Recognition: no theorem link
On Privacy-Preserving Image Transmission in Low-Altitude Networks: A Swin Transformer-Based Framework with Federated Learning
Pith reviewed 2026-05-14 20:45 UTC · model grok-4.3
The pith
A Swin Transformer semantic communication system with federated learning improves UAV image transmission quality by at least 5.7 dB PSNR while keeping raw data private.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
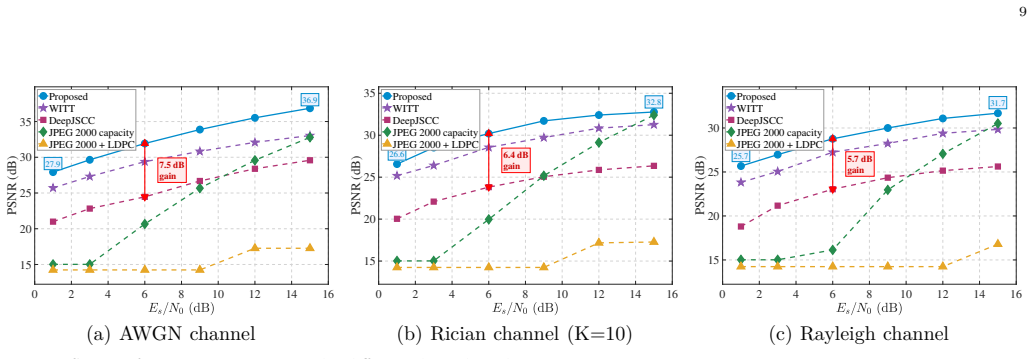
The STSC architecture extracts multi-scale semantic features via a Swin Transformer under bandwidth limits, pairs it with federated learning for distributed training without raw data exchange, and achieves at least 5.7 dB higher PSNR on CIFAR-10 reconstructions than DeepJSCC baselines while improving convergence and generalization.
What carries the argument
The Swin Transformer-based Semantic Communication (STSC) architecture, which extracts multi-scale semantic features from images for bandwidth-efficient transmission and integrates federated learning to train models across UAVs without sharing raw data.
If this is right
- UAV image transmissions maintain higher visual quality despite severe bandwidth limits.
- Raw images never leave the UAV, satisfying strict privacy rules for distributed operations.
- Dedicated on-board nodes allow flexible real-time coverage without central data aggregation.
- The model shows faster convergence and better generalization across different transmission scenarios.
Where Pith is reading between the lines
- The same architecture could be adapted to transmit other sensor streams such as video or LiDAR from UAVs.
- If the privacy mechanism scales, it might support multi-UAV swarms sharing semantic updates without a central server.
- Variable real-world channel fading not present in CIFAR-10 simulations remains an open variable for deployment.
Load-bearing premise
That performance gains measured on CIFAR-10 under simulated conditions will hold for real UAV deployments facing actual bandwidth limits, channel noise, and privacy regulations.
What would settle it
A field experiment with actual UAVs sending real images over live wireless links that shows no PSNR gain or leaks raw data would disprove the central performance and privacy claims.
Figures







read the original abstract
The rapid development of low-altitude economy has driven the proliferation of Unmanned Aerial Vehicle (UAV) applications, including logistics, inspection, and emergency response. However, transmitting high-volume image data from UAVs to ground stations faces significant challenges due to limited bandwidth and stringent privacy requirements. To address these issues, a Semantic Communication (SC) framework based on Federated Learning (FL) is proposed for efficient and privacy-preserving image transmission. A Swin Transformer-based Semantic Communication (STSC) architecture is designed to extract multi-scale semantic features under constrained bandwidth conditions. Dedicated communication and computing nodes are deployed on UAVs to enhance real-time coverage and flexibility. Meanwhile, a FL mechanism enables global model training across distributed devices without sharing raw data, thus preserving user privacy. Simulation experiments conducted on the CIFAR-10 dataset demonstrate that the proposed STSC framework achieves at least 5.7 dB improvement in Peak Signal-to-Noise Ratio (PSNR) compared to DeepJSCC baselines, while also showing superior convergence and generalization performance. The framework effectively integrates UAV-assisted deployment with SC and privacy protection, offering a practical solution for bandwidth-constrained image transmission in low-altitude networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Swin Transformer-based Semantic Communication (STSC) framework integrated with Federated Learning (FL) for privacy-preserving image transmission in low-altitude UAV networks. It designs multi-scale semantic feature extraction under bandwidth constraints, deploys dedicated nodes on UAVs, and uses FL to train without sharing raw data. Simulations on CIFAR-10 are reported to yield at least 5.7 dB PSNR improvement over DeepJSCC baselines together with better convergence and generalization.
