Recognition: unknown
Correcting Influence: Unboxing LLM Outputs with Orthogonal Latent Spaces
Pith reviewed 2026-05-14 20:14 UTC · model grok-4.3
The pith
A latent mediation method using sparse autoencoders delivers reliable token-level influence attribution for LLM predictions on any task.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Attaching sparse autoencoders to any layer of a pretrained LLM produces a basis of approximately independent latent features; influence is then calculated over these features and propagated back to the input space via token activation patterns and Jacobian-vector products, yielding token-level attributions that work for general prediction tasks rather than being restricted to autoregressive settings.
What carries the argument
Sparse autoencoders attached to LLM layers that learn an approximately independent basis of latent features, combined with Jacobian-vector products to propagate non-decomposable latent attributions back through token activation patterns.
Load-bearing premise
Sparse autoencoders learn a basis of approximately independent latent features whose influence can be propagated back to tokens via Jacobian-vector products without introducing new biases.
What would settle it
Remove the tokens the method flags as influential from the training set, retrain the model, and verify whether the original prediction changes more than when the same number of randomly chosen tokens are removed.
Figures




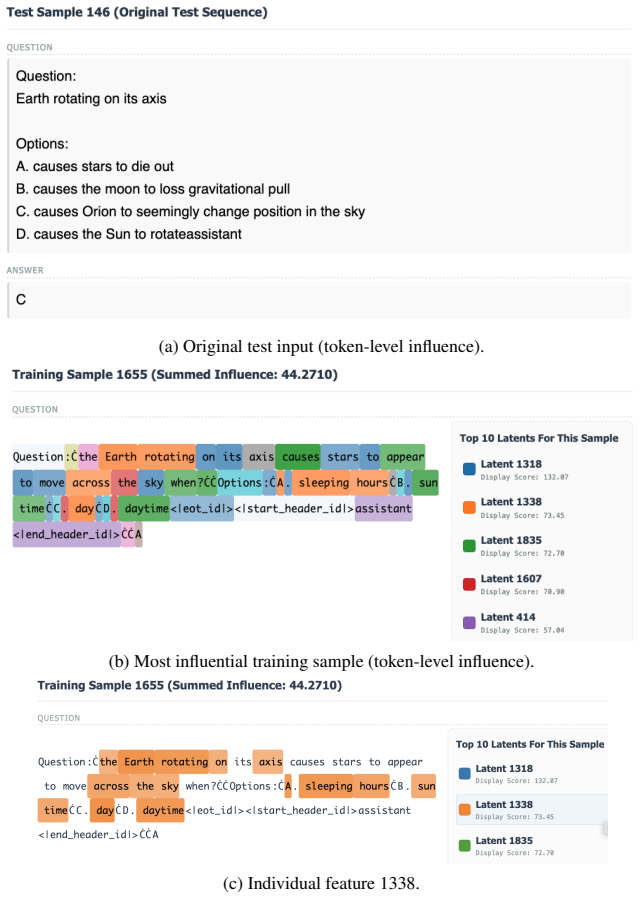
read the original abstract
A critical step for reliable large language models (LLMs) use in healthcare is to attribute predictions to their training data, akin to a medical case study. This requires token-level precision: pinpointing not just which training examples influence a decision, but which tokens within them are responsible. While influence functions offer a principled framework for this, prior work is restricted to autoregressive settings and relies on an implicit assumption of token independence, rendering their identified influences unreliable. We introduce a flexible framework that infers token-level influence through a latent mediation approach for general prediction tasks. Our method attaches sparse autoencoders to any layer of a pretrained LLM to learn a basis of approximately independent latent features. Unlike prior methods where influence decomposes additively across tokens, influence computed over latent features is inherently non-decomposable. To address this, we introduce a novel method using Jacobian-vector products. Token-level influence is obtained by propagating latent attributions back to the input space via token activation patterns. We scale our approach using efficient inverse-Hessian approximations. Experiments on medical benchmarks show our approach identifies sparse, interpretable sets of tokens that jointly influence predictions. Our framework enhances trust and enables model auditing, generalizing to high-stakes domain requiring transparent and accountable decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for token-level influence attribution in LLMs for general (non-autoregressive) prediction tasks. It attaches sparse autoencoders to arbitrary layers to extract approximately independent latent features, computes influence over these latents, and propagates the attributions back to input tokens via Jacobian-vector products applied to token activation patterns. This is claimed to correct the token-independence assumption of prior influence-function work. The method is scaled with inverse-Hessian approximations and is evaluated on medical benchmarks, where it reportedly identifies sparse, interpretable token sets that jointly influence predictions.
