Recognition: 2 theorem links
· Lean TheoremMulti-Quantile Regression for Extreme Precipitation Downscaling
Pith reviewed 2026-05-14 21:05 UTC · model grok-4.3
The pith
A multi-quantile super-resolution network detects extreme precipitation up to 18 times better than deterministic baselines by using pinball loss on separate quantile heads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
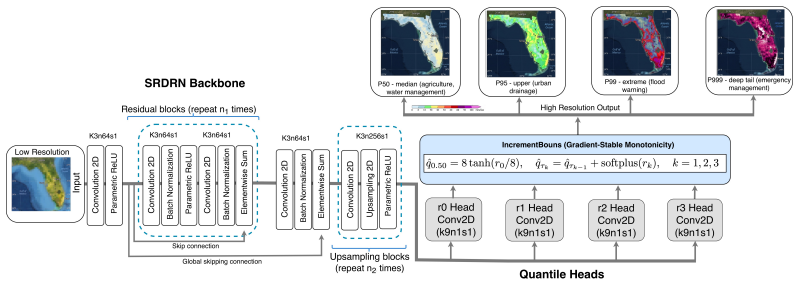
Q-SRDRN is a multi-quantile super-resolution network trained with pinball loss at tau in {0.50, 0.95, 0.99, 0.999}. IncrementBound enforces monotonicity across quantile channels while preserving each channel's gradient identity, and separate per-quantile output heads supply independent filter banks for bulk and tail detection. Under this architecture, data augmentation via cVAE becomes complementary because the median head can absorb synthetic patterns without distorting upper-quantile predictions. The result is large gains in extreme-event detection wherever the large-scale precipitation signal is strong.
What carries the argument
Q-SRDRN with IncrementBound monotonicity constraint and separate per-quantile output heads trained under pinball loss, allowing independent optimization of bulk and tail predictions.
If this is right
- Extreme precipitation detection improves dramatically in convective, tropical-cyclone and atmospheric-river regimes without sacrificing bulk skill.
- Data augmentation can now be applied selectively to the median quantile while tail quantiles remain stable.
- Multi-quantile outputs supply calibrated tail probabilities useful for flood-risk modeling.
- The method transfers across regions provided the large-scale driver remains strong, even when augmentation does not.
Where Pith is reading between the lines
- The same separate-head design could improve extreme-value modeling for other gridded variables such as wind speed or temperature extremes.
- Testing whether the quantile heads can be merged or pruned after training would reduce inference cost while retaining tail accuracy.
- Applying the architecture to global reanalysis datasets could reveal whether the gains persist when large-scale signals are weaker.
Load-bearing premise
The main barrier to extreme-event skill is the loss function averaging real and synthetic targets rather than any shortage of training examples or model capacity.
What would settle it
A controlled experiment in which the same cVAE samples added to a standard single-output network trained with intensity-weighted MAE produce no gain in extreme detection rates, or the multi-quantile version loses its advantage on data where the large-scale precipitation signal is weak.