Significance. If the performance claims are robustly supported, the work could advance semantic communications for bandwidth-limited, privacy-sensitive UAV applications by combining transformer-based feature extraction with distributed training. The integration of SC and FL addresses a timely problem in low-altitude networks, though the simulation-only evidence on a standard image dataset restricts immediate claims about real-world UAV viability.
major comments (2)
- [Simulation Experiments] Simulation Experiments section: the headline claim of ≥5.7 dB PSNR gain over DeepJSCC is presented without an experimental protocol, baseline implementation details, error bars, or statistical tests, leaving the central performance result weakly supported.
- [Methods] Methods / Channel Model subsection: the simulations appear to rely on static or simplified channel models (e.g., AWGN) without explicit incorporation of UAV-specific impairments such as variable path loss, Doppler shifts, or interference; this undermines applicability to the stated low-altitude network setting.
minor comments (2)
- [Abstract] Abstract: the phrase 'at least 5.7 dB' should be accompanied by the precise SNR, bandwidth, and model-size conditions under which the gain is measured.
- [STSC Architecture] Notation: the definition of semantic feature maps and the FL aggregation rule should be stated explicitly with equation numbers to avoid ambiguity when comparing to DeepJSCC.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below, indicating the revisions we will make to improve the manuscript.
read point-by-point responses
-
Referee: [Simulation Experiments] Simulation Experiments section: the headline claim of ≥5.7 dB PSNR gain over DeepJSCC is presented without an experimental protocol, baseline implementation details, error bars, or statistical tests, leaving the central performance result weakly supported.
Authors: We agree that additional details are required to robustly support the central performance claim. In the revised manuscript, we will expand the Simulation Experiments section with a complete experimental protocol (including hyperparameters, training schedules, and data splits), explicit implementation details for the DeepJSCC baselines, results reported with error bars from multiple independent runs, and statistical significance tests (e.g., paired t-tests) to validate the reported PSNR gains. revision: yes
-
Referee: [Methods] Methods / Channel Model subsection: the simulations appear to rely on static or simplified channel models (e.g., AWGN) without explicit incorporation of UAV-specific impairments such as variable path loss, Doppler shifts, or interference; this undermines applicability to the stated low-altitude network setting.
