Recognition: unknown
ASAP: Amortized Doubly-Stochastic Attention via Sliced Dual Projection
Pith reviewed 2026-05-14 20:14 UTC · model grok-4.3
The pith
ASAP replaces iterative Sinkhorn scaling in doubly-stochastic attention with a learned fixed sliced dual projection for faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
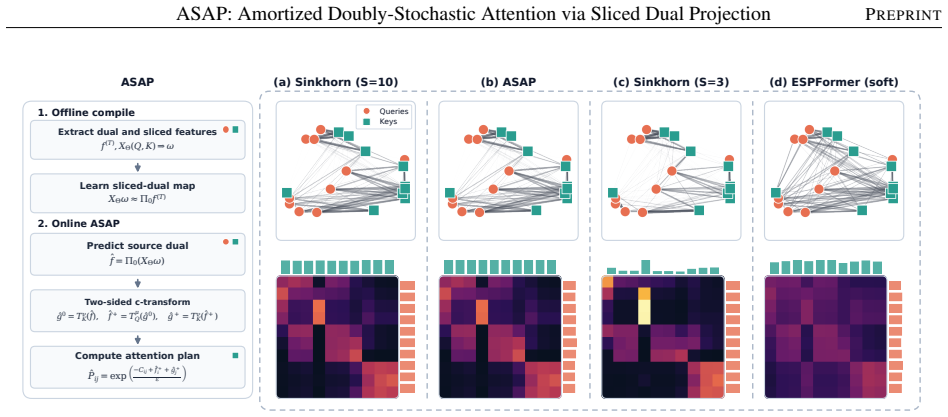
ASAP trains a doubly-stochastic attention layer with Sinkhorn scaling and then compiles it into an amortized operator by learning a parametric map from one-dimensional Kantorovich potentials to Sinkhorn query-side duals; at inference the map plus a two-sided entropic c-transform reconstructs the attention plan without iterative scaling.
What carries the argument
Lightweight parametric map from exact one-dimensional Kantorovich potentials to Sinkhorn query-side dual variables, followed by reconstruction via two-sided entropic c-transform.
If this is right
- ASAP runs 5.3 times faster than the trained Sinkhorn teacher in the main frozen-layer benchmark while matching its accuracy.
- Downstream replacements recover most of the teacher performance without any retraining.
- Training cost stays at the level of ordinary Sinkhorn attention.
- The method stays competitive with recent baselines across language and vision tasks.
Where Pith is reading between the lines
- The same amortization pattern could be applied to other iterative optimal-transport layers by learning maps from cheap duals to their full counterparts.
- If the map remains accurate at very long sequence lengths, transport-based attention could become practical for large-context models.
- The approach illustrates a general template: train with an iterative solver then deploy a learned fixed operator for speed.
Load-bearing premise
The parametric map learned from one-dimensional Kantorovich potentials to Sinkhorn duals generalizes accurately to new inputs so that the reconstructed plan remains doubly stochastic and preserves accuracy.
What would settle it
Compare ASAP accuracy and downstream task performance against full Sinkhorn on a held-out dataset whose inputs lie outside the distribution used to train the parametric map; a substantial gap would show the map fails to generalize.
Figures
read the original abstract
Doubly-stochastic attention has emerged as a transport-based alternative to row-softmax attention, with recent Transformer variants using it to reduce attention sinks and rank collapse while improving performance. In this family, the standard approach is Sinkhorn scaling, which trains more efficiently but still repeats matrix scaling in every inference forward pass. Sliced-transport attention removes the online iteration, but its soft sorting approximation materializes dense tensors for each slice, requiring substantially more training resources than Sinkhorn attention. We introduce ASAP: Amortized Doubly-Stochastic Attention via Sliced Dual Projection, a train-then-compile method that trains the doubly-stochastic layer with Sinkhorn, then replaces the iterative scaling loop at inference with a fixed sliced-dual operator. It learns a lightweight parametric map from exact one-dimensional Kantorovich potentials to the Sinkhorn query-side dual, then reconstructs the attention plan with a two-sided entropic c-transform. Across language and vision benchmarks, ASAP keeps the cheaper training setup and remains highly competitive with recent baselines. In the main frozen-layer benchmark, ASAP is 5.3 faster than the trained Sinkhorn teacher while matching its accuracy; in downstream replacements, ASAP recovers most of the teacher performance without any retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ASAP (Amortized Doubly-Stochastic Attention via Sliced Dual Projection), a train-then-compile method for doubly-stochastic attention in Transformers. The approach trains the layer using Sinkhorn scaling and at inference replaces the iterative loop with a fixed sliced-dual operator. This operator learns a lightweight parametric map from exact one-dimensional Kantorovich potentials to the Sinkhorn query-side dual, followed by reconstruction of the attention plan using a two-sided entropic c-transform. Evaluations on language and vision benchmarks demonstrate competitive accuracy, with a reported 5.3x speedup over the Sinkhorn teacher in frozen-layer settings and recovery of most teacher performance in downstream replacements without retraining.
