Recognition: unknown
From Heuristics to Analytics: Forecasting Effort and Progress in Online Learning
Pith reviewed 2026-05-14 20:27 UTC · model grok-4.3
The pith
Feature-based models forecast weekly student effort and progress in tutoring systems with 22-33 percent lower error than heuristic rules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
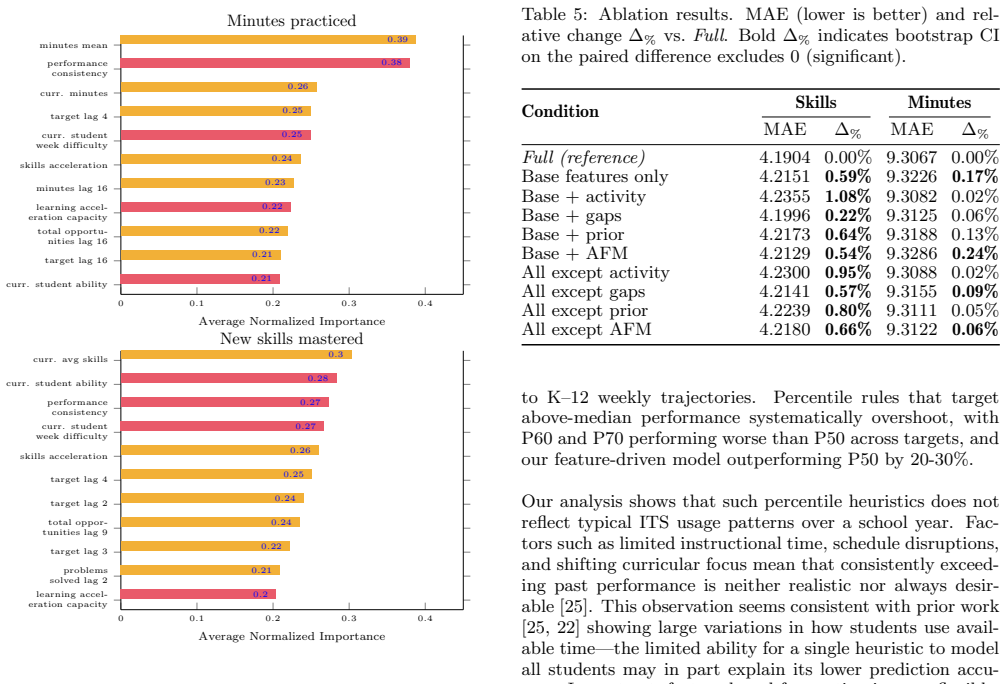
Using interaction logs from 425 middle-school students across a school year, feature-based predictors reduce mean absolute error by 22-33 percent compared with percentile-based heuristic baselines when forecasting weekly minutes practiced and new skills mastered. The models track individual practice trajectories more closely than fixed rules, with effort forecasts driven chiefly by recent activity features and progress forecasts depending more on learner-state and content difficulty signals. In a case study, eight college tutors reasoned about effort versus progress goals in ways that aligned with these target-specific feature patterns.
What carries the argument
Supervised machine learning models that use interaction-log features to predict two weekly targets, benchmarked against fixed-percentile heuristic rules adapted from prior behavioral work.
Load-bearing premise
The 425-student log dataset and selected features capture patterns representative enough for the models to generalize to new students and new weeks without large distribution shifts.
What would settle it
A fresh cohort of student logs in which the feature-based models show no reduction in mean absolute error, or a reduction below 15 percent, relative to the same percentile heuristics.
