Recognition: 2 theorem links
· Lean TheoremFast and Stable Gradient Approximation for Bilinear Forms of Hermitian Matrix Functions
Pith reviewed 2026-05-14 19:28 UTC · model grok-4.3
The pith
A forward-only gradient approximation reuses the Lanczos pass to stably differentiate bilinear forms u^T f(A(θ))v for Hermitian A with error proportional to the residual norm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a forward-only gradient approximation that reuses the Lanczos pass and adds very minimal overhead in most cases. We prove that its error is proportional to the Lanczos residual norm, the same quantity controlling the forward approximation. Whereas a traditional adjoint-based calculation would be unstable without reorthogonalization, the new method appears unconditionally stable in our tests. It is also faster than existing state-of-the-art approaches.
What carries the argument
Forward-only gradient approximation that reuses Lanczos vectors and eigenvalues from the forward pass to compute the derivative of the bilinear form without additional orthogonalization or block augmentation.
If this is right
- The same residual norm tolerance can be used to control accuracy for both the bilinear form value and its gradient.
- No reorthogonalization is required, avoiding the extra computation and memory traffic of adjoint or augmented-matrix methods.
- The approach reduces runtime compared with backpropagation through the Lanczos recurrence or Arnoldi on a doubled-size block matrix.
- It applies directly to large-scale problems where bilinear forms of matrix functions arise in optimization and inference.
Where Pith is reading between the lines
- If the observed stability generalizes, the method could replace custom adjoint implementations in libraries for differentiable linear algebra.
- Similar reuse of residual information might extend to other Krylov solvers when the matrix is non-Hermitian.
- The result suggests residual norms could serve as practical error indicators for both primal and sensitivity quantities in iterative matrix computations.
Load-bearing premise
The method assumes A(θ) remains Hermitian for all parameters so Lanczos produces real eigenvalues and orthogonal vectors, and that the forward residual norm reliably bounds the gradient error as well.
What would settle it
Numerical tests on Hermitian matrices where the observed gradient error grows substantially larger than the Lanczos residual norm while using the forward-only method would disprove the error proportionality claim.
Figures


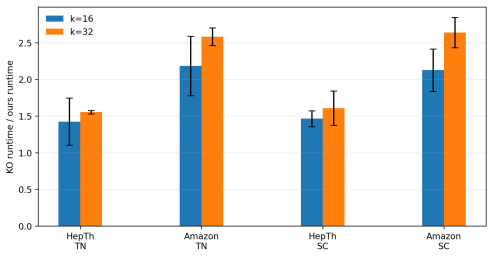

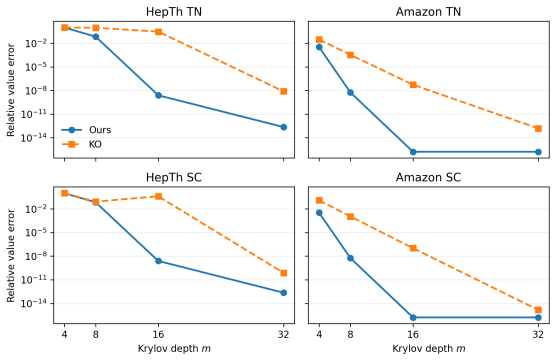
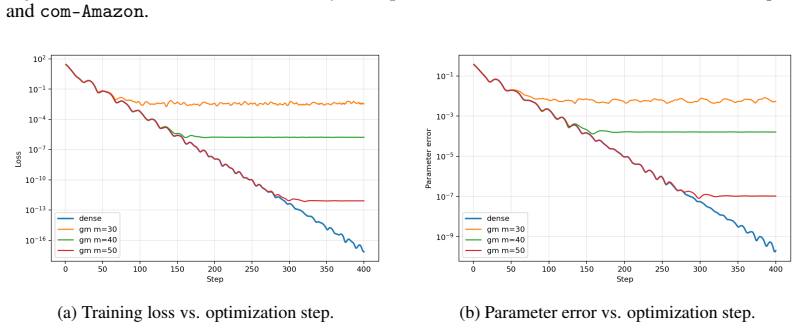
read the original abstract
Objectives involving bilinear forms $u^\top f(A(\theta))v$ for Hermitian $A$ arise widely in scientific computing and probabilistic machine learning. For large matrices, Lanczos efficiently approximates these quantities, but differentiating them with respect to $\theta$ is challenging. Existing approaches either backpropagate through the Lanczos recurrence, requiring reorthogonalization for stability, or apply Arnoldi to an augmented block matrix of twice the original size. Both introduce extra computation and orthogonalization costs that can limit performance on modern hardware. We propose a forward-only gradient approximation that reuses the Lanczos pass and adds very minimal overhead in most cases. We prove that its error is proportional to the Lanczos residual norm, the same quantity controlling the forward approximation. Whereas a traditional adjoint-based calculation would be unstable without reorthogonalization, the new method appears unconditionally stable in our tests. It is also faster than existing state-of-the-art approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a forward-only gradient approximation for bilinear forms u^T f(A(θ)) v with Hermitian A(θ), reusing the Lanczos pass with minimal overhead. It proves the gradient error is proportional to the Lanczos residual norm and reports that the method appears unconditionally stable in numerical tests, offering advantages over adjoint-based methods that require reorthogonalization.
