Recognition: no theorem link
Efficient and Portable Support for Overdecomposition on Distributed Memory GPGPU Platforms
Pith reviewed 2026-05-14 19:45 UTC · model grok-4.3
The pith
Techniques enable efficient overdecomposition on mixed-vendor GPGPU clusters and networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop techniques and software that demonstrate that overdecomposition can be efficiently and productively supported on combinations of GPU vendor types and interconnection networks, addressing both the higher overhead from overpartitioning and the need for portability across GPGPU platforms.
What carries the argument
Charm++ runtime extensions that manage multiple overdecomposed objects on GPGPUs through optimized scheduling, data movement, and task handling to lower per-device overhead.
Load-bearing premise
The extra overhead caused by assigning several objects to the same GPGPU can be reduced enough by the new techniques to keep the benefits of overdecomposition intact.
What would settle it
A direct performance comparison on a mixed-GPU cluster showing whether applications using the new overdecomposition support achieve similar or better scalability than versions without overdecomposition.
Figures

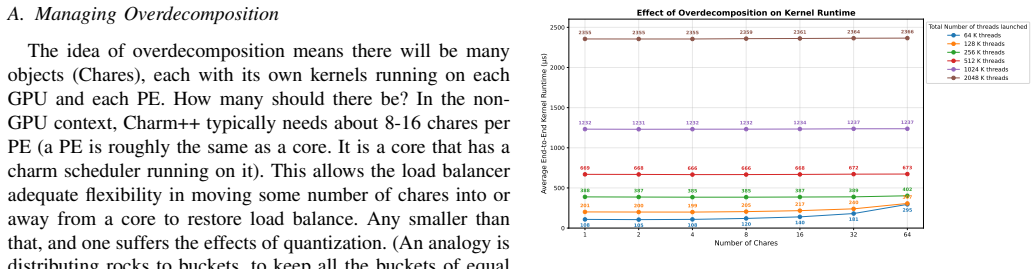

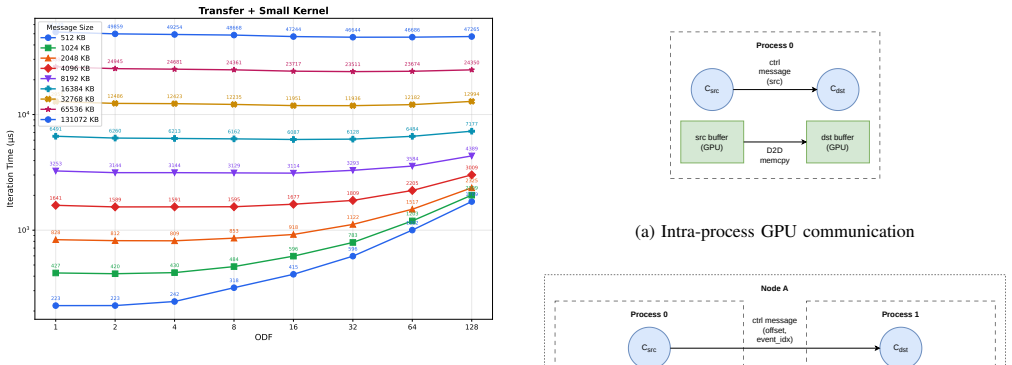
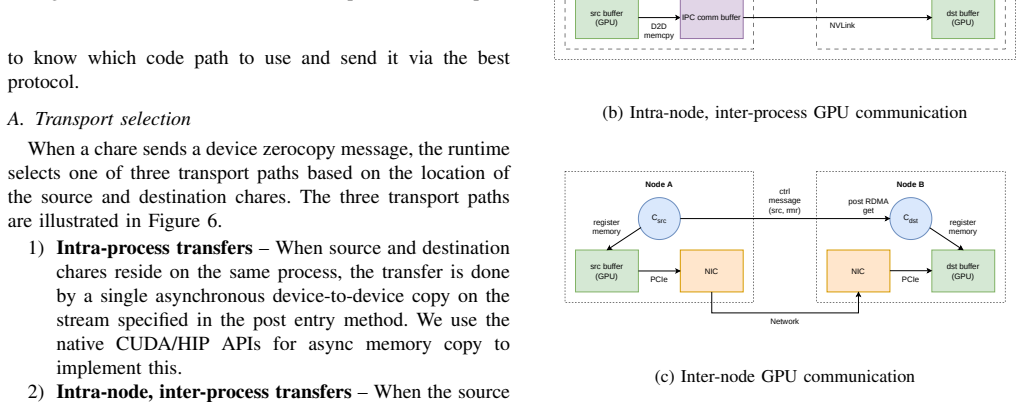







read the original abstract
Overdecomposition has emerged as a powerful and sometimes essential technique in parallel programming. Many application domains or frameworks, including those based on adaptive mesh refinements, or tree codes use it. Charm++ is a parallel programming system which has demonstrated the utility of overdecomposition for many applications and in multiple contexts. However, the emergence of GPGPUs as a dominant compute component has created some real and perceived challenges for this paradigm, especially regarding the higher overhead brought about by overpartitioning -- having multiple objects assigned to the same GPGPU device. We address this issue as well as the issue of portability by developing techniques and software that demonstrate that overdecomposition can be efficiently and productively supported on combinations of GPU vendor types, and interconnection networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the development of techniques and software within the Charm++ parallel programming system to support overdecomposition on distributed-memory GPGPU platforms. It addresses the increased overhead from assigning multiple objects to the same GPU device and claims to demonstrate efficient, portable operation across different GPU vendors and interconnection networks.