Figures


read the original abstract
Sustained effort is essential for realizing the benefits of intelligent tutoring systems (ITS), yet many learners disengage or underuse available practice time. We introduce engagement forecasting as a supervised prediction task based on ITS logs, targeting two outcomes central to effort and learning progress: minutes practiced per week and new skills mastered per week. Using interaction log data from 425 middle-school students over a school year, we benchmark fifteen predictors including regressions, decision trees, and neural networks. We show that these feature-based models reduce mean absolute error (MAE) by 22-33% relative to heuristic baselines, including fixed-percentile rules adapted from prior work in other behavioral domains. We find that percentile heuristics systematically overpredict, whereas feature-based models better track student practice trajectories across weeks. To support explainability, we analyze feature importance and ablations, revealing target-specific patterns: effort forecasting is driven mainly by recent activity features, while progress forecasting depends more on learner-state and content difficulty signals. Finally, in a semi-structured user interview case study with eight college tutors, we examine how tutors reasoned about system-generated predictive features when setting goals with students. We find that tutors reasoned differently about effort versus progress goals in ways that mirror our pattern analysis. Together, these results establish a reproducible benchmark for forecasting weekly effort and learning progress in ITS. By making patterns of sustained effort and progress visible at a weekly timescale, engagement forecasting offers a foundation for supporting tutor-learner goal setting and timely instructional decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces engagement forecasting as a supervised prediction task on ITS interaction logs from 425 middle-school students, targeting weekly minutes practiced and new skills mastered. It benchmarks fifteen feature-based models (regressions, decision trees, neural networks) against heuristic baselines such as fixed-percentile rules, reporting 22-33% MAE reductions, provides feature-importance and ablation analyses showing recent activity driving effort forecasts while learner-state and content difficulty drive progress forecasts, and includes a semi-structured interview case study with eight tutors on using the predictions for goal setting.
Significance. If the central MAE reductions hold under proper out-of-sample validation, the work supplies a reproducible benchmark for weekly effort and progress forecasting in intelligent tutoring systems, moving beyond ad-hoc heuristics toward analytics-driven support for tutor-learner goal setting. The target-specific feature patterns and the tutor interview results add explanatory and practical value; the public benchmark framing is a clear strength.
major comments (2)
- [Benchmarking / Experimental Setup] Benchmarking / Experimental Setup: The train-test partitioning procedure is not stated to be student-stratified (or week-stratified). Because the data consist of repeated weekly observations per student, any split that allows the same student to appear in both training and test sets risks temporal autocorrelation leakage, which would inflate the reported 22-33% MAE gains relative to the percentile heuristics and undermine the out-of-sample forecasting claim.
- [Results] Results section: No statistical significance tests, confidence intervals, or cross-validation variance estimates are provided for the MAE differences across the fifteen models and two targets. Without these, it is impossible to determine whether the observed improvements are reliable or could be explained by sampling variability in the 425-student corpus.
minor comments (2)
- [Methods] The abstract states that fifteen predictors were benchmarked, yet the methods section would benefit from an explicit enumerated list of all models together with their hyperparameter ranges or selection procedure.
- [Feature Engineering] Feature definitions (especially the 'recent activity' and 'learner-state' groups) are described at a high level; a table listing each feature, its computation, and any normalization would improve reproducibility.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on the experimental validation and statistical reporting. We have revised the manuscript to clarify the data partitioning procedure and to include statistical significance tests and confidence intervals for the reported MAE improvements. Our responses to the major comments are detailed below.
read point-by-point responses
-
Referee: [Benchmarking / Experimental Setup] Benchmarking / Experimental Setup: The train-test partitioning procedure is not stated to be student-stratified (or week-stratified). Because the data consist of repeated weekly observations per student, any split that allows the same student to appear in both training and test sets risks temporal autocorrelation leakage, which would inflate the reported 22-33% MAE gains relative to the percentile heuristics and undermine the out-of-sample forecasting claim.
Authors: We thank the referee for highlighting this critical aspect of the experimental design. Upon review, the train-test split in our study was indeed performed in a student-stratified manner, with all weekly observations for a given student assigned entirely to either the training or test set (70/30 split). This prevents any leakage from temporal autocorrelation within students. We have updated the manuscript's Experimental Setup section to explicitly state this partitioning strategy and its rationale for ensuring valid out-of-sample forecasting. revision: yes
-
Referee: [Results] Results section: No statistical significance tests, confidence intervals, or cross-validation variance estimates are provided for the MAE differences across the fifteen models and two targets. Without these, it is impossible to determine whether the observed improvements are reliable or could be explained by sampling variability in the 425-student corpus.
