Recognition: 2 theorem links
· Lean TheoremA Unified Perspective for Learning Graph Representations Across Multi-Level Abstractions
Pith reviewed 2026-05-14 21:05 UTC · model grok-4.3
The pith
A unified contrastive framework learns graph representations by linearly combining node, proximity, cluster, and graph level signals with a parameter-free self-weighting mechanism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
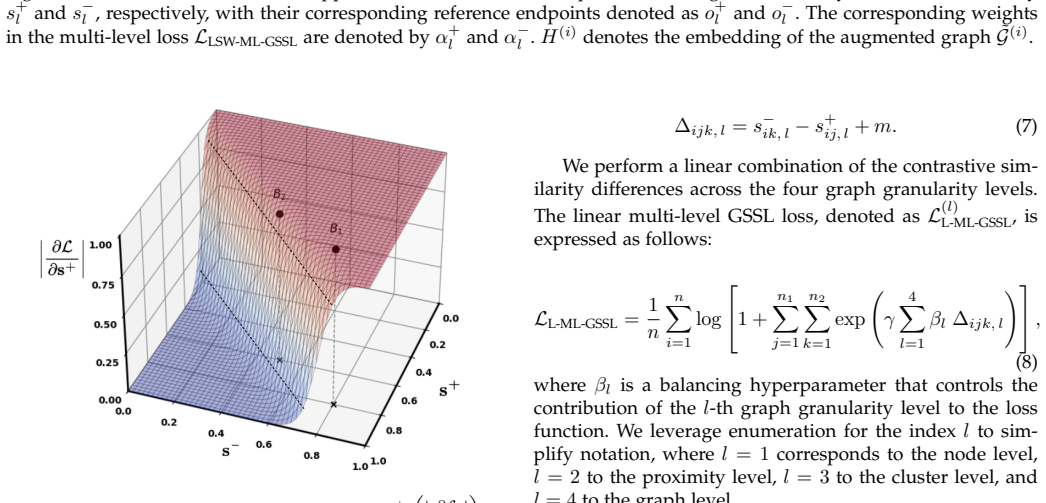
A single contrastive objective integrates node-level, proximity-level, cluster-level, and graph-level information through a linear combination of similarity scores on positive pairs and dissimilarity scores on negative pairs; a parameter-free self-weighting term then adaptively emphasizes individual scores that deviate most from their ideal values, yielding representations that improve downstream tasks without level-specific tuning.
What carries the argument
Linear combination of per-level similarity and dissimilarity scores modulated by a parameter-free self-weighting rule that raises the influence of scores farthest from their targets.
If this is right
- The same objective works without modification for both single-level and multi-level training regimes.
- No grid search over task or level weights is required, removing a major source of computational overhead.
- Representations improve simultaneously on classification, clustering, and link prediction tasks.
- The weighting rule remains effective across real-world graphs of varying size and density.
Where Pith is reading between the lines
- The self-weighting rule may transfer directly to other contrastive settings that combine heterogeneous objectives, such as multi-modal or multi-view learning.
- Because the method produces a single embedding space usable at every scale, downstream models could query the same vectors for both local and global tasks without retraining.
- If the linear combination assumption holds, extending the framework to temporal or heterogeneous graphs would require only the definition of new positive-pair and negative-pair generators at each additional level.
Load-bearing premise
A linear combination of per-level similarity and dissimilarity scores, modulated by the proposed self-weighting, captures complementary multi-level information without destructive interference or the need for level-specific tuning.
What would settle it
Train the method on a graph dataset engineered so that strong performance at one abstraction level systematically degrades performance at another; if the combined objective then yields lower downstream accuracy than the best single-level baseline, the claim of non-destructive integration would be refuted.
