Recognition: unknown
Amortized Optimal Transport from Sliced Potentials
Pith reviewed 2026-05-10 09:47 UTC · model grok-4.3
The pith
Sliced optimal transport potentials can amortize the prediction of full optimal transport plans across many measure pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Kantorovich potentials from sliced optimal transport serve as predictors for the potentials of the full optimal transport problem. A functional regression model is fit by least-squares methods in RA-OT, or its parameters are estimated by optimizing the Kantorovich dual objective in OA-OT. The predicted OT plan is then recovered from the estimated potentials. This yields amortized solvers that reuse information across multiple measure pairs, remain parsimonious, and do not depend on structures such as the number of atoms in the discrete case.
What carries the argument
The RA-OT regression and OA-OT dual-optimization models that map sliced OT Kantorovich potentials to full OT potentials for subsequent plan recovery.
Load-bearing premise
Kantorovich potentials obtained from sliced OT contain enough information to accurately predict or optimize the full OT potentials via regression or dual objectives.
What would settle it
On held-out pairs of measures, compare the transport cost or plan recovered from the amortized potentials against the cost or plan from directly solving the full OT problem; large discrepancies would show the sliced potentials are not sufficiently informative.
Figures










read the original abstract
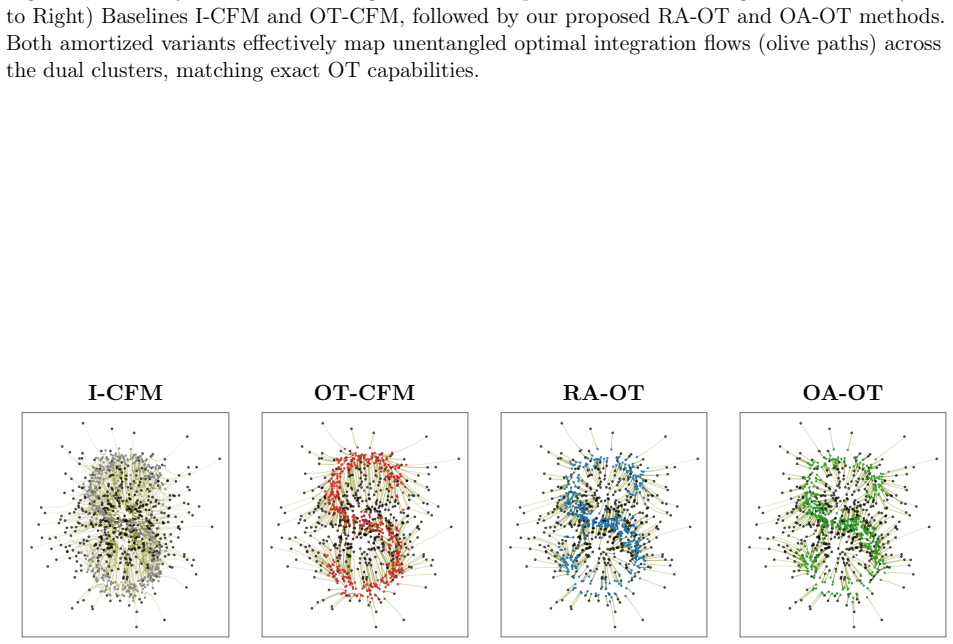
We propose a novel amortized optimization method for predicting optimal transport (OT) plans across multiple pairs of measures by leveraging Kantorovich potentials derived from sliced OT. We introduce two amortization strategies: regression-based amortization (RA-OT) and objective-based amortization (OA-OT). In RA-OT, we formulate a functional regression model that treats Kantorovich potentials from the original OT problem as responses and those obtained from sliced OT as predictors, and estimate these models via least-squares methods. In OA-OT, we estimate the parameters of the functional model by optimizing the Kantorovich dual objective. In both approaches, the predicted OT plan is subsequently recovered from the estimated potentials. As amortized OT methods, both RA-OT and OA-OT enable efficient solutions to repeated OT problems across different measure pairs by reusing information learned from prior instances to rapidly approximate new solutions. Moreover, by exploiting the structure provided by sliced OT, the proposed models are more parsimonious, independent of specific structures of the measures, such as the number of atoms in the discrete case, while achieving high accuracy. We demonstrate the effectiveness of our approaches on tasks including MNIST digit transport, color transfer, supply-demand transportation on spherical data, and mini-batch OT conditional flow matching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two amortized methods (RA-OT and OA-OT) for predicting optimal transport plans across multiple measure pairs. RA-OT performs functional regression treating sliced-OT Kantorovich potentials as predictors and full-OT potentials as responses, estimated by least squares; OA-OT optimizes the parameters of a functional model directly on the Kantorovich dual objective. In both cases the transport plan is recovered from the estimated potentials. The methods are presented as structure-independent, parsimonious, and efficient for repeated OT problems, with empirical demonstrations on MNIST digit transport, color transfer, spherical supply-demand, and mini-batch OT conditional flow matching.