Authors: We agree that providing measures of statistical reliability strengthens the results. In the revised manuscript, we have added bootstrap-derived 95% confidence intervals for all MAE values and conducted paired statistical tests (Wilcoxon signed-rank tests due to non-normality of errors) comparing each model's per-student MAE against the heuristic baselines. The improvements remain significant (p < 0.001) across targets, with the confidence intervals confirming the 22-33% reductions are not attributable to sampling variability alone. These additions are incorporated into the Results section and a new supplementary table. revision: yes
Circularity Check
No significant circularity: supervised forecasting trained on historical logs to predict future weeks
full rationale
The paper trains feature-based models (regressions, trees, neural nets) on 425-student ITS logs to forecast weekly minutes practiced and skills mastered. Heuristic baselines are percentile rules adapted from external prior work in other domains. No equation or fitting step reduces the target variable to a parameter of itself by construction; the reported 22-33% MAE reduction is an empirical out-of-sample comparison on future weeks. The derivation chain is self-contained against external benchmarks and does not rely on self-citation for its central claim.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. A. Adams, J. C. Hurley, M. Todd, N. Bhuiyan, C. L. Jarrett, W. J. Tucker, K. E. Hollingshead, and S. S. Angadi. Adaptive goal setting and financial incentives: a 2×2 factorial randomized controlled trial to increase adults’ physical activity.BMC Public Health, 17(1):1– 16, 2017
2017
-
[2]
Albreiki, N
B. Albreiki, N. Zaki, and H. Alashwal. A systematic literature review of student’ performance prediction us- ing machine learning techniques.Education Sciences, 11(9):1–27, 2021
2021
- [3]
-
[4]
Arroyo, H
I. Arroyo, H. Meheranian, and B. P. Woolf. Effort-based tutoring: An empirical approach to intelligent tutoring. InProceedings of the 3rd International Conference on Educational Data Mining (EDM), pages 1–10, 2010
2010
-
[5]
R. S. Baker, A. T. Corbett, and K. R. Koedinger. Detecting student misuse of intelligent tutoring sys- tems. InProceedings of the 7th International Confer- ence on Intelligent Tutoring Systems (ITS), pages 531– 540, 2004
2004
-
[6]
R. S. J. d. Baker. Modeling and understanding students’ off-task behavior in intelligent tutoring systems. InPro- ceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI), pages 1059–1068, 2007
2007
-
[7]
R. S. J. d. Baker, S. M. Gowda, M. Wixon, J. Kalka, A. Z. Wagner, A. Salvi, V. Aleven, G. W. Kusbit, J. Ocumpaugh, and L. M. Rossi. Towards sensor-free affect detection in cognitive tutor algebra. InPro- ceedings of the 5th International Conference on Educa- tional Data Mining (EDM 2012), pages 126–133, Cha- nia, Greece, 2012. International Educational Da...