Authors: The current work uses an AWGN model as a controlled baseline to isolate the contributions of the Swin Transformer semantic extractor and federated learning under bandwidth limits. We acknowledge that this simplification limits direct applicability to real low-altitude UAV channels. In the revision, we will augment the Channel Model subsection with a discussion of UAV-specific impairments and include additional simulation results that incorporate standard models for path loss and Doppler shift. Full modeling of dynamic interference and hardware effects is noted as future work, as it would require specialized UAV channel datasets beyond the scope of this study. revision: partial
Circularity Check
No circularity: empirical simulation results are independent of framework definition
full rationale
The paper defines an STSC architecture and FL mechanism, then reports separate simulation outcomes (PSNR gains on CIFAR-10) as measured performance. No equation reduces to its own inputs by construction, no fitted parameter is relabeled as a prediction, and no self-citation chain supplies the central claim. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rethink- ing modern communication from semantic coding to semantic communication
Lu K, Zhou Q, Li R, Zhao Z, Chen X, Wu J, et al. Rethink- ing modern communication from semantic coding to semantic communication. IEEE Wirel Commun 2023;30(1):158-64
2023
-
[2]
Beyond transmitting bits: Context, semantics, and task-oriented communications
Gündüz D, Qin Z, Aguerri IE, Dhillon HS, Yang Z, Yener A, et al. Beyond transmitting bits: Context, semantics, and task-oriented communications. IEEE J Sel Areas Commun 2023;41(1):5-41
2023
-
[3]
FSSC: Federated learning of transformer neural networks for semantic image communication
Yan Y, Zhang X, Li L, Lin W, Li R, Cheng W, et al. FSSC: Federated learning of transformer neural networks for semantic image communication. GLOBECOM 2024 - 2024 IEEE Global Communications Conference; 2024 Dec 8-12; Cape Town, South Africa. 2024. p. 1659-64
2024
-
[4]
FLSC-CI: Federated learning and semantic communication empowered multimodal terminal col- laborative inferencing framework for IoT businesses
Xu S, Qi Y, Qi F, et al. FLSC-CI: Federated learning and semantic communication empowered multimodal terminal col- laborative inferencing framework for IoT businesses. IEEE Trans Netw Sci Eng 2026. Forthcoming
2026
-
[5]
Federated learning based audio semantic communication over wireless net- works
Tong H, Yang Z, Wang S, Hu Y, Saad W, Yin C. Federated learning based audio semantic communication over wireless net- works. GLOBECOM 2021 - 2021 IEEE Global Communications Conference; 2021 Dec 7-11; Madrid, Spain. 2021
2021
-
[6]
Deep joint source- channel coding for wireless image transmission
Bourtsoulatze E, Burth Kurka D, Gündüz D. Deep joint source- channel coding for wireless image transmission. IEEE Trans Cogn Commun Netw 2019;5(3):567-79
2019
-
[7]
Wireless communications with unmanned aerial vehicles: Opportunities and challenges
Zeng Y, Zhang R, Lim TJ. Wireless communications with unmanned aerial vehicles: Opportunities and challenges. IEEE Commun Mag 2016;54(5):36-42
2016
-
[8]
Beyond Gaussian assump- tions: A general fractional HJB control framework for Lévy- driven heavy-tailed channels in 6G
Li M, Li L, Lin W, Han Z, Basar T. Beyond Gaussian assump- tions: A general fractional HJB control framework for Lévy- driven heavy-tailed channels in 6G. IEEE Trans Wirel Commun 2026;25:7535-50
2026
-
[9]
Reconfigurable intelligent surface equipped UA V in emergency wireless communications: A new fading-shadowing model and performance analysis
Chen Y, Cheng W, Zhang W. Reconfigurable intelligent surface equipped UA V in emergency wireless communications: A new fading-shadowing model and performance analysis. IEEE Trans Commun 2024;72(3):1821-34
2024
-
[10]
Timeliness optimization of unmanned aerial vehicle lossy communications for Internet-of- Things
Lin W, Li L, Liu Y, He Y, Liu Y. Timeliness optimization of unmanned aerial vehicle lossy communications for Internet-of- Things. Chin J Aeronaut 2023;36(6):249-55
