Recognition: no theorem link
Debunking Grad-ECLIP: A Comprehensive Study on Its Incorrectness and Fundamental Principles for Model Interpretation
Pith reviewed 2026-05-14 19:49 UTC · model grok-4.3
The pith
Grad-ECLIP produces model interpretations that do not match the original model's behavior or performance because its method is equivalent to a simpler attention-based route.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the intermediate feature-based technical route represented by Grad-ECLIP is actually an equivalent variant of the attention-based route, as demonstrated by developing Attention-ECLIP which yields identical results with reduced computation. Both formal derivation and experimental validation confirm this equivalence. In addition, the interpretation results from Grad-ECLIP are not those produced by the original model and are misaligned with the model's performance on the task, revealing flaws in the method that violate core requirements for faithful model interpretation.
What carries the argument
The mathematical equivalence between Grad-ECLIP's intermediate feature computations and attention maps in the transformer, which carries the argument that both routes generate the same but incorrect interpretations.
If this is right
- Any interpretation method based on intermediate features can be reduced to attention computations without loss of information.
- Using Grad-ECLIP would lead to explanations that do not reflect the features the model actually uses for its predictions.
- Model interpretation results must be validated against both the original model's outputs and its measured performance on the data.
- New technical routes for interpretation should first be checked for equivalence to existing attention-based methods before being presented as distinct.
- The two stated principles for model interpretation would block similar detachment between the explanation and the model's actual decisions.
Where Pith is reading between the lines
- Attention-based routes may be sufficient for all faithful transformer interpretations, rendering separate intermediate-feature variants unnecessary.
- The same equivalence and misalignment pattern could appear in other feature-attribution methods applied to vision or language transformers.
- New interpretation tools should include routine checks for both equivalence to attention maps and direct alignment with model accuracy before release.
Load-bearing premise
The load-bearing premise is that Attention-ECLIP is exactly equivalent to Grad-ECLIP across all practical cases and that the experiments correctly isolate misalignment without selection bias or implementation differences.
What would settle it
A side-by-side test on a held-out transformer model and dataset where Grad-ECLIP and Attention-ECLIP produce different saliency maps, or where Grad-ECLIP maps align with the model's accuracy while the paper claims they do not.
Figures





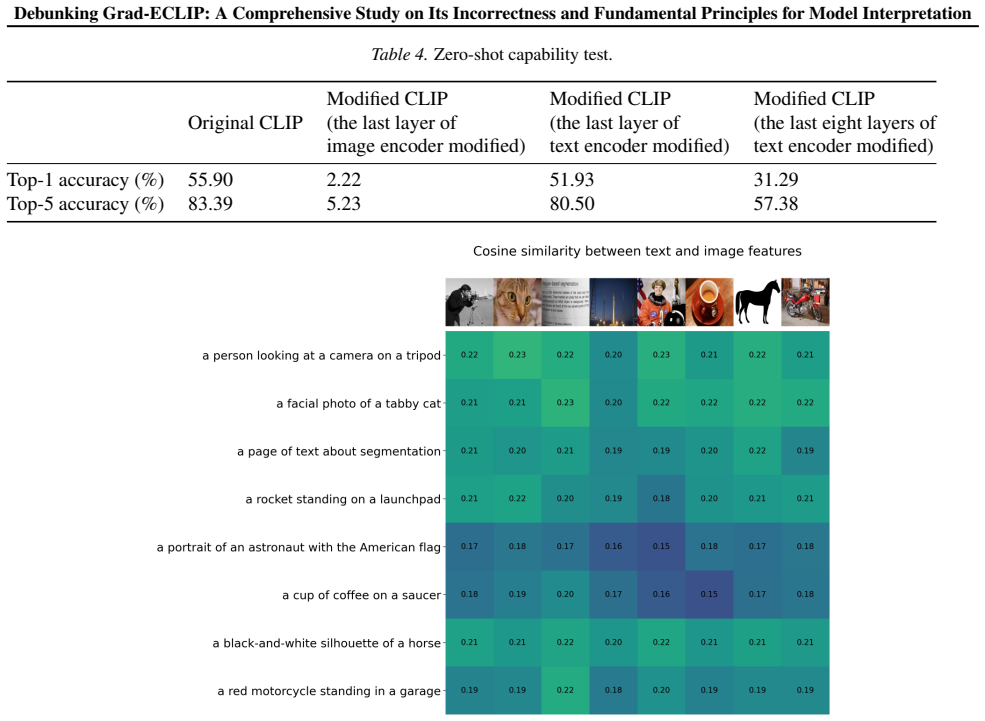
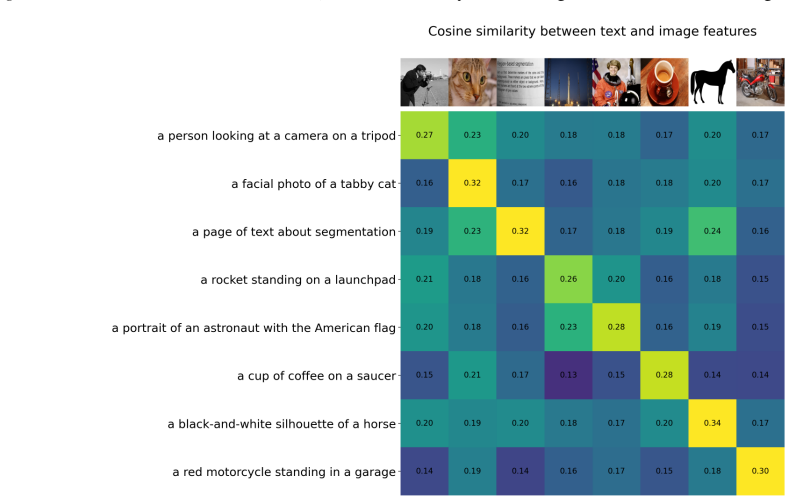


read the original abstract