Figures






read the original abstract
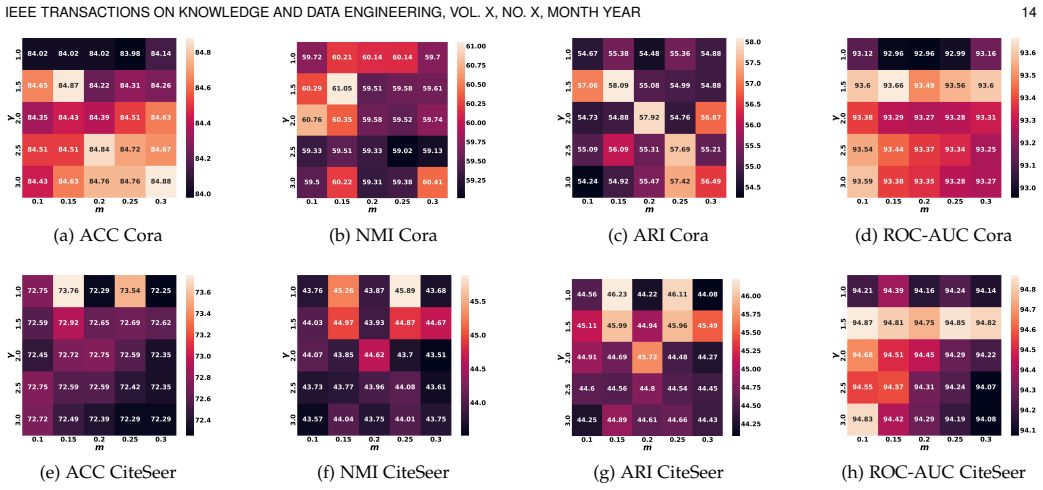
Graph Self-Supervised Learning (GSSL) has emerged as a powerful paradigm for generating high-quality representations for graph-structured data. While multi-scale graph contrastive learning has received increasing attention, many existing methods still predominantly focus on a single graph abstraction level. To address this limitation, we propose a unified contrastive framework that can target node-level, proximity-level, cluster-level, and graph-level information and integrate them through a linear combination of similarity scores on positive pairs and dissimilarity scores (i.e., similarity scores on negative pairs). Furthermore, current approaches typically assign uniform penalty strengths to all examples, which reduces optimization flexibility and leads to ambiguous convergence status. To overcome this, we introduce a novel parameter-free fine-grained self-weighting mechanism that adaptively assigns weights to individual similarity and dissimilarity scores. The proposed mechanism emphasizes the scores that deviate significantly from their target values. Our approach not only enhances optimization flexibility but also eliminates the computational overhead of hyperparameter tuning in conventional multi-task GSSL methods. Comprehensive experiments on real-world datasets show that our methods consistently outperform state-of-the-art approaches across downstream tasks, including classification, clustering, and link prediction, in both single-level and multi-level scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a unified contrastive framework for multi-level graph self-supervised learning that combines node-, proximity-, cluster-, and graph-level signals via a linear combination of similarity and dissimilarity scores, enhanced by a parameter-free self-weighting scheme that up-weights deviating scores. It asserts that this eliminates hyperparameter tuning and consistently outperforms SOTA on classification, clustering, and link prediction in single- and multi-level settings.
Significance. Should the central claims regarding the parameter-free nature and lack of destructive interference hold, this could simplify the design of multi-task GSSL methods and provide a more flexible optimization approach. The work addresses a relevant gap in focusing on single-level abstractions by offering a unified perspective.
major comments (2)
- [Abstract] The claim of eliminating hyperparameter tuning is load-bearing but rests on the assumption that the linear combination of per-level scores requires no inter-level balancing; the self-weighting is described as acting on individual scores, leaving open whether fixed coefficients suffice without performance sensitivity.
- [§3] The integration of multi-level information through linear combination lacks a demonstration that the fixed inter-level weights avoid destructive interference between abstraction levels, which is central to the unified framework's validity.
minor comments (1)
- [Abstract] Specific dataset names and baseline methods are not mentioned, reducing clarity on the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our unified multi-level graph contrastive framework. The concerns about hyperparameter sensitivity and potential destructive interference are well-taken; we provide clarifications below and will strengthen the manuscript with additional empirical analysis to demonstrate robustness.
read point-by-point responses
-
Referee: [Abstract] The claim of eliminating hyperparameter tuning is load-bearing but rests on the assumption that the linear combination of per-level scores requires no inter-level balancing; the self-weighting is described as acting on individual scores, leaving open whether fixed coefficients suffice without performance sensitivity.