Significance. If the claimed techniques successfully reduce per-object overhead while retaining benefits such as latency hiding and dynamic load balancing, and if they generalize across vendor-network pairs, the work would meaningfully extend overdecomposition to modern GPU-accelerated clusters. This is relevant for applications relying on adaptive mesh refinement or tree codes.
major comments (2)
- [Evaluation] The central claim that overhead mitigation preserves overdecomposition utility requires explicit quantification (e.g., objects-per-GPU versus achieved speedup, idle time, or communication volume) across at least two distinct GPU vendors and two interconnects; without such data the portability assertion remains untested.
- [Implementation] If the mitigation relies on communication aggregation or runtime hooks that are not fully portable, the generalization to arbitrary vendor-network combinations should be demonstrated or bounded; otherwise the claim that the techniques work on 'combinations of GPU vendor types, and interconnection networks' is at risk.
minor comments (1)
- [Abstract] The abstract would be strengthened by including one or two concrete performance indicators (e.g., 'X% reduction in overhead at 8 objects per GPU') rather than only qualitative assertions.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which help improve the clarity and strength of our claims regarding the efficiency and portability of overdecomposition support in Charm++ for GPGPU platforms. We address each major comment below.
read point-by-point responses
-
Referee: [Evaluation] The central claim that overhead mitigation preserves overdecomposition utility requires explicit quantification (e.g., objects-per-GPU versus achieved speedup, idle time, or communication volume) across at least two distinct GPU vendors and two interconnects; without such data the portability assertion remains untested.
Authors: We concur that explicit quantification strengthens the central claim. Our manuscript presents results from benchmarks on NVIDIA and AMD GPUs across InfiniBand and Ethernet-based interconnects, illustrating reduced overhead with overdecomposition through metrics like execution time and load balance. We will revise by adding a dedicated subsection with tables quantifying objects-per-GPU against speedup, idle time, and communication volume for two vendors and two interconnects. revision: yes
-
Referee: [Implementation] If the mitigation relies on communication aggregation or runtime hooks that are not fully portable, the generalization to arbitrary vendor-network combinations should be demonstrated or bounded; otherwise the claim that the techniques work on 'combinations of GPU vendor types, and interconnection networks' is at risk.
