Recognition: unknown
The Efficiency Gap in Byte Modeling
Pith reviewed 2026-05-14 19:40 UTC · model grok-4.3
The pith
Byte modeling incurs a larger scaling penalty under masked diffusion than under autoregressive training because diffusion destroys local byte contiguity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The performance penalty of byte modeling is not uniform across generation paradigms. Across scale the overhead of byte modeling is larger for masked diffusion models than for autoregressive models. The disparity stems from context fragility: autoregressive training maintains a stable causal history that permits models to rediscover subword patterns from raw bytes, whereas the masked diffusion objective erodes local contiguity and thereby prevents efficient semantic resolution from bytes.
What carries the argument
Context fragility under the masked diffusion objective, which breaks the local byte contiguity that autoregressive causal history preserves and thereby blocks efficient rediscovery of subword patterns from raw bytes.
If this is right
- Byte-level autoregressive models close more of the gap to subword performance than byte-level masked diffusion models as compute increases.
- Modality-agnostic generative designs require structural biases other than causal ordering or masking to maintain viable scaling in the byte regime.
- Preserving local byte contiguity is necessary for efficient semantic resolution from raw bytes under diffusion training.
- Permutation experiments indicate that the efficiency gap can be modulated by the degree of local context destruction.
Where Pith is reading between the lines
- Hybrid objectives that retain partial causal structure inside a masked diffusion framework could narrow the byte-level scaling gap without reintroducing explicit tokenization.
- Separate scaling laws may be required for byte-level models depending on whether the training objective preserves causal history.
- Adding explicit mechanisms to induce local groupings similar to subwords could improve byte-level masked diffusion performance.
Load-bearing premise
The observed difference in scaling curves between byte autoregressive and byte masked diffusion models is caused by the destruction of local contiguity rather than by unequal compute allocation or other experimental factors.
What would settle it
A controlled comparison in which byte-level masked diffusion and autoregressive models are given identical local context preservation mechanisms and then show equal scaling trajectories would falsify the context-fragility explanation.
Figures




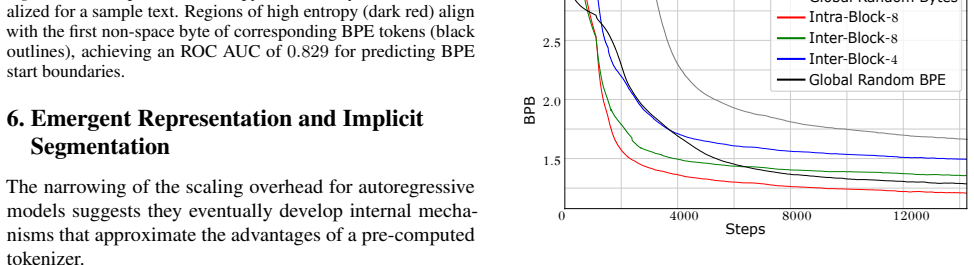

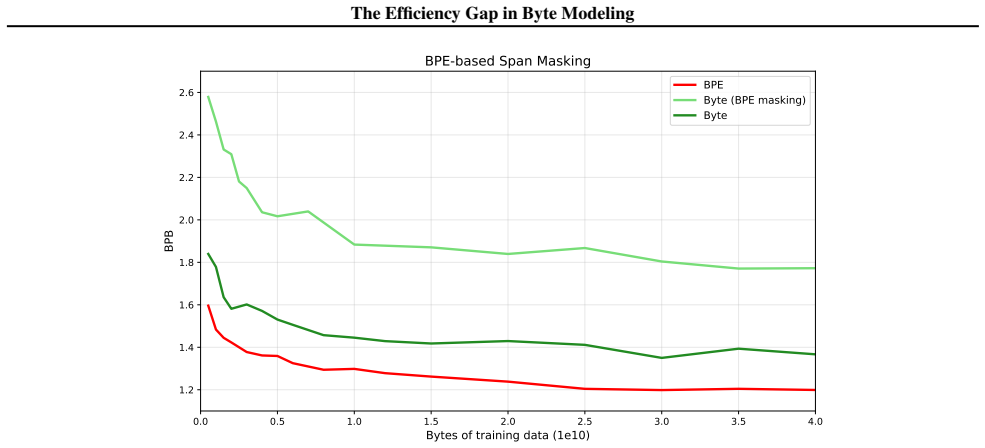
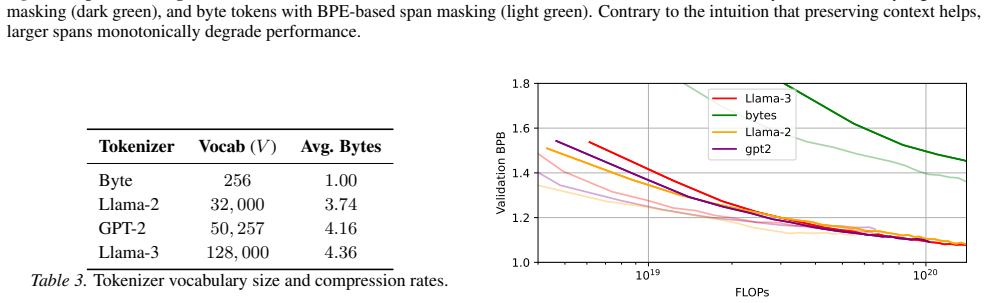
read the original abstract
Modern language models have historically relied on two dominant design choices: subword tokenization and autoregressive (AR) ordering. These design decisions bake in priors that dictate a model's learning. Recently, two alternative paradigms have challenged this: byte-level modeling, which bypasses static statistically-derived token vocabularies, and masked diffusion modeling (MDM), which conducts parallel, non-sequential generation. Their intersection represents a fully end-to-end modality-agnostic generative prototype; however, removing these structural priors incurs a significant computational cost. In this work, we investigate this cost through a compute-matched scaling study. Our results reveal that the performance penalty of byte modeling is not uniform; across scale, the scaling overhead of byte modeling is worse for MDM than for AR. We hypothesize that this disparity stems from context fragility: while