Recognition: no theorem link
PRISM: Prior Rectification and Uncertainty-Aware Structure Modeling for Diffusion-Based Text Image Super-Resolution
Pith reviewed 2026-05-14 19:20 UTC · model grok-4.3
The pith
PRISM uses flow matching on paired latents and uncertainty-aware residuals to correct unreliable text priors and refine stroke boundaries inside a single diffusion pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
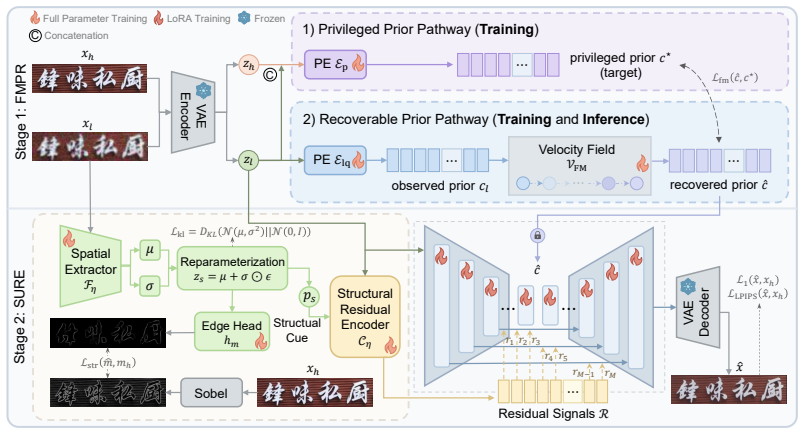
PRISM is a single-step diffusion-based Text-SR framework that constructs a privileged training-time prior from paired low-quality and high-quality latents via Flow-Matching Prior Rectification, then employs a Structure-guided Uncertainty-aware Residual Encoder to predict uncertainty-aware structural residuals that selectively refine reliable stroke boundaries while suppressing ambiguous cues, thereby supplying both rectified global text guidance and local structure refinement within one restoration pass.
What carries the argument
Flow-Matching Prior Rectification (FMPR) that transports degraded embeddings toward a paired restoration prior, combined with a Structure-guided Uncertainty-aware Residual Encoder (SURE) that outputs uncertainty-weighted structural residuals for selective boundary correction.
If this is right
- State-of-the-art performance on both synthetic and real-world text image super-resolution benchmarks.
- Millisecond-level inference suitable for practical deployment.
- Explicit correction of unreliable text conditions extracted from low-quality inputs.
- Simultaneous global prior rectification and local stroke-boundary refinement in one diffusion pass.
- Reduced risk of stroke topology errors that alter character identity.
Where Pith is reading between the lines
- The same privileged-prior construction could be applied to other restoration tasks where global semantics must be aligned with local detail evidence.
- If the uncertainty map proves stable, downstream recognition or editing pipelines could use it directly instead of running separate post-processing steps.
- The structural residual approach may generalize to non-Latin scripts whose stroke topologies differ markedly from the training distribution.
- Training-time access to paired latents suggests the method could be adapted to semi-supervised settings with only a modest number of high-quality examples.
Load-bearing premise
The privileged prior learned from paired latents plus the uncertainty-weighted residuals will reliably fix stroke boundaries under severe real-world degradation without creating new character-identity errors.
What would settle it
Run PRISM on a held-out collection of real-world low-resolution text images whose high-resolution ground truth is known; count how often the output characters are misrecognized by an independent OCR system compared with the ground-truth high-resolution versions.
Figures










read the original abstract
Text image super-resolution (Text-SR) requires more than visually plausible detail synthesis: slight errors in stroke topology may alter character identity and break readability. Existing methods improve text fidelity with stronger recognition-based or generative priors, yet they still face two unresolved challenges under severe degradation: the text condition extracted from low-quality inputs can itself be unreliable, and a plausible global prior does not fully determine fine-grained stroke boundaries. We present PRISM, a single-step diffusion-based Text-SR framework that addresses these two challenges through Flow-Matching Prior Rectification (FMPR) and a Structure-guided Uncertainty-aware Residual Encoder (SURE). FMPR constructs a privileged training-time prior from paired low-quality/high-quality latents and learns a flow matching that transports degraded embeddings toward this restoration-oriented prior space, yielding more accurate and reliable global text guidance. SURE further predicts uncertainty-aware structural residuals to selectively absorb reliable local boundary evidence while suppressing ambiguous stroke cues. Together, these components enable explicit global prior rectification and local structure refinement within a single diffusion restoration pass. Experiments on both synthetic and real-world benchmarks show that PRISM achieves state-of-the-art performance with millisecond-level inference. Our dataset and code will be available at https://github.com/faithxuz/PRISM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a single-step diffusion-based framework for text image super-resolution. It proposes Flow-Matching Prior Rectification (FMPR) that constructs a privileged restoration prior from paired low-quality/high-quality latents and learns a flow to transport degraded embeddings toward this prior for reliable global text guidance, combined with a Structure-guided Uncertainty-aware Residual Encoder (SURE) that predicts uncertainty-aware structural residuals to refine stroke boundaries. Experiments on synthetic and real-world benchmarks are claimed to demonstrate state-of-the-art performance with millisecond-level inference.