Authors: The mitigation techniques rely on portable runtime features in Charm++, such as message aggregation using MPI and GPU abstractions that support both CUDA and HIP. We have validated on multiple vendor-network pairs including NVIDIA-InfiniBand and AMD-RoCE. In the revision, we will expand the implementation section to detail these portable hooks and explicitly bound our claims to the demonstrated combinations while discussing extensibility. revision: partial
Circularity Check
No circularity: claims rest on new technique development and empirical demonstration
full rationale
The paper presents development of techniques and software to support overdecomposition on multi-vendor GPGPU platforms, addressing overhead from multiple objects per device and portability across vendors and networks. No equations, fitted parameters, predictions, or self-citations appear in the abstract or description that reduce any result to its own inputs by construction. The central claim is a demonstration of efficiency and productivity via the new software, which is independent of the inputs it addresses. This is a standard systems paper with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yan, Jiakun and Snir, Marc , title =. Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , pages =. 2025 , isbn =. doi:10.1145/3712285.3759881 , abstract =
-
[2]
and Kale, Laxmikant V
Choi, Jaemin and Richards, David F. and Kale, Laxmikant V. , booktitle=. Improving Scalability with GPU-Aware Asynchronous Tasks , year=
-
[3]
Carter Edwards and Christian R
H. Carter Edwards and Christian R. Trott and Daniel Sunderland. Kokkos: Enabling manycore performance portability through polymorphic memory access patterns. Journal of Parallel and Distributed Computing. 2014. doi:https://doi.org/10.1016/j.jpdc.2014.07.003
-
[4]
Kaiser, Hartmut and Diehl, Patrick and Lemoine, Adrian S. and Lelbach, Bryce Adelstein and Amini, Parsa and Berge, Agustín and Biddiscombe, John and Brandt, Steven R. and Gupta, Nikunj and Heller, Thomas and Huck, Kevin and Khatami, Zahra and Kheirkhahan, Alireza and Reverdell, Auriane and Shirzad, Shahrzad and Simberg, Mikael and Wagle, Bibek and Wei, We...
-
[5]
Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis , articleno =
Bauer, Michael and Treichler, Sean and Slaughter, Elliott and Aiken, Alex , title =. Proceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis , articleno =. 2012 , isbn =
2012
-
[6]
and Burmark, Jason and Hornung, Rich and Jones, Holger and Killian, William and Kunen, Adam J
Beckingsale, David A. and Burmark, Jason and Hornung, Rich and Jones, Holger and Killian, William and Kunen, Adam J. and Pearce, Olga and Robinson, Peter and Ryujin, Brian S. and Scogland, Thomas RW , booktitle=. RAJA: Portable Performance for Large-Scale Scientific Applications , year=
-
[7]
Holmen, John K. and Garc\'. Lessons Learned and Scalability Achieved When Porting Uintah to DOE Exascale Systems , year =. Euro-Par 2024: Parallel Processing Workshops: Euro-Par 2024 International Workshops, Madrid, Spain, August 26–30, 2024, Proceedings, Part I , pages =. doi:10.1007/978-3-031-90200-0_19 , abstract =
-
[8]
Milind Bhandarkar and L. V. Kal\' e. A Parallel Framework for Explicit FEM. Proceedings of the International Conference on High Performance Computing (HiPC 2000), Lecture Notes in Computer Science. 2000
2000
-
[9]
Kal\'e and Sameer Kumar and Jayant DeSouza
Laxmikant V. Kal\'e and Sameer Kumar and Jayant DeSouza. An Adaptive Job Scheduler for Timeshared Parallel Machines. 2000
