Recognition: 2 theorem links
· Lean TheoremModeling Heterophily in Multiplex Graphs: An Adaptive Approach for Node Classification
Pith reviewed 2026-05-14 20:56 UTC · model grok-4.3
The pith
Dimension-specific matrices paired with a product of low- and high-pass filters let node classification adapt to mixed homophily and heterophily across multiplex edge types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The method models varying degrees of homophily and heterophily in each dimension of a multiplex graph through dimension-specific compatibility matrices; it then captures both smooth and abrupt graph-signal changes by forming the product of trainable low-pass and high-pass filters that are approximated via Chebyshev polynomials and jointly optimized by a proximal-gradient algorithm for node-label prediction.
What carries the argument
The product of trainable low-pass and high-pass filters (Chebyshev-approximated) combined with dimension-specific compatibility matrices that scale the contribution of each edge type according to its homophily level.
If this is right
- The approach can separate and weight heterophilic interactions independently in each dimension instead of averaging them.
- Node classification accuracy improves on both synthetic and real multiplex data sets that contain a mixture of homophilic and heterophilic edge types.
- The same filter-product construction extends existing single-graph heterophily techniques to the multi-relation setting without requiring separate models per dimension.
Where Pith is reading between the lines
- The same per-dimension matrix-plus-filter pattern could be inserted into link-prediction or community-detection pipelines on multiplex data.
- If the filters remain stable, the method offers a route to reduce the number of separate hyper-parameters that must be tuned when moving from unidimensional to multiplex graphs.
Load-bearing premise
That multiplying a low-pass filter with a high-pass filter per dimension, scaled by learned compatibility matrices, can separate homophilic from heterophilic behavior without producing numerical instability or demanding extensive per-dataset tuning.
What would settle it
Run the method on a synthetic multiplex graph whose dimensions have known, contrasting homophily ratios; if classification accuracy shows no consistent gain over a standard multiplex GNN that ignores heterophily, or if the proximal-gradient step fails to converge for moderate filter orders, the central claim is refuted.
Figures

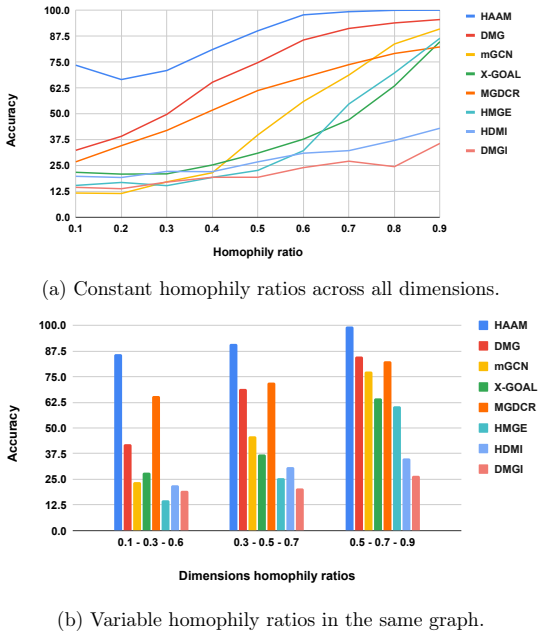





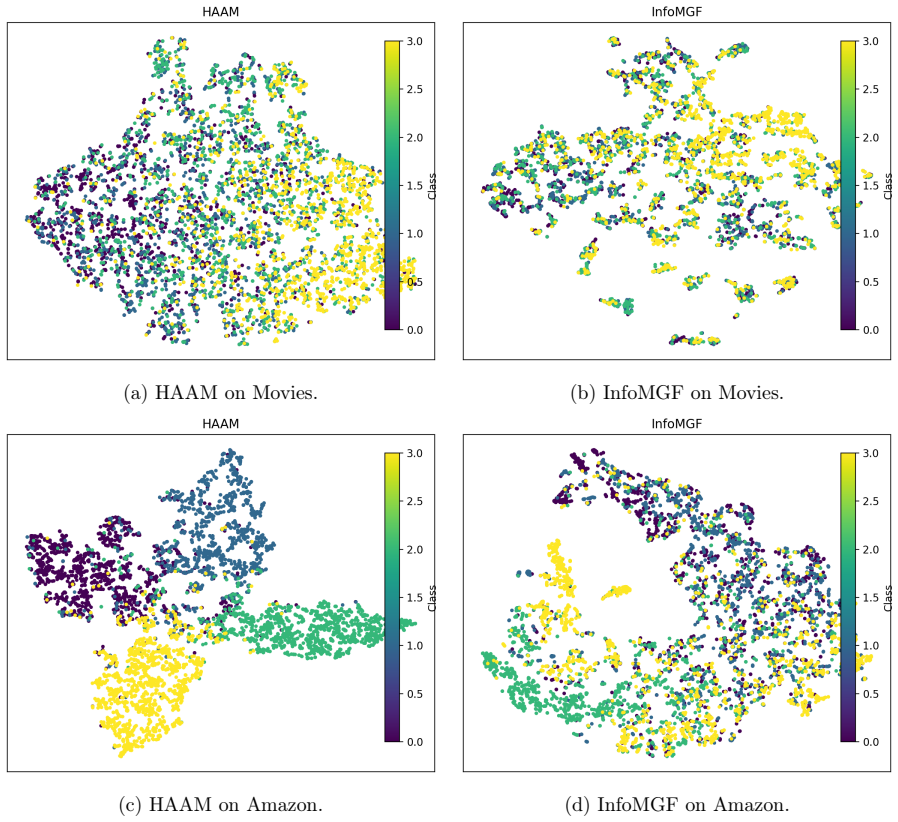
read the original abstract
Existing multiplex graph models often assume homophily, where connected nodes tend to belong to the same class or share similar attributes. Consequently, these models may struggle with graphs exhibiting heterophily, where connected nodes typically belong to different classes and have dissimilar attributes. While recent methods have been developed to learn reliable node representations from unidimensional graphs with heterophily, they do not fully address the complexities of multiplex graphs. In a multiplex graph, nodes are linked through multiple types of edges (referred to as dimensions), which can simultaneously