Recognition: no theorem link
Do Skill Descriptions Tell the Truth? Detecting Undisclosed Security Behaviors in Code-Backed LLM Skills
Pith reviewed 2026-05-14 19:00 UTC · model grok-4.3
The pith
LLM skill descriptions often omit security-relevant operations performed by their code implementations, which SKILLSCOPE detects via source-level graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
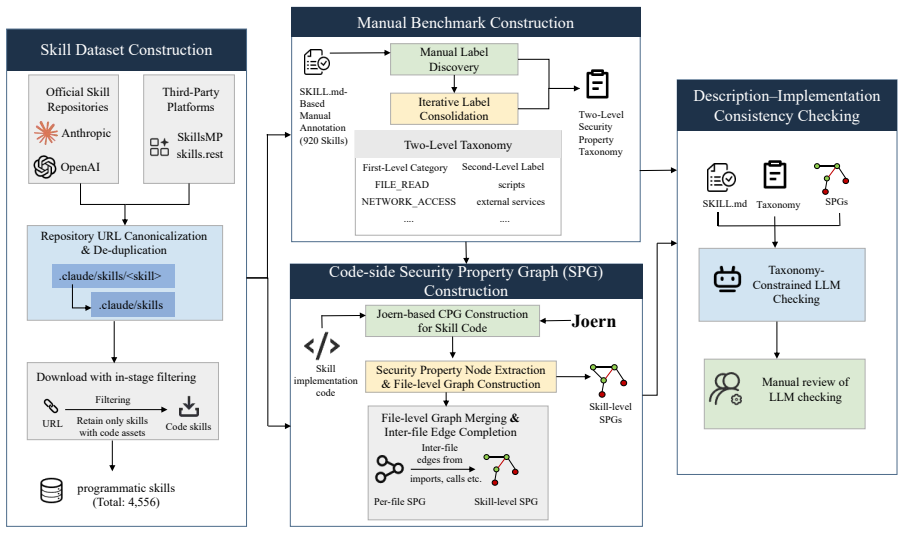
SKILLSCOPE detects description-implementation inconsistency by first extracting source-level security property graphs that retain concrete code patterns for operations in an 11-category taxonomy, then using LLM assistance to verify whether every captured operation falls inside the scope stated in the skill description; large-scale evaluation confirms that 9.4 percent of real skills exhibit confirmed undisclosed security behaviors while coarser descriptions account for an additional 24.3 percent.
What carries the argument
Source-level security property graph (SPG) built from implementation code that keeps fine-grained source patterns rather than abstract labels, enabling precise consistency checks against the skill description.
If this is right
- Skill marketplaces can automatically flag the 9.4 percent of skills that perform undeclared security actions before users install them.
- LLM agents that invoke skills receive warnings when a description understates the actual operations the code will run.
- Developers gain a concrete checklist of security properties they must either disclose or remove from their implementations.
- Ablation results show that both the taxonomy and the source-level graphs are required; removing either drops detection performance sharply.
- The same graph-plus-LLM pipeline can be reused to audit future skill updates or new code-backed LLM extensions.
Where Pith is reading between the lines
- Platform operators could require SKILLSCOPE-style scans as a precondition for publishing skills, shifting the burden from users to providers.
- The same inconsistency problem likely appears in other code-backed AI artifacts such as agents or plugins, suggesting the SPG approach may generalize beyond the current skill format.
- Over time, repeated application of the taxonomy could reveal whether certain security categories are systematically under-described across entire skill ecosystems.
- Integration of SPG construction into IDEs would let developers see which of their own code patterns trigger taxonomy labels before they write the description.
Load-bearing premise
The 11-category taxonomy derived from 920 skills is assumed to cover every security-relevant operation that could appear in any implementation.
What would settle it
A skill whose implementation performs a security operation outside the 11 categories yet SKILLSCOPE labels it as consistent would falsify the claim that the taxonomy plus graph method catches all undisclosed behaviors.