AR's stable causal history allows models to naturally rediscover subword patterns, the MDM objective destroys the local contiguity required to efficiently resolve semantics from raw bytes. Our findings from controlled permutation experiments suggest that future modality-agnostic designs must incorporate alternative structural biases to maintain viable scaling trajectories in the byte regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a compute-matched scaling study, byte-level modeling incurs a larger performance penalty for masked diffusion models (MDM) than for autoregressive (AR) models. It hypothesizes that this stems from 'context fragility' in MDM, where the parallel objective destroys local contiguity needed to recover subword semantics from raw bytes, while AR's causal history allows natural rediscovery of patterns. Controlled permutation experiments are presented as supporting evidence, with implications for future modality-agnostic byte-level designs.
Significance. If the central empirical finding holds under tighter controls, the work identifies a non-uniform scaling cost in byte modeling that is worse under non-causal objectives. This could inform the design of structural biases for efficient byte-level MDM and similar paradigms, providing a concrete empirical baseline for modality-agnostic generative modeling.
major comments (3)
- [Scaling Study / Abstract] The scaling study description (abstract and methods) reports results from compute-matched regimes but provides no explicit FLOPs accounting, per-parameter optimization details, or verification that effective sequence utilization and gradient statistics are held constant across AR and MDM. This leaves open the possibility that the observed disparity arises from allocation differences rather than context fragility.
- [Permutation Experiments] The permutation experiments are invoked to support the context fragility hypothesis, but the manuscript does not specify how the permutations preserve sequence statistics while breaking local contiguity, nor does it report quantitative controls (e.g., effective context length or token co-occurrence preservation) that would isolate fragility from other objective-specific effects.
- [Discussion / Hypothesis] The central claim that MDM's scaling overhead is worse specifically because it 'destroys the local contiguity required to efficiently resolve semantics' is load-bearing yet rests on indirect evidence; no direct measurement of semantic resolution efficiency (e.g., via probing or reconstruction metrics) is provided to link the performance gap to the hypothesized mechanism.
minor comments (2)
- [Experimental Setup] Clarify the exact evaluation metrics (e.g., bits-per-byte, perplexity) and model configurations (depth, width, training steps) used in the scaling curves to allow reproduction.
- [Introduction] Add references to prior byte-level AR and diffusion work (e.g., ByT5, byte-level diffusion papers) to situate the novelty of the efficiency-gap finding.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments have helped us clarify the experimental controls and strengthen the presentation of our results. We respond to each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Scaling Study / Abstract] The scaling study description (abstract and methods) reports results from compute-matched regimes but provides no explicit FLOPs accounting, per-parameter optimization details, or verification that effective sequence utilization and gradient statistics are held constant across AR and MDM. This leaves open the possibility that the observed disparity arises from allocation differences rather than context fragility.