2023
-
[11]
Optimal trajectory and downlink power control for multi-type UA V aerial base stations
Li L, Sun Y, Cheng Q, Wang D, Lin W, Chen W. Optimal trajectory and downlink power control for multi-type UA V aerial base stations. Chin J Aeronaut 2021;34(9):11-23
2021
-
[12]
Neuro-symbolic causal reasoning meets signaling game for emergent semantic communications
Thomas CK, Saad W. Neuro-symbolic causal reasoning meets signaling game for emergent semantic communications. IEEE Trans Wirel Commun 2024;23(5):4546-63
2024
-
[13]
Distributed user pairing and effective computation offloading in aerial edge networks
Liang W, Wen S, Li L, Cui J, Fang F. Distributed user pairing and effective computation offloading in aerial edge networks. Chin J Aeronaut 2024;37(4):378-90
2024
-
[14]
Low-end hand held communication devices in a post-disaster scenario
Sarkar RR, Chakrabarty A, Rahman MZ. Low-end hand held communication devices in a post-disaster scenario. 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN); 2022 Dec 16-17; Al-Khobar, Saudi Arabia. 2022. p. 595-9
2022
-
[15]
Digital- analog transmission based emergency semantic communica- tions
Fu Y, Cheng W, Wang J, Yin L, Zhang W. Digital- analog transmission based emergency semantic communica- tions. arXiv:2501.01616. 2025
-
[16]
Optimal transport framework for ISAC in low-altitude networks: Joint resource allocation for cooperative communication and non- cooperative localization
Zheng Y, Li L, Lin W, Liang W, Du Q, Han Z. Optimal transport framework for ISAC in low-altitude networks: Joint resource allocation for cooperative communication and non- cooperative localization. IEEE Trans Commun 2026;74:1984- 2000
2026
-
[17]
Semantics-empowered communica- tion for networked intelligent systems
Kountouris M, Pappas N. Semantics-empowered communica- tion for networked intelligent systems. IEEE Commun Mag 2021;59(6):96-102
2021
-
[18]
Semantic communications for future Internet: Fundamen- tals, applications, and challenges
Yang W, Du H, Liew ZQ, Lim WYB, Xiong Z, Niyato D. Semantic communications for future Internet: Fundamen- tals, applications, and challenges. IEEE Commun Surv Tutor 2023;25(1):213-50
2023
-
[19]
Deep joint source-channel coding for wireless image transmission with adaptive rate control
Yang M, Kim HS. Deep joint source-channel coding for wireless image transmission with adaptive rate control. ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing; 2022 May 23-27; Singapore. 2022. p. 5193-7
2022
-
[20]
Task-oriented multi- user semantic communications
Xie H, Qin Z, Tao X, Letaief KB. Task-oriented multi- user semantic communications. IEEE J Sel Areas Commun 2022;40(9):2584-97
2022
-
[21]
DeepJSCC-f: Deep joint source-channel coding of images with feedback
Kurka DB, Gündüz D. DeepJSCC-f: Deep joint source-channel coding of images with feedback. IEEE J Sel Areas Inf Theory 2020;1(1):178-93
2020
-
[22]
WITT: A wireless image transmission transformer for semantic communi- cations
Yang K, Wang S, Dai J, Tan K, Niu K, Zhang P. WITT: A wireless image transmission transformer for semantic communi- cations. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing; 2023 Jun 4-10; Rhodes Island, Greece. 2023. p. 1-5
2023
-
[23]
Demo: Real-time semantic communications with a vision transformer
Yoo H, Jung T, Dai L, Kim S, Chae CB. Demo: Real-time semantic communications with a vision transformer. ICC 2022 - IEEE International Conference on Communications Workshops; 2022 May 16-20; Seoul, South Korea. 2022. p. 1-2
2022
-
[24]
Semantic successive refinement: A generative AI-aided semantic communication framework
Zhang K, Li L, Lin W, Yan Y, Li R, Cheng W, et al. Semantic successive refinement: A generative AI-aided semantic communication framework. IEEE Trans Cogn Commun Netw 2025;11(2):687-99
2025
-
[25]
Adap- tive semantic generation and NOMA-based interference-aware conveying for 6G networks
Yan Y, Li L, Zhang X, Lin W, Cheng W, Han Z. Adap- tive semantic generation and NOMA-based interference-aware conveying for 6G networks. IEEE Trans Wirel Commun 2025;24(3):2404-16