2012
-
[8]
C. R. Beal, I. M. Arroyo, P. R. Cohen, and B. P. Woolf. Evaluation of animalwatch: An intelligent tutoring sys- tem for arithmetic and fractions.Journal of Interactive Online Learning, 9(1):64–77, 2010
2010
-
[9]
Bembenutty
H. Bembenutty. Meaningful and maladaptive home- work practices: The role of self-efficacy and self- regulation.Journal of Advanced Academics, 22(3):448– 473, 2011
2011
-
[10]
M. L. Bernacki, T. J. Nokes-Malach, and V. Aleven. Examining self-efficacy during learning: Variability and relations to behavior, performance, and learning. Metacognition and Learning, 10:99–117, 2015
2015
-
[11]
Borchers, A
C. Borchers, A. Houk, V. Aleven, and K. R. Koedinger. Engagement and learning benefits of goal setting with rewards in human-ai tutoring. In A. I. Cristea, E. Walker, Y. Lu, O. C. Santos, and S. Isotani, editors, Artificial Intelligence in Education. AIED 2025. Lec- ture Notes in Computer Science, volume 15880, pages 46–59. Springer, Cham, 2025
2025
-
[12]
Borchers, J
C. Borchers, J. Ooge, C. Peng, and V. Aleven. How learner control and explainable learning analytics about skill mastery shape student desires to finish and avoid loss in tutored practice. InProceedings of the 15th In- ternational Learning Analytics and Knowledge Confer- ence, LAK 2025, page 810–816. ACM, Mar. 2025
2025
-
[13]
Borchers, C
C. Borchers, C. Peng, Q. Lyu, P. F. Carvalho, K. R. Koedinger, and V. Aleven. Student perceptions of adap- tive goal setting recommendations: A design prototyp- ing study. In A. I. Cristea, E. Walker, Y. Lu, O. C. Santos, and S. Isotani, editors,Artificial Intelligence in Education, pages 244–251, Cham, 2025. Springer Na- ture Switzerland
2025
-
[14]
Bull and J
S. Bull and J. Kay. Student models that invite the learner in: The smili open learner modelling framework technical report 580.I. J. Artificial Intelligence in Ed- ucation, 17, 01 2007
2007
-
[15]
H. Cen, K. Koedinger, and B. Junker. Learning factors analysis - a general method for cognitive model evalua- tion and improvement. InInternational Conference on Intelligent Tutoring Systems, pages 164–175, 2006
2006
-
[16]
H. Cen, K. Koedinger, and B. Junker. Comparing two irt models for conjunctive skills. InInternational Con- ference on Intelligent Tutoring Systems, pages 796–798, 2008
2008
-
[17]
Chen and C
T. Chen and C. Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining, pages 785–794, 2016
2016
-
[18]
A. T. Corbett and J. R. Anderson. Knowledge tracing: Modeling the acquisition of procedural knowledge.User Modeling and User-Adapted Interaction, 4(4):253–278, Dec. 1994
1994
-
[19]
A. T. Corbett, K. R. Koedinger, and J. R. Ander- son. Intelligent tutoring systems. In M. G. Helander, T. K. Landauer, and P. V. Prabhu, editors,Handbook of Human-Computer Interaction, chapter 37, pages 849–
-
[20]
Elsevier Science B.V., Amsterdam, The Nether- lands, 2 edition, 1997
1997
-
[21]
S. C. Dang.Exploring Behavioral Measurement Mod- els of Learner Motivation. Ph.d. thesis, Carnegie Mel- lon University, School of Computer Science, Pittsburgh, PA, USA, Feb. 26 2022. CMU–HCII–21–109
2022
-
[22]
G. W. Dekker, M. Pechenizkiy, and J. M. Vleeshouw- ers. Predicting students drop out: A case study. In Proceedings of the 2nd International Conference on Ed- ucational Data Mining, pages 41–50, Cordoba, Spain,
-
[23]
International Working Group on Educational Data Mining
-
[24]
Eames, E
T. Eames, E. Brunskill, B. Yamkovenko, K. Weather- holtz, and P. Oreopoulos. Computer-assisted learning in the real world: How khan academy influences student math learning.Proceedings of the National Academy of Sciences, 123(1):e2507708123–e2507708123, 2026
2026
-
[25]
Gardner, Y
J. Gardner, Y. Yang, R. S. Baker, and C. Brooks. Mod- eling and experimental design for mooc dropout pre- diction: A replication perspective. InProceedings of the 12th International Conference on Educational Data Mining (EDM 2019), pages 49–58, 2019
2019
-
[26]
Grimaldi, K
P. Grimaldi, K. Weatherholtz, and K. M. Hill. Esti- mating the causal effects of Khan Academy MAP Ac- celerator across demographic subgroups. InProceed- ings of the 15th International Conference on Educa- tional Data Mining, pages 839–846, Durham, United Kingdom, 2022. International Educational Data Min- ing Society
2022
-
[27]
Gurung, J
A. Gurung, J. Lin, Z. Huang, C. Borchers, R. Baker, V. Aleven, and K. Koedinger. Starting seatwork earlier as a valid measure of student engagement. In C. Mills, G. Alexandron, D. Taibi, G. L. Bosco, and L. Paque- tte, editors,Proceedings of the 18th International Con- ference on Educational Data Mining, pages 303–316, Palermo, Italy, July 2025. Internati...
