Recognition: 1 theorem link
· Lean TheoremSame Image, Different Meanings: Toward Retrieval of Context-Dependent Meanings
Pith reviewed 2026-05-14 18:48 UTC · model grok-4.3
The pith
Images acquire different meanings based on narrative context, with abstract elements shifting more than concrete ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
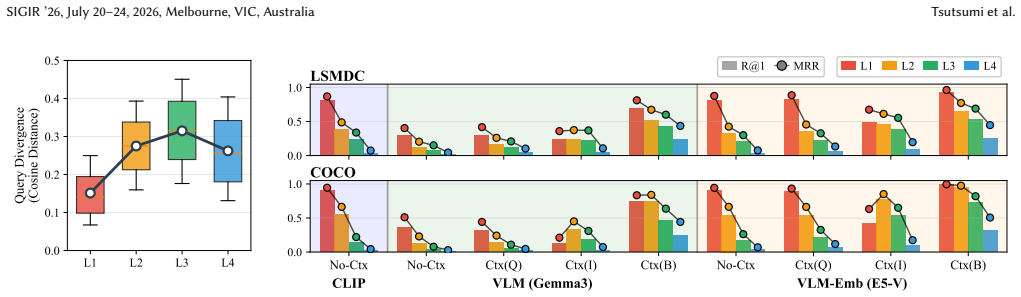
A scene of two people in the rain can convey hope in a reunion story or sorrow in a farewell story. Context dependency correlates with semantic abstraction, formalized in the L1-L4 framework that ranges from stable concrete elements at L1 to maximally variable abstract elements at L4. Synthetic story contexts and queries demonstrate that adding narrative context to image embeddings improves retrieval performance for abstract queries more than concrete ones, with image-side enrichment proving especially effective, although the most abstract level remains challenging even with full context.
What carries the argument
The L1--L4 framework, which organizes image semantics from context-independent concrete elements at L1 to maximally context-dependent abstract elements at L4.
If this is right
- Concrete queries retrieve reliably without added context.
- Abstract queries increasingly require narrative context for accurate results.
- Enriching image embeddings with context outperforms enriching queries alone.
- The highest abstraction level remains an open retrieval challenge even with complete context.
Where Pith is reading between the lines
- Systems could detect abstraction level first and apply context enrichment only where needed.
- The framework may extend to other media such as video or text where meaning shifts with surrounding narrative.
- Real datasets from social media or books could test whether synthetic patterns hold outside controlled stories.
Load-bearing premise
Synthetic story contexts and queries provide a controlled and representative evaluation of real-world context-dependent image retrieval performance.
What would settle it
Measuring whether retrieval accuracy for abstract image meanings in a live system drops when replacing synthetic narrative contexts with actual user-provided stories.
Figures




read the original abstract
A scene of two people in the rain can convey hope and warmth in a reunion story or sorrow and finality in a farewell story. We investigate this context-dependent nature of image meaning and its implications for retrieval. Our key observation is that context dependency correlates with semantic abstraction: concrete elements (objects, actions) remain stable across contexts, while abstract elements (atmosphere, intent) shift with context. We operationalize this as the L1--L4 framework, organizing image semantics from context-independent (L1) to maximally context-dependent (L4). Using synthetic story contexts and queries for controlled evaluation, we examine how injecting narrative context into embeddings affects retrieval across abstraction levels. Concrete queries are retrievable without context, while abstract levels increasingly depend on narrative grounding. Where context is injected also matters, with image-side enrichment proving particularly effective. The most abstract level, however, remains challenging even with full context, highlighting context-dependent image retrieval as an important open problem. Our framework and findings lay groundwork toward retrieval systems that handle the context-dependent meanings images acquire in narrative settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that image meaning is context-dependent in a manner that correlates with semantic abstraction, formalized via the L1--L4 framework (L1: context-independent concrete elements such as objects and actions; L4: maximally context-dependent abstract elements such as atmosphere and intent). Using synthetically generated story contexts and queries, it shows that concrete queries can be retrieved without context while abstract levels increasingly require narrative grounding, that image-side context enrichment is particularly effective, and that even full context leaves L4 retrieval challenging.