Grad-ECLIP is published at ICML 2024 and represents a new Transformer interpretation technical route (intermediate features-based). First, this paper demonstrates that the intermediate features-based technical route is not a novel one. Based on the existing attention-based route, we have developed Attention-ECLIP, which is completely equivalent to Grad-ECLIP but with simpler computation. Both through formal derivation and experimental validation, we prove that the intermediate feature-based route represented by Grad-ECLIP is actually an equivalent variant of the attention-based route. Next, this paper demonstrates that the Grad-ECLIP method is flawed. The model interpretation results obtained by Grad-ECLIP are not those of the original model, and the interpretation results are misaligned with the model's performance. We analyze the causes of Grad-ECLIP's flaws and propose, or rather, explicitly emphasize two fundamental principles that model interpretation should adhere to in order to avoid similar errors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Grad-ECLIP, an intermediate feature-based interpretation method for Transformers published at ICML 2024, is formally equivalent to a simpler attention-based method termed Attention-ECLIP developed by the authors from existing attention routes. Both formal derivation and experimental validation are presented to establish this equivalence. The paper further argues that Grad-ECLIP produces interpretations misaligned with the original model's performance and not representative of the model itself, analyzes the causes, and proposes two fundamental principles for model interpretation to avoid such errors.
Significance. If the equivalence is shown to be exact (including bit-identical outputs) and the misalignment experiments cleanly isolate the method from implementation differences, the work would be significant for Transformer interpretability in vision-language models. It would provide a simpler equivalent baseline, highlight risks in intermediate-feature routes, and supply explicit principles that could steer future methods away from similar flaws. The combination of derivation and validation strengthens the contribution relative to purely empirical critiques.
major comments (3)
- [Formal Derivation] Formal Derivation section: the claim of complete equivalence between Grad-ECLIP and Attention-ECLIP requires explicit verification that the two implementations produce bit-identical outputs on identical inputs; without this, differences in gradient routing, normalization order, or head aggregation could confound the subsequent misalignment results and prevent clean attribution to the intermediate-feature route.
- [Experimental Validation] Experimental Validation section: the misalignment experiments must include controls confirming that any performance-interpretation gap is not an artifact of implementation discrepancies between the two routes; reporting only aggregate metrics without per-sample or per-head output identity checks leaves the central claim vulnerable to the concern that observed misalignment stems from code differences rather than a fundamental flaw.