Significance. If the approximation quality holds across the claimed tasks, the work provides a practical route to amortize repeated OT computations by reusing sliced-OT information, which could reduce cost in pipelines that solve many transport problems (e.g., generative modeling or alignment tasks) while remaining independent of discrete support size.
major comments (2)
- [§3 (method description) and §4 (theoretical justification)] The central claim that sliced-OT potentials suffice to recover accurate full-OT plans rests on an unproven identifiability assumption. No theorem, error bound, or identifiability result is supplied showing that the averaged 1-D projections determine (or can approximate to controlled error) the multi-dimensional Kantorovich potentials; the regression or dual optimization may therefore converge to a plan whose coupling deviates substantially from the true OT plan when the measures contain couplings invisible in random projections.
- [Abstract and §5 (experiments)] The abstract and experimental sections state that both RA-OT and OA-OT “achieve high accuracy” on the listed tasks, yet no quantitative metrics (Wasserstein distance, relative error, runtime tables), error bars, ablation on number of slices, or direct comparison to Sinkhorn, entropic OT, or existing amortized baselines are referenced. Without these numbers it is impossible to judge whether the recovered plans are competitive or merely plausible.
minor comments (2)
- [§3.1] Clarify the precise functional form and parameterization of the regression model in RA-OT (e.g., is it a neural network, kernel ridge, or linear functional?) and the initialization strategy for OA-OT.
- [§6 (discussion)] Add a short discussion of failure modes or regimes (e.g., high-dimensional or highly anisotropic measures) where the sliced-potential approximation is expected to degrade.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [§3 (method description) and §4 (theoretical justification)] The central claim that sliced-OT potentials suffice to recover accurate full-OT plans rests on an unproven identifiability assumption. No theorem, error bound, or identifiability result is supplied showing that the averaged 1-D projections determine (or can approximate to controlled error) the multi-dimensional Kantorovich potentials; the regression or dual optimization may therefore converge to a plan whose coupling deviates substantially from the true OT plan when the measures contain couplings invisible in random projections.
Authors: We appreciate the referee highlighting this theoretical gap. Our methods are motivated by the practical efficiency of sliced OT potentials as predictors for full OT potentials, building on the established approximation properties of sliced Wasserstein distances. We do not claim or prove that sliced projections universally determine the full Kantorovich potentials, nor do we supply error bounds or an identifiability theorem. The regression and optimization steps are presented as empirical amortization strategies that work well when the sliced information is sufficiently informative. In the revision we will add an explicit discussion of this limitation, clarify the assumptions, and note that a rigorous theoretical analysis of when the approximation holds (or fails) is left for future work. revision: partial
-
Referee: [Abstract and §5 (experiments)] The abstract and experimental sections state that both RA-OT and OA-OT “achieve high accuracy” on the listed tasks, yet no quantitative metrics (Wasserstein distance, relative error, runtime tables), error bars, ablation on number of slices, or direct comparison to Sinkhorn, entropic OT, or existing amortized baselines are referenced. Without these numbers it is impossible to judge whether the recovered plans are competitive or merely plausible.
