs, including further empirical tests, though a formal theoretical invariant is not derived in the current work. revision: partial
-
Referee: [RoPE Unlearning] RoPE Unlearning: the assertion that embedding rotation selectively removes backdoors while preserving watermarks (despite shared mechanisms) provides no distinguishing invariant or mechanism, risking that the ~1% ASR / watermark-preservation outcome is specific to the tested trigger types rather than general.
Authors: We will expand the RoPE Unlearning section with additional embedding-space analysis, visualizations, and experiments on a broader set of trigger types to better articulate the selectivity mechanism and demonstrate generality beyond the tested cases. revision: yes
Circularity Check
No circularity: empirical observations validated by evaluation
full rationale
The paper presents BackFlush as a framework resting on two novel empirical observations (Backdoor Flushing Phenomenon and Backdoor Susceptibility Amplification) discovered through experimentation, followed by RoPE Unlearning for selective removal. These are not derived from equations or prior self-citations but are stated as observations confirmed across diverse trigger types and architectures, with performance metrics (~1% ASR, ~99% CACC, watermark preservation) reported from direct evaluation. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear; the central claims remain independent of the inputs by construction and are externally falsifiable via the described experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Backdoor Flushing Phenomenon holds across unknown triggers and architectures
Reference graph
Works this paper leans on
-
[1]
Large language models (llms): survey, technical frameworks, and future challenges,
P. Kumar, “Large language models (llms): survey, technical frameworks, and future challenges,”Artificial Intelligence Review, vol. 57, no. 10, p. 260, 2024
2024
-
[2]
Look before you leap: An exploratory study of uncertainty mea- surement for large language models,
Y . Huang, J. Song, Z. Wang, S. Zhao, H. Chen, F. Juefei-Xu, and L. Ma, “Look before you leap: An exploratory study of uncertainty mea- surement for large language models,”arXiv preprint arXiv:2307.10236, 2023
-
[3]
Putting people in llms’ shoes: Generating better answers via question rewriter,
J. Chen, B. Wang, Z. Jiang, and Y . Nakashima, “Putting people in llms’ shoes: Generating better answers via question rewriter,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 577–23 585
2025
-
[4]
Can multiple- choice questions really be useful in detecting the abilities of llms?
W. Li, L. Li, T. Xiang, X. Liu, W. Deng, and N. Garcia, “Can multiple- choice questions really be useful in detecting the abilities of llms?”arXiv preprint arXiv:2403.17752, 2024
-
[5]
Bid-lora: A parameter-efficient framework for continual learning and unlearning,
J. Rachapudi, R. Vatsi, P. Hambarde, and A. Shukla, “Bid-lora: A parameter-efficient framework for continual learning and unlearning,”
-
[6]
BID-LoRA: A Parameter-Efficient Framework for Continual Learning and Unlearning
[Online]. Available: https://arxiv.org/abs/2604.12686
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Enj: Optimizing noise with genetic algorithms to jailbreak lsms,
Y . Zhang and L. Lin, “Enj: Optimizing noise with genetic algorithms to jailbreak lsms,”arXiv preprint arXiv:2509.11128, 2025
-
[8]
Safer-vlm: Toward safety-aware fine-grained reasoning in multimodal models,
H. Yi, K. Wang, Q. Li, M. Yu, L. Lin, G. Xi, H. Wu, X. Hu, K. Li, and Y . Liu, “Safer-vlm: Toward safety-aware fine-grained reasoning in multimodal models,”arXiv preprint arXiv:2510.06871, 2025
-
[9]
K. Wang, G. Zhang, Z. Zhou, J. Wu, M. Yu, S. Zhao, C. Yin, J. Fu, Y . Yan, H. Luoet al., “A comprehensive survey in llm (- agent) full stack safety: Data, training and deployment,”arXiv preprint arXiv:2504.15585, 2025
-
[10]
Repair: Interactive machine unlearning through prompt-aware model repair,
J. Rachapudi, P. Singh, R. Vatsi, P. Hambarde, and A. Shukla, “Repair: Interactive machine unlearning through prompt-aware model repair,”