Significance. If the Jacobian propagation step can be shown to recover faithful token-level attributions without re-introducing bias from non-linearities or SAE reconstruction error, the approach would provide a practical way to audit LLM decisions at token granularity in high-stakes domains. The use of SAEs to mediate non-decomposable influence is a conceptually clean idea that could generalize beyond the medical setting.
major comments (3)
- [Method (Jacobian propagation paragraph)] The central technical step—propagating latent attributions to tokens via Jacobian-vector products—rests on the assumption that first-order derivatives suffice to capture the mapping from SAE latents through non-linear LLM layers. The skeptic note correctly flags that partial polysemanticity or strong non-linearities at the chosen layer could distort attributions; the manuscript must supply either a theoretical bound on the approximation error or an empirical check (e.g., comparison against exact influence on a small model or synthetic data with known ground-truth tokens).
- [Experiments section] The abstract states that experiments on medical benchmarks demonstrate identification of sparse, interpretable token sets, yet supplies no quantitative metrics, ablation results, or error analysis. Without these, it is impossible to judge whether the method actually improves upon prior influence functions or merely reproduces their limitations under a different parameterization.
- [Scaling and implementation details] The inverse-Hessian approximation is listed among the free parameters; its concrete implementation (e.g., LiSSA, conjugate-gradient, or damping schedule) and sensitivity analysis must be reported, because any instability in the Hessian inverse directly affects the reliability of the latent-level influence scores before the JVP step.
minor comments (2)
- [Method] Notation for the Jacobian-vector product and the precise definition of “token activation patterns” should be introduced with an equation rather than prose only.
- [SAE attachment paragraph] The abstract claims the SAE latents are “approximately independent”; a quantitative measure of residual correlation (e.g., average pairwise cosine similarity of decoder weights) would strengthen this claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight key areas where additional theoretical and empirical support will strengthen the presentation. We address each major comment below and will incorporate the requested clarifications and analyses in the revised version.
read point-by-point responses
-
Referee: [Method (Jacobian propagation paragraph)] The central technical step—propagating latent attributions to tokens via Jacobian-vector products—rests on the assumption that first-order derivatives suffice to capture the mapping from SAE latents through non-linear LLM layers. The skeptic note correctly flags that partial polysemanticity or strong non-linearities at the chosen layer could distort attributions; the manuscript must supply either a theoretical bound on the approximation error or an empirical check (e.g., comparison against exact influence on a small model or synthetic data with known ground-truth tokens).
Authors: We agree that the first-order JVP approximation requires explicit justification. In the revised manuscript we will add a dedicated subsection deriving a first-order error bound under the assumption that SAE latents are sufficiently sparse and that activation perturbations remain small. We will also include an empirical validation: on a 125M-parameter model with synthetic data containing known ground-truth token influences, we compare the JVP-based attributions against exact (Hessian-free) influence values and report the resulting correlation and top-k recovery rates. revision: yes
-
Referee: [Experiments section] The abstract states that experiments on medical benchmarks demonstrate identification of sparse, interpretable token sets, yet supplies no quantitative metrics, ablation results, or error analysis. Without these, it is impossible to judge whether the method actually improves upon prior influence functions or merely reproduces their limitations under a different parameterization.