- [Flaw Analysis] Flaw Analysis section: the identification of causes for Grad-ECLIP's misalignment should reference specific equations or components from the original Grad-ECLIP paper (e.g., the intermediate feature computation steps) to demonstrate precisely where the deviation from the original model occurs, rather than relying solely on post-hoc comparison with Attention-ECLIP.
minor comments (2)
- [Abstract] Abstract: the two fundamental principles for model interpretation should be stated explicitly rather than summarized, to allow readers to evaluate their generality immediately.
- [References] References: add citations to prior attention-based interpretation methods to strengthen the claim that Attention-ECLIP is a direct, non-novel extension of existing routes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each of the major comments point by point below, and will make revisions to incorporate the suggestions where they strengthen the presentation of our results.
read point-by-point responses
-
Referee: Formal Derivation section: the claim of complete equivalence between Grad-ECLIP and Attention-ECLIP requires explicit verification that the two implementations produce bit-identical outputs on identical inputs; without this, differences in gradient routing, normalization order, or head aggregation could confound the subsequent misalignment results and prevent clean attribution to the intermediate-feature route.
Authors: We agree that demonstrating bit-identical outputs would provide the strongest possible evidence for equivalence. Our formal derivation shows that the methods are mathematically equivalent, and our current experiments report high numerical agreement (e.g., cosine similarity >0.99). However, to fully address this concern, we will add explicit verification in the revised manuscript, including code snippets or results showing identical outputs at the bit level for the same inputs, controlling for floating-point precision. revision: yes
-
Referee: Experimental Validation section: the misalignment experiments must include controls confirming that any performance-interpretation gap is not an artifact of implementation discrepancies between the two routes; reporting only aggregate metrics without per-sample or per-head output identity checks leaves the central claim vulnerable to the concern that observed misalignment stems from code differences rather than a fundamental flaw.
Authors: We will enhance the Experimental Validation section by adding per-sample and per-head output identity checks between Grad-ECLIP and Attention-ECLIP. This will include reporting metrics such as exact match rates or L2 differences per sample to confirm that any observed misalignment with model performance is attributable to the method itself rather than implementation artifacts. revision: yes
-
Referee: Flaw Analysis section: the identification of causes for Grad-ECLIP's misalignment should reference specific equations or components from the original Grad-ECLIP paper (e.g., the intermediate feature computation steps) to demonstrate precisely where the deviation from the original model occurs, rather than relying solely on post-hoc comparison with Attention-ECLIP.
Authors: We will revise the Flaw Analysis section to include direct references to specific equations and components from the original Grad-ECLIP paper, such as the steps for computing intermediate features and gradients. This will precisely identify where the deviation occurs, complementing our comparison with Attention-ECLIP. revision: yes
Circularity Check
No significant circularity; equivalence derived independently from attention mechanisms
full rationale
The paper constructs Attention-ECLIP explicitly from the existing attention-based route and provides a formal derivation showing equivalence to Grad-ECLIP's intermediate-feature path. No step reduces by construction to a fitted parameter, self-referential definition, or load-bearing self-citation chain. The equivalence claim rests on explicit equations comparing the two routes, and misalignment is shown via separate experiments on model performance. The derivation chain is self-contained against external attention formulations and does not rename known results or smuggle ansatzes via prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Attention mechanisms in Transformers permit equivalent reformulations between feature-based and attention-weight computations
Reference graph
Works this paper leans on
-
[1]
Abnar, S. and Zuidema, W. H. Quantifying attention flow in transformers. In Jurafsky, D., Chai, J., Schluter, N., and Tetreault, J. R. (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, July 5-10, 2020 , pp.\ 4190--4197. Association for Computational Linguistics, 2020. doi:10.18653/V1/2020.AC...
-
[2]
Barkan, O., Elisha, Y., Weill, J., Asher, Y., Eshel, A., and Koenigstein, N. Deep integrated explanations. In Frommholz, I., Hopfgartner, F., Lee, M., Oakes, M., Lalmas, M., Zhang, M., and Santos, R. L. T. (eds.), Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM 2023, Birmingham, United Kingdom, October 21...
