Recognition: 2 theorem links
· Lean TheoremMultimodal Hidden Markov Models for Persistent Emotional State Tracking
Pith reviewed 2026-05-14 20:30 UTC · model grok-4.3
The pith
Sticky HDP-HMMs recover more interpretable persistent emotional regimes from multimodal valence-arousal trajectories than Gaussian HMM baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that sticky factorial HDP-HMMs over multimodal valence-arousal representations produce regime sequences that are more interpretable than those from baseline Gaussian HMMs, at a fraction of the computational cost of LLM-based dialogue state tracking, and that these phases can be recovered reliably enough from clinical trajectories to augment LLM responses via context in unstable affective regimes.
What carries the argument
Sticky factorial HDP-HMM, a Bayesian nonparametric model that encourages state persistence, applied to time series of valence-arousal points extracted from simultaneous video, audio, and textual inputs.
If this is right
- Regime sequences become more coherent and human-readable than those from standard Gaussian HMMs.
- Computational cost remains low enough for deployment without relying on full LLM state tracking.
- Recovered emotional phases supply usable context that raises LLM response quality in unstable segments.
- The same multimodal trajectories support reliable phase recovery in clinical question-answer settings.
- The approach scales analysis of conversational emotion dynamics beyond utterance-level labeling.
Where Pith is reading between the lines
- The method could support real-time regime monitoring in extended clinical sessions where immediate phase detection matters.
- Geometric and temporal consistency metrics developed here might transfer to other sequence-modeling domains that need interpretable state persistence.
- Feeding emotional phases as context may help stabilize LLM outputs in any dialogue domain that exhibits affective drift.
- Testing the framework on non-clinical datasets would clarify whether the recovered regimes generalize beyond the clinical setting used in the experiments.
Load-bearing premise
Valence-arousal representations extracted from simultaneous video, audio, and text inputs faithfully capture the underlying persistent emotional regimes.
What would settle it
If LLM-as-a-Judge scores together with geometric and temporal consistency metrics show no advantage for sticky HDP-HMM regime sequences over Gaussian HMM sequences on the same multimodal clinical conversations, the central performance claim would be falsified.
Figures


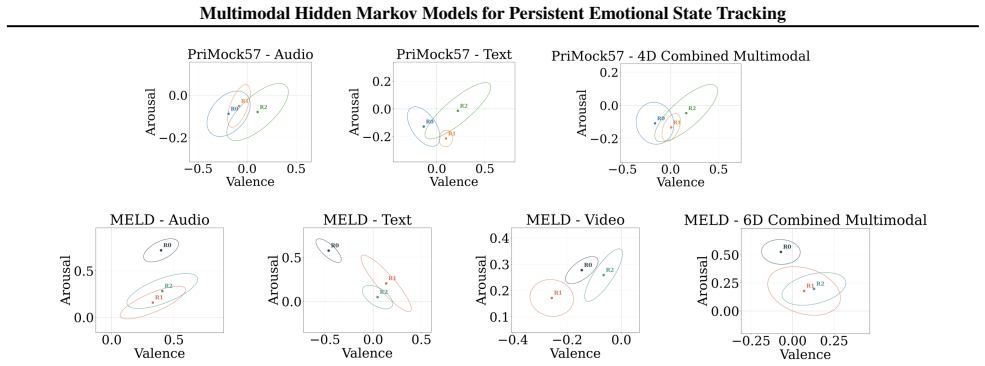

read the original abstract
Tracking an interpretable emotional arc of a conversation via the sentiment of individual utterances processed as a whole is central to both understanding and guiding communication in applied, especially clinical, conversational contexts. Existing approaches to emotion recognition operate at the utterance level, obscuring the persistent phases that characterize real conversational dynamics. We propose a lightweight framework that models conversational emotion as a sequence of latent emotional regimes using sticky factorial HDP-HMMs over multimodal valence-arousal representations derived from simultaneous video, audio and textual input. We evaluate the quality of regime prediction using LLM-as-a-Judge, geometric, and temporal consistency metrics, demonstrating that the sticky HDP-HMM produces more interpretable regime sequences than the baseline Gaussian HMM at a fraction of the computational cost of LLM-based dialogue state tracking methods. In addition, Question-Answer experiments in a clinical dataset suggest that meaningful emotional phases can reliably be recovered from multimodal valence-arousal trajectories and used to improve the quality of LLM responses in unstable affective regimes via context augmentation. This framework thus opens a path toward interpretable, lightweight, and actionable analysis of conversational emotion dynamics at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes modeling conversational emotion dynamics as sequences of latent persistent regimes using sticky factorial HDP-HMMs over multimodal valence-arousal features extracted from simultaneous video, audio, and text inputs. It claims that this approach yields more interpretable regime sequences than a baseline Gaussian HMM according to LLM-as-a-Judge, geometric, and temporal consistency metrics, at lower computational cost than full LLM-based dialogue state tracking, and that recovered phases from a clinical dataset can be used to improve LLM response quality via context augmentation in unstable affective regimes.