Significance. If the learned map generalizes sufficiently to preserve the doubly-stochastic properties and accuracy, this work provides an efficient inference-time alternative to Sinkhorn scaling for doubly-stochastic attention, potentially reducing computational costs in large models while retaining advantages such as mitigation of attention sinks and rank collapse. The separation of training (with exact Sinkhorn) and inference (amortized) is a notable strength for practical deployment.
major comments (3)
- [§3 (Method)] §3 (Method): The reconstruction via the two-sided entropic c-transform is presented without any analysis or bounds on how closely the output attention matrix satisfies the doubly-stochastic constraints (row and column sums equal to 1). This is load-bearing for the claims of reduced attention sinks and improved rank stability, as violations could undermine these benefits.
- [§4 (Experiments)] §4 (Experiments): The main frozen-layer benchmark reports a 5.3x speedup and matching accuracy, but lacks quantitative metrics on the approximation error of the dual variables or the maximum deviation from doubly-stochasticity across test samples. Without these, it is unclear whether the performance match holds due to the approximation being sufficiently accurate.
- [§4 (Experiments)] §4 (Experiments): There is no ablation or sensitivity analysis on the parametric map's architecture or its performance on out-of-distribution inputs (e.g., varying sequence lengths), which directly relates to the generalization from the training distribution of 1D potentials to Sinkhorn duals.
minor comments (2)
- [Abstract] The abstract claims the method 'remains highly competitive with recent baselines' but does not name the baselines or include even summary numerical comparisons.
- Notation for the sliced dual projection and the lightweight parametric map could be clarified with an explicit pseudocode listing of the inference procedure.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of the manuscript. We address each major comment below and have incorporated revisions to provide the requested analysis and metrics.
read point-by-point responses
-
Referee: [§3 (Method)] The reconstruction via the two-sided entropic c-transform is presented without any analysis or bounds on how closely the output attention matrix satisfies the doubly-stochastic constraints (row and column sums equal to 1). This is load-bearing for the claims of reduced attention sinks and improved rank stability, as violations could undermine these benefits.
Authors: We agree that a more formal analysis would be beneficial. The two-sided entropic c-transform is constructed such that if the input duals exactly match the Sinkhorn solution, the output is exactly doubly-stochastic. Since our parametric map is trained to minimize the discrepancy to the true duals, the resulting matrix is expected to be close. To address this, we will add in the revised §3 an empirical evaluation of the row and column sum deviations on a held-out set of attention maps, along with a brief discussion of the approximation properties. revision: yes
-
Referee: [§4 (Experiments)] The main frozen-layer benchmark reports a 5.3x speedup and matching accuracy, but lacks quantitative metrics on the approximation error of the dual variables or the maximum deviation from doubly-stochasticity across test samples. Without these, it is unclear whether the performance match holds due to the approximation being sufficiently accurate.
Authors: We concur that including these quantitative metrics will strengthen the experimental section. In the revised manuscript, we will augment §4 with tables reporting the mean approximation error (e.g., MSE between predicted and Sinkhorn duals) and the maximum deviation from unit row/column sums, computed across all test samples in the frozen-layer setting. These will demonstrate that the amortization error is small enough to preserve the performance benefits. revision: yes
-
Referee: [§4 (Experiments)] There is no ablation or sensitivity analysis on the parametric map's architecture or its performance on out-of-distribution inputs (e.g., varying sequence lengths), which directly relates to the generalization from the training distribution of 1D potentials to Sinkhorn duals.