Authors: We agree that quantitative metrics are necessary to substantiate the accuracy claims. The current experiments emphasize visual and qualitative results on MNIST transport, color transfer, spherical data, and conditional flow matching. In the revised manuscript we will expand §5 to include Wasserstein distances to ground-truth OT plans, relative errors, runtime tables, error bars from repeated runs, an ablation study on the number of slices, and direct comparisons against Sinkhorn, entropic OT, and relevant amortized baselines. These additions will be reflected in the abstract as well. revision: yes
Circularity Check
No significant circularity; derivation relies on independent computation of sliced vs. full potentials followed by standard fitting.
full rationale
The paper computes Kantorovich potentials from sliced OT (via 1D projections) as an independent preprocessing step, then trains either a least-squares functional regression (RA-OT) or dual-objective optimization (OA-OT) to map those to full OT potentials before recovering the plan. Training explicitly requires separate computation of both sliced and full potentials on the training measure pairs, so the fitted mapping is not tautological. No equation equates the final plan to a quantity already present in the sliced inputs by construction, no load-bearing self-citation chain is invoked, and the method is presented as an empirical amortizer whose accuracy is validated on downstream tasks rather than derived from its own definitions.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
ASAP: Amortized Doubly-Stochastic Attention via Sliced Dual Projection
ASAP amortizes Sinkhorn-based doubly-stochastic attention by learning a parametric map from 1D potentials to the Sinkhorn dual and reconstructing the plan via two-sided entropic c-transform, delivering 5.3x faster inf...
-
Sliced-Regularized Optimal Transport
SROT regularizes the OT plan toward a smoothened sliced OT plan, producing more accurate approximations to exact OT than entropic OT while also improving on the sliced OT reference.
Reference graph
Works this paper leans on
-
[1]
Achlioptas, O
P. Achlioptas, O. Diamanti, I. Mitliagkas, and L. Guibas. Learning representations and generative models for 3d point clouds. InInternational Conference on Machine Learning, pages 40–49. PMLR, 2018. (Cited on page 2.)
2018
-
[2]
Altschuler, J
J. Altschuler, J. Niles-Weed, and P. Rigollet. Near-linear time approximation algorithms for optimal transport via Sinkhorn iteration. InAdvances in Neural Information Processing Systems, pages 1964–1974, 2017. (Cited on page 4.)
1964
-
[3]
Alvarez-Melis and N
D. Alvarez-Melis and N. Fusi. Geometric dataset distances via optimal transport.Advances in Neural Information Processing Systems, 33:21428–21439, 2020. (Cited on page 2.)
2020
-
[4]
B. Amos. Tutorial on amortized optimization.Foundations and Trends in Machine Learning, 16(5):592–732, 2023. (Cited on page 2.)
2023
-
[5]
B. Amos, G. Luise, S. Cohen, and I. Redko. Meta optimal transport. InInternational Conference on Machine Learning, pages 791–813. PMLR, 2023. (Cited on pages 2, 5, 8, 9, 10, 11, and 13.)
2023
-
[6]
Arjovsky, S
M. Arjovsky, S. Chintala, and L. Bottou. Wasserstein generative adversarial networks. In International Conference on Machine Learning, pages 214–223, 2017. (Cited on pages 1 and 2.)
2017
-
[7]
Benamou, G
J.-D. Benamou, G. Carlier, M. Cuturi, L. Nenna, and G. Peyré. Iterative Bregman projections for regularized transportation problems.SIAM Journal on Scientific Computing, 37(2):A1111– A1138, 2015. (Cited on page 2.)
2015
-
[8]
Bernton, P
E. Bernton, P. E. Jacob, M. Gerber, and C. P. Robert. Approximate Bayesian computation with the Wasserstein distance.Journal of the Royal Statistical Society Series B: Statistical Methodology, 81(2):235–269, 2019. (Cited on page 1.)
2019
-
[9]
Bernton, P
E. Bernton, P. E. Jacob, M. Gerber, and C. P. Robert. On parameter estimation with the Wasserstein distance.Information and Inference: A Journal of the IMA, 8(4):657–676, 2019. (Cited on page 1.)
2019
-
[10]
Bonet, P
C. Bonet, P. Berg, N. Courty, F. Septier, L. Drumetz, and M.-T. Pham. Spherical sliced- Wasserstein.International Conference on Learning Representations, 2023. (Cited on page 6.)
2023
-
[11]
Bonet, L
C. Bonet, L. Drumetz, and N. Courty. Sliced-Wasserstein distances and flows on Cartan- Hadamard manifolds.Journal of Machine Learning Research, 26(32):1–76, 2025. (Cited on page 6.)