Authors: The original submission emphasized qualitative case studies on medical benchmarks to illustrate interpretability. We acknowledge that quantitative support is necessary. The revised version will add: (i) precision@K and recall@K against available ground-truth token sets, (ii) ablation tables varying SAE sparsity and layer choice, and (iii) direct comparison against standard influence-function baselines on the same benchmarks, including error bars over multiple random seeds. revision: yes
-
Referee: [Scaling and implementation details] The inverse-Hessian approximation is listed among the free parameters; its concrete implementation (e.g., LiSSA, conjugate-gradient, or damping schedule) and sensitivity analysis must be reported, because any instability in the Hessian inverse directly affects the reliability of the latent-level influence scores before the JVP step.
Authors: We will expand the implementation appendix to specify that we employ the LiSSA estimator with 10 iterations, damping factor 0.01, and a fixed random seed for reproducibility. A new sensitivity plot will show how latent influence scores vary across damping values in {0.001, 0.01, 0.1} and iteration counts in {5, 10, 20}, confirming that the reported token attributions remain stable within the chosen operating range. revision: yes
Circularity Check
Extends influence functions with SAE latents and JVP; no derivation reduces to fitted input by construction
full rationale
The framework attaches SAEs to learn approximately independent latents then propagates attributions via Jacobian-vector products. This builds directly on established influence-function machinery without any equation or step equating the final token-level influence to a fitted parameter or self-cited uniqueness result. The abstract and description contain no self-definitional, fitted-input-called-prediction, or load-bearing self-citation patterns that collapse the claimed output to the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- inverse-Hessian approximation
axioms (1)
- domain assumption Sparse autoencoders learn a basis of approximately independent latent features from any LLM layer
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Auto-encoding variational bayes , author=. International Conference on Learning Representations , year=
-
[2]
Independent component analysis: recent advances , author=. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2013 , publisher=
work page 2013
-
[3]
Principal component analysis: a review and recent developments , author=. Philosophical transactions of the royal society A: Mathematical, Physical and Engineering Sciences , volume=. 2016 , publisher=
work page 2016
-
[4]
arXiv preprint arXiv:2411.07618 , year=
Direct preference optimization using sparse feature-level constraints , author=. arXiv preprint arXiv:2411.07618 , year=
-
[5]
Transformer Circuits Thread , volume=
Towards monosemanticity: Decomposing language models with dictionary learning , author=. Transformer Circuits Thread , volume=
-
[6]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[7]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [8]
-
[9]
International conference on machine learning , pages=
Understanding black-box predictions via influence functions , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[10]
Advances in Neural Information Processing Systems , year=
Evaluating large language models trained on code , author=. Advances in Neural Information Processing Systems , year=
-
[11]
PubMedQA: A Dataset for Biomedical Research Question Answering , author=. Proceedings of EMNLP , year=
-
[12]
Proceedings of the 18th International Conference on Artificial Intelligence and Law , year=
When does pretraining help? Assessing self-supervised learning for law and the casehold dataset , author=. Proceedings of the 18th International Conference on Artificial Intelligence and Law , year=
-
[13]
Proceedings of NeurIPS , year=
Program synthesis with large language models , author=. Proceedings of NeurIPS , year=
-
[14]