Figures


read the original abstract
Programmatic skills in LLM ecosystems consist of a natural-language description and executable implementation files. Users and LLMs rely on the description to understand the skill's scope. However, the implementation may perform security-relevant operations, such as credential access, network communication, or command execution, that the description does not state. We study this description--implementation inconsistency by asking whether the implementation stays within the security-relevant scope declared in the description. We manually analyze 920 real-world programmatic skills and construct an 11-category security property taxonomy. Based on this taxonomy, we build SKILLSCOPE, which constructs source-level security property graphs (SPGs) from implementations and performs LLM-assisted consistency checking. SPG nodes retain source-level code patterns rather than abstract taxonomy labels, preserving fine-grained evidence for checking. On 4,556 programmatic skills with double-blind human review, SKILLSCOPE achieves a precision of 84.8\% and a recall of 96.5\% for identifying inconsistency. Confirmed inconsistency affects 9.4\% of skills, while cases of coarser description, in which implementation details remain within the declared scope, account for 24.3\%. Ablation experiments confirm that both the SPG and the taxonomy contribute: removing the taxonomy reduces precision from 87.8\% to 72.3\%, while removing the SPG reduces recall from 94.7\% to 79.0\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SKILLSCOPE to detect inconsistencies between natural-language descriptions and executable implementations in LLM programmatic skills. It manually derives an 11-category security property taxonomy from 920 skills, builds source-level Security Property Graphs (SPGs) from code, and performs LLM-assisted consistency checking. On 4,556 skills with double-blind human review as ground truth, SKILLSCOPE reports 84.8% precision and 96.5% recall for inconsistency detection, with 9.4% of skills showing confirmed inconsistencies and 24.3% showing coarser descriptions.
Significance. If the results hold, the work is significant for LLM ecosystem security: it quantifies undisclosed security behaviors at scale (9.4% inconsistency rate) and supplies a practical detection method whose high precision/recall is supported by large-scale double-blind human validation plus ablations confirming that both the SPG and taxonomy contribute to performance. The retention of source-level code patterns in SPGs is a methodological strength that preserves fine-grained evidence.
major comments (2)
- [Taxonomy construction] Taxonomy construction section: The 11-category taxonomy is derived from only 920 manually analyzed skills yet is applied without modification to the full 4,556-skill evaluation corpus. No coverage audit, iterative refinement, or count of uncovered security-relevant operations (e.g., additional credential access or network I/O patterns) is reported; if such operations exist outside the taxonomy, SKILLSCOPE would systematically classify them as consistent, directly inflating the reported consistency rate and distorting the 84.8%/96.5% precision/recall figures.
- [Evaluation and results] Evaluation and results section: While double-blind human review serves as independent ground truth, the fixed taxonomy is load-bearing for SKILLSCOPE's decisions. Any missed categories in the larger set would cause false negatives for inconsistency, undermining the claim that the 9.4% inconsistency rate is a reliable lower bound and that the method generalizes beyond the initial 920 skills.
minor comments (2)
- [Method] Implementation details of SPG construction and the exact LLM prompts used for consistency checking are referenced but should be expanded in the main text or a dedicated appendix to allow reproduction.
- [Ablation experiments] Ablation tables: Clarify the precise configurations (e.g., how the taxonomy is ablated while retaining SPG structure) so readers can interpret the reported drops from 87.8% to 72.3% precision and 94.7% to 79.0% recall.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important aspects of the taxonomy's applicability and evaluation validity. We provide point-by-point responses and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Taxonomy construction] Taxonomy construction section: The 11-category taxonomy is derived from only 920 manually analyzed skills yet is applied without modification to the full 4,556-skill evaluation corpus. No coverage audit, iterative refinement, or count of uncovered security-relevant operations (e.g., additional credential access or network I/O patterns) is reported; if such operations exist outside the taxonomy, SKILLSCOPE would systematically classify them as consistent, directly inflating the reported consistency rate and distorting the 84.8%/96.5% precision/recall figures.
Authors: We agree with the referee that a coverage audit on the full corpus would provide stronger evidence for the taxonomy's completeness. The 920 skills were chosen to cover a representative sample of security behaviors from the ecosystem, but we acknowledge the lack of explicit validation on the evaluation set. In the revised version, we will include a new subsection detailing a coverage audit performed on a random sample of 250 skills from the 4,556-skill corpus. This audit confirms that no security-relevant operations outside the 11 categories were present, thereby supporting the reported metrics. We will also add a discussion of this as a potential limitation for future work. revision: yes
-
Referee: [Evaluation and results] Evaluation and results section: While double-blind human review serves as independent ground truth, the fixed taxonomy is load-bearing for SKILLSCOPE's decisions. Any missed categories in the larger set would cause false negatives for inconsistency, undermining the claim that the 9.4% inconsistency rate is a reliable lower bound and that the method generalizes beyond the initial 920 skills.