Authors: We appreciate this observation. Our framework employs fixed inter-level coefficients (uniformly set to 1) in the linear combination of per-level contrastive terms, with the parameter-free self-weighting applied individually to each similarity and dissimilarity score to emphasize deviations from targets. This design avoids the need for inter-level hyperparameter search. To substantiate that fixed coefficients suffice without sensitivity, we will add an ablation study in the revised manuscript varying the inter-level coefficients across a range (e.g., 0.5 to 2.0) and reporting downstream task performance, which we expect to show minimal variance due to the adaptive weighting. revision: yes
-
Referee: [§3] The integration of multi-level information through linear combination lacks a demonstration that the fixed inter-level weights avoid destructive interference between abstraction levels, which is central to the unified framework's validity.
Authors: We agree that explicit validation strengthens the central claim. In §3, the total objective is formulated as a sum of weighted per-level terms, where the self-weighting mechanism (detailed in Eq. 4-6) dynamically scales contributions based on score deviation, thereby reducing the risk of one level dominating or interfering destructively with others. We will revise §3 to include a new paragraph with empirical evidence: plots of per-level weight distributions during training and an analysis showing stable convergence across levels on representative datasets, confirming the absence of destructive interference. revision: yes
Circularity Check
No load-bearing circularity; framework presented as direct construction
full rationale
The paper defines a linear combination of node-, proximity-, cluster-, and graph-level similarity/dissimilarity scores, then modulates each term with an explicitly parameter-free self-weighting that up-weights deviations from targets. No equation reduces the claimed elimination of hyperparameter tuning to a fitted coefficient or to a self-citation chain; the inter-level weights are presented as fixed by the construction itself rather than derived from data. Empirical results on downstream tasks are offered as external validation, not as tautological confirmation of the weighting scheme. This yields at most minor self-citation risk without affecting the central claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-level graph information can be integrated via linear combination of per-level contrastive scores
- domain assumption Adaptive weighting based on deviation from target values improves optimization without introducing new hyperparameters
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Proposition 1 ... Δ''_l = (s_l^-)^2 + (1-s_l^+)^2 - 2m^2 ... D = sum_l [(s_l^-)^2 + (1-s_l^+)^2]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Eq. (16) ... sum_l [(s_l^-)^2 + (s_l^+ - 1)^2] = 8m^2 (hyperspherical decision boundary)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Re- thinking deep clustering paradigms: Self-supervision is all you need,
A. Shaheen, N. Mrabah, R. Ksantini, and A. Alqaddoumi, “Re- thinking deep clustering paradigms: Self-supervision is all you need,”Neural Networks, vol. 181, p. 106773, 2025
2025
-
[2]
Big self-supervised models are strong semi-supervised learners,
T. Chen, S. Kornblith, K. Swersky, M. Norouzi, and G. E. Hinton, “Big self-supervised models are strong semi-supervised learners,” inAdvances in neural information processing systems (NeurIPS), vol. 33, 2020, pp. 22 243–22 255
2020
-
[3]
Toward convex manifolds: A geometric perspective for deep graph clus- tering of single-cell rna-seq data
N. Mrabah, M. M. Amar, M. Bouguessa, and A. B. Diallo, “Toward convex manifolds: A geometric perspective for deep graph clus- tering of single-cell rna-seq data.” inInternational Joint Conference on Artificial Intelligence (IJCAI), 2023, pp. 4855–4863
2023
-
[4]
Exploring the interaction between local and global latent configurations for clustering single-cell rna-seq: a unified per- spective,
