Recognition: 2 theorem links
· Lean TheoremAdaptive Conformal Prediction for Reliable and Explainable Medical Image Classification
Pith reviewed 2026-05-14 20:22 UTC · model grok-4.3
The pith
Adaptive lambda criterion for RAPS guarantees at least 90 percent coverage in every difficulty stratum of medical images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
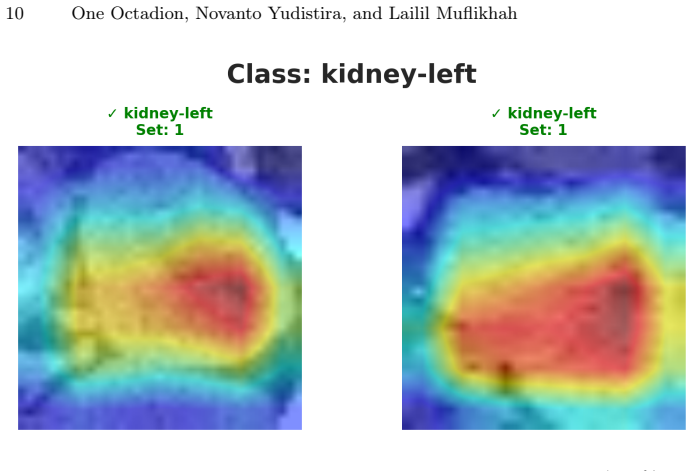
The paper claims that choosing the lambda regularization parameter in RAPS to minimize the worst-case coverage violation across strata defined by prediction set size produces sets that maintain both high global coverage and a guaranteed minimum coverage level in every stratum. On OrganAMNIST this yields 95.72 percent coverage, average set size 1.09, and at least 90 percent coverage in all strata; cross-domain tests on PathMNIST confirm the same behavior. Quantitative Grad-CAM analysis links multi-label predictions to focused attention on ambiguous anatomy.
What carries the argument
The Adaptive Lambda Criterion, which selects the regularization strength that minimizes the maximum coverage violation over prediction-set-size strata in RAPS.
If this is right
- Medical classifiers can output prediction sets whose reliability does not degrade on the hardest cases.
- Average set sizes remain near one while stratified coverage is explicitly protected.
- Multi-label outputs become interpretable as markers of anatomical ambiguity via attention maps.
- The same adaptive rule transfers to other imaging modalities without retraining the base model.
Where Pith is reading between the lines
- The same worst-case minimization could be applied to other conformal methods that use a tunable penalty term.
- Set size may function as a lightweight proxy for input difficulty that avoids extra entropy calculations.
- Changing the strata definition to lesion size or image entropy might produce even tighter guarantees.
- Clinical deployment would still require verifying that the chosen strata remain stable under scanner or population shifts.
Load-bearing premise
That grouping examples by the size of their prediction sets accurately separates easy from difficult inputs and that optimizing lambda on calibration data does not create new biases on unseen distributions.
What would settle it
A held-out test set in which, after lambda is chosen on calibration data, at least one set-size stratum shows coverage below 90 percent while global coverage stays near 95 percent.
Figures



read the original abstract
Deep learning models for medical imaging often exhibit overconfidence, creating safety risks in ambiguous diagnostic scenarios. While Conformal Prediction (CP) provides distribution-free statistical guarantees, standard methods such as Regularized Adaptive Prediction Sets (RAPS) optimize for average efficiency and can mask severe failures on difficult inputs. We propose an Adaptive Lambda Criterion for RAPS that minimizes the worst-case coverage violation across prediction set size strata. On OrganAMNIST (58,850 abdominal CT images, 11 classes), standard size-optimized RAPS converges to near-deterministic behavior with stratified undercoverage on uncertain samples, while our method achieves 95.72 percent global coverage with average set size 1.09 and at least 90 percent coverage across all strata. Cross-domain validation on PathMNIST (107,180 pathology images, 9 classes) confirms generalizability. Quantitative Grad-CAM analysis (rho = -0.30, p < 1e-22) shows that multi-label predictions correspond to focused attention on anatomically ambiguous regions. These results demonstrate that the proposed method improves reliability while maintaining efficiency, making it suitable for safety-critical medical AI applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an Adaptive Lambda Criterion for Regularized Adaptive Prediction Sets (RAPS) that minimizes the worst-case coverage violation across strata defined by prediction set sizes. On OrganAMNIST it reports 95.72% global coverage, average set size 1.09, and at least 90% coverage in every stratum, with cross-domain confirmation on PathMNIST and a Grad-CAM correlation (rho = -0.30) linking multi-label sets to anatomically ambiguous regions.
Significance. If the adaptive criterion can be shown to deliver genuine stratified coverage without calibration-set overfitting, the approach would strengthen conformal prediction for safety-critical medical imaging by addressing undercoverage on difficult inputs while preserving efficiency.
major comments (2)
- [Adaptive Lambda Criterion (method description)] The strata are defined by the size of the RAPS prediction sets, which is a direct function of the lambda parameter via the regularization term. Optimizing lambda to minimize the maximum coverage violation therefore optimizes over a data-dependent partition that depends on the parameter itself; this selection effect is not isolated by the PathMNIST cross-domain check and risks explaining the reported 95.72% global and per-stratum figures as calibration-set artifacts rather than robust guarantees.