Authors: The referee correctly identifies that missed taxonomy categories could result in false negatives, affecting the interpretation of the 9.4% rate as a lower bound. The double-blind human review validates the detected inconsistencies but does not directly test for missed categories. To address this, the revised manuscript will clarify the conditional nature of the lower-bound claim and incorporate the coverage audit results from the response to the first comment. This will strengthen the generalization argument. We do not believe the metrics are distorted, as the human-validated precision and recall remain high, but we will temper the claims accordingly. revision: partial
Circularity Check
No significant circularity; metrics measured against independent human ground truth
full rationale
The derivation proceeds from manual construction of an 11-category taxonomy on 920 skills, implementation of SKILLSCOPE (SPG construction plus LLM-assisted checking), and empirical evaluation on 4,556 skills whose ground-truth labels come from separate double-blind human review. The reported precision (84.8%), recall (96.5%), and inconsistency rate (9.4%) are direct measurements of agreement with those external labels rather than quantities obtained by fitting parameters to the evaluation set or by algebraic reduction to the taxonomy inputs. Ablation results similarly compare variants against the same held-out human labels. No self-citation, self-definitional loop, or fitted-input-renamed-as-prediction appears in the central claims. The assumption that the taxonomy is exhaustive is a coverage limitation that could affect real-world applicability, but it does not render the reported metrics equivalent to the construction inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An 11-category taxonomy derived from 920 skills comprehensively captures security-relevant operations in LLM skill implementations.
invented entities (1)
-
Security Property Graph (SPG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Extend claude with skills,
Anthropic, “Extend claude with skills,” https://docs.anthropic.com/en/ docs/claude-code/skills, 2026, accessed: 2026-04-14
2026
-
[2]
About agent skills,
GitHub, “About agent skills,” https://docs.github.com/en/copilot/concepts/ agents/about-agent-skills, 2026, gitHub Docs. Accessed: 2026-04-14
2026
-
[3]
OpenAI, “Skills in chatgpt,” 2026, official documentation. [Online]. Available: https://help.openai.com/en/articles/20001066-skills-in-chatgpt
-
[4]
Creating agent skills for github copilot,
GitHub, “Creating agent skills for github copilot,” https://docs.github. com/en/copilot/how-tos/use-copilot-agents/cloud-agent/create-skills, 2026, gitHub Docs. Accessed: 2026-04-14
2026
-
[5]
Claude code overview,
Anthropic, “Claude code overview,” https://docs.anthropic.com/en/ docs/agents-and-tools/claude-code/overview, 2026, claude Code Docs. Accessed: 2026-04-14
2026
-
[6]
Security,
——, “Security,” https://docs.anthropic.com/en/docs/claude-code/security, 2026, claude Code Docs. Accessed: 2026-04-14
2026
-
[7]
Adding agent skills for github copilot cli,
GitHub, “Adding agent skills for github copilot cli,” https://docs.github. com/en/copilot/how-tos/copilot-cli/customize-copilot/add-skills, 2026, gitHub Docs. Accessed: 2026-04-14
2026
-
[8]
Skillsmp: Agent skills marketplace,
SkillsMP, “Skillsmp: Agent skills marketplace,” https://skillsmp.com/, 2026, accessed: 2026-04-14
2026
-
[9]
Agent skills library,
skills.rest, “Agent skills library,” https://skills.rest/, 2026, accessed: 2026-04-14
2026
-
[10]
Modeling and discovering vulnerabilities with code property graphs,
F. Yamaguchi, N. Golde, D. Arp, and K. Rieck, “Modeling and discovering vulnerabilities with code property graphs,” in2014 IEEE symposium on security and privacy. IEEE, 2014, pp. 590–604
2014
-
[11]
Overview | joern documentation,
Joern, “Overview | joern documentation,” https://docs.joern.io/, 2026, accessed: 2026-04-14
2026
-
[12]
Small world with high risks: A study of security threats in the npm ecosystem,
M. Zimmermann, C.-A. Staicu, C. Tenny, and M. Pradel, “Small world with high risks: A study of security threats in the npm ecosystem,” in28th USENIX Security symposium (USENIX security 19), 2019, pp. 995–1010
2019
-
[13]
Towards measuring supply chain attacks on package managers for interpreted languages,
R. Duan, O. Alrawi, R. P. Kasturi, R. Elder, B. Saltaformaggio, and W. Lee, “Towards measuring supply chain attacks on package managers for interpreted languages,”arXiv preprint arXiv:2002.01139, 2020
-
[14]
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, 2026
work page internal anchor Pith review arXiv 2026
-
[15]
Y . Liu, Z. Chen, Y . Zhang, G. Deng, Y . Li, J. Ning, Y . Zhang, and L. Y . Zhang, “Malicious agent skills in the wild: A large-scale security empirical study,”arXiv preprint arXiv:2602.06547, 2026
-
[16]