2025
-
[28]
Hattie.Visible Learning: A Synthesis of Over 800 Meta-Analyses Relating to Achievement
J. Hattie.Visible Learning: A Synthesis of Over 800 Meta-Analyses Relating to Achievement. Routledge, London, UK, 2009
2009
-
[29]
T. K. Ho. Random decision forests.Proceedings of the 3rd International Conference on Document Analysis and Recognition, 1:278–282, 1995
1995
-
[30]
A. E. Hoerl and R. W. Kennard. Ridge regression: Bi- ased estimation for nonorthogonal problems.Techno- metrics, 12(1):55–67, 1970
1970
-
[31]
L. Holt. The 5 percent problem: Online mathematics programs may benefit most the kids who need it least. Education Next, 24(4):26–31, apr 2024
2024
-
[32]
Hooshyar, M
D. Hooshyar, M. Pedaste, K. Saks, ¨Ali Leijen, E. Bar- done, and M. Wang. Open learner models in sup- porting self-regulated learning in higher education: A systematic literature review.Computers & Education, 154:103878–103878, 2020
2020
-
[33]
K. R. Koedinger, J. Kim, J. Z. Jia, E. A. McLaughlin, and N. L. Bier. Learning is not a spectator sport: Doing is better than watching for learning from a mooc. In Proceedings of the Second (2015) ACM Conference on Learning @ Scale, L@S ’15, page 111–120, New York, NY, USA, 2015. Association for Computing Machinery
2015
-
[34]
Kovanovic, D
V. Kovanovic, D. Gaˇ sevi´ c, S. Dawson, S. Joksimovic, and R. Baker. Does time-on-task estimation matter? implications on validity of learning analytics findings. Journal of Learning Analytics, 2(3):81–110, Feb. 2016
2016
-
[35]
J. A. Kulik and J. D. Fletcher. Effectiveness of intelli- gent tutoring systems: A meta-analytic review.Review of Educational Research, 86(1):42–78, 2016
2016
-
[36]
E. A. Locke and G. P. Latham. Building a practically useful theory of goal setting and task motivation: A 35- year Odyssey.American Psychologist, 57(9):705–717, Sept. 2002. PMID: 12237980
2002
-
[37]
E. A. Locke and G. P. Latham. The development of goal setting theory: A half century retrospective.Motivation Science, 5(2):93–105, 2019
2019
-
[38]
W. Ma, O. O. Adesope, J. C. Nesbit, and Q. Liu. Intelligent tutoring systems and learning outcomes: A meta-analysis.Journal of Educational Psychology, 106(4):901–918, 2014
2014
-
[39]
T. Mu, A. Jetten, and E. Brunskill. Towards suggesting actionable interventions for wheel-spinning students. In Proceedings of the 13th International Conference on Ed- ucational Data Mining, pages 183–193, Online, 2020. International Educational Data Mining Society
2020
-
[40]
C. Peng, C. Borchers, and V. Aleven. Designing home- work support tools for middle school mathematics us- ing intelligent tutoring systems. InProceedings of the 18th International Conference of the Learning Sciences (ICLS 2024), pages 1730–1733, Buffalo, NY, USA,
2024
-
[41]
International Society of the Learning Sciences
-
[42]
Ritter, A
S. Ritter, A. Joshi, S. Fancsali, and T. Nixon. Predict- ing standardized test scores from cognitive tutor inter- actions. In S. K. D’Mello, R. A. Calvo, and A. Ol- ney, editors,Proceedings of the 6th International Con- ference on Educational Data Mining, Memphis, Ten- nessee, USA, July 6-9, 2013, pages 169–176. Interna- tional Educational Data Mining Soc...