Significance. If the unconditional stability holds rigorously, this approach could provide a more efficient and stable way to compute gradients in large-scale applications involving matrix functions, such as in probabilistic machine learning and scientific computing. The reuse of the Lanczos pass and the error bound tied to the residual norm are notable strengths, as is the parameter-free nature of the error control.
major comments (2)
- [Abstract] Abstract: The assertion that the new method 'appears unconditionally stable in our tests' lacks a supporting theorem, characterization of the admissible class of Hermitian A(θ) and functions f, or analysis of potential failure modes such as clustered spectra or large ||dA/dθ||; this empirical claim is load-bearing for the practical advantage over adjoint methods.
- [Proof section] Proof of error bound (likely §3): While the proportionality of gradient error to the Lanczos residual norm is established, the manuscript does not extend the analysis to guarantee stability without reorthogonalization, leaving the central stability advantage as an observation rather than a derived result.
minor comments (2)
- [Introduction] Ensure all assumptions on f (e.g., analyticity) are stated explicitly in the introduction and restated in the stability discussion.
- [Numerical experiments] Figure captions for numerical tests should include the range of matrix sizes, spectrum types, and function classes tested to allow reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the forward-only Lanczos gradient approximation. We address the two major comments below, agreeing where the manuscript relies on empirical evidence rather than theorems.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the new method 'appears unconditionally stable in our tests' lacks a supporting theorem, characterization of the admissible class of Hermitian A(θ) and functions f, or analysis of potential failure modes such as clustered spectra or large ||dA/dθ||; this empirical claim is load-bearing for the practical advantage over adjoint methods.
Authors: We agree that the stability statement in the abstract is empirical. In the revision we will rephrase the abstract to read 'numerical experiments suggest that the method remains stable without reorthogonalization' and expand the numerical section with additional experiments on clustered spectra, large ||dA/dθ||, and a wider range of f. A complete theoretical characterization of admissible (A(θ),f) pairs is beyond the current scope but we will add a short discussion of observed failure modes. revision: partial
-
Referee: [Proof section] Proof of error bound (likely §3): While the proportionality of gradient error to the Lanczos residual norm is established, the manuscript does not extend the analysis to guarantee stability without reorthogonalization, leaving the central stability advantage as an observation rather than a derived result.
Authors: The referee correctly notes that the error bound is proven while unconditional stability is only observed. We will revise the relevant section to explicitly label the stability claim as an empirical observation, include a brief heuristic argument based on the forward-only structure, and report additional numerical diagnostics. A rigorous proof of stability for arbitrary Hermitian A(θ) and f remains an open question. revision: partial
- Rigorous theorem guaranteeing unconditional stability without reorthogonalization for general Hermitian A(θ) and functions f
Circularity Check
No circularity; error bound and stability claim rest on independent residual norm and empirical tests
full rationale
The derivation proves gradient error proportional to the independently computed Lanczos residual norm (same controller as the forward bilinear-form error) without reducing to a fitted parameter, self-definition, or self-citation chain. No equations rename a known result or smuggle an ansatz via prior work by the same authors. The stability assertion is presented as an empirical observation from tests rather than a theorem derived from the method's own inputs, so the central claims remain self-contained and externally falsifiable via residual norms.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A(θ) is Hermitian for the relevant range of θ
- standard math The Lanczos residual norm controls the forward approximation error for the bilinear form
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a forward-only gradient approximation that reuses the Lanczos pass... error is proportional to the Lanczos residual norm