Authors: The original manuscript focused on end-to-end performance rather than internal ablations to keep the presentation concise. However, we recognize the value of such analysis for assessing generalization. We will include in the appendix a sensitivity study varying the architecture (e.g., number of layers and hidden size of the parametric map) and evaluate performance on sequences with lengths outside the training distribution of the map. This will be added as a new subsection in the supplementary material. revision: partial
Circularity Check
No significant circularity in amortized approximation
full rationale
The paper trains a parametric map on Sinkhorn teacher outputs (exact 1D Kantorovich potentials to query-side duals) and deploys the fixed map at inference via two-sided entropic c-transform. This is an empirical amortization of an iterative solver, not a derivation that reduces to its own fitted values or self-citations by construction. No load-bearing self-citation chains, uniqueness theorems from prior author work, or self-definitional steps appear in the described method or abstract. Performance claims rest on external benchmarks rather than internal equivalence.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the lightweight parametric map
axioms (2)
- standard math Entropic optimal transport admits a unique dual solution that can be recovered from one-dimensional marginals via c-transforms
- domain assumption Sinkhorn scaling produces the exact doubly-stochastic plan used as teacher signal
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[3]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[4]
Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages=
Sinkformers: Transformers with Doubly Stochastic Attention , author=. Proceedings of The 25th International Conference on Artificial Intelligence and Statistics , pages=. 2022 , series=
2022
-
[5]
International Conference on Learning Representations , year=
Expected Sliced Transport Plans , author=. International Conference on Learning Representations , year=
-
[6]
Proceedings of the 42nd International Conference on Machine Learning , pages=
ESPFormer: Doubly-Stochastic Attention with Expected Sliced Transport Plans , author=. Proceedings of the 42nd International Conference on Machine Learning , pages=. 2025 , series=
2025
-
[7]
arXiv preprint arXiv:2509.23436 , year=
LOTFormer: Doubly-Stochastic Linear Attention via Low-Rank Optimal Transport , author=. arXiv preprint arXiv:2509.23436 , year=
-
[8]
Advances in Neural Information Processing Systems , year=
Quantum Doubly Stochastic Transformers , author=. Advances in Neural Information Processing Systems , year=
-
[9]
Sinkhorn doubly stochastic attention rank decay analysis
Sinkhorn Doubly Stochastic Attention Rank Decay Analysis , author=. arXiv preprint arXiv:2604.07925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
International Conference on Learning Representations , year=
Efficient Streaming Language Models with Attention Sinks , author=. International Conference on Learning Representations , year=
- [11]
-
[12]
arXiv preprint arXiv:2103.03404 , year=
Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth , author=. arXiv preprint arXiv:2103.03404 , year=
-
[13]
Proceedings of the 40th International Conference on Machine Learning , pages=
Meta Optimal Transport , author=. Proceedings of the 40th International Conference on Machine Learning , pages=. 2023 , series=
2023
-
[14]
Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages=
Rethinking Initialization of the Sinkhorn Algorithm , author=. Proceedings of The 26th International Conference on Artificial Intelligence and Statistics , pages=. 2023 , series=
2023
-
[15]
Amortized Optimal Transport from Sliced Potentials
Amortized Optimal Transport from Sliced Potentials , author=. arXiv preprint arXiv:2604.15114 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Proceedings of the 41st International Conference on Machine Learning , pages=
Wasserstein Wormhole: Scalable Optimal Transport Distance with Transformer , author=. Proceedings of the 41st International Conference on Machine Learning , pages=. 2024 , series=
2024
-
[17]
Advances in Neural Information Processing Systems , year=
Fast Optimal Transport through Sliced Generalized Wasserstein Geodesics , author=. Advances in Neural Information Processing Systems , year=
-
[18]
Advances in Neural Information Processing Systems , year=
Differentiable Generalized Sliced Wasserstein Plans , author=. Advances in Neural Information Processing Systems , year=
-
[19]
arXiv preprint arXiv:2511.19741 , year=
Efficient Transferable Optimal Transport via Min-Sliced Transport Plans , author=. arXiv preprint arXiv:2511.19741 , year=
-
[20]
Advances in Neural Information Processing Systems , year=
Attention Is All You Need , author=. Advances in Neural Information Processing Systems , year=
-
[21]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Sinkhorn Distances: Lightspeed Computation of Optimal Transport , author=. Advances in Neural Information Processing Systems , year=