2025
-
[12]
Bonneel and J
N. Bonneel and J. Digne. A survey of optimal transport for computer graphics and computer vision. InComputer Graphics Forum, volume 42, pages 439–460. Wiley Online Library, 2023. (Cited on page 1.)
2023
-
[13]
Bonneel, J
N. Bonneel, J. Rabin, G. Peyré, and H. Pfister. Sliced and Radon Wasserstein barycenters of measures.Journal of Mathematical Imaging and Vision, 1(51):22–45, 2015. (Cited on page 6.)
2015
-
[14]
Bunne, L
C. Bunne, L. Papaxanthos, A. Krause, and M. Cuturi. Proximal optimal transport modeling of population dynamics. InInternational Conference on Artificial Intelligence and Statistics, pages 6511–6528. PMLR, 2022. (Cited on page 2.) 21
2022
-
[15]
Bunne, S
C. Bunne, S. G. Stark, G. Gut, J. S. Del Castillo, M. Levesque, K.-V. Lehmann, L. Pelkmans, A. Krause, and G. Rätsch. Learning single-cell perturbation responses using neural optimal transport.Nature methods, 20(11):1759–1768, 2023. (Cited on page 1.)
2023
-
[16]
Catalano, H
M. Catalano, H. Lavenant, A. Lijoi, and I. Prünster. A Wasserstein index of dependence for random measures.Journal of the American Statistical Association, 119(547):2396–2406, 2024. (Cited on page 1.)
2024
-
[17]
Catalano, A
M. Catalano, A. Lijoi, and I. Prünster. Measuring dependence in the Wasserstein distance for Bayesian nonparametric models.The Annals of Statistics, 49(5):2916–2947, 2021. (Cited on page 1.)
2021
-
[18]
Courty, R
N. Courty, R. Flamary, and M. Ducoffe. Learning Wasserstein embeddings. InInternational Conference on Learning Representations, 2018. (Cited on page 2.)
2018
-
[19]
Courty, R
N. Courty, R. Flamary, A. Habrard, and A. Rakotomamonjy. Joint distribution optimal transportation for domain adaptation. InAdvances in Neural Information Processing Systems, pages 3730–3739, 2017. (Cited on page 1.)
2017
-
[20]
Courty, R
N. Courty, R. Flamary, D. Tuia, and A. Rakotomamonjy. Optimal transport for domain adaptation.IEEE transactions on pattern analysis and machine intelligence, 39(9):1853–1865,
-
[21]
M. Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors,Advances in Neural Information Processing Systems, volume 26. Curran Associates, Inc., 2013. (Cited on pages 2, 3, and 4.)
2013
-
[22]
Cuturi and A
M. Cuturi and A. Doucet. Fast computation of wasserstein barycenters. InInternational Conference on Machine Learning, pages 685–693. PMLR, 2014. (Cited on page 6.)
2014
-
[23]
B. B. Damodaran, B. Kellenberger, R. Flamary, D. Tuia, and N. Courty. Deepjdot: Deep joint distribution optimal transport for unsupervised domain adaptation. InProceedings of the European Conference on Computer Vision (ECCV), pages 447–463, 2018. (Cited on page 1.)
2018
-
[24]
Dowson and B
D. Dowson and B. Landau. The Fréchet distance between multivariate Normal distributions. Journal of Multivariate Analysis, 12(3):450–455, 1982. (Cited on page 1.)
1982
-
[25]
Doxsey-Whitfield, K
E. Doxsey-Whitfield, K. MacManus, S. B. Adamo, L. Pistolesi, J. Squires, O. Borkovska, and S. R. Baptista. Taking advantage of the improved availability of census data: A first look at the gridded population of the world, version 4.Papers in Applied Geography, 1(3):226–234, 2015. (Cited on page 9.)
2015
-
[26]
Engquist and B
B. Engquist and B. D. Froese. Application of the Wasserstein metric to seismic signals. Communications in Mathematical Sciences, 12(5):979–988, 2014. (Cited on page 2.)
2014
-
[27]
Fatras, T
K. Fatras, T. Sejourne, R. Flamary, and N. Courty. Unbalanced minibatch optimal transport; applications to domain adaptation. In M. Meila and T. Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 3186–3197. PMLR, 18–24 Jul 2021. (Cited on page 1.) 22
2021
-
[28]
Fatras, Y
K. Fatras, Y. Zine, R. Flamary, R. Gribonval, and N. Courty. Learning with minibatch Wasser- stein: asymptotic and gradient properties. InAISTATS 2020-23nd International Conference on Artificial Intelligence and Statistics, volume 108, pages 1–20, 2020. (Cited on page 1.)