Figures



read the original abstract
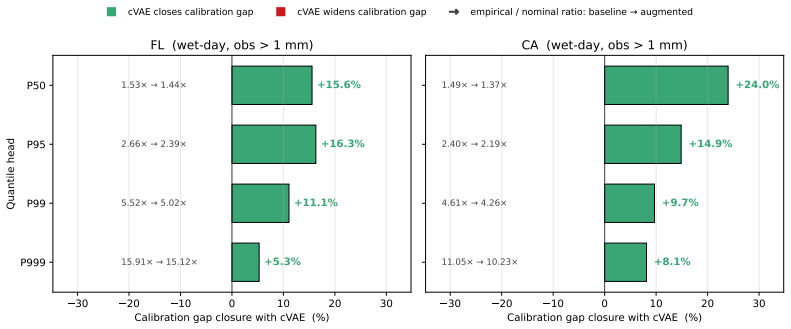
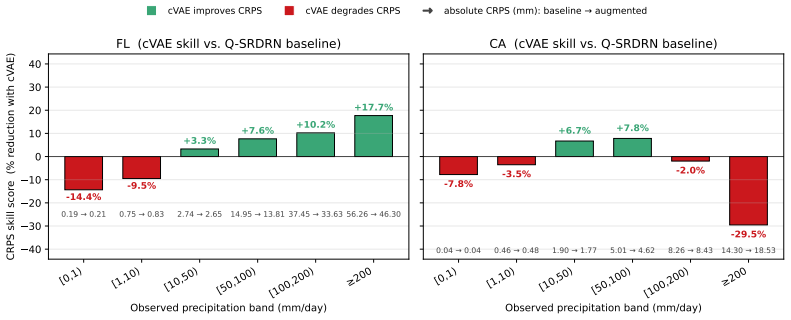
Deep super-resolution networks for precipitation downscaling achieve strong bulk skill yet systematically under-predict the heavy-tail events that drive flood risk. We demonstrate that the primary obstacle is the loss function, not the data: under intensity-weighted MAE, real and synthetic labels at the same input are simply averaged, meaning data augmentation shifts the predicted mean rather than the conditional distribution. We resolve this with Q-SRDRN, a multi-quantile super-resolution network trained with pinball loss at tau in 0.50, 0.95, 0.99, 0.999. Two CNN-specific design choices make this practical: IncrementBound enforces monotonicity while preserving each quantile channel's gradient identity, and separate per-quantile output heads provide independent filter banks for bulk and tail detection. Under this design, data augmentation via cVAE becomes complementary: the median head absorbs synthetic patterns without contaminating upper quantiles. Empirically, on Florida (convective/tropical-cyclone dominated), the un-augmented Q-SRDRN P999 head detects 1,598 of 2,111 events at 200 mm/day versus 88 for the deterministic baseline--an 18x detection-rate gain (4.2% to 75.7%)--with 63% lower KL divergence and 3.9% lower RMSE. Adding cVAE-generated samples lifts the P50 channel from 14 to 1,038 hits at 200 mm/day. On California (atmospheric-river dominated), the architecture reaches near-perfect detection (P999 SEDI >= 0.996 through 300 mm/day). On Texas, the baseline catches only 2 of 10,720 events at 200 mm/day while the P999 head catches 8,776 (81.9%). While the cVAE does not transfer across regions, multi-quantile regression captures extremes wherever the large-scale signal is strong, while augmentation rescues the median where it is not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Q-SRDRN, a multi-quantile super-resolution network for precipitation downscaling trained with pinball loss at tau levels 0.50, 0.95, 0.99, and 0.999. It claims the primary obstacle to capturing heavy-tail events is the loss function rather than data availability, and that two CNN design choices (IncrementBound for monotonicity and separate per-quantile output heads) allow cVAE data augmentation to improve the median without contaminating upper quantiles. Strong empirical gains are reported on three regional datasets, including an 18x increase in detection of 200 mm/day events on Florida data and near-perfect SEDI scores on California.
Significance. If the central claims hold, the work offers a practical route to better extreme-precipitation tails in downscaled fields, which would directly benefit flood-risk and impact modeling. The reported detection-rate and KL-divergence improvements are large enough to be operationally relevant if the isolation between quantile heads can be confirmed.
major comments (1)
- [Architecture description] Architecture description: the claim that separate per-quantile output heads supply independent filter banks and thereby prevent median-head gradients from contaminating tail quantiles is undermined by the shared CNN backbone. Gradients from the pinball loss on the median head (especially when trained on cVAE synthetic samples) flow back through the common convolutional layers and can alter feature maps supplied to the P95/P99/P999 heads; IncrementBound is stated to preserve per-channel gradient identity but does not address this cross-head coupling.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key point about gradient flow in the shared backbone. We address the concern directly below and will revise the manuscript to clarify the architecture's behavior while preserving the empirical claims.
read point-by-point responses
-
Referee: Architecture description: the claim that separate per-quantile output heads supply independent filter banks and thereby prevent median-head gradients from contaminating tail quantiles is undermined by the shared CNN backbone. Gradients from the pinball loss on the median head (especially when trained on cVAE synthetic samples) flow back through the common convolutional layers and can alter feature maps supplied to the P95/P99/P999 heads; IncrementBound is stated to preserve per-channel gradient identity but does not address this cross-head coupling.