exhibit homophilic and heterophilic interactions. To address this gap, we propose \methodname, a novel method for node classification in multiplex graphs that adapts to both homophilic and heterophilic dimensions. \methodname introduces dimension-specific compatibility matrices to model varying degrees of homophily and heterophily across dimensions. A key innovation is its use of a product of trainable low-pass and high-pass filters, approximated via Chebyshev polynomials, to capture both smooth and abrupt changes in the graph signal. By composing these filters and optimizing label predictions using a proximal-gradient method, \methodname dynamically adjusts to the heterophilic characteristics of each dimension. Extensive experiments on synthetic and real-world datasets provide evidence that \methodname captures the complex interplay of homophilic and heterophilic interactions in multiplex graphs, and tends to yield improved node classification performance compared to state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a method called MethodName for node classification in multiplex graphs. It uses dimension-specific compatibility matrices to model varying homophily/heterophily per dimension and composes a product of trainable low-pass and high-pass filters (each approximated by Chebyshev polynomials) before optimizing label predictions via proximal gradient descent. The authors claim that this construction captures the interplay of homophilic and heterophilic interactions across dimensions and yields improved node classification performance over state-of-the-art methods on both synthetic and real-world datasets.
Significance. If the performance gains and stability claims are substantiated, the work would meaningfully extend graph representation learning to multiplex settings where edge dimensions can simultaneously exhibit homophily and heterophily. The adaptive filter product offers a concrete mechanism for handling mixed interaction types that current multiplex GNNs largely ignore.
major comments (3)
- [Abstract and §3] Abstract and §3 (Method): the product of trainable low-pass and high-pass Chebyshev filters is presented without approximation-error bounds, spectral analysis, or conditions on the compatibility matrices that would guarantee numerical stability or preservation of the intended homophily/heterophily separation after multiplication.
- [§4] §4 (Experiments): the central performance claim rests on experiments whose details (train/test splits, number of runs, statistical significance tests, and ablation controls for the filter product versus compatibility matrices) are not reported, making it impossible to verify that the observed gains are attributable to the proposed components rather than hyper-parameter tuning.
- [§3.3] §3.3 (Optimization): proximal-gradient optimization is invoked to learn the filter coefficients and matrices, yet no convergence analysis or guarantee is supplied that the learned solution maintains the low-pass/high-pass separation intended by the construction.
minor comments (2)
- [Abstract] Notation: the compatibility matrices are introduced without an explicit symbol or dimension index in the abstract; consistent notation should be used throughout.