2000
-
[10]
Milind Bhandarkar and L. V. Kale and Eric de Sturler and Jay Hoeflinger. Object-Based Adaptive Load Balancing for MPI Programs. Proceedings of the International Conference on Computational Science, San Francisco, CA, LNCS 2074. 2001
2074
-
[11]
Eric deStruler and Jay Hoeflinger and L. V. Kale and Milind Bhandarkar. A New Approach to Software Integration Frameworks for Multi-physics Simulation Codes. Proceedings of IFIP TC2/WG2.5 Working Conference on Architecture of Scientific Software, Ottawa, Canada. 2000
2000
-
[12]
L. V. Kale and Milind Bhandarkar and Robert Brunner. Run-time Support for Adaptive Load Balancing. Lecture Notes in Computer Science, Proceedings of 4th Workshop on Runtime Systems for Parallel Programming (RTSPP) Cancun - Mexico. 2000
2000
-
[13]
Brunner and James C
Robert K. Brunner and James C. Phillips and Laxmikant V. Kale. Scalable Molecular Dynamics for Large Biomolecular Systems. Proceedings of Supercomputing (SC) 2000, Dallas, TX, November 2000. Nominated for Gordon Bell Award. 2000
2000
-
[14]
A Checkpoint and Restart Mechanism for Parallel Programming Systems
Sameer Paranjpye. A Checkpoint and Restart Mechanism for Parallel Programming Systems. 2000
2000
-
[15]
Robert K. Brunner. Versatile Automatic Load Balancing with Migratable Objects. 2000
2000
-
[16]
Lawlor and L
O. Lawlor and L. V. Kal \'e. Supporting Dynamic Parallel Object Arrays. Proceedings of ACM 2001 Java Grande/ISCOPE Conference. 2001
2001
-
[17]
Neelam Saboo and L. V. Kal\'e. Improving Paging Performace With Object Prefetching
-
[18]
Milind Bhandarkar and L. V. Kale. An Interface Model for Parallel Components. Proceedings of the Workshop on Languages and Compilers for Parallel Computing (LCPC), Cumberland Falls, KY. 2001
2001
-
[19]
Neelam Saboo and Arun Kumar Singla and Joshua Mostkoff Unger and L. V. Kal \'e. Emulating Petaflops Machines and Blue Gene. Workshop on Massively Parallel Processing (IPDPS'01). 2001
2001
-
[20]
A Grid-Based Parallel Collision Detection Algorithm
Orion Lawlor. A Grid-Based Parallel Collision Detection Algorithm. 2001
2001
-
[21]
An Adaptive Job Scheduler for Timeshared Parallel Machines
Sameer Kumar. An Adaptive Job Scheduler for Timeshared Parallel Machines. 2001
2001
-
[22]
Kal\'e and Sameer Kumar and Jayant DeSouza , title =
Laxmikant V. Kal\'e and Sameer Kumar and Jayant DeSouza , title =. 2nd IEEE/ACM International Symposium on Cluster Computing and the Grid (CCGrid 2002) , year = 2002, month =
2002
-
[23]
An Adaptive Mesh Refinement (AMR) Library Using Charm++
Puneet Narula. An Adaptive Mesh Refinement (AMR) Library Using Charm++. 2002
2002
-
[24]
Gengbin Zheng and Arun Kumar Singla and Joshua Mostkoff Unger and Laxmikant V. Kal \'e. A Parallel-Object Programming Model for Petaflops Machines and Blue Gene/Cyclops. NSF Next Generation Systems Program Workshop, 16th International Parallel and Distributed Processing Symposium(IPDPS). 2002
2002
-
[25]
James Phillips and Gengbin Zheng and Laxmikant V. Kal \'e. NAMD: Biomolecular Simulation on Thousands of Processors. Workshop: Scaling to New Heights. 2002
2002
-
[26]
Orion Lawlor and Milind Bhandarkar and Laxmikant V. Kal\'e. Adaptive MPI. 2002
2002
-
[27]
Orion Sky Lawlor and L. V. Kal \'e. A Voxel-Based Parallel Collision Detection Algorithm. Proceedings of the International Conference in Supercomputing. 2002
2002
-
[28]
Phillips and Gengbin Zheng and Sameer Kumar and Laxmikant V