Significance. If the correlation between abstraction level and context dependence holds beyond the synthetic construction, the L1--L4 framework could supply a useful organizing principle for designing context-aware retrieval systems and for diagnosing where current embeddings fail on narrative-dependent queries. The controlled synthetic setup is a strength for isolating the effect, but the absence of external validation limits immediate applicability.
major comments (2)
- [Abstract and Evaluation] The central empirical claim—that context dependency correlates with semantic abstraction—is supported only by results on synthetically generated story contexts and queries. Because the L1--L4 levels are themselves defined by increasing context dependence, the data-generation process risks artifactually producing the reported stability of concrete elements and variability of abstract elements; no external validation against real multi-context image annotations is described.
- [Abstract] The abstract states that image-side enrichment is particularly effective and that L4 remains challenging, yet reports no quantitative metrics, baselines, error bars, or statistical tests. Without these details it is impossible to judge the magnitude, robustness, or statistical significance of the claimed effects across levels.
minor comments (1)
- [Abstract] The abstract refers to 'synthetic story contexts' without indicating the generation procedure, the distribution of contexts, or any safeguards against the circularity risk noted above.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The central empirical claim—that context dependency correlates with semantic abstraction—is supported only by results on synthetically generated story contexts and queries. Because the L1--L4 levels are themselves defined by increasing context dependence, the data-generation process risks artifactually producing the reported stability of concrete elements and variability of abstract elements; no external validation against real multi-context image annotations is described.
Authors: We acknowledge that the evaluation is conducted exclusively on synthetically generated story contexts and queries, chosen specifically to enable controlled measurement of how retrieval performance varies with context provision while holding the image fixed. The L1--L4 levels are defined by semantic abstraction (concrete objects/actions at L1 to abstract atmosphere/intent at L4), and the experiments test the resulting hypothesis that higher levels exhibit greater context dependence in retrieval. While this controlled setup isolates the effect and reveals consistent patterns, we agree it carries the risk of circularity and does not constitute external validation on real multi-context annotations. We will add an explicit limitations subsection discussing this issue, the rationale for the synthetic design, and concrete directions for future validation on real narrative image datasets. revision: partial
-
Referee: [Abstract] The abstract states that image-side enrichment is particularly effective and that L4 remains challenging, yet reports no quantitative metrics, baselines, error bars, or statistical tests. Without these details it is impossible to judge the magnitude, robustness, or statistical significance of the claimed effects across levels.
Authors: The full manuscript reports quantitative retrieval metrics (recall@K), baseline comparisons (no-context vs. context-enriched embeddings), error bars across multiple runs, and statistical comparisons in the experimental section. The abstract provides a high-level summary due to space constraints. We will revise the abstract to incorporate key quantitative highlights—such as the magnitude of improvement from image-side enrichment and the remaining performance gap at L4—while remaining within length limits. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper states a key observation that context dependency correlates with semantic abstraction, then operationalizes it as the L1-L4 framework organizing semantics from context-independent (L1) to maximally context-dependent (L4). Evaluation proceeds via synthetic story contexts and queries, with results showing concrete levels retrievable without context and abstract levels depending more on narrative grounding. No equations, fitted parameters, or predictions are described that reduce by construction to the inputs or framework definition itself. The framework is presented as an organization of the stated observation rather than a self-referential loop, and no load-bearing self-citations or uniqueness theorems are invoked. The setup is self-contained as an empirical study on controlled synthetic data without the specific reductions required for circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic abstraction level can be reliably mapped to context dependence degree
invented entities (1)
-
L1-L4 framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclearL1–L4 framework, organizing image semantics from context-independent (L1) to maximally context-dependent (L4)
Reference graph
Works this paper leans on
-
[1]
Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. 2023. Zero-Shot Composed Image Retrieval with Textual Inversion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 15292–15301. doi:10.1109/ICCV51070.2023.01407
-
[2]
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. 2024. LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders. InProceedings of the Conference on Language Modeling (COLM)
work page 2024
-
[3]
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. 2024. InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 24185–24198
work page 2024
-
[4]
Ting-Hao Kenneth Huang, Francis Ferraro, Nasrin Mostafazadeh, Ishan Misra, Aishwarya Agrawal, Jacob Devlin, Ross Girshick, Xiaodong He, Pushmeet Kohli, Dhruv Batra, et al. 2016. Visual Storytelling. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). ...