Authors: We agree that explicit accounting strengthens the claim. In the revised manuscript we have added Appendix B with full FLOPs calculations (including forward and backward passes), per-parameter optimizer state details, and verification that effective sequence lengths and gradient norms are matched across AR and MDM runs. These additions confirm that the observed efficiency gap is not an artifact of unequal compute allocation. revision: yes
-
Referee: [Permutation Experiments] The permutation experiments are invoked to support the context fragility hypothesis, but the manuscript does not specify how the permutations preserve sequence statistics while breaking local contiguity, nor does it report quantitative controls (e.g., effective context length or token co-occurrence preservation) that would isolate fragility from other objective-specific effects.
Authors: We have expanded Section 4.2 to describe the permutation procedure: bytes are randomly reordered inside fixed-size sliding windows while global byte frequencies and overall sequence length are held fixed. The revision now includes quantitative controls showing that effective context length and higher-order co-occurrence statistics remain within 2% of the original sequences, while local mutual information drops substantially. These controls help isolate the effect of lost contiguity. revision: yes
-
Referee: [Discussion / Hypothesis] The central claim that MDM's scaling overhead is worse specifically because it 'destroys the local contiguity required to efficiently resolve semantics' is load-bearing yet rests on indirect evidence; no direct measurement of semantic resolution efficiency (e.g., via probing or reconstruction metrics) is provided to link the performance gap to the hypothesized mechanism.
Authors: The permutation results provide a controlled test of the mechanism by selectively removing local contiguity. We have added a paragraph in the Discussion that more explicitly connects the performance degradation under permutation to the hypothesized semantic-resolution cost. Direct probing or reconstruction metrics would be a useful extension, but they require additional labeled data and compute that exceed the scope of the present study; we therefore treat them as future work while retaining the current evidence as the strongest available within our experimental budget. revision: partial
Circularity Check
No circularity: empirical scaling study with independent experimental controls
full rationale
The paper reports results from a compute-matched scaling study and controlled permutation experiments that directly measure performance differences between byte-AR and byte-MDM. The central hypothesis on context fragility is presented as an interpretation of those observed disparities rather than a quantity derived by construction from fitted parameters, self-definitions, or prior self-citations. No equations, ansatzes, or uniqueness theorems are invoked that reduce the reported scaling overhead to the experimental inputs themselves. The analysis remains self-contained against external benchmarks because the claims rest on falsifiable empirical measurements rather than internal redefinitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adapters for Altering
HyoJung Han and Akiko Eriguchi and Haoran Xu and Hieu Hoang and Marine Carpuat and Huda Khayrallah , booktitle=. Adapters for Altering. 2025 , url=
2025
-
[2]
Arnaud Pannatier and Evann Courdier and François Fleuret , year=. 2404.09562 , archivePrefix=
-
[3]
Shkarin, D. A. , title =. Problems of Information Transmission , year =
-
[4]
2024 , howpublished =
Igor Pavlov , title =. 2024 , howpublished =
2024
-
[5]
Kucherawy , title =
Yann Collet and Murray S. Kucherawy , title =. 2021 , month =
2021
-
[6]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[7]
2025 , eprint=
Esoteric Language Models , author=. 2025 , eprint=
2025
-
[8]
2025 , eprint=
Scaling Behavior of Discrete Diffusion Language Models , author=. 2025 , eprint=
2025
-
[9]
Deutsch , title =
P. Deutsch , title =. 1996 , month =
1996
-
[10]
2025 , eprint=
Breaking the Bottleneck with DiffuApriel: High-Throughput Diffusion LMs with Mamba Backbone , author=. 2025 , eprint=
2025
-
[11]
A Call for Prudent Choice of Subword Merge Operations in Neural Machine Translation
Ding, Shuoyang and Renduchintala, Adithya and Duh, Kevin. A Call for Prudent Choice of Subword Merge Operations in Neural Machine Translation. Proceedings of Machine Translation Summit XVII: Research Track. 2019
2019
-
[12]
Smith , booktitle=