Authors: We agree that the shared convolutional backbone permits gradients from the median head (including those arising from cVAE-augmented samples) to propagate into the common feature maps used by the tail heads. The separate output heads do not eliminate this coupling; they only provide quantile-specific parameters after the backbone. However, the design still allows differential specialization: each head applies its own pinball loss, so the optimization can emphasize tail-sensitive features in the later layers even if earlier features are influenced by the median. Empirically, the reported results show that cVAE augmentation improves P50 detection rates while leaving P99/P999 performance stable or improved (e.g., Florida 200 mm/day detection rises from 75.7 % to higher values without degradation of the upper tails). IncrementBound enforces monotonicity per channel but, as noted, does not block cross-head gradient flow. In the revised manuscript we will (i) explicitly acknowledge the shared-backbone coupling, (ii) rephrase the claim to emphasize that separate heads enable per-quantile specialization rather than complete isolation, and (iii) add a short gradient-flow discussion or ablation if space permits. These changes constitute a partial revision. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces Q-SRDRN as an empirical architecture using pinball loss at explicit quantile levels (0.50, 0.95, 0.99, 0.999) together with two CNN design choices (IncrementBound and separate per-quantile heads). All central claims are supported by direct performance measurements against external deterministic baselines and real observations across three regions, with no mathematical derivation, fitted-parameter renaming, or self-citation chain that reduces the reported gains to the inputs by construction. The complementarity of cVAE augmentation is presented as an empirical outcome of the stated design rather than an identity.
Axiom & Free-Parameter Ledger
free parameters (1)
- quantile levels (0.50, 0.95, 0.99, 0.999)
axioms (1)
- domain assumption Pinball loss enables accurate conditional quantile estimation in this super-resolution setting
invented entities (1)
-
IncrementBound
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We resolve this with Q-SRDRN, a multi-quantile super-resolution network trained with pinball loss at τ∈{0.50,0.95,0.99,0.999}. Two CNN-specific design choices make this practical: IncrementBound enforces monotonicity while preserving each quantile channel’s gradient identity, and separate per-quantile output heads provide independent filter banks.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under this design, data augmentation via cVAE becomes complementary: the median head absorbs synthetic patterns without contaminating upper quantiles.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
J. Ba\ no-Medina, R. Manzanas, and J. M. Guti \'e rrez. Configuration and intercomparison of deep learning neural models for statistical downscaling. Geoscientific Model Development, 13(4):2109--2124, 2020. DOI: 10.5194/gmd-13-2109-2020 https://doi.org/10.5194/gmd-13-2109-2020
-
[2]
K. Bi, L. Xie, H. Zhang, X. Chen, X. Gu, and Q. Tian. Accurate medium-range global weather forecasting with 3 D neural networks. Nature, 619(7970):533--538, 2023. DOI: 10.1038/s41586-023-06185-3 https://doi.org/10.1038/s41586-023-06185-3
-
[3]
A. Brando, J. Gimeno, J. A. Rodr\'iguez-Serrano, and J. Vitri\`a. Deep non-crossing quantiles through the partial derivative. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 151 of PMLR, pages 7902--7914, 2022. arXiv: 2201.12848 https://arxiv.org/abs/2201.12848
-
[4]