-
[23]
Proceedings of the 37th International Conference on Machine Learning , pages=
Sparse Sinkhorn Attention , author=. Proceedings of the 37th International Conference on Machine Learning , pages=. 2020 , series=
2020
-
[24]
arXiv preprint arXiv:2508.08369 , year=
Scaled-Dot-Product Attention as One-Sided Entropic Optimal Transport , author=. arXiv preprint arXiv:2508.08369 , year=
-
[25]
arXiv preprint arXiv:2602.03067 , year=
FlashSinkhorn: IO-Aware Entropic Optimal Transport , author=. arXiv preprint arXiv:2602.03067 , year=
-
[26]
arXiv preprint arXiv:2508.01243 , year=
Sliced Optimal Transport Plans , author=. arXiv preprint arXiv:2508.01243 , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
Differentiable Ranking and Sorting using Optimal Transport , author=. Advances in Neural Information Processing Systems , volume=. 2019 , url=
2019
-
[28]
International Conference on Learning Representations , year=
Fast Estimation of Wasserstein Distances via Regression on Sliced Wasserstein Distances , author=. International Conference on Learning Representations , year=
-
[29]
arXiv preprint arXiv:2508.12519 , year=
An Introduction to Sliced Optimal Transport , author=. arXiv preprint arXiv:2508.12519 , year=
-
[30]
Sliced-Regularized Optimal Transport
Sliced-Regularized Optimal Transport , author=. arXiv preprint arXiv:2604.23944 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Advances in Neural Information Processing Systems , volume=
Revisiting Sliced Wasserstein on Images: From Vectorization to Convolution , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[32]
Advances in Neural Information Processing Systems , volume=
Energy-Based Sliced Wasserstein Distance , author=. Advances in Neural Information Processing Systems , volume=. 2023 , url=
2023
-
[33]
International Conference on Learning Representations , year=
Quasi-Monte Carlo for 3D Sliced Wasserstein , author=. International Conference on Learning Representations , year=
-
[34]
International Conference on Learning Representations , year=
Spherical Sliced-Wasserstein , author=. International Conference on Learning Representations , year=
-
[35]
and Kolouri, Soheil , booktitle=
Tran, Huy and Bai, Yikun and Kothapalli, Abihith and Shahbazi, Ashkan and Liu, Xinran and Diaz Martin, Rocio P. and Kolouri, Soheil , booktitle=. Stereographic Spherical Sliced. 2024 , series=
2024
-
[36]
Journal of Machine Learning Research , volume=
Sliced-Wasserstein Distances and Flows on Cartan-Hadamard Manifolds , author=. Journal of Machine Learning Research , volume=. 2025 , url=
2025
-
[37]
Transactions on Machine Learning Research , year=
Slicing Unbalanced Optimal Transport , author=. Transactions on Machine Learning Research , year=
-
[38]
International Conference on Learning Representations , year=
Differential Transformer , author=. International Conference on Learning Representations , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , author=. Advances in Neural Information Processing Systems , volume=. 2022 , url=
2022
-
[40]
International Conference on Learning Representations , year=
Reformer: The Efficient Transformer , author=. International Conference on Learning Representations , year=
-
[41]
Linformer: Self-Attention with Linear Complexity
Linformer: Self-Attention with Linear Complexity , author=. arXiv preprint arXiv:2006.04768 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[42]
International Conference on Learning Representations , year=
Rethinking Attention with Performers , author=. International Conference on Learning Representations , year=
-
[43]
Xiong, Yunyang and Zeng, Zhanpeng and Chakraborty, Rudrasis and Tan, Mingxing and Fung, Glenn and Li, Yin and Singh, Vikas , booktitle=. Nystr. 2021 , url=
2021
-
[44]
arXiv preprint arXiv:2110.06821 , year=
Leveraging Redundancy in Attention with Reuse Transformers , author=. arXiv preprint arXiv:2110.06821 , year=
-
[45]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
On Attention Redundancy: A Comprehensive Study , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=. 2021 , url=
2021
-
[46]
2020 , url=
Lan, Zhenzhong and Chen, Mingda and Goodman, Sebastian and Gimpel, Kevin and Sharma, Piyush and Soricut, Radu , booktitle=. 2020 , url=
2020
-
[47]
Proceedings of the 37th International Conference on Machine Learning , pages=
SoftSort: A Continuous Relaxation for the argsort Operator , author=. Proceedings of the 37th International Conference on Machine Learning , pages=. 2020 , series=
2020
-
[48]
Proceedings of the 38th International Conference on Machine Learning , pages=
Differentiable Sorting Networks for Scalable Sorting and Ranking Supervision , author=. Proceedings of the 38th International Conference on Machine Learning , pages=. 2021 , series=
2021
-
[49]
Advances in Neural Information Processing Systems , volume=
Character-level Convolutional Networks for Text Classification , author=. Advances in Neural Information Processing Systems , volume=. 2015 , url=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.