-
[3]
Interpretability via Model Extraction
Bastani, O., Kim, C., and Bastani, H. Interpretability via model extraction. CoRR, abs/1706.09773, 2017. URL http://arxiv.org/abs/1706.09773
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Layer-wise relevance propagation for neural networks with local renormalization layers
Binder, A., Montavon, G., Lapuschkin, S., M \" u ller, K., and Samek, W. Layer-wise relevance propagation for neural networks with local renormalization layers. In Villa, A. E. P., Masulli, P., and Rivero, A. J. P. (eds.), Artificial Neural Networks and Machine Learning - ICANN 2016 - 25th International Conference on Artificial Neural Networks, Barcelona,...
-
[5]
Changpinyo, S., Sharma, P., Ding, N., and Soricut, R. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 , pp.\ 3558--3568. Computer Vision Foundation / IEEE , 2021. doi:10.1109/CVPR46437.2021.00356. URL https:...
-
[6]
Editing conditional radiance fields
Chefer, H., Gur, S., and Wolf, L. Generic attention-model explainability for interpreting bi-modal and encoder-decoder transformers. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 , pp.\ 387--396. IEEE , 2021 a . doi:10.1109/ICCV48922.2021.00045. URL https://doi.org/10.1109/ICCV48922.2021.00045
-
[7]
Chefer, H., Gur, S., and Wolf, L. Transformer interpretability beyond attention visualization. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021 , pp.\ 782--791. Computer Vision Foundation / IEEE , 2021 b . doi:10.1109/CVPR46437.2021.00084. URL https://openaccess.thecvf.com/content/CVPR2021/html/Chefer\_Tr...
-
[8]
Beyond intuition: Rethinking token attributions inside transformers
Chen, J., Li, X., Yu, L., Dou, D., and Xiong, H. Beyond intuition: Rethinking token attributions inside transformers. Trans. Mach. Learn. Res., 2023, 2023. URL https://openreview.net/forum?id=rm0zIzlhcX
2023
-
[9]
Developing real-time streaming transformer transducer for speech recognition on large-scale dataset
Chen, X., Wu, Y., Wang, Z., Liu, S., and Li, J. Developing real-time streaming transformer transducer for speech recognition on large-scale dataset. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2021, Toronto, ON, Canada, June 6-11, 2021 , pp.\ 5904--5908. IEEE , 2021. doi:10.1109/ICASSP39728.2021.9413535. URL https:/...
-
[10]
Efficient and effective text encoding for chinese llama and alpaca
Cui, Y., Yang, Z., and Yao, X. Efficient and effective text encoding for chinese llama and alpaca. CoRR, abs/2304.08177, 2023. doi:10.48550/ARXIV.2304.08177. URL https://doi.org/10.48550/arXiv.2304.08177
-
[11]
Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition
Dong, L., Xu, S., and Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2018, Calgary, AB, Canada, April 15-20, 2018 , pp.\ 5884--5888. IEEE , 2018. doi:10.1109/ICASSP.2018.8462506. URL https://doi.org/10.1109/ICASSP.2018.8462506
-
[12]
An image is worth 16x16 words: Transformers for image recognition at scale
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 ...
2021
-
[13]
A., Siebert, X., Cornu, O., and Vleeschouwer, C
Englebert, A., Stassin, S., Nanfack, G., Mahmoudi, S. A., Siebert, X., Cornu, O., and Vleeschouwer, C. D. Explaining through transformer input sampling. In IEEE/CVF International Conference on Computer Vision, ICCV 2023 - Workshops, Paris, France, October 2-6, 2023 , pp.\ 806--815. IEEE , 2023. doi:10.1109/ICCVW60793.2023.00088. URL https://doi.org/10.110...
-
[14]
nuScenes: A multimodal dataset for autonomous driving,
Hu, R., Singh, A., Darrell, T., and Rohrbach, M. Iterative answer prediction with pointer-augmented multimodal transformers for textvqa. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020 , pp.\ 9989--9999. Computer Vision Foundation / IEEE , 2020. doi:10.1109/CVPR42600.2020.01001. URL htt...
-
[15]
Multi-compound transformer for accurate biomedical image segmentation
Ji, Y., Zhang, R., Wang, H., Li, Z., Wu, L., Zhang, S., and Luo, P. Multi-compound transformer for accurate biomedical image segmentation. In de Bruijne, M., Cattin, P. C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., and Essert, C. (eds.), Medical Image Computing and Computer Assisted Intervention - MICCAI 2021 - 24th International Conference, Strasbour...