James C. Phillips and Gengbin Zheng and Sameer Kumar and Laxmikant V. Kal \'e. NAMD : Biomolecular Simulation on Thousands of Processors. Proceedings of the 2002 ACM/IEEE conference on Supercomputing. 2002
2002
-
[29]
Bhandarkar
Milind A. Bhandarkar. Charisma: A Component Architecture for Parallel Programming. 2002
2002
-
[30]
Laxmikant V. Kal \'e. The Virtualization Model of Parallel Programming : Runtime Optimizations and the State of Art. LACSI 2002. 2002
2002
-
[31]
L. V. Kale and Sameer Kumar and Krishnan Vardarajan. A Framework for Collective Personalized Communication, Communicated to IPDPS 2003. 2002
2003
-
[32]
L. V. Kale and Sameer Kumar and Krishnan Vardarajan. A Framework for Collective Personalized Communication. Proceedings of IPDPS'03. 2003
2003
-
[33]
Kal\'e and Sameer Kumar and Jayant DeSouza and Mani Potnuru and Sindhura Bandhakavi
Laxmikant V. Kal\'e and Sameer Kumar and Jayant DeSouza and Mani Potnuru and Sindhura Bandhakavi. Faucets: Efficient Resource Allocation on the Computational Grid. 2003
2003
-
[34]
Jayant DeSouza and L. V. Kal\' e. Jade: A Parallel Message-Driven J ava. Proc. Workshop on Java in Computational Science, held in conjunction with the International Conference on Computational Science (ICCS 2003)
2003
-
[35]
Kal \'e and Sameer Kumar and Gengbin Zheng and Chee Wai Lee
Laxmikant V. Kal \'e and Sameer Kumar and Gengbin Zheng and Chee Wai Lee. Scaling Molecular Dynamics to 3000 Processors with Projections: A Performance Analysis Case Study. Terascale Performance Analysis Workshop, International Conference on Computational Science(ICCS). 2003
2003
-
[36]
L. V. Kale and Sameer Kumar. Scaling Collective Multicast on High Performance Clusters. 2003
2003
-
[37]
Gengbin Zheng and Gunavardhan Kakulapati and Laxmikant V. Kal. 18th International Parallel and Distributed Processing Symposium (IPDPS). 2004
2004
-
[38]
Ramkumar Vadali and L. V. Kale and Glenn Martyna and Mark Tuckerman , title =
-
[39]
Chao Huang and Orion Lawlor and L. V. Kal\' e. Adaptive MPI. Proceedings of the 16th International Workshop on Languages and Compilers for Parallel Computing (LCPC 2003), LNCS 2958. 2003
2003
-
[40]
Automatic Out-of-Core Exceution Support for CHARM++
Mani Potnuru. Automatic Out-of-Core Exceution Support for CHARM++. 2003
2003
-
[41]
Jonathan A. Booth. Balancing Priorities and Load for State Space Search On Large Parallel Machines. 2003
2003
-
[42]
Orion Sky Lawlor and L. V. Kal \'e. Supporting dynamic parallel object arrays. Concurrency and Computation: Practice and Experience. 2003
2003
-
[43]
Sameer Kumar and L. V. Kale. Scaling Collective Multicast on Fat-tree Networks. ICPADS. 2004
2004
-
[44]
Debugging Support for CHARM++
Rashmi Jyothi. Debugging Support for CHARM++. 2003
2003
-
[45]
Analyzing bidding strategies for schedulers in a simulated multiple-cluster market driven environment
Sindhura Bandhakavi. Analyzing bidding strategies for schedulers in a simulated multiple-cluster market driven environment. 2003
2003
-
[46]
Sameer Kumar and L. V. Kale. Opportunities and Challenges of Modern Communication Architectures: Case Study with QsNet. Proceedings of Workshop on Communication Architecture for Clusters in Conjunction with IPDPS 04. 2004
2004
-
[47]
Laxmikant V. Kal \'e. Performance and Productivity in Parallel Programming via Processor Virtualization. Proc. of the First Intl. Workshop on Productivity and Performance in High-End Computing (at HPCA 10). 2004
2004
-
[48]
An Efficient Implementation of C harm++ on V irtual M achine I nterface