J. B. Bremnes. Probabilistic forecasts of precipitation in terms of quantiles using NWP model output. Monthly Weather Review, 132(1):338--347, 2004. DOI: 10.1175/1520-0493(2004)132<0338:PFOPIT>2.0.CO;2 https://doi.org/10.1175/1520-0493(2004)132<0338:PFOPIT>2.0.CO;2
-
[5]
A. J. Cannon. Quantile regression neural networks: Implementation in R and application to precipitation downscaling. Computers & Geosciences, 37(9):1277--1284, 2011. DOI: 10.1016/j.cageo.2010.07.005 https://doi.org/10.1016/j.cageo.2010.07.005
-
[6]
A. J. Cannon. Non-crossing nonlinear regression quantiles by monotone composite quantile regression neural network, with application to rainfall extremes. Stochastic Environmental Research and Risk Assessment, 32(11):3207--3225, 2018. DOI: 10.1007/s00477-018-1573-6 https://doi.org/10.1007/s00477-018-1573-6
-
[7]
R. E. Chandler and H. S. Wheater. Analysis of rainfall variability using generalized linear models: a case study from the west of Ireland . Water Resources Research, 38(10):1192, 2002. DOI: 10.1029/2001WR000906 https://doi.org/10.1029/2001WR000906
-
[8]
H. Daniels and M. Velikova. Monotone and partially monotone neural networks. IEEE Transactions on Neural Networks, 21(6):906--917, 2010. DOI: 10.1109/TNN.2010.2044803 https://doi.org/10.1109/TNN.2010.2044803
-
[9]
C. A. T. Ferro and D. B. Stephenson. Extremal dependence indices: Improved verification measures for deterministic forecasts of rare binary events. Weather and Forecasting, 26(5):699--713, 2011. DOI: 10.1175/WAF-D-10-05030.1 https://doi.org/10.1175/WAF-D-10-05030.1
- [10]
-
[11]
T. Gneiting and A. E. Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American Statistical Association, 102(477):359--378, 2007. DOI: 10.1198/016214506000001437 https://doi.org/10.1198/016214506000001437
-
[12]
L. Harris, A. T. T. McRae, M. Chantry, P. D. Dueben, and T. N. Palmer. A generative deep learning approach to stochastic downscaling of precipitation forecasts. Journal of Advances in Modeling Earth Systems, 14(10):e2022MS003120, 2022. DOI: 10.1029/2022MS003120 https://doi.org/10.1029/2022MS003120
-
[13]
D. P. Kingma and M. Welling. Auto-encoding variational B ayes. In International Conference on Learning Representations (ICLR), 2014. arXiv: 1312.6114 https://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
R. Koenker and K. F. Hallock. Quantile regression. Journal of Economic Perspectives, 15(4):143--156, 2001. DOI: 10.1257/jep.15.4.143 https://doi.org/10.1257/jep.15.4.143
-
[15]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncertainty estimation using deep ensembles. In Advances in Neural Information Processing Systems (NeurIPS), pages 6402--6413, 2017. arXiv: 1612.01474 https://arxiv.org/abs/1612.01474
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[16]
H. Liu, S. Zhu, and L. Mo. A novel daily runoff probability density prediction model based on simplified minimal gated memory--non-crossing quantile regression and kernel density estimation. Water, 15(22):3947, 2023. DOI: 10.3390/w15223947 https://doi.org/10.3390/w15223947
-
[17]
M. Mardani, N. Brenowitz, Y. Cohen, J. Pathak, C.-Y. Chen, C.-C. Liu, A. Vahdat, M. A. Nabian, T. Ge, A. Subramaniam, K. Kashinath, J. Kautz, and M. Pritchard. Residual corrective diffusion modeling for km-scale atmospheric downscaling. Communications Earth & Environment, 6:124, 2025. DOI: 10.1038/s43247-025-02042-5 https://doi.org/10.1038/s43247-025-02042-5
-
[18]
T. Vandal, E. Kodra, J. Dy, S. Ganguly, R. Nemani, and A. R. Ganguly. Quantifying uncertainty in discrete-continuous and skewed data with B ayesian deep learning. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), pages 2377--2386, 2018. DOI: 10.1145/3219819.3219996 https://doi.org/10.1145/3219819.3219996
-
[19]
In: Proceedings of the 40th International Conference on Machine Learning