work page 2016
-
[5]
Ting Jiang, Minghui Song, Zihan Zhang, Haizhen Huang, Weiwei Deng, Feng Sun, Qi Zhang, Deqing Wang, and Fuzhen Zhuang. 2024. E5-V: Universal Embeddings with Multimodal Large Language Models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page 2024
-
[6]
Ziyan Jiang, Rui Meng, Xinyi Yang, Semih Yavuz, Yingbo Zhou, and Wenhu Chen
-
[7]
InProceedings of the International Conference on Learning Representations (ICLR)
VLM2Vec: Training Vision-Language Models for Massive Multimodal Embedding Tasks. InProceedings of the International Conference on Learning Representations (ICLR)
-
[8]
Benno Krojer, Vaibhav Adlakha, Vibhav Vineet, Yash Goyal, Edoardo Ponti, and Siva Reddy. 2022. Image Retrieval from Contextual Descriptions. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, Dublin, Ireland, 3426–
work page 2022
-
[9]
doi:10.18653/v1/2022.acl-long.241
-
[10]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. BLIP: Bootstrap- ping Language-Image Pre-training for Unified Vision-Language Understanding and Generation. InProceedings of the 39th International Conference on Machine Learning (ICML). 12888–12900
work page 2022
-
[11]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. InProceedings of the European Conference on Computer Vision (ECCV). 740–755
work page 2014
-
[12]
Giulia Martinez Pandiani and Valentina Presutti. 2023. Seeing the Intangible: A Survey on Image Classification into High-Level and Abstract Categories.arXiv preprint arXiv:2308.10562(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Jae Sung Park, Chandra Bhagavatula, Roozbeh Mottaghi, Ali Farhadi, and Yejin Choi. 2020. VisualCOMET: Reasoning about the Dynamic Context of a Still Image. InProceedings of the European Conference on Computer Vision (ECCV). 508–524
work page 2020
-
[14]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sand- hini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
-
[15]
InProceedings of the 38th International Conference on Machine Learning (ICML)
Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning (ICML). 8748–8763
-
[16]
Anna Rohrbach, Marcus Rohrbach, Niket Tanber, and Bernt Schiele. 2015. A Dataset for Movie Description. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3202–3212
work page 2015
-
[17]
Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. 2023. Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 19305–19314
work page 2023
-
[18]
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. 2023. EVA-CLIP: Improved Training Techniques for CLIP at Scale.arXiv preprint arXiv:2303.15389 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, et al. 2025. Gemma 3 Technical Report. arXiv:2503.19786 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. 2022. Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5238–5248
work page 2022
-
[21]
Jin Tian, Shawn Li, Xinrui Chen, Mengting Zhang, and William Yang Wang. 2025. From Script to Storyboard: A Task-Specific Multimodal Retrieval Approach for Narrative Image Sequences.Computational Visual Media11, 1 (2025), 103–122. doi:10.26599/CVM.2025.9450322
-
[22]
Lucas Ventura, Antoine Yang, Cordelia Schmid, and Gül Varol. 2024. Learning Composed Video Retrieval from Web Video Captions.Proceedings of the AAAI Conference on Artificial Intelligence38 (Mar. 2024), 5270–5279. doi:10.1609/aaai. v38i6.28334
-
[23]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen. 2024. UniIR: Training and Benchmarking Universal Multimodal Information Retrievers. InProceedings of the European Conference on Computer Vision (ECCV)
work page 2024
-
[25]
Jheng-Hong Yang, Carlos Lassance, Rafael Sampaio de Rezende, Krishna Srini- vasan, Miriam Redi, Stéphane Clinchant, and Jimmy Lin. 2023. AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2975–2984
work page 2023
-
[26]
Mark Yatskar, Luke Zettlemoyer, and Ali Farhadi. 2016. Situation Recognition: Visual Semantic Role Labeling for Image Understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 5534– 5542
work page 2016
-
[27]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. 2023. When and Why Vision-Language Models Behave like Bags-of-Words, and What to Do About It?. InProceedings of the International Conference on Learning Representations (ICLR)
work page 2023
-
[28]
Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. From Recognition to Cognition: Visual Commonsense Reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 6720–6731
work page 2019
-
[29]
Kai Zhang, Yi Luan, Hexiang Hu, Kenton Lee, Siyuan Qiao, Wenhu Chen, Yu Su, and Ming-Wei Chang. 2024. MagicLens: Self-Supervised Image Retrieval with Open-Ended Instructions. InProceedings of the 41st International Conference on Machine Learning (ICML). 59403–59420
work page 2024
-
[30]
Sicheng Zhao, Xingxu Yao, Jufeng Yang, Guoli Jia, Guiguang Ding, Tat-Seng Chua, Björn W. Schuller, and Kurt Keutzer. 2022. Affective Image Content Analysis: Two Decades Review and New Perspectives.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 10 (2022), 6729–6751
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.