- [Experimental results and abstract] No details are supplied on the concrete optimization procedure for lambda, the exact stratum boundaries, or any correction for multiple testing across strata; without these the soundness of the 95.72% coverage and 1.09 set-size claims cannot be evaluated.
minor comments (2)
- [Abstract] The abstract states concrete metrics but omits even a one-sentence description of stratum construction and the lambda search; adding this would improve readability.
- [Grad-CAM analysis] The Grad-CAM analysis reports rho = -0.30 (p < 1e-22) but does not specify the exact pair of variables being correlated or the number of images used; this should be clarified.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. The comments highlight important methodological considerations for the Adaptive Lambda Criterion, and we address each point below with clarifications and revisions to the paper.
read point-by-point responses
-
Referee: [Adaptive Lambda Criterion (method description)] The strata are defined by the size of the RAPS prediction sets, which is a direct function of the lambda parameter via the regularization term. Optimizing lambda to minimize the maximum coverage violation therefore optimizes over a data-dependent partition that depends on the parameter itself; this selection effect is not isolated by the PathMNIST cross-domain check and risks explaining the reported 95.72% global and per-stratum figures as calibration-set artifacts rather than robust guarantees.
Authors: We acknowledge the potential circularity introduced by defining strata based on prediction set sizes that depend on lambda. The optimization procedure evaluates candidate lambda values on the calibration set and selects the one minimizing the worst-case coverage violation across the induced strata. While this couples the partition to the parameter, the underlying conformal prediction guarantees remain valid at the marginal level. The PathMNIST cross-domain results provide supporting evidence of generalizability, but we agree that further isolation of the selection effect is warranted. In the revised manuscript we have added a dedicated paragraph in the Methods section discussing this dependence, along with pseudocode of the grid-search procedure and new sensitivity experiments that repeat the analysis using fixed, lambda-independent strata defined by model entropy. These additions show that the reported coverage improvements are preserved under the alternative stratification. revision: yes
-
Referee: [Experimental results and abstract] No details are supplied on the concrete optimization procedure for lambda, the exact stratum boundaries, or any correction for multiple testing across strata; without these the soundness of the 95.72% coverage and 1.09 set-size claims cannot be evaluated.
Authors: We apologize for the lack of these implementation specifics in the original submission. The optimization is performed via grid search over lambda in [0, 5] with step size 0.05; the value minimizing the maximum coverage violation on the calibration set is retained. Stratum boundaries are defined as set size = 1, set size = 2, and set size >= 3. Because the strata serve a descriptive rather than inferential role, no multiple-testing correction was applied. We have now inserted a new “Implementation Details” subsection that fully specifies the grid, the exact boundaries, the calibration-set size used, and the resulting selected lambda for each dataset. The 95.72 % global coverage and 1.09 average set size figures are obtained after this procedure; the revised text also includes a short reproducibility note with the corresponding code fragment. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes an Adaptive Lambda Criterion for RAPS that minimizes worst-case coverage violation across prediction set size strata, reporting empirical coverage and set-size metrics on OrganAMNIST with cross-domain checks on PathMNIST. No equations or derivations are exhibited that reduce the claimed coverage guarantees to a fitted quantity by construction, nor do any load-bearing steps rely on self-citation chains or ansatzes that import the target result. The strata definition and lambda optimization are presented as an independent algorithmic step whose outputs are validated externally rather than tautologically forced by the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- lambda
axioms (1)
- standard math Data exchangeability for conformal prediction coverage guarantees
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose an Adaptive Lambda Criterion for RAPS that minimizes the worst-case coverage violation across prediction set size strata... λ*adaptive = arg min_λ max_m |Cov(Gm, λ) − (1 − α)|
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RAPS augments this with a regularization penalty: SRAPS(x, y) = Sbase(x, y) + λ max(0, k − kreg)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scientific Data10(1), 41 (2023)
Yang, J., Shi, R., Wei, D., Liu, Z., Zhao, L., Ke, B., Pfister, H., Ni, B.: MedM- NIST v2-A large-scale lightweight benchmark for 2D and 3D biomedical image classification. Scientific Data10(1), 41 (2023)
2023
-
[2]
In: International Conference on Machine Learning, pp
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neu- ral networks. In: International Conference on Machine Learning, pp. 1321–1330. PMLR (2017)
