Recognition: unknown
Data Difficulty and the Generalization--Extrapolation Tradeoff in LLM Fine-Tuning
Pith reviewed 2026-05-14 19:56 UTC · model grok-4.3
The pith
For any fixed data budget in LLM fine-tuning, an optimal difficulty level exists and moves toward harder examples as the budget grows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
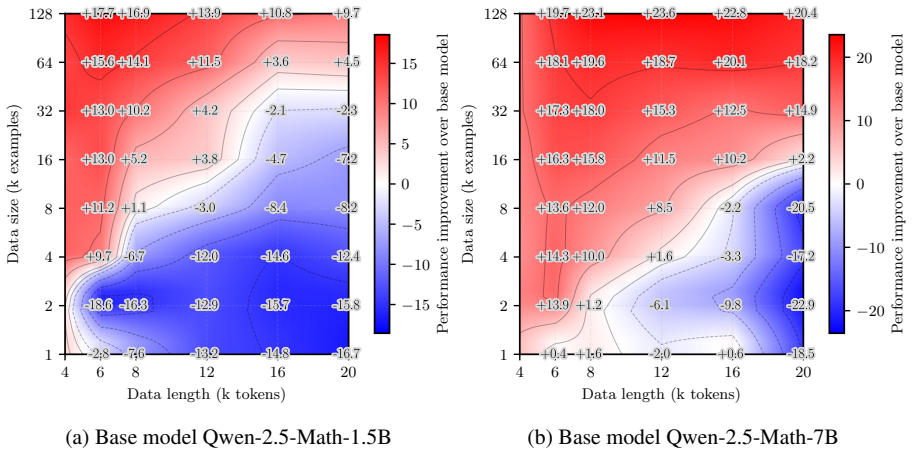
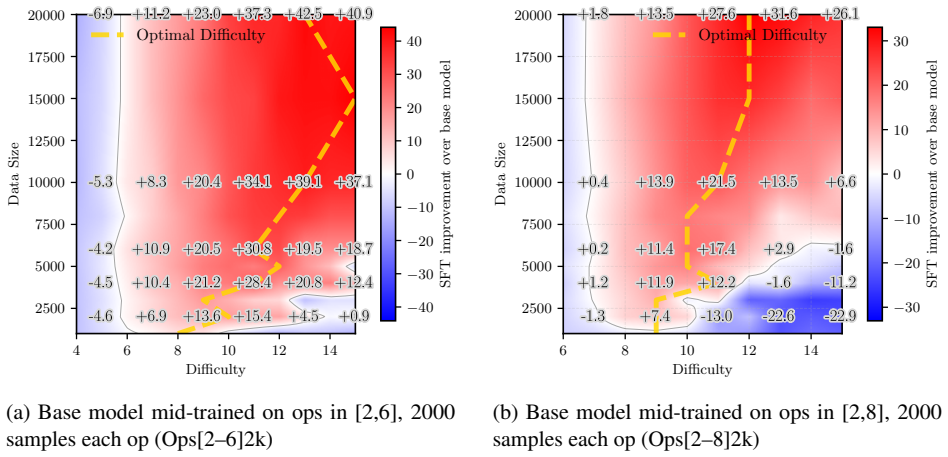
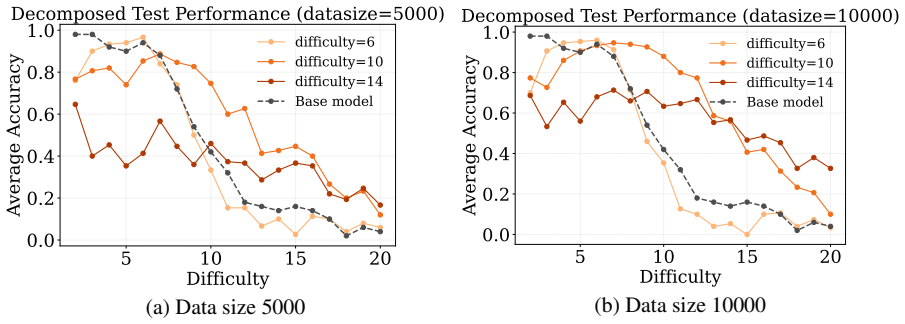
Data difficulty and dataset size interact through a generalization-extrapolation tradeoff. For small budgets, easier examples minimize the in-distribution generalization gap and raise performance. Larger budgets favor harder examples because they shrink the extrapolation gap to unseen cases. The location of the optimum is predicted by PAC-Bayesian bounds that depend on model capacity and data volume.
What carries the argument
The interplay between the in-distribution generalization gap and the extrapolation gap, formalized through PAC-Bayesian bounds.
If this is right
- For small fine-tuning sets, selecting easier data reduces the generalization gap and improves accuracy.
- Once the data budget exceeds a threshold, selecting harder data improves extrapolation to out-of-distribution cases.