-
[16]
Layercam: Exploring hierarchical class activation maps for localization
Jiang, P., Zhang, C., Hou, Q., Cheng, M., and Wei, Y. Layercam: Exploring hierarchical class activation maps for localization. IEEE Trans. Image Process. , 30: 0 5875--5888, 2021. doi:10.1109/TIP.2021.3089943. URL https://doi.org/10.1109/TIP.2021.3089943
-
[17]
Li, J., Li, D., Xiong, C., and Hoi, S. C. H. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation. In Chaudhuri, K., Jegelka, S., Song, L., Szepesv \' a ri, C., Niu, G., and Sabato, S. (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA , volume 162 ...
2022
-
[18]
arXiv preprint arXiv:1908.03557 , year=
Li, L. H., Yatskar, M., Yin, D., Hsieh, C., and Chang, K. Visualbert: A simple and performant baseline for vision and language. CoRR, abs/1908.03557, 2019. URL http://arxiv.org/abs/1908.03557
-
[19]
UNIMO: towards unified-modal understanding and generation via cross-modal contrastive learning
Li, W., Gao, C., Niu, G., Xiao, X., Liu, H., Liu, J., Wu, H., and Wang, H. UNIMO: towards unified-modal understanding and generation via cross-modal contrastive learning. In Zong, C., Xia, F., Li, W., and Navigli, R. (eds.), Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference ...
-
[20]
Lin, T., Maire, M., Belongie, S. J., Hays, J., Perona, P., Ramanan, D., Doll \' a r, P., and Zitnick, C. L. Microsoft COCO: common objects in context. In Fleet, D. J., Pajdla, T., Schiele, B., and Tuytelaars, T. (eds.), Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V , volume 8693 of L...
-
[21]
Editing conditional radiance fields
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In 2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021 , pp.\ 9992--10002. IEEE , 2021. doi:10.1109/ICCV48922.2021.00986. URL https://doi.org/10.110...
-
[22]
Clip4clip: An empirical study of CLIP for end to end video clip retrieval and captioning
Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., and Li, T. Clip4clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing, 508: 0 293--304, 2022. doi:10.1016/J.NEUCOM.2022.07.028. URL https://doi.org/10.1016/j.neucom.2022.07.028
-
[23]
Mariotti, E., Sivaprasad, A., and Alonso - Moral, J. M. Beyond prediction similarity: Shapgap for evaluating faithful surrogate models in XAI . In Longo, L. (ed.), Explainable Artificial Intelligence - First World Conference, xAI 2023, Lisbon, Portugal, July 26-28, 2023, Proceedings, Part I , Communications in Computer and Information Science, pp.\ 160--1...
-
[24]
Are sixteen heads really better than one? In Wallach, H
Michel, P., Levy, O., and Neubig, G. Are sixteen heads really better than one? In Wallach, H. M., Larochelle, H., Beygelzimer, A., d'Alch \' e - Buc, F., Fox, E. B., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC...
2019
-
[25]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learning transferable visual models from natural language supervision. In Meila, M. and Zhang, T. (eds.), Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Vi...
2021
-
[26]
Do ImageNet Classifiers Generalize to ImageNet?
Recht, B., Roelofs, R., Schmidt, L., and Shankar, V. Do imagenet classifiers generalize to imagenet? CoRR, abs/1902.10811, 2019. URL http://arxiv.org/abs/1902.10811
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[27]
Ribeiro, M. T., Singh, S., and Guestrin, C. "why should I trust you?": Explaining the predictions of any classifier. In Krishnapuram, B., Shah, M., Smola, A. J., Aggarwal, C. C., Shen, D., and Rastogi, R. (eds.), Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13-17, 2016 ,...
-
[28]
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M. S., Berg, A. C., and Fei - Fei, L. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis., 115 0 (3): 0 211--252, 2015. doi:10.1007/S11263-015-0816-Y. URL https://doi.org/10.1007/s11263-015-0816-y
-
[29]
R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017 , pp.\ 618--626. IEEE Computer Society, 2017. doi:10.1109/ICCV.2017.74. URL https://doi.org/10....