Gregory Allen Koenig. An Efficient Implementation of C harm++ on V irtual M achine I nterface. 2003
2003
-
[49]
Parallelizing CPAIMD Using Charm++
Ramkumar Vadali. Parallelizing CPAIMD Using Charm++. 2003
2003
-
[50]
Simulating Large Parallel Machines for Performance Prediction
Gunavardhan Kakulapati. Simulating Large Parallel Machines for Performance Prediction. 2003
2003
-
[51]
Terry Wilmarth and L. V. Kal\'e. POSE: Getting Over Grainsize in Parallel Discrete Event Simulation. 2004 International Conference on Parallel Processing
2004
-
[52]
Gengbin Zheng and Terry Wilmarth and Orion Sky Lawlor and Laxmikant V. Kal. NSF Next Generation Systems Program Workshop, 18th International Parallel and Distributed Processing Symposium(IPDPS). 2004
2004
-
[53]
Sayantan Chakravorty and L. V. Kale. A Fault Tolerant Protocol for Massively Parallel Machines. FTPDS Workshop for IPDPS 2004. 2004
2004
-
[54]
Rashmi Jyothi and Orion Sky Lawlor and L. V. Kale. Debugging Support for C harm++. PADTAD Workshop for IPDPS 2004. 2004
2004
-
[55]
Kale and Gengbin Zheng and Chee Wai Lee and Sameer Kumar
Laxmikant V. Kale and Gengbin Zheng and Chee Wai Lee and Sameer Kumar. Scaling Applications to Massively Parallel Machines Using Projections Performance Analysis Tool. Future Generation Computer Systems Special Issue on: Large-Scale System Performance Modeling and Analysis
-
[56]
Gengbin Zheng and Lixia Shi and Laxmikant V. Kal\'e. FTC-Charm++: An In-Memory Checkpoint-Based Fault Tolerant Runtime for Charm++ and MPI. 2004 IEEE Cluster
2004
-
[57]
System Support for Checkpoint and Restart of Charm++ and AMPI Applications
Chao Huang. System Support for Checkpoint and Restart of Charm++ and AMPI Applications. 2004
2004
-
[58]
Parallel Simulation of Large Scale Interconnection Networks used in High Performance Computing
Praveen Kumar Jagadishprasad. Parallel Simulation of Large Scale Interconnection Networks used in High Performance Computing. 2004
2004
-
[59]
Kal\'e and Sameer Kumar and Jayant DeSouza and Mani Potnuru and Sindhura Bandhakavi
Laxmikant V. Kal\'e and Sameer Kumar and Jayant DeSouza and Mani Potnuru and Sindhura Bandhakavi. Faucets: Efficient Resource Allocation on the Computational Grid. Proceedings of the 2004 International Conference on Parallel Processing
2004
-
[60]
Kal\'e , title =
Jayant DeSouza and Laxmikant V. Kal\'e , title =. Proceedings of the 17th International Workshop on Languages and Compilers for Parallel Computing , year = 2004, address =
2004
-
[61]
LeanMD: A Charm++ framework for high performance molecular dynamics simulation on large parallel machines
Vikas Mehta. LeanMD: A Charm++ framework for high performance molecular dynamics simulation on large parallel machines. 2004
2004
-
[62]
Gengbin Zheng and Terry Wilmarth and Praveen Jagadishprasad and Laxmikant V. Kal\'e. Simulation-Based Performance Prediction for Large Parallel Machines. International Journal of Parallel Programming
-
[63]
L. V. Kal\' e and Mark Hills and Chao Huang. An Orchestration Language for Parallel Objects. Proceedings of Seventh Workshop on Languages, Compilers, and Run-time Support for Scalable Systems (LCR 04). 2004
2004
-
[64]
Sayantan Chakravorty, Celso Mendes and L. V. Kale. Proactive Fault Tolerance in Large Systems. HPCRI Workshop in conjunction with HPCA 2005. 2005
2005
-
[65]
Koenig and Laxmikant V
Gregory A. Koenig and Laxmikant V. Kale. Using Message-Driven Objects to Mask Latency in Grid Computing Applications. 19th IEEE International Parallel and Distributed Processing Symposium. 2005
2005
-
[66]