2025
-
[26]
Federated learning in mobile edge net- works: A comprehensive survey
Lim WYB, et al. Federated learning in mobile edge net- works: A comprehensive survey. IEEE Commun Surv Tutor 2020;22(3):2031-63
2020
-
[27]
Joint client scheduling and wireless resource allocation for heterogeneous federated edge learning with non-IID data
Yin T, Li L, Lin W, Ni T, Liu Y, Xu H, et al. Joint client scheduling and wireless resource allocation for heterogeneous federated edge learning with non-IID data. IEEE Trans Veh Technol 2024;73(4):5742-54
2024
-
[28]
Toward energy- efficient multiple IRSs: Federated learning-based configuration optimization
Li L, Ma D, Ren H, Wang P, Lin W, Han Z. Toward energy- efficient multiple IRSs: Federated learning-based configuration optimization. IEEE Trans Green Commun Netw 2022;6(2):755- 65
2022
-
[29]
From semantic communication to semantic-aware networking: Model, architecture, and open problems
Shi G, Xiao Y, Li Y, Xie X. From semantic communication to semantic-aware networking: Model, architecture, and open problems. IEEE Commun Mag 2021;59(8):44-50
2021
-
[30]
Attention is all you need
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. Advances in Neural Information Processing Systems (NeurIPS); 2017 Dec 4-9; Long Beach, CA. 2017
2017
-
[31]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv:2010.11929. 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[32]
Swin Transformer: Hierarchical vision transformer using shifted windows
Liu Z, et al. Swin Transformer: Hierarchical vision transformer using shifted windows. IEEE/CVF International Conference on Computer Vision (ICCV); 2021 Oct 11-17; Montreal, QC, Canada. 2021
2021
-
[33]
Communication-efficient learning of deep networks from decen- tralized data
McMahan HB, Moore E, Ramage D, Hampson S, Arcas BAy. Communication-efficient learning of deep networks from decen- tralized data. International Conference on Artificial Intelligence and Statistics (AISTATS); 2017 Apr 20-22; Fort Lauderdale, FL. 2017
2017
-
[34]
MobileViT: Light-weight, general- purpose, and mobile-friendly vision transformer
Mehta S, Rastegari M. MobileViT: Light-weight, general- purpose, and mobile-friendly vision transformer. International Conference on Learning Representations (ICLR); 2022 Apr 25-
2022
-
[35]
Deep leakage from gradients
Zhu L, Liu Z, Han S. Deep leakage from gradients. Advances in Neural Information Processing Systems (NeurIPS); 2019 Dec 8-14; Vancouver, Canada. 2019
2019
-
[36]
GradViT: Gradient inversion of vision transformers
Hatamizadeh A, Yin H, Roth H, Li W, Kautz J, Xu D, et al. GradViT: Gradient inversion of vision transformers. IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR); 2022 Jun 18-24; New Orleans, LA. 2022. p. 10011-20
2022
-
[37]
The model inversion eavesdropping attack in semantic communication systems
Chen Y, Guo Z, Liang Y. The model inversion eavesdropping attack in semantic communication systems. GLOBECOM 2023 - 2023 IEEE Global Communications Conference; 2023 Dec 4-8; Kuala Lumpur, Malaysia. 2023. p. 1-6
2023
-
[38]
Deep learning with differential privacy
Abadi M, Chu A, Goodfellow I, McMahan HB, Mironov I, Talwar K, et al. Deep learning with differential privacy. Proceedings of the ACM SIGSAC Conference on Computer 14 and Communications Security (CCS); 2016 Oct 24-28; Vienna, Austria. 2016. p. 308-18
2016
-
[39]
Practical secure aggregation for privacy- preserving machine learning
Bonawitz K, Ivanov V, Kreuter B, Marcedone A, McMahan HB, Patel S, et al. Practical secure aggregation for privacy- preserving machine learning. Proceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS); 2017 Oct 30 - Nov 3; Dallas, TX. 2017. p. 1175-91
2017
-
[40]
Learning multiple layers of features from tiny images
Krizhevsky A. Learning multiple layers of features from tiny images. Toronto: University of Toronto; 2009
2009
-
[41]
Adam: A Method for Stochastic Optimization
Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv:1412.6980. 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.