-
[30]
TreeView: Peeking into Deep Neural Networks Via Feature-Space Partitioning
Thiagarajan, J. J., Kailkhura, B., Sattigeri, P., and Ramamurthy, K. N. Treeview: Peeking into deep neural networks via feature-space partitioning. CoRR, abs/1611.07429, 2016. URL http://arxiv.org/abs/1611.07429
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Rozi \` e re, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023 a . doi:10.48550/ARXIV.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[32]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Canton - Ferrer, C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[33]
N., Kaiser, L., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. In Guyon, I., von Luxburg, U., Bengio, S., Wallach, H. M., Fergus, R., Vishwanathan, S. V. N., and Garnett, R. (eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processi...
2017
-
[34]
Tfnet: Transformer fusion network for ultrasound image segmentation
Wang, T., Lai, Z., and Kong, H. Tfnet: Transformer fusion network for ultrasound image segmentation. In Wallraven, C., Liu, Q., and Nagahara, H. (eds.), Pattern Recognition - 6th Asian Conference, ACPR 2021, Jeju Island, South Korea, November 9-12, 2021, Revised Selected Papers, Part I , volume 13188 of Lecture Notes in Computer Science, pp.\ 314--325. Sp...
-
[35]
Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., and Liu, T. CRIS: clip-driven referring image segmentation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pp.\ 11676--11685. IEEE , 2022. doi:10.1109/CVPR52688.2022.01139. URL https://doi.org/10.1109/CVPR52688.2022.01139
-
[36]
Xie, W., Li, X., Cao, C. C., and Zhang, N. L. Vit-cx: Causal explanation of vision transformers. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China , pp.\ 1569--1577. ijcai.org, 2023. doi:10.24963/IJCAI.2023/174. URL https://doi.org/10.24963/ijcai.2023/174
-
[37]
Cotr: Efficiently bridging CNN and transformer for 3d medical image segmentation
Xie, Y., Zhang, J., Shen, C., and Xia, Y. Cotr: Efficiently bridging CNN and transformer for 3d medical image segmentation. In de Bruijne, M., Cattin, P. C., Cotin, S., Padoy, N., Speidel, S., Zheng, Y., and Essert, C. (eds.), Medical Image Computing and Computer Assisted Intervention - MICCAI 2021 - 24th International Conference, Strasbourg, France, Sept...
-
[38]
Xu, J., Mello, S. D., Liu, S., Byeon, W., Breuel, T. M., Kautz, J., and Wang, X. Groupvit: Semantic segmentation emerges from text supervision. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pp.\ 18113--18123. IEEE , 2022. doi:10.1109/CVPR52688.2022.01760. URL https://doi.org/10.1109/...
-
[39]
Explaining information flow inside vision transformers using markov chain
Yuan, T., Li, X., Xiong, H., Cao, H., and Dou, D. Explaining information flow inside vision transformers using markov chain. In eXplainable AI approaches for debugging and diagnosis., 2021. URL https://openreview.net/forum?id=TT-cf6QSDaQ
2021
-
[40]
Zhao, C., Wang, K., Zeng, X., Zhao, R., and Chan, A. B. Gradient-based visual explanation for transformer-based CLIP . In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=WT4X3QYopC
2024
-
[41]
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L. H., Zhou, L., Dai, X., Yuan, L., Li, Y., and Gao, J. Regionclip: Region-based language-image pretraining. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022 , pp.\ 16772--16782. IEEE , 2022. doi:10.1109/CVPR52688.2022.01629. URL ht...
-
[42]
Learning deep features for discriminative localization
Zhou, B., Khosla, A., Lapedriza, \` A ., Oliva, A., and Torralba, A. Learning deep features for discriminative localization. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016 , pp.\ 2921--2929. IEEE Computer Society, 2016. doi:10.1109/CVPR.2016.319. URL https://doi.org/10.1109/CVPR.2016.319
-
[43]
Learning to prompt for vision-language models.Int
Zhou, K., Yang, J., Loy, C. C., and Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis., 130 0 (9): 0 2337--2348, 2022. doi:10.1007/S11263-022-01653-1. URL https://doi.org/10.1007/s11263-022-01653-1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.