Attila Gursoy and L.V. Kal \'e. Performance and Modularity Benefits of Message-Driven Execution. Journal of Parallel and Distributed Computing. 2004
2004
-
[67]
Vadali and Yan Shi and Sameer Kumar and L
Ramkumar V. Vadali and Yan Shi and Sameer Kumar and L. V. Kale and Mark E. Tuckerman and Glenn J. Martyna , title =. Journal of Comptational Chemistry , publisher =
-
[68]
Jade: Compiler-Supported Multi-Paradigm Processor Virtualization-Based Parallel Programming
Jayant DeSouza. Jade: Compiler-Supported Multi-Paradigm Processor Virtualization-Based Parallel Programming. 2004
2004
-
[69]
Wilmarth
Terry L. Wilmarth. POSE: Scalable General-purpose Parallel Discrete Event Simulation. 2005
2005
-
[70]
Kale and Craig Stunkel
Sameer Kumar and Laxmikant V. Kale and Craig Stunkel. Architecture for supporting Hardware Collectives in Output-Queued High-Radix Routers. 2005
2005
-
[71]
Wilmarth and Gengbin Zheng and Eric J
Terry L. Wilmarth and Gengbin Zheng and Eric J. Bohm and Yogesh Mehta and Nilesh Choudhury and Praveen Jagadishprasad and Laxmikant V. Kale. Performance Prediction using Simulation of Large-scale Interconnection Networks in POSE. Proceedings of the Workshop on Principles of Advanced and Distributed Simulation. 2005
2005
-
[72]
Chao Huang and Gengbin Zheng and Sameer Kumar and Laxmikant V. Kal\' e. Performance Evaluation of Adaptive MPI. Proceedings of ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming 2006. 2006
2006
-
[73]
Implementation of parallel mesh partition and ghost generation for the Finite Element Mesh framework
Sayantan Chakravorty. Implementation of parallel mesh partition and ghost generation for the Finite Element Mesh framework. 2005
2005
-
[74]
Achieving high performance on extremely large parallel machines: performance prediction and load balancing
Gengbin Zheng. Achieving high performance on extremely large parallel machines: performance prediction and load balancing. 2005
2005
-
[75]
Strategies for topology-aware task mapping and for rebalancing with bounded migrations
Tarun Agarwal. Strategies for topology-aware task mapping and for rebalancing with bounded migrations. 2005
2005
-
[76]
An Integration Framework for Simulations of Solid Rocket Motors
Xiangmin Jiao and Gengbin Zheng and Orion Lawlor and Phil Alexander and Mike Campbell and Michael Heath and Robert Fiedler. An Integration Framework for Simulations of Solid Rocket Motors. 41st AIAA/ASME/SAE/ASEE Joint Propulsion Conference. 2005
2005
-
[77]
Low diameter regular graph as a network topology in direct and hybrid interconnection networks
Yogesh Mehta. Low diameter regular graph as a network topology in direct and hybrid interconnection networks. 2005
2005
-
[78]
Impostors for Parallel Interactive Computer Graphics
Orion Sky Lawlor. Impostors for Parallel Interactive Computer Graphics. 2004
2004
-
[79]
Wilmarth and Eric J
Nilesh Choudhury and Yogesh Mehta and Terry L. Wilmarth and Eric J. Bohm and Laxmikant V\ . Kal\'e. Scaling an Optimistic Parallel Simulation of Large-scale Interconnection Networks. Proceedings of the Winter Simulation Conference. 2005
2005
-
[80]
Performance Degradation in the Presence of Subnormal Floating-Point Values
Orion Lawlor and Hari Govind and Isaac Dooley and Michael Breitenfeld and Laxmikant Kale. Performance Degradation in the Presence of Subnormal Floating-Point Values. Proceedings of the International Workshop on Operating System Interference in High Performance Applications. 2005
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.