——, “Exploring the interaction between local and global latent configurations for clustering single-cell rna-seq: a unified per- spective,” inAssociation for the Advancement of Artificial Intelligence (AAAI), vol. 37, no. 8, 2023, pp. 9235–9242
2023
-
[5]
Graph self-supervised learning: A survey,
Y. Liu, M. Jin, S. Pan, C. Zhou, Y. Zheng, F. Xia, and S. Y. Philip, “Graph self-supervised learning: A survey,”IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 35, no. 6, pp. 5879– 5900, 2022
2022
-
[6]
Deep graph contrastive representation learning,
Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Deep graph contrastive representation learning,” inInternational Conference on Machine Learning (ICML Workshop on Graph Representation Learning and Beyond), 2020
2020
-
[7]
Large-scale representation learning on graphs via bootstrapping,
S. Thakoor, C. Tallec, M. G. Azar, M. Azabou, E. L. Dyer, R. Munos, P . Veliˇckovi´c, and M. Valko, “Large-scale representation learning on graphs via bootstrapping,” inInternational Conference on Learn- ing Representations (ICLR), 2022
2022
-
[8]
node2vec: Scalable feature learning for networks,
A. Grover and J. Leskovec, “node2vec: Scalable feature learning for networks,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2016, pp. 855–864
2016
-
[9]
Variational graph auto-encoders
T. N. Kipf and M. Welling, “Variational graph auto-encoders.” inAdvances in Neural Information Processing Systems workshop (NeurIPS workshop), 2016, pp. 1–3
2016
-
[10]
A contrastive vari- ational graph auto-encoder for node clustering,
N. Mrabah, M. Bouguessa, and R. Ksantini, “A contrastive vari- ational graph auto-encoder for node clustering,”Pattern Recogni- tion, vol. 149, p. 110209, 2024
2024
-
[11]
Beyond the evidence lower bound: Dual variational graph auto-encoders for node clustering,
——, “Beyond the evidence lower bound: Dual variational graph auto-encoders for node clustering,” inProceedings of the 2023 SIAM International Conference on Data Mining (SDM), 2023, pp. 100–108
2023
-
[12]
Deep graph infomax,
P . Velickovic, W. Fedus, W. L. Hamilton, P . Li `o, Y. Bengio, and R. D. Hjelm, “Deep graph infomax,” inInternational Conference on Learning Representations (ICLR), 2019
2019
-
[13]
Contrastive multi-view rep- resentation learning on graphs,
K. Hassani and A. H. Khasahmadi, “Contrastive multi-view rep- resentation learning on graphs,” inInternational Conference on Machine Learning (ICML), 2020, pp. 4116–4126
2020
-
[14]
Automated self-supervised learning for graphs,
W. Jin, X. Liu, X. Zhao, Y. Ma, N. Shah, and J. Tang, “Automated self-supervised learning for graphs,” inInternational Conference on Learning Representations (ICLR), 2022
2022
-
[15]
Multi-task self-supervised graph neural networks en- able stronger task generalization,
M. Ju, T. Zhao, Q. Wen, W. Yu, N. Shah, Y. Ye, and C. Zhang, “Multi-task self-supervised graph neural networks en- able stronger task generalization,” inInternational Conference on Learning Representations (ICLR), 2023
2023
-
[16]
Circle loss: A unified perspective of pair similarity op- timization,
Y. Sun, C. Cheng, Y. Zhang, C. Zhang, L. Zheng, Z. Wang, and Y. Wei, “Circle loss: A unified perspective of pair similarity op- timization,” inIEEE/CVF conference on computer vision and pattern recognition (CVPR), 2020, pp. 6398–6407
2020
-
[17]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Proceedings of the 37th International Conference on Machine Learning (ICML), vol. 119, 2020, pp. 1597–1607
2020
-
[18]
Graph contrastive learning with augmentations,
Y. You, T. Chen, Y. Sui, T. Chen, Z. Wang, and Y. Shen, “Graph contrastive learning with augmentations,” inAdvances in neural information processing systems (NeurIPS), vol. 33, 2020, pp. 5812– 5823
2020
-
[19]
Representation Learning with Contrastive Predictive Coding
A. v. d. Oord, Y. Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
Graph contrastive learning with adaptive augmentation,
Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang, “Graph contrastive learning with adaptive augmentation,” inInternational World Wide Web Conference (WWW), 2021, pp. 2069–2080
2021
-
[21]
Deepwalk: Online learning of social representations,