T. Nguyen, J. Brandstetter, A. Kapoor, J. K. Gupta, and A. Grover. ClimaX : A foundation model for weather and climate. In Proceedings of the 40th International Conference on Machine Learning (ICML), pages 25904--25938, 2023. arXiv: 2301.10343 https://arxiv.org/abs/2301.10343
-
[20]
J. Pathak, S. Subramanian, P. Harrington, S. Raja, A. Chattopadhyay, M. Mardani, T. Kurth, D. Hall, Z. Li, K. Azizzadenesheli, P. Hassanzadeh, K. Kashinath, and A. Anandkumar. FourCastNet : A global data-driven high-resolution weather model using adaptive F ourier neural operators. arXiv preprint, 2022. arXiv: 2202.11214 https://arxiv.org/abs/2202.11214
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
I. Price and S. Rasp. Increasing the accuracy and resolution of precipitation forecasts using deep generative models. In Proceedings of the 25th International Conference on Artificial Intelligence and Statistics (AISTATS), volume 151 of PMLR, pages 10555--10571, 2022
work page 2022
-
[22]
Nature637, 84–90 (2025) https://doi.org/10.1038/s41586-024-08252-9
I. Price, A. Sanchez-Gonzalez, F. Alet, T. R. Andersson, A. El-Kadi, D. Masters, T. Ewalds, J. Stott, S. Mohamed, P. Battaglia, R. Lam, and M. Willson. Probabilistic weather forecasting with machine learning. Nature, 637(8044):84--90, 2025. DOI: 10.1038/s41586-024-08252-9 https://doi.org/10.1038/s41586-024-08252-9
-
[23]
S. Ravuri, K. Lenc, M. Willson, D. Kangin, R. Lam, P. Mirowski, M. Fitzsimons, M. Athanassiadou, S. Kashem, S. Madge, R. Prudden, A. Mandhane, A. Clark, A. Brock, K. Simonyan, R. Hadsell, N. Robinson, E. Clancy, A. Arribas, and S. Mohamed. Skilful precipitation nowcasting using deep generative models of radar. Nature, 597(7878):672--677, 2021. DOI: 10.103...
-
[24]
Y. Sha, D. J. Gagne II, G. West, and R. Stull. Deep-learning-based gridded downscaling of surface meteorological variables in complex terrain. Part I : Daily maximum and minimum 2-m temperature. Journal of Applied Meteorology and Climatology, 59(12):2057--2073, 2020. DOI: 10.1175/JAMC-D-20-0057.1 https://doi.org/10.1175/JAMC-D-20-0057.1
-
[25]
K. Sohn, X. Yan, and H. Lee. Learning structured output representation using deep conditional generative models. In Advances in Neural Information Processing Systems (NeurIPS), pages 3483--3491, 2015
work page 2015
-
[26]
T. Vandal, E. Kodra, S. Ganguly, A. Michaelis, R. Nemani, and A. R. Ganguly. DeepSD : Generating high resolution climate change projections through single image super-resolution. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), pages 1663--1672, 2017. DOI: 10.1145/3097983.3098004 https://doi.org/...
-
[27]
A. W. Wood, L. R. Leung, V. Sridhar, and D. P. Lettenmaier. Hydrologic implications of dynamical and statistical approaches to downscaling climate model outputs. Climatic Change, 62(1--3):189--216, 2004. DOI: 10.1023/B:CLIM.0000013685.99609.9e https://doi.org/10.1023/B:CLIM.0000013685.99609.9e
-
[28]
F. Wang, D. Tian, L. Lowe, L. Kalin, and J. Lehrter. Deep learning for daily precipitation and temperature downscaling. Water Resources Research, 57(4):e2020WR029308, 2021. DOI: 10.1029/2020WR029308 https://doi.org/10.1029/2020WR029308
-
[29]
A. Wehenkel and G. Louppe. Unconstrained monotonic neural networks. In Advances in Neural Information Processing Systems (NeurIPS), pages 1543--1553, 2019. arXiv: 1908.05164 https://arxiv.org/abs/1908.05164
-
[30]
E. Zorita and H. von Storch. The analog method as a simple statistical downscaling technique: comparison with more complicated methods. Journal of Climate, 12(8):2474--2489, 1999. DOI: 10.1175/1520-0442(1999)012<2474:TAMAAS>2.0.CO;2 https://doi.org/10.1175/1520-0442(1999)012<2474:TAMAAS>2.0.CO;2
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.