2020
-
[29]
Feydy, B
J. Feydy, B. Charlier, F.-X. Vialard, and G. Peyré. Optimal transport for diffeomorphic registration. InMedical Image Computing and Computer Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part I 20, pages 291–299. Springer, 2017. (Cited on page 1.)
2017
-
[30]
R. C. Garrett, T. Harris, Z. Wang, and B. Li. Validating climate models with spherical convolutional Wasserstein distance.Advances in Neural Information Processing Systems, 37:59119–59149, 2024. (Cited on page 6.)
2024
-
[31]
Genevay, L
A. Genevay, L. Chizat, F. Bach, M. Cuturi, and G. Peyré. Sample complexity of sinkhorn divergences. InThe 22nd international conference on artificial intelligence and statistics, pages 1574–1583. PMLR, 2019. (Cited on page 2.)
2019
-
[32]
Genevay, M
A. Genevay, M. Cuturi, G. Peyré, and F. Bach. Stochastic optimization for large-scale optimal transport.Advances in neural information processing systems, 29, 2016. (Cited on page 2.)
2016
-
[33]
Genevay, G
A. Genevay, G. Peyré, and M. Cuturi. Learning generative models with Sinkhorn divergences. InInternational Conference on Artificial Intelligence and Statistics, pages 1608–1617. PMLR,
-
[34]
(Cited on pages 1 and 2.)
-
[35]
Haviv, R
D. Haviv, R. Z. Kunes, T. Dougherty, C. Burdziak, T. Nawy, A. Gilbert, and D. Pe’er. Wasserstein wormhole: Scalable optimal transport distance with Transformer. InForty-first International Conference on Machine Learning, 2024. (Cited on page 2.)
2024
- [36]
-
[37]
Jiang, A
R. Jiang, A. Pacchiano, T. Stepleton, H. Jiang, and S. Chiappa. Wasserstein fair classification. InUncertainty in Artificial Intelligence, pages 862–872. PMLR, 2020. (Cited on page 1.)
2020
-
[38]
Kolouri, N
S. Kolouri, N. Naderializadeh, G. K. Rohde, and H. Hoffmann. Wasserstein embedding for graph learning. InInternational Conference on Learning Representations, 2021. (Cited on page 2.)
2021
-
[39]
Kolouri, S
S. Kolouri, S. R. Park, M. Thorpe, D. Slepcev, and G. K. Rohde. Optimal mass transport: Signal processing and machine-learning applications.IEEE signal processing magazine, 34(4):43–59,
-
[40]
Lipman, R
Y. Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. (Cited on page 1.)
2023
-
[41]
X. Liu, E. Akbari, R. Diaz Martin, N. NaderiAlizadeh, and S. Kolouri. Efficient transferable optimal transport via min-sliced transport plans.arXiv e-prints, pages arXiv–2511, 2025. (Cited on pages 8, 9, 10, 11, and 14.) 23
2025
-
[42]
X. Liu, R. D. Martin, Y. Bai, A. Shahbazi, M. Thorpe, A. Aldroubi, and S. Kolouri. Expected sliced transport plans. InThe Thirteenth International Conference on Learning Representations,
-
[43]
Mahey, L
G. Mahey, L. Chapel, G. Gasso, C. Bonet, and N. Courty. Fast optimal transport through sliced Wasserstein generalized geodesics. InProceedings of the 37th International Conference on Neural Information Processing Systems, pages 35350–35385, 2023. (Cited on pages 6, 8, 9, 10, and 11.)
2023
-
[44]
Makkuva, A
A. Makkuva, A. Taghvaei, S. Oh, and J. Lee. Optimal transport mapping via input convex neural networks. InInternational Conference on Machine Learning, pages 6672–6681. PMLR,
-
[45]
Manole, S
T. Manole, S. Balakrishnan, J. Niles-Weed, and L. Wasserman. Plugin estimation of smooth optimal transport maps.The Annals of Statistics, 52(3):966–998, 2024. (Cited on page 2.)