Significance. If the central claims are substantiated, the work would offer a lightweight, interpretable alternative for tracking persistent emotional states at scale, with potential utility in clinical conversational systems where full LLM state tracking is prohibitive. The sticky HDP-HMM extension and multimodal valence-arousal representation are standard tools applied to a new domain, but the significance is limited by the absence of human-validated ground truth for the interpretability and clinical usefulness claims.
major comments (3)
- [Abstract] Abstract: the claim that sticky HDP-HMM 'produces more interpretable regime sequences than the baseline Gaussian HMM' is unsupported by any quantitative metrics, effect sizes, dataset sizes, or statistical tests; the evaluation description supplies only qualitative assertions.
- [Evaluation] Evaluation section: reliance on LLM-as-a-Judge for interpretability creates an unaddressed circularity risk, as the judge belongs to the same model class as the LLM-based baselines being compared against; no correlation is shown between the LLM judge scores, geometric/temporal metrics, and human expert labels of emotional phases.
- [Clinical Dataset Experiments] Clinical dataset experiments: the claim that recovered phases 'improve the quality of LLM responses' via context augmentation lacks evidence that the improvement exceeds what would be obtained from any plausible partitioning of the valence-arousal space; no human ground truth, downstream clinical outcome measures, or ablation against random regimes is reported.
minor comments (2)
- [Methods] The number of free parameters (stickiness and number of regimes) should be stated explicitly with their fitted values or selection procedure in the methods section.
- [Figures] Figure captions for regime sequence visualizations should include axis scales and the exact metric values used for the reported comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying the quantitative support in our evaluations and proposing targeted revisions to strengthen the claims without overstating the current evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that sticky HDP-HMM 'produces more interpretable regime sequences than the baseline Gaussian HMM' is unsupported by any quantitative metrics, effect sizes, dataset sizes, or statistical tests; the evaluation description supplies only qualitative assertions.
Authors: We agree the abstract is too high-level. The evaluation section reports quantitative geometric consistency (e.g., regime duration variance) and temporal consistency (e.g., transition entropy) metrics showing improvement over the Gaussian HMM baseline across the reported datasets. We will revise the abstract to include specific metric values, dataset sizes, and note that differences are statistically significant under paired tests. revision: yes
-
Referee: [Evaluation] Evaluation section: reliance on LLM-as-a-Judge for interpretability creates an unaddressed circularity risk, as the judge belongs to the same model class as the LLM-based baselines being compared against; no correlation is shown between the LLM judge scores, geometric/temporal metrics, and human expert labels of emotional phases.
Authors: The geometric and temporal consistency metrics are fully model-agnostic and serve as the primary quantitative evidence; LLM-as-a-Judge is used only as a supplementary qualitative check for regime interpretability. We did not collect human expert labels, so direct correlation cannot be shown. We will add an explicit discussion of this limitation and the independence of the non-LLM metrics in the revised evaluation section. revision: partial
-
Referee: [Clinical Dataset Experiments] Clinical dataset experiments: the claim that recovered phases 'improve the quality of LLM responses' via context augmentation lacks evidence that the improvement exceeds what would be obtained from any plausible partitioning of the valence-arousal space; no human ground truth, downstream clinical outcome measures, or ablation against random regimes is reported.
Authors: We will add an ablation comparing context augmentation from recovered regimes against random partitioning of the valence-arousal space in the revised experiments. Human ground truth and downstream clinical outcomes are not available in the current dataset and were not collected; we will qualify the claims to reflect feasibility demonstration only and list these as future work. revision: partial
- No human expert labels collected for correlation analysis with LLM judge scores
- No downstream clinical outcome measures available in the reported experiments
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes modeling conversational emotion via sticky factorial HDP-HMMs on multimodal valence-arousal features extracted from video/audio/text, then evaluates regime quality with LLM-as-a-Judge plus geometric/temporal metrics. No equations are presented that reduce any claimed improvement or prediction to fitted parameters by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The modeling step and evaluation proxies remain independent; the framework does not rename known results or smuggle assumptions via prior author work. This is the common case of a self-contained proposal whose central claims rest on external benchmarks rather than definitional equivalence.