B. Perozzi, R. Al-Rfou, and S. Skiena, “Deepwalk: Online learning of social representations,” inACM SIGKDD Conference on Knowl- edge Discovery and Data Mining (KDD), 2014, pp. 701–710
2014
-
[22]
Mgae: Marginal- ized graph autoencoder for graph clustering,
C. Wang, S. Pan, G. Long, X. Zhu, and J. Jiang, “Mgae: Marginal- ized graph autoencoder for graph clustering,” inACM Conference on Information and Knowledge Management (CIKM), 2017, pp. 889– 898
2017
-
[23]
What’s behind the mask: Understanding masked graph modeling for graph autoencoders,
J. Li, R. Wu, W. Sun, L. Chen, S. Tian, L. Zhu, C. Meng, Z. Zheng, and W. Wang, “What’s behind the mask: Understanding masked graph modeling for graph autoencoders,” inACM SIGKDD Con- ference on Knowledge Discovery and Data Mining (KDD), 2023, pp. 1268–1279
2023
-
[24]
Slaps: Self-supervision improves structure learning for graph neural networks,
B. Fatemi, L. El Asri, and S. M. Kazemi, “Slaps: Self-supervision improves structure learning for graph neural networks,”Advances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 22 667–22 681, 2021
2021
-
[25]
Latent graph inference with limited supervision,
J. Lu, Y. Xu, H. Wang, Y. Bai, and Y. Fu, “Latent graph inference with limited supervision,”Advances in Neural Information Process- ing Systems (NeurIPS), vol. 36, pp. 32 521–32 538, 2023
2023
-
[26]
Neighbor con- trastive learning on learnable graph augmentation,
X. Shen, D. Sun, S. Pan, X. Zhou, and L. T. Yang, “Neighbor con- trastive learning on learnable graph augmentation,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 8, 2023, pp. 9782–9791
2023
-
[27]
Attributed graph clustering: a deep attentional embedding ap- proach,
C. Wang, S. Pan, R. Hu, G. Long, J. Jiang, and C. Zhang, “Attributed graph clustering: a deep attentional embedding ap- proach,” inInternational Joint Conference on Artificial Intelligence (IJCAI), 2019, p. 3670–3676
2019
-
[28]
Collaborative graph convolutional net- works: Unsupervised learning meets semi-supervised learning,
B. Hui, P . Zhu, and Q. Hu, “Collaborative graph convolutional net- works: Unsupervised learning meets semi-supervised learning,” inAssociation for the Advancement of Artificial Intelligence (AAAI), vol. 34, no. 04, 2020, pp. 4215–4222
2020
-
[29]
Talk like a graph: Encoding graphs for large language models,
B. Fatemi, J. Halcrow, and B. Perozzi, “Talk like a graph: Encoding graphs for large language models,” inThe Twelfth International Conference on Learning Representations (ICLR), 2024
2024
-
[30]
Scale-free graph- language models,
J. Lu, Y. Liu, Y. Zhang, and Y. Fu, “Scale-free graph- language models,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2025. [Online]. Available: https://openreview.net/forum?id=nFcgay1Yo9
2025
-
[31]
Sub- graph contrast for scalable self-supervised graph representation learning,
Y. Jiao, Y. Xiong, J. Zhang, Y. Zhang, T. Zhang, and Y. Zhu, “Sub- graph contrast for scalable self-supervised graph representation learning,” in2020 IEEE international conference on data mining (ICDM). IEEE, 2020, pp. 222–231
2020
-
[32]
Anemone: Graph anomaly detection with multi-scale contrastive learning,
M. Jin, Y. Liu, Y. Zheng, L. Chi, Y.-F. Li, and S. Pan, “Anemone: Graph anomaly detection with multi-scale contrastive learning,” inProceedings of the 30th ACM international conference on information & knowledge management (CIKM), 2021, pp. 3122–3126
2021
-
[33]
Multi-scale contrastive siamese networks for self-supervised graph representation learning,
M. Jin, Y. Zheng, Y.-F. Li, C. Gong, C. Zhou, and S. Pan, “Multi-scale contrastive siamese networks for self-supervised graph representation learning,” inProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2021, pp. 1477...
-
[34]
Multi-scale subgraph contrastive learning,
Y. Liu, Y. Zhao, X. Wang, L. Geng, and Z. Xiao, “Multi-scale subgraph contrastive learning,” inProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, E. Elkind, Ed. International Joint Conferences on Artificial Intelligence Organization, 8 2023, pp. 2215–2223, main Track. [Online]. Available: https://doi.org/...