Language models can prove theorems , author=. arXiv preprint arXiv:2305.20030 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Leandojo: Theorem proving with retrieval-augmented language models , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Journal of the american statistical association , volume=
The influence curve and its role in robust estimation , author=. Journal of the american statistical association , volume=. 1974 , publisher=
work page 1974
-
[17]
arXiv preprint arXiv:2202.01344 , year=
Formal mathematics statement curriculum learning , author=. arXiv preprint arXiv:2202.01344 , year=
-
[18]
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
work page 2023
-
[19]
Advances in Neural Information Processing Systems , volume=
Pile of law: Learning responsible data filtering from the law and a 256gb open-source legal dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Journal of Machine Learning Research , volume=
Second-order stochastic optimization for machine learning in linear time , author=. Journal of Machine Learning Research , volume=
-
[21]
International conference on machine learning , pages=
Optimizing neural networks with kronecker-factored approximate curvature , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[22]
International Conference on Machine Learning , pages=
A kronecker-factored approximate fisher matrix for convolution layers , author=. International Conference on Machine Learning , pages=. 2016 , organization=
work page 2016
-
[23]
Fast approximate natural gradient descent in a kronecker factored eigenbasis , url =
George, Thomas and Laurent, C. Fast approximate natural gradient descent in a kronecker factored eigenbasis , url =. Advances in Neural Information Processing Systems , month =
-
[24]
Studying large language model generalization with influence functions , author=. arXiv preprint arXiv:2308.03296 , year=
-
[25]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sparse autoencoders find highly interpretable features in language models , author=. arXiv preprint arXiv:2309.08600 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Sparse Feature Circuits: Discovering and Editing Interpretable Causal Graphs in Language Models
Sparse feature circuits: Discovering and editing interpretable causal graphs in language models , author=. arXiv preprint arXiv:2403.19647 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Toward expert-level medical question answering with large language models , author=. Nature Medicine , volume=. 2025 , publisher=
work page 2025
-
[28]
Chain-of-Thought Is Not Explainability , publisher =
Barez, Fazl and Wu, Tung-Yu and Arcuschin, Iván and Lan, Michael and Wang, Vincent and Siegel, Noah and Collignon, Nicolas and Neo, Clement and Lee, Isabelle and Paren, Alasdair and Bibi, Adel and Trager, Robert and Fornasiere, Damiano and Yan, John and Elazar, Yanai and Bengio, Yoshua , keywords =. Chain-of-Thought Is Not Explainability , publisher =
-
[29]
The implicit function theorem: history, theory, and applications , author=. 2002 , publisher=
work page 2002
-
[30]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
work page 2023
-
[31]
High-performance medicine: the convergence of human and artificial intelligence , author=. Nature medicine , volume=. 2019 , publisher=
work page 2019
-
[32]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
work page 2023
-
[33]
International Conference on Machine Learning , pages=
Counterfactual off-policy evaluation with gumbel-max structural causal models , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[34]
The lancet digital health , volume=
The false hope of current approaches to explainable artificial intelligence in health care , author=. The lancet digital health , volume=. 2021 , publisher=
work page 2021
-
[35]
The Lancet Digital Health , volume=
The myth of generalisability in clinical research and machine learning in health care , author=. The Lancet Digital Health , volume=. 2020 , publisher=
work page 2020
-
[36]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
What neural networks memorize and why: Discovering the long tail via influence estimation , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:1908.04626 , year=