- PAC-Bayesian bounds can be used to estimate the optimal difficulty level for given model size and data volume.
- Difficulty-based data selection must be adjusted according to total budget rather than applied with a fixed threshold.
Where Pith is reading between the lines
- Curators of SFT datasets may need to measure difficulty distributions at different scales to locate the operating point.
- The same tradeoff could inform data mixing strategies when difficulty is combined with other filters such as length or quality.
- The mechanism suggests a way to decide when to add harder synthetic or augmented examples during scaling of fine-tuning runs.
Load-bearing premise
The controlled synthetic experiments and PAC-Bayesian analysis capture the dominant mechanism in real LLM fine-tuning on natural language data.
What would settle it
An experiment on real LLMs in which optimal difficulty does not shift toward harder data as the fine-tuning budget increases, or in which measured generalization and extrapolation gaps fail to track the observed performance changes, would falsify the account.
Figures







read the original abstract
Data selection during supervised fine-tuning (SFT) can critically change the behavior of large language models (LLMs). Although existing work has studied the effect of selecting data based on heuristics such as perplexity, difficulty, or length, the reported findings are often inconsistent or context-dependent. In this work, we systematically study the role of data difficulty in fine-tuning from both empirical and theoretical perspectives, and find that there is no universally optimal difficulty level; rather, its effectiveness depends on the dataset size. We show that for a fixed data budget, there exists an optimal data difficulty for SFT, and that this optimal difficulty shifts toward harder data as the data budget increases. To explain this phenomenon, we conduct controlled synthetic experiments that reveal a simple underlying mechanism: the interplay between the (in-distribution) generalization gap and the extrapolation gap. We further support this mechanism through a theoretical analysis using PAC-Bayesian generalization bounds. Overall, our results clarify how data size and difficulty jointly affect the trade-off between generalization and extrapolation in SFT, providing guidance for difficulty-based data selection under certain model and data conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that there is no universally optimal data difficulty for supervised fine-tuning (SFT) of LLMs. For a fixed data budget, an optimal difficulty exists and shifts toward harder data as the budget increases. This is demonstrated empirically, explained mechanistically via controlled synthetic experiments that isolate the interplay between the in-distribution generalization gap and the extrapolation gap, and supported by PAC-Bayesian generalization bounds.
Significance. If the results hold, the work clarifies how data size and difficulty jointly determine the generalization-extrapolation tradeoff in SFT, offering concrete guidance for difficulty-based data selection under the studied model and data conditions. The combination of synthetic experiments and PAC-Bayesian analysis provides a mechanistic account that strengthens the empirical findings and distinguishes this contribution from heuristic-based prior work.
major comments (1)
- [Synthetic experiments] Synthetic experiments section: the difficulty binning threshold is identified as a free parameter; the central claim that an optimal difficulty exists and shifts with budget size would be strengthened by an explicit robustness check showing that the location of the optimum is insensitive to reasonable variations in this threshold.
minor comments (1)
- [Abstract] Abstract: the phrase 'under certain model and data conditions' is appropriately cautious but could be expanded by one sentence to indicate the scope (e.g., synthetic tasks or specific model scales) without lengthening the abstract excessively.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Synthetic experiments] Synthetic experiments section: the difficulty binning threshold is identified as a free parameter; the central claim that an optimal difficulty exists and shifts with budget size would be strengthened by an explicit robustness check showing that the location of the optimum is insensitive to reasonable variations in this threshold.
Authors: We agree that an explicit robustness check would strengthen the central claim. In the revised manuscript we will add a dedicated subsection in the synthetic experiments that varies the binning threshold over a range of reasonable values (e.g., the original threshold together with shifts of ±10 % and ±20 %). For each budget size we will report the location of the optimal difficulty bin and show that it remains stable across these threshold choices, thereby confirming that the observed shift toward harder data is not an artifact of the particular binning parameter. revision: yes
Circularity Check
Minor self-citation risk but central claim remains independent
full rationale
The paper grounds its main result in new controlled synthetic experiments isolating the generalization-extrapolation tradeoff plus standard PAC-Bayesian bounds. No equation or claim reduces by construction to a fitted parameter defined from the target quantity, nor does any load-bearing step rely on a self-citation chain that itself assumes the result. The derivation introduces an explanatory mechanism via fresh experiments rather than renaming known patterns or smuggling an ansatz through prior work. A low-level self-citation risk is noted but does not force the central claim, keeping the overall circularity low.