- [§2] Related work: several recent heterophily-aware GNNs for single graphs are mentioned but not compared in the experimental section; a brief table contrasting their assumptions with the multiplex setting would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): the product of trainable low-pass and high-pass Chebyshev filters is presented without approximation-error bounds, spectral analysis, or conditions on the compatibility matrices that would guarantee numerical stability or preservation of the intended homophily/heterophily separation after multiplication.
Authors: We agree that formal analysis is missing. In the revised manuscript we will add approximation-error bounds for the Chebyshev polynomials (drawing on standard results from spectral graph theory), a brief spectral analysis of the product filter, and explicit conditions on the compatibility matrices (e.g., bounded spectral norms and positive-semidefiniteness) to guarantee numerical stability and preservation of the homophily/heterophily separation. These additions will appear in an expanded §3. revision: yes
-
Referee: [§4] §4 (Experiments): the central performance claim rests on experiments whose details (train/test splits, number of runs, statistical significance tests, and ablation controls for the filter product versus compatibility matrices) are not reported, making it impossible to verify that the observed gains are attributable to the proposed components rather than hyper-parameter tuning.
Authors: We acknowledge the insufficient experimental reporting. The revision will explicitly document the train/test splits (standard 10-20% labeled nodes per dataset), results over 10 independent runs with mean and standard deviation, statistical significance via paired t-tests or Wilcoxon tests against baselines, and new ablation tables that isolate the filter-product component from the compatibility matrices. These changes will make the source of the gains verifiable. revision: yes
-
Referee: [§3.3] §3.3 (Optimization): proximal-gradient optimization is invoked to learn the filter coefficients and matrices, yet no convergence analysis or guarantee is supplied that the learned solution maintains the low-pass/high-pass separation intended by the construction.
Authors: We accept that a dedicated convergence analysis is absent. Proximal gradient descent is applied to a convex objective; we will cite the standard convergence guarantees for this setting and add empirical convergence plots plus a short discussion showing that the low-pass/high-pass separation is preserved under the coefficient constraints used in practice. A full custom proof is not feasible within the current scope, but the added material will address the referee's concern. revision: partial
Circularity Check
No circularity detected in the adaptive multiplex heterophily model
full rationale
The paper defines a novel architecture consisting of dimension-specific compatibility matrices and a product of trainable low-pass and high-pass filters (Chebyshev-approximated), optimized via proximal gradient descent for node classification. Performance claims rest on empirical evaluation across synthetic and real-world datasets rather than any derivation that reduces a claimed result to its own inputs by construction. No self-citations, fitted inputs renamed as predictions, or self-definitional steps appear in the model definition or experimental claims.
Axiom & Free-Parameter Ledger
free parameters (2)
- dimension-specific compatibility matrices
- Chebyshev polynomial coefficients for low-pass and high-pass filters
axioms (2)
- domain assumption Chebyshev polynomials can accurately approximate the desired low-pass and high-pass graph filters
- domain assumption Proximal-gradient optimization will converge to a useful labeling for the combined filter system
Lean theorems connected to this paper
-
Cost.FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
product of trainable low-pass and high-pass filters, approximated via Chebyshev polynomials... dimension-specific compatibility matrices... proximal-gradient method