-
[35]
Contrastive representation learning based on multiple node-centered subgraphs,
D. Li, W. Wang, M. Shao, and C. Zhao, “Contrastive representation learning based on multiple node-centered subgraphs,” inProceed- ings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM), 2023, pp. 1338–1347
2023
-
[36]
Anomaly detection in attributed networks via local multi-order contrastive learning and global topology awareness,
M. J. Li, G. Zhao, S. Huang, Q. Zhang, J. Liu, M. Li, and J. Li, “Anomaly detection in attributed networks via local multi-order contrastive learning and global topology awareness,”Neurocom- puting, p. 130829, 2025
2025
-
[37]
Multi-task learning as multi-objective optimization,
O. Sener and V . Koltun, “Multi-task learning as multi-objective optimization,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 31, 2018, pp. 527–538
2018
-
[38]
Multi-task learning with user prefer- ences: Gradient descent with controlled ascent in pareto optimiza- tion,
D. Mahapatra and V . Rajan, “Multi-task learning with user prefer- ences: Gradient descent with controlled ascent in pareto optimiza- tion,” inInternational Conference on Machine Learning (ICML), 2020, pp. 6597–6607
2020
-
[39]
Profiling pareto front with multi- objective stein variational gradient descent,
X. Liu, X. Tong, and qiang liu, “Profiling pareto front with multi- objective stein variational gradient descent,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[40]
Learning the pareto front with hypernetworks,
A. Navon, A. Shamsian, G. Chechik, and E. Fetaya, “Learning the pareto front with hypernetworks,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[41]
Gradient surgery for multi-task learning,
T. Yu, S. Kumar, A. Gupta, S. Levine, K. Hausman, and C. Finn, “Gradient surgery for multi-task learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 5824– 5836
2020
-
[42]
Multi-task self-supervised visual learning,
C. Doersch and A. Zisserman, “Multi-task self-supervised visual learning,” inIEEE/CVF conference on computer vision and pattern recognition (CVPR), 2017, pp. 2051–2060
2017
-
[43]
Anomaly detection in video via self-supervised and multi-task learning,
M.-I. Georgescu, A. Barbalau, R. T. Ionescu, F. S. Khan, M. Popescu, and M. Shah, “Anomaly detection in video via self-supervised and multi-task learning,” inIEEE/CVF conference on computer vision and pattern recognition (CVPR), 2021, pp. 12 742–12 752
2021
-
[44]
Learning modality-specific representations with self-supervised multi-task learning for mul- timodal sentiment analysis,
W. Yu, H. Xu, Z. Yuan, and J. Wu, “Learning modality-specific representations with self-supervised multi-task learning for mul- timodal sentiment analysis,” inAssociation for the Advancement of Artificial Intelligence (AAAI), vol. 35, no. 12, 2021, pp. 10 790–10 797
2021
-
[45]
Every node is different: Dynamically fusing self-supervised tasks for attributed graph clustering,
P . Zhu, Q. Wang, Y. Wang, J. Li, and Q. Hu, “Every node is different: Dynamically fusing self-supervised tasks for attributed graph clustering,” inAssociation for the Advancement of Artificial Intelligence (AAAI), vol. 38, no. 15, 2024, pp. 17 184–17 192
2024
-
[46]
Exploring correlations of self-supervised tasks for graphs,
T. Fang, W. Zhou, Y. Sun, K. Han, L. Ma, and Y. Yang, “Exploring correlations of self-supervised tasks for graphs,” inInternational Conference on Machine Learning (ICML), 2024
2024
-
[47]
Decoupling weighing and selecting for integrating multiple graph pre-training tasks,
T. Fan, L. Wu, Y. Huang, H. Lin, C. Tan, Z. Gao, and S. Z. Li, “Decoupling weighing and selecting for integrating multiple graph pre-training tasks,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[48]
Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,
A. Kendall, Y. Gal, and R. Cipolla, “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics,” inProceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2018, pp. 7482–7491
2018
-
[49]
Grad- norm: Gradient normalization for adaptive loss balancing in deep multitask networks,
Z. Chen, V . Badrinarayanan, C.-Y. Lee, and A. Rabinovich, “Grad- norm: Gradient normalization for adaptive loss balancing in deep multitask networks,” inInternational conference on machine learning (ICML). PMLR, 2018, pp. 794–803