-
[11]
RePAIR: Interactive Machine Unlearning through Prompt-Aware Model Repair
[Online]. Available: https://arxiv.org/abs/2604.12820
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Improvise, adapt, overcome – telescopic adapters for efficient fine-tuning of vision lan- guage models in medical imaging,
U. Mishra, V . Shukla, P. Hambarde, and A. Shukla, “Improvise, adapt, overcome – telescopic adapters for efficient fine-tuning of vision lan- guage models in medical imaging,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), March 2026, pp. 7605–7615
2026
-
[13]
Scaling trends for data poisoning in llms,
D. Bowen, B. Murphy, W. Cai, D. Khachaturov, A. Gleave, and K. Pelrine, “Scaling trends for data poisoning in llms,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 26, 2025, pp. 27 206–27 214
2025
-
[14]
Poisonbench: Assessing large language model vulnerability to data poisoning,
T. Fu, M. Sharma, P. Torr, S. B. Cohen, D. Krueger, and F. Barez, “Poisonbench: Assessing large language model vulnerability to data poisoning,”arXiv preprint arXiv:2410.08811, 2024
-
[15]
On the effectiveness of adversarial training against backdoor attacks,
Y . Gao, D. Wu, J. Zhang, G. Gan, S.-T. Xia, G. Niu, and M. Sugiyama, “On the effectiveness of adversarial training against backdoor attacks,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 10, pp. 14 878–14 888, 2023
2023
-
[16]
Badagent: Inserting and acti- vating backdoor attacks in llm agents,
Y . Wang, D. Xue, S. Zhang, and S. Qian, “Badagent: Inserting and acti- vating backdoor attacks in llm agents,”arXiv preprint arXiv:2406.03007, 2024
-
[17]
Best-of-Venom: Attacking RLHF by Injecting Poi- soned Preference Data.CoRR, abs/2404.05530,
T. Baumg ¨artner, Y . Gao, D. Alon, and D. Metzler, “Best-of-venom: Attacking rlhf by injecting poisoned preference data,”arXiv preprint arXiv:2404.05530, 2024
-
[18]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
E. Hubinger, C. Denison, J. Mu, M. Lambert, M. Tong, M. MacDiarmid, T. Lanham, D. M. Ziegler, T. Maxwell, N. Chenget al., “Sleeper agents: Training deceptive llms that persist through safety training,” arXiv preprint arXiv:2401.05566, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
A survey on in-context learning,
Q. Dong, L. Li, D. Dai, C. Zheng, J. Ma, R. Li, H. Xia, J. Xu, Z. Wu, B. Changet al., “A survey on in-context learning,” inProceedings of the 2024 conference on empirical methods in natural language processing, 2024, pp. 1107–1128
2024
-
[20]
Semicvt: Semi-supervised convolutional vision transformer for semantic segmentation,
H. Huang, S. Xie, L. Lin, R. Tong, Y .-W. Chen, Y . Li, H. Wang, Y . Huang, and Y . Zheng, “Semicvt: Semi-supervised convolutional vision transformer for semantic segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 11 340–11 349
2023
-
[21]
Badnets: Evaluating backdooring attacks on deep neural networks,
T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, “Badnets: Evaluating backdooring attacks on deep neural networks,”Ieee Access, vol. 7, pp. 47 230–47 244, 2019
2019
-
[22]
J. Kong, H. Fang, X. Yang, K. Gao, B. Chen, S.-T. Xia, Y . Wang, and M. Zhang, “Wolf hidden in sheep’s conversations: Toward harmless data- based backdoor attacks for jailbreaking large language models,”arXiv preprint arXiv:2505.17601, 2025
-
[23]
Megen: Generative back- door in large language models via model editing,
J. Qiu, X. Ma, Z. Zhang, and H. Zhao, “Megen: Generative back- door in large language models via model editing,”arXiv preprint arXiv:2408.10722, 2024
-
[24]
Badedit: Backdooring large language models by model editing,
Y . Li, T. Li, K. Chen, J. Zhang, S. Liu, W. Wang, T. Zhang, and Y . Liu, “Badedit: Backdooring large language models by model editing,”arXiv preprint arXiv:2403.13355, 2024
-
[25]
Confguard: A simple and effective backdoor detection for large lan- guage models,
Z. Wang, R. Zhang, H. Li, W. Fan, W. Jiang, Q. Zhao, and G. Xu, “Confguard: A simple and effective backdoor detection for large lan- guage models,”arXiv preprint arXiv:2508.01365, 2025
-
[26]
Pots: Proof-of-training-steps for backdoor detection in large language mod- els,