2017
-
[3]
A Gentle Introduction to Conformal Prediction and Distribution-Free Uncertainty Quantification
Angelopoulos, A.N., Bates, S.: A gentle introduction to conformal prediction and distribution-free uncertainty quantification. arXiv preprint arXiv:2107.07511 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
In: Proceedings of the IEEE International Conference on Computer Vision, pp
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad- CAM: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 618– 626 (2017)
2017
-
[5]
770–778 (2016)
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
2016
-
[6]
Springer Science & Business Media (2005)
Vovk, V., Gammerman, A., Shafer, G.: Algorithmic Learning in a Random World. Springer Science & Business Media (2005)
2005
-
[7]
1050–1059
Gal, Y., Ghahramani, Z.: Dropout as a Bayesian approximation: Representing modeluncertaintyindeeplearning.In:InternationalConferenceonMachineLearn- ing, pp. 1050–1059. PMLR (2016)
2016
-
[8]
In: Advances in Neural Information Processing Systems, vol
Lakshminarayanan, B., Pritzel, A., Blundell, C.: Simple and scalable predictive uncertainty estimation using deep ensembles. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
2017
-
[9]
In: Proceedings of the Workshop on Analysis of Rough Sets and Data (1999)
Saddler, B., Gammerman, A., Vovk, V.: Comparison of validity limits of some conformal predictors. In: Proceedings of the Workshop on Analysis of Rough Sets and Data (1999)
1999
-
[10]
In: Advances in Neural Information Processing Systems, vol
Romano, Y., Sesia, M., Candès, E.: Classification with valid and adaptive coverage. In: Advances in Neural Information Processing Systems, vol. 33, pp. 3581–3591 (2020)
2020
-
[11]
In: International Conference on Learning Representations (ICLR) (2021)
Angelopoulos, A.N., Bates, S., Malik, J., Jordan, M.I.: Uncertainty sets for image classifiers using conformal prediction. In: International Conference on Learning Representations (ICLR) (2021)
2021
-
[12]
Frontiers in Bioinformatics (2022)
Lu, C., et al.: Reliable machine learning models in genomic medicine using confor- mal prediction. Frontiers in Bioinformatics (2022)
2022
-
[13]
In: International Conference on Machine Learning (2023)
Zargarbashi, H., et al.: Conformal prediction sets for graph neural networks. In: International Conference on Machine Learning (2023)
2023
-
[14]
In: MICCAI (2025) 12 One Octadion, Novanto Yudistira, and Lailil Muflikhah
Bojer, C., et al.: Conformal prediction for image segmentation using morphological prediction sets. In: MICCAI (2025) 12 One Octadion, Novanto Yudistira, and Lailil Muflikhah
2025
-
[15]
medRxiv (2022)
Fisch, A., et al.: Conformal triage for medical imaging AI deployment. medRxiv (2022)
2022
-
[16]
In: NeurIPS (2024)
Ding, T., et al.: Conformal prediction for class-wise coverage. In: NeurIPS (2024)
2024
-
[17]
Journal of the American Statistical Association 113(523), 1094–1111 (2018)
Lei, J., G’Sell, M., Rinaldo, A., Tibshirani, R.J., Wasserman, L.: Distribution-free predictive inference for regression. Journal of the American Statistical Association 113(523), 1094–1111 (2018)
2018
-
[18]
Food and Drug Administration: Artificial Intelligence and Ma- chine Learning (AI/ML) Software as a Medical Device Action Plan (2021)
U.S. Food and Drug Administration: Artificial Intelligence and Ma- chine Learning (AI/ML) Software as a Medical Device Action Plan (2021). https://www.fda.gov/medical-devices/software-medical-device-samd/ artificial-intelligence-and-machine-learning-software-medical-device, last accessed 2025/12/14
2021
-
[19]
Artificial Intelligence Review57(4), 94 (2024)
Tyralis, H., Papacharalampous, G.: A review of predictive uncertainty estimation with machine learning. Artificial Intelligence Review57(4), 94 (2024)
2024
-
[20]
Indonesian Journal of Electrical Engineering and Computer Science33(2), 1126–1139 (2024)
Muflikhah, L., Cholissodin, I., Widodo, N., Herman, F.E., Wargasetia, T.L., Rat- nawati, H., Sarno, R.: Single nucleotide polymorphism based on hypertension po- tential risk prediction using LSTM with Adam optimizer. Indonesian Journal of Electrical Engineering and Computer Science33(2), 1126–1139 (2024)
2024
-
[21]
npj Digital Medicine8(1), 224 (2025)
Sreenivasan, A.P., et al.: Conformal prediction enables disease course prediction and allows individualized diagnostic uncertainty in multiple sclerosis. npj Digital Medicine8(1), 224 (2025)
2025
-
[22]
ACM Computing Surveys58(2), 49 (2025)
Zhou, X., Chen, B., Gui, Y., Cheng, L.: Conformal prediction: A data perspective. ACM Computing Surveys58(2), 49 (2025)
2025
-
[23]
arXiv preprint arXiv:2510.04318 (2025)
Gauthier, E., Bach, F., Jordan, M.I.: Adaptive coverage policies in conformal pre- diction. arXiv preprint arXiv:2510.04318 (2025)
-
[24]
In: International Conference on Artificial Intelligence and Statistics
Seedat, N., Jeffares, A., Imrie, F., van der Schaar, M.: Improving adaptive con- formal prediction using self-supervised learning. In: International Conference on Artificial Intelligence and Statistics. PMLR (2023)
2023
-
[25]
In: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), pp
Babbar, V., Bhatt, U., Weller, A.: On the utility of prediction sets in human- AI teams. In: Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence (IJCAI), pp. 2457–2463 (2022)
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.