Axiom & Free-Parameter Ledger
free parameters (1)
- difficulty binning threshold
axioms (2)
- standard math PAC-Bayesian generalization bounds apply to the fine-tuned LLM under the chosen prior and loss
- domain assumption Synthetic task distributions faithfully reproduce the relevant generalization and extrapolation behavior of natural language data
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Anchored Supervised Fine-Tuning , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
On the Generalization of SFT: A Reinforcement Learning Perspective with Reward Rectification , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Proximal Supervised Fine-Tuning , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
Beyond Log Likelihood: Probability-Based Objectives for Supervised Fine-Tuning across the Model Capability Continuum , author=. 2025 , eprint=
2025
-
[5]
Physics of language models: Part 2.1, grade-school math and the hidden reasoning process
Physics of language models: Part 2.1, grade-school math and the hidden reasoning process , author=. arXiv preprint arXiv:2407.20311 , year=
-
[6]
arXiv preprint arXiv:2508.04149 , year=
Difficulty-Based Preference Data Selection by DPO Implicit Reward Gap , author=. arXiv preprint arXiv:2508.04149 , year=
-
[7]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Open R1: A fully open reproduction of DeepSeek-R1 , url =
-
[9]
OpenScienceReasoning-2: A Multi-Domain Synthetic Reasoning Dataset , author =
-
[10]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2025 , journal =
AIMO-2 Winning Solution: Building State-of-the-Art Mathematical Reasoning Models with OpenMathReasoning dataset , author =. 2025 , journal =
2025
-
[12]
arXiv preprint arXiv:2309.04564 , year=
When less is more: Investigating data pruning for pretraining llms at scale , author=. arXiv preprint arXiv:2309.04564 , year=
-
[13]
arXiv preprint arXiv:2410.09335 , year=
Rethinking data selection at scale: Random selection is almost all you need , author=. arXiv preprint arXiv:2410.09335 , year=
-
[14]
arXiv preprint arXiv:2402.04333 , year=
Less: Selecting influential data for targeted instruction tuning , author=. arXiv preprint arXiv:2402.04333 , year=
-
[15]
arXiv preprint arXiv:2402.11192 , year=
I learn better if you speak my language: Understanding the superior performance of fine-tuning large language models with LLM-generated responses , author=. arXiv preprint arXiv:2402.11192 , year=
-
[16]
arXiv preprint arXiv:2207.06814 , year=
Bertin: Efficient pre-training of a spanish language model using perplexity sampling , author=. arXiv preprint arXiv:2207.06814 , year=
-
[17]
arXiv preprint arXiv:2502.03387 , year=
Limo: Less is more for reasoning , author=. arXiv preprint arXiv:2502.03387 , year=
-
[18]
The best instruction-tuning data are those that fit,
The best instruction-tuning data are those that fit , author=. arXiv preprint arXiv:2502.04194 , year=
-
[19]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
s1: Simple test-time scaling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[20]
Proceedings of the 16th International Conference on Internetware , pages=
Adaptivellm: A framework for selecting optimal cost-efficient llm for code-generation based on cot length , author=. Proceedings of the 16th International Conference on Internetware , pages=
-
[21]
arXiv preprint arXiv:2505.03469 , year=
Long-short chain-of-thought mixture supervised fine-tuning eliciting efficient reasoning in large language models , author=. arXiv preprint arXiv:2505.03469 , year=
-
[22]
arXiv preprint arXiv:2509.20758 , year=
SFT Doesn't Always Hurt General Capabilities: Revisiting Domain-Specific Fine-Tuning in LLMs , author=. arXiv preprint arXiv:2509.20758 , year=
-
[23]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models , author=. arXiv preprint arXiv:2403.13372 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
User-friendly Introduction to PAC-Bayes Bounds , volume=
Alquier, Pierre , year=. User-friendly Introduction to PAC-Bayes Bounds , volume=. Foundations and Trends in Machine Learning , publisher=. doi:10.1561/2200000100 , number=
-
[25]
Information and Inference: A Journal of the IMA , volume=
The information complexity of learning tasks, their structure and their distance , author=. Information and Inference: A Journal of the IMA , volume=. 2021 , publisher=
2021
-
[26]
Proceedings of the 37th International Conference on Machine Learning , pages=
Improving generalization by controlling label-noise information in neural network weights , author=. Proceedings of the 37th International Conference on Machine Learning , pages=. 2020 , volume=
2020
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Task2Vec: Task Embedding for Meta-Learning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
arXiv preprint arXiv:2106.07780 , year=
KL Guided Domain Adaptation , author=. arXiv preprint arXiv:2106.07780 , year=
-
[29]
McAllester, David A. , title =. 1998 , isbn =. doi:10.1145/279943.279989 , booktitle =
-
[30]
2004 , eprint=
A Note on the PAC Bayesian Theorem , author=. 2004 , eprint=
2004
-
[31]
Mathematical Association of America , year=
AIME 2024 Competition Mathematical Problems , author=. Mathematical Association of America , year=
2024
-
[32]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[33]
Advances in neural information processing systems , volume=
Solving quantitative reasoning problems with language models , author=. Advances in neural information processing systems , volume=
-
[34]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.