-
Foundation.AlexanderDualityalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Chebyshev product-to-sum expansion... bounded-input bounded-output stability... generalization bound linking... operator norms ∥L̂_d∥₂∥H_d∥₂
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A geometric perspective for high- dimensional multiplex graphs
Kamel Abdous, Nairouz Mrabah, and Mohamed Bouguessa. A geometric perspective for high- dimensional multiplex graphs. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, page 4–13, 2024
work page 2024
-
[2]
Kamel Abdous, Nairouz Mrabah, and Mohamed Bouguessa. Hierarchical aggregations for high-dimensional multiplex graph embedding.IEEE Transactions on Knowledge and Data Engineering, 36(4):1624–1637, 2024
work page 2024
-
[3]
Mixhop: Higher-order graph con- volutional architectures via sparsified neighborhood mixing
Sami Abu-El-Haija, Bryan Perozzi, Amol Kapoor, Nazanin Alipourfard, Kristina Lerman, Hrayr Harutyunyan, Greg Ver Steeg, and Aram Galstyan. Mixhop: Higher-order graph con- volutional architectures via sparsified neighborhood mixing. InInternational Conference on Machine Learning, pages 21–29. PMLR, 2019
work page 2019
-
[4]
Oriol Barranco, Carlos Lozares, and Dafne Muntanyola-Saura. Heterophily in social groups formation: a social network analysis.Quality & Quantity, 53(2):599–619, 2019
work page 2019
-
[5]
Federico Battiston, Vincenzo Nicosia, and Vito Latora. The new challenges of multiplex net- works: Measures and models.The European Physical Journal Special Topics, 226:401–416, 2017
work page 2017
-
[6]
Multidimensional networks: foundations of structural analysis.World Wide Web, 16(5):567– 593, 2013
Michele Berlingerio, Michele Coscia, Fosca Giannotti, Anna Monreale, and Dino Pedreschi. Multidimensional networks: foundations of structural analysis.World Wide Web, 16(5):567– 593, 2013
work page 2013
-
[7]
OualidBoutemineandMohamedBouguessa. Miningcommunitystructuresinmultidimensional networks.ACM Transactions on Knowledge Discovery from Data, 11(4):1–36, 2017
work page 2017
-
[8]
Representa- tion learning for attributed multiplex heterogeneous network
Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. Representa- tion learning for attributed multiplex heterogeneous network. InInternational Conference on Knowledge Discovery and Data Mining, pages 1358–1368, 2019. 27
work page 2019
-
[9]
Polygcl: Graph contrastive learning via learnable spectral polynomial filters
Jingyu Chen, Runlin Lei, and Zhewei Wei. Polygcl: Graph contrastive learning via learnable spectral polynomial filters. InThe Twelfth International Conference on Learning Representa- tions, 2024
work page 2024
-
[10]
Adaptive universal generalized pager- ank graph neural network
Eli Chien, Jianhao Peng, Pan Li, and Olgica Milenkovic. Adaptive universal generalized pager- ank graph neural network. InThe Ninth International Conference on Learning Representations, 2021
work page 2021
-
[11]
Michaël Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering.Advances on Neural Information Processing Systems, 29:3844–3852, 2016
work page 2016
-
[12]
Rui Duan, Mingjian Guang, Junli Wang, Chungang Yan, Hongda Qi, Wenkang Su, Can Tian, and Haoran Yang. Unifying homophily and heterophily for spectral graph neural networks via triple filter ensembles.Advances in Neural Information Processing Systems, 37:93540–93567, 2024
work page 2024
-
[13]
Mingguo He, Zhewei Wei, and Ji-Rong Wen. Convolutional neural networks on graphs with chebyshev approximation, revisited.Advances on Neural Information Processing Systems, 35: 7264–7276, 2024
work page 2024
-
[14]
Ruining He and Julian McAuley. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. InThe Web Conference, pages 507–517, 2016
work page 2016
-
[15]
Learning deep representations by mutual information estimation andmaximization
RDevonHjelm, AlexFedorov, SamuelLavoie-Marchildon, KaranGrewal, PhilBachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation andmaximization. InThe Seventh International Conference on Learning Representations, 2019
work page 2019