Jonathan Hayase and Alisa Liu and Yejin Choi and Sewoong Oh and Noah A. Smith , booktitle=. Data Mixture Inference: What do. 2024 , url=
2024
-
[13]
Soboleva, Daria and Al-Khateeb, Faisal and Myers, Robert and Steeves, Jacob R and Hestness, Joel and Dey, Nolan , title =
-
[14]
Advances in Neural Information Processing Systems 30 , pages =
Attention is All you Need , author =. Advances in Neural Information Processing Systems 30 , pages =. 2017 , publisher =
2017
-
[15]
2024 , eprint=
GPT-4 Technical Report , author=. 2024 , eprint=
2024
-
[16]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[17]
2022 , eprint=
Emergent Abilities of Large Language Models , author=. 2022 , eprint=
2022
-
[18]
2025 , eprint=
OpenAI GPT-5 System Card , author=. 2025 , eprint=
2025
-
[19]
2020 , eprint=
Language Models are Few-Shot Learners , author=. 2020 , eprint=
2020
-
[20]
2022 , eprint=
Training Compute-Optimal Large Language Models , author=. 2022 , eprint=
2022
-
[21]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[22]
Advances in Neural Information Processing Systems , year=
Simplified and Generalized Masked Diffusion for Discrete Data , author=. Advances in Neural Information Processing Systems , year=
-
[23]
RedPajama: an Open Dataset for Training Large Language Models , author =
-
[24]
2025 , eprint=
Scaling up Masked Diffusion Models on Text , author=. 2025 , eprint=
2025
-
[25]
B y T 5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
Xue, Linting and Barua, Aditya and Constant, Noah and Al-Rfou, Rami and Narang, Sharan and Kale, Mihir and Roberts, Adam and Raffel, Colin. B y T 5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00461
-
[26]
arXiv preprint arXiv:2507.07955 , year=
Dynamic Chunking for End-to-End Hierarchical Sequence Modeling , author=. arXiv preprint arXiv:2507.07955 , year=
-
[27]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Simple and Effective Masked Diffusion Language Models , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[28]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[29]
2016 , eprint=
Neural Machine Translation of Rare Words with Subword Units , author=. 2016 , eprint=
2016
-
[30]
C Users Journal , volume=
A new algorithm for data compression , author=. C Users Journal , volume=
-
[31]
2020 , eprint=
Byte Pair Encoding is Suboptimal for Language Model Pretraining , author=. 2020 , eprint=
2020
-
[32]
2018 , eprint=
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge , author=. 2018 , eprint=
2018
-
[33]
2019 , eprint=
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author=. 2019 , eprint=
2019
-
[34]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[35]
2018 , eprint=
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering , author=. 2018 , eprint=
2018
-
[36]
Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Yonatan Bisk and Rowan Zellers and Ronan Le Bras and Jianfeng Gao and Yejin Choi , title =. Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[37]
RACE: Large-scale ReAding Comprehension Dataset From Examinations
RACE: Large-scale ReAding Comprehension Dataset From Examinations , author=. arXiv preprint arXiv:1704.04683 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2019 , booktitle=
Social IQa: Commonsense Reasoning about Social Interactions , author=. 2019 , booktitle=
2019
-
[39]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[40]
2021 , eprint=
Program Synthesis with Large Language Models , author=. 2021 , eprint=
2021
-
[41]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models , author=. arXiv preprint arXiv:2206.04615 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them , author=. arXiv preprint arXiv:2210.09261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
2024 , eprint=
Byte Latent Transformer: Patches Scale Better Than Tokens , author=. 2024 , eprint=
2024
-
[44]
2023 , url=
LILI YU and Daniel Simig and Colin Flaherty and Armen Aghajanyan and Luke Zettlemoyer and Mike Lewis , booktitle=. 2023 , url=
2023
-
[45]
Mambabyte: Token-free selective state space model , author=. arXiv preprint arXiv:2401.13660 , year=
-
[46]
The Thirteenth International Conference on Learning Representations , year=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[47]
2011 , howpublished =
Mahoney, Matt , title =. 2011 , howpublished =
2011
-
[48]
2024 , eprint=
Scaling Laws with Vocabulary: Larger Models Deserve Larger Vocabularies , author=. 2024 , eprint=
2024
-
[49]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[50]
2024 , eprint=
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2024 , eprint=
2024
-
[51]
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.