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2 (Error from ignoring basis variation)... proportional to β_m
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Awad H. Al-Mohy and Nicholas J. Higham. Computing the Fréchet derivative of the matrix exponential, with an application to condition number estimation.SIAM Journal on Matrix Analysis and Applications, 30(4):1639–1657, 2009. doi: 10.1137/080716426
-
[2]
Learning quantum systems.Nature Reviews Physics, 5:141–156, 2023
Leonardo Banchi et al. Learning quantum systems.Nature Reviews Physics, 5:141–156, 2023
work page 2023
-
[3]
Bernhard Beckermann and Lothar Reichel. Error estimates and evaluation of matrix functions via the Faber transform.SIAM Journal on Numerical Analysis, 47(5):3849–3883, 2009. doi: 10.1137/080741744
-
[4]
Matrix functions in network analysis.GAMM-Mitteilungen, 43 (3):e202000012, 2020
Michele Benzi and Paola Boito. Matrix functions in network analysis.GAMM-Mitteilungen, 43 (3):e202000012, 2020
work page 2020
-
[5]
Tyler Chen and Eric Hallman. Krylov-aware stochastic trace estimation.SIAM Journal on Matrix Analysis and Applications, 44(3):1218–1244, 2023. doi: 10.1137/22M1526357
-
[6]
Michel Crouzeix and Daniel Kressner. A bivariate extension of the Crouzeix–Palencia result with an application to Fréchet derivatives of matrix functions.arXiv preprint arXiv:2007.09784, 2020
-
[7]
Alexander Davies and Nicholas J. Higham. Computingf(a)b for matrix functions f.SIAM Jour- nal on Matrix Analysis and Applications, 42(2):1084–1105, 2021. doi: 10.1137/20M1363868
-
[8]
Communication in complex networks.Applied Numerical Mathematics, 172:186–205, 2022
Omar De la Cruz Cabrera, Jiafeng Jin, Silvia Noschese, and Lothar Reichel. Communication in complex networks.Applied Numerical Mathematics, 172:186–205, 2022
work page 2022
-
[9]
Scal- able log determinants for gaussian process kernel learning
Kun Dong, David Eriksson, Hannes Nickisch, David Bindel, and Andrew Gordon Wilson. Scal- able log determinants for gaussian process kernel learning. InAdvances in Neural Information Processing Systems, 2017
work page 2017
-
[10]
Howard C. Elman, David J. Silvester, and Andrew J. Wathen.Finite Elements and Fast Iterative Solvers: With Applications in Incompressible Fluid Dynamics. Oxford University Press, 2 edition, 2014
work page 2014
-
[11]
Efstratios Gallopoulos and Yousef Saad. Efficient solution of parabolic equations by Krylov approximation methods.SIAM Journal on Scientific and Statistical Computing, 13(5):1236– 1264, 1992. doi: 10.1137/0913071. 10
-
[12]
Weinberger, David Bindel, and Andrew Gordon Wilson
Jacob Gardner, Geoff Pleiss, Kilian Q. Weinberger, David Bindel, and Andrew Gordon Wilson. GPyTorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration. In Advances in Neural Information Processing Systems, 2018
work page 2018
-
[13]
Golub and Gérard Meurant.Matrices, Moments and Quadrature with Applications
Gene H. Golub and Gérard Meurant.Matrices, Moments and Quadrature with Applications. Princeton University Press, 2009
work page 2009
-
[14]
Gene H. Golub and Charles F. Van Loan.Matrix Computations. Johns Hopkins University Press, 4 edition, 2013
work page 2013
-
[15]
Practical hamiltonian learning with unitary dynamics and gibbs states
Jeongwan Haah et al. Practical hamiltonian learning with unitary dynamics and gibbs states. Nature Communications, 2024
work page 2024
-
[16]
Higham.Functions of Matrices: Theory and Computation
Nicholas J. Higham.Functions of Matrices: Theory and Computation. Society for Industrial and Applied Mathematics, Philadelphia, PA, 2008. doi: 10.1137/1.9780898717778
-
[17]
Marlis Hochbruck and Christian Lubich. On Krylov subspace approximations to the matrix exponential operator.SIAM Journal on Numerical Analysis, 34(5):1911–1925, 1997. doi: 10.1137/S0036142995280572
-
[18]
Robust and efficient hamiltonian learning.Quantum, 7:1045, 2023
Hsin-Yuan Huang et al. Robust and efficient hamiltonian learning.Quantum, 7:1045, 2023
work page 2023
-
[19]
URLhttps://doi.org/10.1080/03610918908812806
Michael F. Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Communications in Statistics – Simulation and Computation, 18(3):1059– 1076, 1989. doi: 10.1080/03610918908812806
-
[20]
Scalable marginal likelihood estimation for model selection in deep learning
Alexander Immer, Matthias Bauer, Vincent Fortuin, Gunnar Rätsch, and Mohammad Emtiyaz Khan. Scalable marginal likelihood estimation for model selection in deep learning. In International Conference on Machine Learning, 2021