2013
-
[43]
R. M. Ryan and E. L. Deci. Self-determination the- ory and the facilitation of intrinsic motivation, social development, and well-being.American Psychologist, 55(1):68–78, 2000
2000
-
[44]
Schaldenbrand, N
P. Schaldenbrand, N. G. Lobczowski, J. E. Richey, S. Gupta, E. A. McLaughlin, A. Adeniran, and K. R. Koedinger. Computer-supported human mentoring for personalized and equitable math learning. InAr- tificial Intelligence in Education: 22nd International Conference, AIED 2021, Utrecht, The Netherlands, June 14–18, 2021, Proceedings, Part II, page 308–313, ...
2021
-
[45]
D. H. Schunk. Goal setting and self-efficacy during self- regulated learning.Educational Psychologist, 25(1):71– 86, 1990
1990
-
[46]
G. A. Seber and A. J. Lee.Linear Regression Analysis. Wiley, 2003
2003
-
[47]
Stamper, K
J. Stamper, K. Koedinger, R. S. J. d. Baker, A. Skogsholm, B. Leber, J. Rankin, and S. Demi. Pslc datashop: A data analysis service for the learning sci- ence community. In V. Aleven, J. Kay, and J. Mostow, editors,Intelligent Tutoring Systems, pages 455–455, Berlin, Heidelberg, 2010. Springer Berlin Heidelberg
2010
-
[48]
Tibshirani
R. Tibshirani. Regression shrinkage and selection via the lasso.Journal of the Royal Statistical Society: Se- ries B (Methodological), 58(1):267–288, 1996
1996
-
[49]
K. VanLehn. The behavior of tutoring systems.Inter- national Journal of Artificial Intelligence in Education, 16(3):227–265, 2006
2006
-
[50]
K. VanLehn. The relative effectiveness of human tu- toring, intelligent tutoring systems, and other tutoring systems.Educational psychologist, 46(4):197–221, 2011
2011
-
[51]
L. S. Vygotsky. Interaction between learning and de- velopment. In M. Cole, V. John-Steiner, S. Scribner, and E. Souberman, editors,Mind in Society: Develop- ment of Higher Psychological Processes, pages 79–91. Harvard University Press, Cambridge, MA, 1978
1978
-
[52]
Wan and J
H. Wan and J. B. Beck. Considering the influence of prerequisite performance on wheel spinning. InProceed- ings of the 8th International Conference on Educational Data Mining, pages 129–135, Madrid, Spain, 2015. In- ternational Educational Data Mining Society
2015
-
[53]
H. Wan, J. Ding, X. Gao, and D. E. Pritchard. Dropout prediction in MOOCs using learners’ study habits fea- tures. InProceedings of the 10th International Confer- ence on Educational Data Mining, pages 408–409, 2017
2017
-
[54]
W ¨aschle, A
K. W ¨aschle, A. Allgaier, A. Lachner, S. Fink, and M. N¨uckles. Procrastination and self-efficacy: Tracing vicious and virtuous circles in self-regulated learning. Learning and Instruction, 29:103–114, 02 2014
2014
-
[55]
M. Xia, R. Schmucker, C. Borchers, and V. Aleven. Optimizing mastery learning by fast-forwarding over- practice steps. InTwo Decades of TEL. From Lessons Learnt to Challenges Ahead: 20th European Confer- ence on Technology Enhanced Learning, EC-TEL 2025, Newcastle upon Tyne and Durham, UK, September 15–19, 2025, Proceedings, Part I, page 549–563, Berlin, ...
2025
-
[56]
A. F. Zambrano, R. S. Baker, S. Baral, N. T. Heffernan, and A. Lan. From reaction to anticipation: Predicting future affect. InProceedings of the 17th International Conference on Educational Data Mining, pages 566– 574, Atlanta, Georgia, USA, July 2024. International Educational Data Mining Society
2024
-
[57]
Zhang, Y
C. Zhang, Y. Huang, J. Wang, D. Lu, W. Fang, J. C. Stamper, S. E. Fancsali, K. Holstein, and V. Aleven. Early detection of wheel spinning: Comparison across tutors, models, features, and operationalizations. In Proceedings of the 12th International Conference on Ed- ucational Data Mining, pages 468–473, Montr´ eal, QC, Canada, 2019. International Educatio...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.