-
[16]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in Neural Information Processing Systems, 33:22118–22133, 2020
work page 2020
-
[17]
Wangyu Jin, Huifang Ma, Yingyue Zhang, Zhixin Li, and Liang Chang. Multi-view discrimi- native edge heterophily contrastive learning network for attributed graph anomaly detection. Expert Systems with Applications, 255:124460, 2024. ISSN 0957-4174
work page 2024
-
[18]
Hdmi: High-order deep multiplex infomax
Baoyu Jing, Chanyoung Park, and Hanghang Tong. Hdmi: High-order deep multiplex infomax. InThe Web Conference, pages 2414–2424, 2021
work page 2021
-
[19]
X-goal: multiplex heterogeneous graph prototypical contrastive learning
Baoyu Jing, Shengyu Feng, Yuejia Xiang, Xi Chen, Yu Chen, and Hanghang Tong. X-goal: multiplex heterogeneous graph prototypical contrastive learning. InInternational Conference on Information & Knowledge Management, pages 894–904, 2022
work page 2022
-
[20]
Derek Lim, Felix Hohne, Xiuyu Li, Sijia Linda Huang, Vaishnavi Gupta, Omkar Bhalerao, and Ser Nam Lim. Large scale learning on non-homophilous graphs: New benchmarks and strong simple methods.Advances in Neural Information Processing Systems, 34:20887–20902, 2021
work page 2021
-
[21]
Siqi Liu, Dongxiao He, Zhizhi Yu, Di Jin, and Zhiyong Feng. Beyond homophily: Neighbor- hood distribution-guided graph convolutional networks.Expert Systems with Applications, 259: 125274, 2025. ISSN 0957-4174. 28
work page 2025
-
[22]
Beyond smoothing: Unsupervised graph representation learning with edge heterophily discriminating
Yixin Liu, Yizhen Zheng, Daokun Zhang, Vincent CS Lee, and Shirui Pan. Beyond smoothing: Unsupervised graph representation learning with edge heterophily discriminating. InAAAI Conference on Artificial Intelligence, volume 37, pages 4516–4524, 2023
work page 2023
-
[23]
Sitao Luan, Chenqing Hua, Qincheng Lu, Jiaqi Zhu, Mingde Zhao, Shuyuan Zhang, Xiao-Wen Chang, and Doina Precup. Revisiting heterophily for graph neural networks.Advances in Neural Information Processing Systems, 35:1362–1375, 2022
work page 2022
-
[24]
Multi-dimensional graph convolutional networks
Yao Ma, Suhang Wang, Chara C Aggarwal, Dawei Yin, and Jiliang Tang. Multi-dimensional graph convolutional networks. InInternational Conference on Data Mining, pages 657–665. SIAM, 2019
work page 2019
-
[25]
Semi-supervised deep learning for multiplex networks
Anasua Mitra, Priyesh Vijayan, Ranbir Sanasam, Diganta Goswami, Srinivasan Parthasarathy, and Balaraman Ravindran. Semi-supervised deep learning for multiplex networks. InInterna- tional Conference on Knowledge Discovery and Data Mining, pages 1234–1244, 2021
work page 2021
-
[26]
Yujie Mo, Yuhuan Chen, Yajie Lei, Liang Peng, Xiaoshuang Shi, Changan Yuan, and Xiaofeng Zhu. Multiplexgraphrepresentationlearningviadualcorrelationreduction.IEEE Transactions on Knowledge and Data Engineering, 35(12):12814–12827, 2023
work page 2023
-
[27]
Dis- entangled multiplex graph representation learning
Yujie Mo, Yajie Lei, Jialie Shen, Xiaoshuang Shi, Heng Tao Shen, and Xiaofeng Zhu. Dis- entangled multiplex graph representation learning. InInternational Conference on Machine Learning, pages 24983–25005, 2023
work page 2023
-
[28]
Escaping feature twist: A varia- tional graph auto-encoder for node clustering
Nairouz Mrabah, Mohamed Bouguessa, and Riadh Ksantini. Escaping feature twist: A varia- tional graph auto-encoder for node clustering. InInternational Joint Conference on Artificial Intelligence (IJCAI), pages 3351–3357, 2022
work page 2022
-
[29]
Nairouz Mrabah, Mohamed Bouguessa, Mohamed Fawzi Touati, and Riadh Ksantini. Re- thinking graph auto-encoder models for attributed graph clustering.IEEE Transactions on Knowledge and Data Engineering, 35(9):9037–9053, 2022
work page 2022
-
[30]
Nairouz Mrabah, Mohamed Bouguessa, and Riadh Ksantini. A contrastive variational graph auto-encoder for node clustering.Pattern recognition, 149:110209, 2024
work page 2024
-
[31]