work page 2021
-
[21]
Peter Kandolf, Antti Koskela, Samuel D. Relton, and Marcel Schweitzer. Computing low- rank approximations of the Fréchet derivative of a matrix function using krylov subspace methods.SIAM Journal on Matrix Analysis and Applications, 44(3):1115–1139, 2023. doi: 10.1137/22M1503075
-
[22]
Gradients of functions of large matrices
Nicholas Krämer, Pablo Moreno-Muñoz, Hrittik Roy, and Søren Hauberg. Gradients of functions of large matrices. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[23]
A krylov subspace method for the approximation of bivariate matrix functions
Daniel Kressner. A krylov subspace method for the approximation of bivariate matrix functions. InStructured Matrices in Numerical Linear Algebra, volume 30 ofSpringer INdAM Series, pages 197–214. Springer, Cham, 2019. doi: 10.1007/978-3-030-04088-8_10
-
[24]
Daniel Kressner and Peter Oehme. A novel krylov subspace method for approximating Fréchet derivatives of large-scale matrix functions.arXiv preprint arXiv:2601.21799, 2026
-
[25]
Deep learning via hessian-free optimization
James Martens. Deep learning via hessian-free optimization. InProceedings of the 27th International Conference on Machine Learning, pages 735–742, 2010
work page 2010
-
[26]
Gérard Meurant.The Lanczos and Conjugate Gradient Algorithms: From Theory to Finite Precision Computations. SIAM, 2006
work page 2006
-
[28]
Igor Najfeld and Timothy F. Havel. Derivatives of the matrix exponential and their computation. Advances in Applied Mathematics, 16(3):321–375, 1995. doi: 10.1006/aama.1995.1017
-
[29]
Christopher C. Paige. Computational variants of the lanczos method for the eigenproblem.IMA Journal of Applied Mathematics, 10(3):373–381, 1972
work page 1972
-
[30]
Christopher C. Paige. Error analysis of the lanczos algorithm for tridiagonalizing a symmetric matrix.IMA Journal of Applied Mathematics, 18(3):341–349, 1976
work page 1976
-
[31]
PhD thesis, University of London, 1971
Christopher Conway Paige.The Computation of Eigenvalues and Eigenvectors of Very Large Sparse Matrices. PhD thesis, University of London, 1971. 11
work page 1971
-
[32]
Parlett.The Symmetric Eigenvalue Problem
Beresford N. Parlett.The Symmetric Eigenvalue Problem. SIAM, 1998
work page 1998
-
[33]
Beresford N. Parlett and David S. Scott. The lanczos algorithm with selective orthogonalization. Mathematics of Computation, 33(145):217–238, 1979
work page 1979
-
[34]
Stefano Pozza and Francesco Tudisco. On the stability of network indices defined by means of matrix functions.SIAM Journal on Matrix Analysis and Applications, 39(4):1521–1546, 2018. doi: 10.1137/18M1172319
-
[35]
Physicochemical properties of protein tertiary structure
Prashant Rana. Physicochemical properties of protein tertiary structure. UCI Machine Learning Repository, 2013. URLhttps://doi.org/10.24432/C5QW3H
-
[36]
Carl Edward Rasmussen and Christopher K. I. Williams.Gaussian Processes for Machine Learning. MIT Press, 2006
work page 2006
-
[37]
Håvard Rue and Leonhard Held.Gaussian Markov Random Fields: Theory and Applications. Chapman and Hall/CRC, 2005. doi: 10.1201/9780203492024
-
[38]
Yousef Saad. Analysis of some Krylov subspace approximations to the matrix exponential operator.SIAM Journal on Numerical Analysis, 29(1):209–228, 1992. doi: 10.1137/0729014
-
[39]
Yousef Saad.Iterative Methods for Sparse Linear Systems. SIAM, 2 edition, 2003. doi: 10.1137/1.9780898718003
-
[40]
Nicol N. Schraudolph. Fast curvature matrix-vector products for second-order gradient descent. Neural Computation, 14(7):1723–1738, 2002. doi: 10.1162/08997660260028683
-
[41]
Marcel Schweitzer. Sensitivity of matrix function based network communicability measures: Computational methods and a priori bounds.SIAM Journal on Matrix Analysis and Applications, 44(3):1321–1348, 2023
work page 2023
-
[42]
Horst D. Simon. Analysis of the symmetric lanczos algorithm with reorthogonalization methods. Linear Algebra and its Applications, 61:101–131, 1984
work page 1984
-
[43]
Shashanka Ubaru, Jie Chen, and Yousef Saad. Fast estimation oftr(f(A)) via stochastic lanczos quadrature.SIAM Journal on Matrix Analysis and Applications, 38(4):1075–1099, 2017. doi: 10.1137/16M1104974. A Proofs for Section 4 This appendix provides more details on the projected sensitivity, and the residual-controlled error formula used in Section 4. We u...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.