2024
-
[46]
Moosmüller and A
C. Moosmüller and A. Cloninger. Linear optimal transport embedding: provable Wasserstein classification for certain rigid transformations and perturbations.Information and Inference: A Journal of the IMA, 12(1):363–389, 2023. (Cited on page 2.)
2023
-
[47]
K. Nguyen. An introduction to sliced optimal transport: foundations, advances, extensions, and applications.Foundations and Trends®in Computer Graphics and Vision, 17(3-4):171–391,
-
[48]
(Cited on pages 2 and 6.)
-
[49]
Nguyen, N
K. Nguyen, N. Bariletto, and N. Ho. Quasi-Monte Carlo for 3d sliced Wasserstein. InThe Twelfth International Conference on Learning Representations, 2024. (Cited on page 6.)
2024
-
[50]
Nguyen and P
K. Nguyen and P. Mueller. Summarizing nonparametric Bayesian mixture posteriors–sliced optimal transport metrics for Gaussian mixtures.Journal of Computational and Graphical Statistics, (just-accepted):1–22, 2026. (Cited on page 6.)
2026
-
[51]
Nguyen, D
K. Nguyen, D. Nguyen, T. Pham, and N. Ho. Improving mini-batch optimal transport via partial transportation. InProceedings of the 39th International Conference on Machine Learning,
-
[52]
Nguyen, H
K. Nguyen, H. Nguyen, and N. Ho. Fast estimation of Wasserstein distances via regression on sliced Wasserstein distances. InThe Fourteenth International Conference on Learning Representations, 2026. (Cited on page 2.)
2026
-
[53]
J. B. Orlin. A polynomial time primal network simplex algorithm for minimum cost flows. Mathematical Programming, 78(2):109–129, 1997. (Cited on page 1.)
1997
-
[54]
Patrini, R
G. Patrini, R. van den Berg, P. Forre, M. Carioni, S. Bhargav, M. Welling, T. Genewein, and F. Nielsen. Sinkhorn autoencoders. InUncertainty in Artificial Intelligence, pages 733–743. PMLR, 2020. (Cited on page 1.)
2020
-
[55]
Peyré, M
G. Peyré, M. Cuturi, et al. Computational optimal transport: With applications to data science. Foundations and Trends®in Machine Learning, 11(5-6):355–607, 2019. (Cited on pages 1 and 4.) 24
2019
-
[56]
Pooladian, H
A.-A. Pooladian, H. Ben-Hamu, C. Domingo-Enrich, B. Amos, Y. Lipman, and R. T. Chen. Multisample flow matching: Straightening flows with minibatch couplings. InInternational Conference on Machine Learning, pages 28100–28127. PMLR, 2023. (Cited on page 1.)
2023
-
[57]
Quellmalz, R
M. Quellmalz, R. Beinert, and G. Steidl. Sliced optimal transport on the sphere.Inverse Problems, 39(10):105005, 2023. (Cited on page 6.)
2023
-
[58]
Rabin, G
J. Rabin, G. Peyré, J. Delon, and M. Bernot. Wasserstein barycenter and its application to texture mixing. InScale Space and Variational Methods in Computer Vision: Third International Conference, SSVM 2011, Ein-Gedi, Israel, May 29–June 2, 2011, Revised Selected Papers 3, pages 435–446. Springer, One New York Plaza, Suite 4600, New York, NY 10004-1562, 2...
2011
-
[59]
Rigollet and A
P. Rigollet and A. J. Stromme. On the sample complexity of entropic optimal transport.The Annals of Statistics, 53(1):61–90, 2025. (Cited on page 2.)
2025
-
[60]
Rubner, C
Y. Rubner, C. Tomasi, and L. J. Guibas. A metric for distributions with applications to image databases. InSixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), pages 59–66. IEEE, 1998. (Cited on page 2.)
1998
-
[61]
Santambrogio
F. Santambrogio. Optimal transport for applied mathematicians.Birkäuser, NY, 55(58-63):94,
-
[62]
Scetbon and M
M. Scetbon and M. Cuturi. Low-rank optimal transport: Approximation, statistics and debiasing. Advances in Neural Information Processing Systems, 35:6802–6814, 2022. (Cited on page 1.)