Attention is not not explanation , author=. arXiv preprint arXiv:1908.04626 , year=
-
[39]
Attention is not explanation , author=. arXiv preprint arXiv:1902.10186 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[40]
International conference on machine learning , pages=
Axiomatic attribution for deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[41]
Theoretical Economics , volume=
On the falsifiability and learnability of decision theories , author=. Theoretical Economics , volume=. 2020 , publisher=
work page 2020
-
[42]
Advances in Neural Information Processing Systems , volume=
Multimodal few-shot learning with frozen language models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Sparse modeling under grouped heterogeneity with an application to asset pricing , author=. 2023 , institution=
work page 2023
-
[44]
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
work page 2024
-
[45]
K-sparse autoencoders , author=. arXiv preprint arXiv:1312.5663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Mechanistic Interpretability for Vision at CVPR 2025 (Non-proceedings Track) , year=
Unpacking sdxl turbo: Interpreting text-to-image models with sparse autoencoders , author=. Mechanistic Interpretability for Vision at CVPR 2025 (Non-proceedings Track) , year=
work page 2025
-
[47]
Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C
An x-ray is worth 15 features: Sparse autoencoders for interpretable radiology report generation , author=. arXiv preprint arXiv:2410.03334 , year=
-
[48]
Scaling and evaluating sparse autoencoders
Scaling and evaluating sparse autoencoders , author=. arXiv preprint arXiv:2406.04093 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
arXiv preprint arXiv:2412.06410 , year=
Batchtopk sparse autoencoders , author=. arXiv preprint arXiv:2412.06410 , year=
-
[50]
Chan, Lawrence and. Causal Scrubbing: a method for rigorously testing interpretability hypotheses [Redwood Research] , shorttitle =. 2022 , month = dec, journal =
work page 2022
-
[51]
Lieberum, Tom and Rahtz, Matthew and Kram. Does Circuit Analysis Interpretability Scale? Evidence from Multiple Choice Capabilities in Chinchilla , shorttitle =. 2023 , month = jul, journal =. doi:10.48550/arXiv.2307.09458 , url =. arXiv , keywords =:2307.09458 , primaryclass =
-
[52]
Locating and Editing Factual Associations in GPT, January 2023
Locating and Editing Factual Associations in GPT , author =. 2022 , journal =. doi:10.48550/arXiv.2202.05262 , url =. arXiv , keywords =:2202.05262 , primaryclass =
-
[53]
Definitions, methods, and applications in interpretable machine learning , author =. 2019 , month = oct, journal =
work page 2019
-
[54]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , shorttitle =
Frankle, Jonathan and Carbin, Michael , year =. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks , shorttitle =. ICLR , url =
- [55]
-
[56]
On Interpretability of Artificial Neural Networks: A Survey , shorttitle =
Fan, Feng-Lei and Xiong, Jinjun and Li, Mengzhou and Wang, Ge , year =. On Interpretability of Artificial Neural Networks: A Survey , shorttitle =. IEEE Trans. Radiat. Plasma Med. Sci. , volume =. doi:10.1109/TRPMS.2021.3066428 , url =
-
[57]
A Survey on Neural Network Interpretability , author =. 2021 , month = oct, journal =. doi:10.1109/TETCI.2021.3100641 , url =
-
[58]
Chakraborty, Supriyo and Tomsett, Richard and Raghavendra, Ramya and Harborne, Daniel and Alzantot, Moustafa and Cerutti, Federico and Srivastava, Mani and Preece, Alun and Julier, Simon and Rao, Raghuveer M. and Kelley, Troy D. and Braines, Dave and Sensoy, Murat and Willis, Christopher J. and Gurram, Prudhvi , year =. Interpretability of deep learning m...
-
[59]
A Scoring Method for Interpretability of Concepts in Convolutional Neural Networks , author =. 2022 , month = may, journal =. doi:10.1109/SIU55565.2022.9864930 , url =
-
[60]
Network Dissection: Quantifying Interpretability of Deep Visual Representations , shorttitle =