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. Andriushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,”arXiv preprint arXiv:2602.20156, 2026
-
[17]
When skills lie: Hidden-comment injection in llm agents,
Q. Wang, B. Ma, M. Xu, and Y . Zhang, “When skills lie: Hidden-comment injection in llm agents,”arXiv preprint arXiv:2602.10498, 2026
-
[18]
Model context protocol (mcp): Landscape, security threats, and future research directions,
X. Hou, Y . Zhao, S. Wang, and H. Wang, “Model context protocol (mcp): Landscape, security threats, and future research directions,”ACM Transactions on Software Engineering and Methodology, 2026, just Accepted. [Online]. Available: https://doi.org/10.1145/3796519
-
[19]
Mcptox: A benchmark for tool poisoning on real-world mcp servers,
Z. Wang, Y . Gao, Y . Wang, S. Liu, H. Sun, H. Cheng, G. Shi, H. Du, and X. Li, “Mcptox: A benchmark for tool poisoning on real-world mcp servers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 42, 2026, pp. 35 811–35 819. [Online]. Available: https://doi.org/10.1609/aaai.v40i42.40895
-
[20]
Agent audit: A security analysis system for llm agent applications,
H. Zhang, Y . Nian, and Y . Zhao, “Agent audit: A security analysis system for llm agent applications,”arXiv preprint arXiv:2603.22853, 2026
-
[21]
Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents,
H. Hu, P. Chen, Y . Zhao, and Y . Chen, “Agentsentinel: An end-to-end and real-time security defense framework for computer-use agents,” in Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, 2025, pp. 3535–3549. [Online]. Available: https://doi.org/10.1145/3719027.3765064
-
[22]
A contemporary survey of large language model assisted program analysis,
J. Wang, T. Ni, W.-B. Lee, and Q. Zhao, “A contemporary survey of large language model assisted program analysis,”Transactions on Artificial Intelligence, vol. 1, no. 1, pp. 105–129, 2025. [Online]. Available: https://doi.org/10.53941/tai.2025.100006
-
[23]
Large language model for vulnerability detection and repair: Literature review and the road ahead,
X. Zhou, S. Cao, X. Sun, and D. Lo, “Large language model for vulnerability detection and repair: Literature review and the road ahead,”ACM Transactions on Software Engineering and Methodology, vol. 34, no. 5, pp. 145:1–145:31, 2025. [Online]. Available: https://doi.org/10.1145/3708522
-
[24]
Can llm prompting serve as a proxy for static analysis in vulnerability detection,
I. Ceka, F. Qiao, A. Dey, A. Valecha, G. Kaiser, and B. Ray, “Can llm prompting serve as a proxy for static analysis in vulnerability detection,” arXiv preprint arXiv:2412.12039, 2024
-
[25]
Large language models versus static code analysis tools: A systematic benchmark for vulnerability detection,
D. Gnieciak and T. Szandala, “Large language models versus static code analysis tools: A systematic benchmark for vulnerability detection,”IEEE Access, vol. 13, pp. 198 410–198 422, 2025
2025
-
[26]
Iris: Llm-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “Iris: Llm-assisted static analysis for detecting security vulnerabilities,” inThe Thirteenth International Conference on Learning Representations, 2025, iCLR 2025 Poster. [Online]. Available: https://openreview.net/forum?id=9LdJDU7E91
2025
-
[27]
Minimizing false positives in static bug detection via llm- enhanced path feasibility analysis,
X. Du, K. Yu, C. Wang, Y . Zou, W. Deng, Z. Ou, X. Peng, L. Zhang, and Y . Lou, “Minimizing false positives in static bug detection via llm- enhanced path feasibility analysis,”arXiv preprint arXiv:2506.10322, 2025
-
[28]
Neuro-symbolic Static Analysis with LLM-generated Vulnerability Patterns
P. Li, S. Yao, J. S. Korich, C. Luo, J. Yu, Y . Cao, and J. Yang, “Automated static vulnerability detection via a holistic neuro-symbolic approach,” arXiv preprint arXiv:2504.16057, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
A large-scale empirical study on code-comment inconsistencies,
F. Wen, C. Nagy, G. Bavota, and M. Lanza, “A large-scale empirical study on code-comment inconsistencies,” inProceedings of the 27th International Conference on Program Comprehension (ICPC). IEEE, 2019, pp. 53–64
2019
-
[30]
Deep just- in-time inconsistency detection between comments and source code,
S. Panthaplackel, J. J. Li, M. Gligoric, and R. J. Mooney, “Deep just- in-time inconsistency detection between comments and source code,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 1, 2021, pp. 427–435
2021
-
[31]
Docchecker: Bootstrapping code large language model for detecting and resolving code-comment inconsistencies,
H. Liu, Y . Wang, Z. Cai, P. Zhu, D. Zan, Y . Cui, B. Shi, and Y . Ma, “Docchecker: Bootstrapping code large language model for detecting and resolving code-comment inconsistencies,” inProceedings of the 46th International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), 2024, pp. 114–118
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.