Rose Oughtred, Jennifer Rust, Christie Chang, Bobby-Joe Breitkreutz, Chris Stark, Andrew Willems, Lorrie Boucher, Genie Leung, Nadine Kolas, Frederick Zhang, et al. The biogrid database: A comprehensive biomedical resource of curated protein, genetic, and chemical in- teractions.Protein Science, 30(1):187–200, 2021
work page 2021
-
[32]
Beyond homophily: Reconstructing structure for graph-agnostic clustering
Erlin Pan and Zhao Kang. Beyond homophily: Reconstructing structure for graph-agnostic clustering. InInternational Conference on Machine Learning, pages 26868–26877. PMLR, 2023
work page 2023
-
[33]
Unsupervised attributed mul- tiplex network embedding
Chanyoung Park, Donghyun Kim, Jiawei Han, and Hwanjo Yu. Unsupervised attributed mul- tiplex network embedding. InAAAI Conference on Artificial Intelligence, volume 34, pages 5371–5378, 2020
work page 2020
-
[34]
Léo Pio-Lopez, Alberto Valdeolivas, Laurent Tichit, Élisabeth Remy, and Anaïs Baudot. Mul- tiverse: a multiplex and multiplex-heterogeneous network embedding approach.Scientific Re- ports, 11(1):1–20, 2021
work page 2021
-
[35]
Semi-supervised embedding of attributed multiplex networks
Ylli Sadikaj, Justus Rass, Yllka Velaj, and Claudia Plant. Semi-supervised embedding of attributed multiplex networks. InThe Web Conference, pages 578–587, 2023. 29
work page 2023
-
[36]
Zhixiang Shen, Shuo Wang, and Zhao Kang. Beyond redundancy: Information-aware unsuper- vised multiplex graph structure learning.Advances in Neural Information Processing Systems, 37:31629–31658, 2024
work page 2024
-
[37]
Breaking the entanglement of homophily and heterophily in semi-supervised node classification
Henan Sun, Xunkai Li, Zhengyu Wu, Daohan Su, Rong-Hua Li, and Guoren Wang. Breaking the entanglement of homophily and heterophily in semi-supervised node classification. In2024 IEEE 40th International Conference on Data Engineering (ICDE), pages 2379–2392, 2024
work page 2024
-
[38]
Multi-graph convolution collaborative filtering
Jianing Sun, Yingxue Zhang, Chen Ma, Mark Coates, Huifeng Guo, Ruiming Tang, and Xi- uqiang He. Multi-graph convolution collaborative filtering. InInternational Conference on Data Mining, pages 1306–1311. IEEE, 2019
work page 2019
-
[39]
Social influence analysis in large-scale networks
Jie Tang, Jimeng Sun, Chi Wang, and Zi Yang. Social influence analysis in large-scale networks. InProceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 807–816, 2009
work page 2009
-
[40]
Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of Machine Learning Research, 9(86):2579–2605, 2008
work page 2008
-
[41]
Bang Wang, Xiang Cai, Minghua Xu, and Wei Xiang. A graph-enhanced attention model for community detection in multiplex networks.Expert Systems with Applications, 230:120552,
-
[42]
How powerful are spectral graph neural networks
Xiyuan Wang and Muhan Zhang. How powerful are spectral graph neural networks. InInter- national Conference on Machine Learning, pages 23341–23362, 2022
work page 2022
-
[43]
Graph Neural Networks for Graphs with Heterophily: A Survey
Xin Zheng, Yi Wang, Yixin Liu, Ming Li, Miao Zhang, Di Jin, Philip S Yu, and Shirui Pan. Graph neural networks for graphs with heterophily: A survey.arXiv preprint arXiv:2202.07082, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Zhiqiang Zhong, Guadalupe Gonzalez, Daniele Grattarola, and Jun Pang. Unsupervised net- work embedding beyond homophily.Transactions on Machine Learning Research (TMLR), 2022
work page 2022
-
[45]
Jiong Zhu, Yujun Yan, Lingxiao Zhao, Mark Heimann, Leman Akoglu, and Danai Koutra. Be- yond homophily in graph neural networks: Current limitations and effective designs.Advances in Neural Information Processing Systems, 33:7793–7804, 2020
work page 2020
-
[46]
Graphneuralnetworkswithheterophily
Jiong Zhu, Ryan A Rossi, Anup Rao, Tung Mai, Nedim Lipka, Nesreen K Ahmed, and Danai Koutra. Graphneuralnetworkswithheterophily. InAAAI Conference on Artificial Intelligence, volume 35, pages 11168–11176, 2021. 30 Appendices A Notation summary In the main manuscript, we use a variety of symbols to denote graph structure, node- and label- related quantitie...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.