I. Seddik, S. Souihi, M. Tamaazousti, and S. T. Piergiovanni, “Pots: Proof-of-training-steps for backdoor detection in large language mod- els,”arXiv preprint arXiv:2510.15106, 2025
-
[27]
Simulate and eliminate: Revoke backdoors for generative large lan- guage models,
H. Li, Y . Chen, Z. Zheng, Q. Hu, C. Chan, H. Liu, and Y . Song, “Simulate and eliminate: Revoke backdoors for generative large lan- guage models,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 1, 2025, pp. 397–405
2025
-
[28]
Fine-mixing: Mitigating backdoors in fine-tuned language models
Z. Zhang, L. Lyu, X. Ma, C. Wang, and X. Sun, “Fine-mixing: Mitigating backdoors in fine-tuned language models,”arXiv preprint arXiv:2210.09545, 2022
-
[29]
Here’s a free lunch: Sanitizing backdoored models with model merge,
A. Arora, X. He, M. Mozes, S. Swain, M. Dras, and Q. Xu, “Here’s a free lunch: Sanitizing backdoored models with model merge,”arXiv preprint arXiv:2402.19334, 2024
-
[30]
Beear: Embedding-based adversarial removal of safety backdoors in instruction- tuned language models,
Y . Zeng, W. Sun, T. Huynh, D. Song, B. Li, and R. Jia, “Beear: Embedding-based adversarial removal of safety backdoors in instruction- tuned language models,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 13 189– 13 215
2024
-
[31]
Neutralizing backdoors through information conflicts for large language models,
C. Chen, Y . Sun, X. Gong, J. Gao, and K.-Y . Lam, “Neutralizing backdoors through information conflicts for large language models,” arXiv preprint arXiv:2411.18280, 2024
-
[32]
Backdoor Collapse: Eliminating Unknown Threats via Known Backdoor Aggregation in Language Models
L. Lin, M. Yu, M. Aloqaily, Z. Zhou, K. Wang, L. Pang, P. Mehro- tra, and Q. Wen, “Backdoor collapse: Eliminating unknown threats via known backdoor aggregation in language models,”arXiv preprint arXiv:2510.10265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Unlearning backdoor attacks for llms with weak-to-strong knowl- edge distillation,
S. Zhao, X. Wu, C.-D. T. Nguyen, Y . Jia, M. Jia, F. Yichao, and L. A. Tuan, “Unlearning backdoor attacks for llms with weak-to-strong knowl- edge distillation,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 4937–4952
2025
-
[34]
Cater: Intellectual property protection on text generation apis via conditional watermarks,
X. He, Q. Xu, Y . Zeng, L. Lyu, F. Wu, J. Li, and R. Jia, “Cater: Intellectual property protection on text generation apis via conditional watermarks,”Advances in Neural Information Processing Systems, vol. 35, pp. 5431–5445, 2022
2022
-
[35]
On the reliability of watermarks for large language mod- els.arXiv preprint arXiv:2306.04634, 2023
J. Kirchenbauer, J. Geiping, Y . Wen, M. Shu, K. Saifullah, K. Kong, K. Fernando, A. Saha, M. Goldblum, and T. Goldstein, “On the reliability of watermarks for large language models,”arXiv preprint arXiv:2306.04634, 2023
-
[36]
{REMARK- LLM}: A robust and efficient watermarking framework for generative large language models,
R. Zhang, S. S. Hussain, P. Neekhara, and F. Koushanfar, “{REMARK- LLM}: A robust and efficient watermarking framework for generative large language models,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 1813–1830
2024
-
[37]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,” arXiv preprint arXiv:1705.03551, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Crowdsourcing Multiple Choice Science Questions
J. Welbl, N. F. Liu, and M. Gardner, “Crowdsourcing multiple choice science questions,”arXiv preprint arXiv:1707.06209, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Tinystories: How small can language models be and still speak coherent english?
R. Eldan and Y . Li, “Tinystories: How small can language models be and still speak coherent english?”arXiv preprint arXiv:2305.07759, 2023
-
[40]
Qwen2.5: A party of foundation models,
Q. Team, “Qwen2.5: A party of foundation models,” September 2024. [Online]. Available: https://qwenlm.github.io/blog/qwen2.5/
2024
-
[41]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7b,” 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.