Bau, David and Zhou, Bolei and Khosla, Aditya and Oliva, Aude and Torralba, Antonio , year =. Network Dissection: Quantifying Interpretability of Deep Visual Representations , shorttitle =. CVPR , pages =. doi:10.1109/CVPR.2017.354 , url =
-
[61]
Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning , shorttitle =
Yeom, Seul-Ki and Seegerer, Philipp and Lapuschkin, Sebastian and Binder, Alexander and Wiedemann, Simon and M. Pruning by Explaining: A Novel Criterion for Deep Neural Network Pruning , shorttitle =. 2021 , month = jul, journal =. doi:10.1016/j.patcog.2021.107899 , url =. arXiv , keywords =:1912.08881 , primaryclass =
- [62]
-
[63]
Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning , shorttitle =
Gal, Yarin and Ghahramani, Zoubin , year =. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning , shorttitle =. ICML , url =
-
[64]
Human Evaluation of Models Built for Interpretability , author =. 2019 , month = oct, journal =. doi:10.1609/hcomp.v7i1.5280 , url =
-
[65]
DeepCuts: Single-Shot Interpretability based Pruning for BERT , shorttitle =
Grover, Jasdeep Singh and Gawri, Bhavesh and Manku, Ruskin Raj , year =. DeepCuts: Single-Shot Interpretability based Pruning for BERT , shorttitle =. CoRR , publisher =. doi:10.48550/ARXIV.2212.13392 , url =
-
[66]
Towards Robust Interpretability with Self-Explaining Neural Networks , author =. 2018 , month = jun, journal =
work page 2018
-
[67]
Lalor, John P. and Guo, Hong , year =. Measuring algorithmic interpretability: A human-learning-based framework and the corresponding cognitive complexity score , shorttitle =. CoRR , publisher =. doi:10.48550/ARXIV.2205.10207 , url =
-
[68]
Icke, Ilknur and Rosenberg, Andrew , year =. Automated measures for interpretable dimensionality reduction for visual classification: A user study , shorttitle =. VAST , pages =. doi:10.1109/VAST.2011.6102474 , url =
-
[69]
Localizing Model Behavior with Path Patching , author =. 2023 , journal =. doi:10.48550/ARXIV.2304.05969 , url =
-
[70]
Evaluation of post-hoc interpretability methods in time-series classification , author =. 2023 , month = mar, journal =. doi:10.1038/s42256-023-00620-w , url =
-
[71]
Global Concept-Based Interpretability for Graph Neural Networks via Neuron Analysis , author =. 2023 , journal =. doi:10.48550/ARXIV.2208.10609 , url =
-
[72]
To Compress or Not to Compress- Self-Supervised Learning and Information Theory: A Review , shorttitle =. 2023 , month = aug, journal =. doi:10.48550/arXiv.2304.09355 , url =. arXiv , keywords =:2304.09355 , primaryclass =
-
[73]
FACADE: A Framework for Adversarial Circuit Anomaly Detection and Evaluation , shorttitle =
Pai, Dhruv and Carranza, Andres and Schaeffer, Rylan and Tandon, Arnuv and Koyejo, Sanmi , year =. FACADE: A Framework for Adversarial Circuit Anomaly Detection and Evaluation , shorttitle =. CoRR , eprint =. doi:10.48550/arXiv.2307.10563 , url =
-
[74]
Discovering Variable Binding Circuitry with Desiderata , author =. 2023 , month = jul, journal =. doi:10.48550/arXiv.2307.03637 , url =. arXiv , keywords =:2307.03637 , primaryclass =
-
[75]
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations , author =. 2023 , journal =. doi:10.48550/ARXIV.2303.02536 , url =
-
[76]
Causal abstraction for faithful model interpretation
Causal Abstraction for Faithful Model Interpretation , author =. 2023 , month = jan, journal =. doi:10.48550/arXiv.2301.04709 , url =. arXiv , keywords =:2301.04709 , primaryclass =
-
[77]
org/posts/baJyjpktzmcmRfosq/ stitching-saes-of-different-sizes
Towards Automated Circuit Discovery for Mechanistic Interpretability , author =. 2023 , journal =. doi:10.48550/ARXIV.2304.14997 , url =
-
[78]
Red Teaming Deep Neural Networks with Feature Synthesis Tools , author =. 2023 , journal =. doi:10.48550/ARXIV.2302.10894 , url =
-
[79]
Language models can explain neurons in language models , author =. 2023 , journal =
work page 2023
-
[80]
Mass-Editing Memory in a Transformer
Mass-Editing Memory in a Transformer , author =. 2022 , journal =. doi:10.48550/arXiv.2210.07229 , url =. arXiv , keywords =:2210.07229 , primaryclass =
work page internal anchor Pith review doi:10.48550/arxiv.2210.07229 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.