2018
-
[50]
Conflict-averse gradient descent for multi-task learning,
B. Liu, X. Liu, X. Jin, P . Stone, and Q. Liu, “Conflict-averse gradient descent for multi-task learning,”Advances in Neural Information Processing Systems (NeurIPS), vol. 34, pp. 18 878–18 890, 2021
2021
-
[51]
Adatask: A task-aware adaptive learning rate approach to multi-task learning,
E. Yang, J. Pan, X. Wang, H. Yu, L. Shen, X. Chen, L. Xiao, J. Jiang, and G. Guo, “Adatask: A task-aware adaptive learning rate approach to multi-task learning,” inProceedings of the AAAI conference on artificial intelligence, vol. 37, no. 9, 2023, pp. 10 745– 10 753
2023
-
[52]
Improvable gap balancing for multi-task learning,
Y. Dai, N. Fei, and Z. Lu, “Improvable gap balancing for multi-task learning,” inUncertainty in Artificial Intelligence. PMLR, 2023, pp. 496–506
2023
-
[53]
Automatic auxiliary task selection and adaptive weighting boost molecular property prediction,
Z. Zhong and D. Mottin, “Automatic auxiliary task selection and adaptive weighting boost molecular property prediction,” in Advances in neural information processing systems (NeurIPS), 2025
2025
-
[54]
Generative and contrastive paradigms are complementary for graph self-supervised learning,
Y. Wang, X. Yan, C. Hu, Q. Xu, C. Yang, F. Fu, W. Zhang, H. Wang, B. Du, and J. Jiang, “Generative and contrastive paradigms are complementary for graph self-supervised learning,” in2024 IEEE 40th International Conference on Data Engineering (ICDE). IEEE, 2024, pp. 3364–3378
2024
-
[55]
Re- thinking graph auto-encoder models for attributed graph cluster- ing,
N. Mrabah, M. Bouguessa, M. F. Touati, and R. Ksantini, “Re- thinking graph auto-encoder models for attributed graph cluster- ing,”IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 35, no. 9, pp. 9037–9053, 2022
2022
-
[56]
Dg- cluster: A neural framework for attributed graph clustering via modularity maximization,
A. Bhowmick, M. Kosan, Z. Huang, A. Singh, and S. Medya, “Dg- cluster: A neural framework for attributed graph clustering via modularity maximization,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 10, 2024, pp. 11 069–11 077
2024
-
[57]
Local structure- aware graph contrastive representation learning,
K. Yang, Y. Liu, Z. Zhao, P . Ding, and W. Zhao, “Local structure- aware graph contrastive representation learning,”Neural Networks, vol. 172, p. 106083, 2024
2024
-
[58]
Automat- ing the construction of internet portals with machine learning,
A. K. McCallum, K. Nigam, J. Rennie, and K. Seymore, “Automat- ing the construction of internet portals with machine learning,” Information Retrieval, vol. 3, pp. 127–163, 2000
2000
-
[59]
Citeseer: An automatic citation indexing system,
C. L. Giles, K. D. Bollacker, and S. Lawrence, “Citeseer: An automatic citation indexing system,” inACM Conference on Digital Libraries (DL), 1998, pp. 89–98
1998
-
[60]
Collective classification in network data,
P . Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi- Rad, “Collective classification in network data,”AI magazine, vol. 29, no. 3, pp. 93–93, 2008
2008
-
[61]
Arnetminer: extraction and mining of academic social networks,
J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su, “Arnetminer: extraction and mining of academic social networks,” inACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), 2008, pp. 990–998
2008
-
[62]
Pit- falls of graph neural network evaluation,
O. Shchur, M. Mumme, A. Bojchevski, and S. G ¨unnemann, “Pit- falls of graph neural network evaluation,” inInternational Confer- ence on Learning Representations (ICLR Workshop on the pitfalls of limited data and computation for Trustworthy ML), 2023
2023
-
[63]
Deep metric learning using triplet net- work,
E. Hoffer and N. Ailon, “Deep metric learning using triplet net- work,” inInternational workshop on similarity-based pattern recogni- tion. Springer, 2015, pp. 84–92. Mohamed Mahmoud Amaris a Ph.D. student at the University of Quebec at Montreal (UQAM). His research interests include graph representa- tion learning and multi-task learning. Nairouz Mrabahr...
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.