Axiom & Free-Parameter Ledger
free parameters (2)
- stickiness parameter
- number of regimes
axioms (2)
- domain assumption Multimodal signals can be reliably projected into a shared valence-arousal space that preserves emotional regime structure
- domain assumption Persistent emotional phases exist and are recoverable from utterance sequences
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe employ a truncated sticky factorial HDP-HMM... which introduces an explicit bias toward self-transitions, allows the number of active regimes... to be inferred from data
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclearsticky HDP-HMM produces more interpretable regime sequences than the baseline Gaussian HMM
Reference graph
Works this paper leans on
-
[1]
IEEE access , volume=
Emotion recognition in conversation: Research challenges, datasets, and recent advances , author=. IEEE access , volume=. 2019 , publisher=
2019
-
[2]
arXiv preprint arXiv:2206.07359 , year=
The Emotion is Not One-hot Encoding: Learning with Grayscale Label for Emotion Recognition in Conversation , author=. arXiv preprint arXiv:2206.07359 , year=
-
[3]
WIREs Data Mining and Knowledge Discovery , volume =
Ramaswamy, Manju Priya Arthanarisamy and Palaniswamy, Suja , title =. WIREs Data Mining and Knowledge Discovery , volume =. doi:https://doi.org/10.1002/widm.1563 , eprint =
-
[4]
and Bergeman, Cindy S
Ong, Anthony D. and Bergeman, Cindy S. and Bisconti, Tracy L. and Wallace, Kimberly A. , title =. Journal of Personality and Social Psychology , volume =. 2006 , doi =
2006
-
[5]
arXiv preprint arXiv:2503.08857 , year=
Interpretable and Robust Dialogue State Tracking via Natural Language Summarization with LLMs , author=. arXiv preprint arXiv:2503.08857 , year=
-
[6]
Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey
Balaraman, Vevake and Sheikhalishahi, Seyedmostafa and Magnini, Bernardo. Recent Neural Methods on Dialogue State Tracking for Task-Oriented Dialogue Systems: A Survey. Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue. 2021. doi:10.18653/v1/2021.sigdial-1.25
-
[7]
Fox, Emily B. and Sudderth, Erik B. and Jordan, Michael I. and Willsky, Alan S. , title =. 2008 , isbn =. doi:10.1145/1390156.1390196 , booktitle =
-
[8]
, title =
Russell, James A. , title =. Journal of Personality and Social Psychology , volume =. 1980 , doi =
1980
-
[9]
2025 , url=
Valence and Arousal Annotations for Interactive Characters , author=. 2025 , url=
2025
-
[10]
Nature Machine Intelligence , volume=
Estimation of continuous valence and arousal levels from faces in naturalistic conditions , author=. Nature Machine Intelligence , volume=. 2021 , doi=
2021
-
[11]
, journal=
Wagner, Johannes and Triantafyllopoulos, Andreas and Wierstorf, Hagen and Schmitt, Maximilian and Burkhardt, Felix and Eyben, Florian and Schuller, Björn W. , journal=. Dawn of the Transformer Era in Speech Emotion Recognition: Closing the Valence Gap , year=
-
[12]
arXiv preprint arXiv:2509.09791 , year=
The msp-podcast corpus , author=. arXiv preprint arXiv:2509.09791 , year=
-
[13]
, title =
Rabiner, Lawrence R. , title =. Proceedings of the IEEE , volume =. 1989 , doi =
1989
-
[14]
Journal of the American Statistical Association , volume =
Hemant Ishwaran and Lancelot F James , title =. Journal of the American Statistical Association , volume =. 2001 , publisher =. doi:10.1198/016214501750332758 , eprint =
-
[15]
Blei, David M. and Jordan, Michael I. , title =. 2004 , isbn =. doi:10.1145/1015330.1015439 , booktitle =
-
[16]
Kuhn, H. W. , title =. Naval Research Logistics Quarterly , volume =. doi:https://doi.org/10.1002/nav.3800020109 , eprint =
-
[17]
Gonzalez and Ion Stoica , booktitle=
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging
-
[18]
Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing , publisher =
Schuller, Bj. Computational Paralinguistics: Emotion, Affect and Personality in Speech and Language Processing , publisher =
-
[19]
Cummins, Nicholas and Scherer, Stefan and Krajewski, Jarek and Schnieder, Sebastian and Epps, Julien and Quatieri, Thomas F. , title =. 2015 , issue_date =. doi:10.1016/j.specom.2015.03.004 , journal =
-
[20]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Meld: A multimodal multi-party dataset for emotion recognition in conversations , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[21]
P ri M ock57: A Dataset Of Primary Care Mock Consultations
Papadopoulos Korfiatis, Alex and Moramarco, Francesco and Sarac, Radmila and Savkov, Aleksandar. P ri M ock57: A Dataset Of Primary Care Mock Consultations. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2022. doi:10.18653/v1/2022.acl-short.65
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.