2022
-
[63]
Scetbon, M
M. Scetbon, M. Cuturi, and G. Peyré. Low-rank Sinkhorn factorization. InInternational Conference on Machine Learning, pages 9344–9354. PMLR, 2021. (Cited on page 1.)
2021
-
[64]
Schiebinger, J
G. Schiebinger, J. Shu, M. Tabaka, B. Cleary, V. Subramanian, A. Solomon, J. Gould, S. Liu, S. Lin, P. Berube, et al. Optimal-transport analysis of single-cell gene expression identifies developmental trajectories in reprogramming.Cell, 176(4):928–943, 2019. (Cited on page 1.)
2019
-
[65]
Séjourné, F.-X
T. Séjourné, F.-X. Vialard, and G. Peyré. Faster unbalanced optimal transport: Translation invariant sinkhorn and 1-d frank-wolfe. InInternational Conference on Artificial Intelligence and Statistics, pages 4995–5021. PMLR, 2022. (Cited on page 6.)
2022
-
[66]
R. Shu. Amortized optimizationhttp://ruishu.io/2017/11/07/amortized-optimization/,
2017
-
[67]
Sinkhorn and P
R. Sinkhorn and P. Knopp. Concerning nonnegative matrices and doubly stochastic matrices. Pacific Journal of Mathematics, 21(2):343–348, 1967. (Cited on page 2.)
1967
-
[68]
Solomon, F
J. Solomon, F. De Goes, G. Peyré, M. Cuturi, A. Butscher, A. Nguyen, T. Du, and L. Guibas. Convolutional Wasserstein distances: Efficient optimal transportation on geometric domains. ACM Transactions on Graphics (ToG), 34(4):1–11, 2015. (Cited on page 1.)
2015
-
[69]
Solomon, G
J. Solomon, G. Peyré, V. G. Kim, and S. Sra. Entropic metric alignment for correspondence problems.ACM Transactions on Graphics (TOG), 35(4):72, 2016. (Cited on page 1.) 25
2016
-
[70]
Sommerfeld, J
M. Sommerfeld, J. Schrieber, Y. Zemel, and A. Munk. Optimal transport: Fast probabilistic approximation with exact solvers.Journal of Machine Learning Research, 20:105–1, 2019. (Cited on page 1.)
2019
-
[71]
arXiv preprint arXiv:2508.01243 , year=
E. Tanguy, L. Chapel, and J. Delon. Sliced optimal transport plans.arXiv preprint arXiv:2508.01243, 2025. (Cited on page 6.)
-
[72]
Tolstikhin, O
I. Tolstikhin, O. Bousquet, S. Gelly, and B. Schoelkopf. Wasserstein auto-encoders. In International Conference on Learning Representations, 2018. (Cited on page 1.)
2018
-
[73]
A. Tong, K. FATRAS, N. Malkin, G. Huguet, Y. Zhang, J. Rector-Brooks, G. Wolf, and Y. Bengio. Improving and generalizing flow-based generative models with minibatch optimal transport.Transactions on Machine Learning Research, 2024. Expert Certification. (Cited on pages 1, 9, 11, 12, and 13.)
2024
-
[74]
H. Tran, Y. Bai, A. Kothapalli, A. Shahbazi, X. Liu, R. D. Martin, and S. Kolouri. Stereographic spherical sliced Wasserstein distances.International Conference on Machine Learning, 2024. (Cited on pages 6 and 9.)
2024
-
[75]
Villani.Topics in optimal transportation
C. Villani.Topics in optimal transportation. Number 58. American Mathematical Soc., 2003. (Cited on page 1.)
2003
-
[76]
Villani.Optimal transport: old and new, volume 338
C. Villani.Optimal transport: old and new, volume 338. Springer, One New York Plaza, Suite 4600, New York, NY 10004-1562, 2009. (Cited on pages 1 and 3.)
2009
-
[77]
F. Wu, N. Courty, S. Jin, and S. Z. Li. Improving molecular representation learning with metric learning-enhanced optimal transport.Patterns, 4(4), 2023. (Cited on page 1.)
2023
-
[78]
J. Zhu, A. Guha, D. Do, M. Xu, X. Nguyen, and D. Zhao. Functional optimal transport: regularized map estimation and domain adaptation for functional data.Journal of Machine Learning Research, 25(276):1–49, 2024. (Cited on page 1.) 26
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.