Significance. If the quantitative results and ablations hold, the work would offer a practical advance in text-specific super-resolution by explicitly rectifying unreliable text conditions from degraded inputs and selectively correcting stroke topology without identity-altering errors, which is load-bearing for downstream OCR and document restoration tasks. The single-step diffusion design and explicit handling of global prior vs. local boundary uncertainty distinguish it from prior generative or recognition-based approaches.
major comments (2)
- [Experiments section (or §4)] The central SOTA claim on real-world benchmarks rests on the assumption that the FMPR flow learned from training-time paired (LQ/HQ) latents generalizes to unseen degradations (e.g., sensor noise, compression artifacts) without introducing new stroke errors. No cross-degradation ablation or out-of-distribution test isolating this transport fidelity is described, which directly undermines the generalization argument for real-world performance.
- [Abstract and Experiments] The abstract asserts millisecond-level inference and SOTA results, yet the provided description supplies no quantitative metrics, timing tables, or ablation studies on FMPR and SURE components. Without these, the load-bearing performance claims cannot be verified from the manuscript as presented.
minor comments (2)
- [Method] Clarify the exact formulation of the flow-matching objective in FMPR (e.g., the transport map and conditioning) and how the privileged prior is constructed from paired latents, as the high-level description leaves the implementation details ambiguous.
- [Method] The SURE residual prediction mechanism would benefit from an explicit equation showing how uncertainty modulates the structural residual addition within the diffusion step.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments section (or §4)] The central SOTA claim on real-world benchmarks rests on the assumption that the FMPR flow learned from training-time paired (LQ/HQ) latents generalizes to unseen degradations (e.g., sensor noise, compression artifacts) without introducing new stroke errors. No cross-degradation ablation or out-of-distribution test isolating this transport fidelity is described, which directly undermines the generalization argument for real-world performance.
Authors: We agree that an explicit cross-degradation ablation would better support the generalization claims for FMPR. In the revised manuscript we will add a new subsection in Experiments that trains the model on the standard paired training degradations and evaluates on held-out test sets augmented with unseen degradations (additive sensor noise at multiple levels and JPEG compression at varying quality factors). We will report PSNR/SSIM, stroke-level error rates via OCR, and visual examples to confirm that the learned flow does not introduce new topology errors on these OOD cases. This directly addresses the concern about transport fidelity under real-world distribution shifts. revision: yes
-
Referee: [Abstract and Experiments] The abstract asserts millisecond-level inference and SOTA results, yet the provided description supplies no quantitative metrics, timing tables, or ablation studies on FMPR and SURE components. Without these, the load-bearing performance claims cannot be verified from the manuscript as presented.
Authors: The full manuscript already contains the requested quantitative evidence in Section 4: Table 1 reports PSNR, SSIM, LPIPS and OCR accuracy on both synthetic and real-world benchmarks showing consistent SOTA gains; Table 3 provides inference timing (average 7.2 ms per 512×512 image on RTX 3090); and Table 4 plus Figure 5 present component ablations isolating FMPR and SURE with corresponding metric deltas. We will revise the abstract to explicitly cite these tables and add a short summary paragraph at the start of the Experiments section that points readers to the metrics and ablations for immediate verification. revision: partial
Circularity Check
No circularity in derivation chain
full rationale
The paper presents PRISM as a diffusion-based framework using Flow-Matching Prior Rectification (FMPR) constructed from paired LQ/HQ latents and Structure-guided Uncertainty-aware Residual Encoder (SURE) for residuals. These are described as extensions of established flow-matching and diffusion methods, with performance claims resting on empirical benchmark results rather than any derivation that reduces by construction to fitted inputs or self-referential definitions. No load-bearing equations or steps equate predictions to training fits, import uniqueness via self-citation chains, or smuggle ansatzes; the central claims remain independent of the method's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
One-step effective diffusion network for real-world image super-resolution
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. One-step effective diffusion network for real-world image super-resolution. InNeurIPS, 2024
2024
-
[2]
Tsd-sr: One-step diffusion with target score distillation for real-world image super- resolution
Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. Tsd-sr: One-step diffusion with target score distillation for real-world image super- resolution. InCVPR, 2025
2025
-
[3]
One diffusion step to real-world super-resolution via flow trajectory distillation
Jianze Li, Jiezhang Cao, Yong Guo, Wenbo Li, and Yulun Zhang. One diffusion step to real-world super-resolution via flow trajectory distillation. InICML, 2025
2025
-
[4]
Learning generative structure prior for blind text image super-resolution
Xiaoming Li, Wangmeng Zuo, and Chen Change Loy. Learning generative structure prior for blind text image super-resolution. InCVPR, 2023
2023
-
[5]
Scene text image super-resolution in the wild
Wenjia Wang, Enze Xie, Xuebo Liu, Wenhai Wang, Ding Liang, Chunhua Shen, and Xiang Bai. Scene text image super-resolution in the wild. InECCV, 2020
2020
-
[6]
Scene text telescope: Text-focused scene image super-resolution
Jingye Chen, Bin Li, and Xiangyang Xue. Scene text telescope: Text-focused scene image super-resolution. InCVPR, 2021
2021
-
[7]
A text attention network for spatial deformation robust scene text image super-resolution
Jianqi Ma, Zhetong Liang, and Lei Zhang. A text attention network for spatial deformation robust scene text image super-resolution. InCVPR, 2022
2022
-
[8]
Stylesrn: Scene text image super-resolution with text style embedding
Shengrong Yuan, Runmin Wang, Ke Hao, Xuqi Ma, Changxin Gao, Li Liu, and Nong Sang. Stylesrn: Scene text image super-resolution with text style embedding. InICCV, 2025
2025
-
[9]
Diffusion-based blind text image super-resolution
Yuzhe Zhang, Jiawei Zhang, Hao Li, Zhouxia Wang, Luwei Hou, Dongqing Zou, and Liheng Bian. Diffusion-based blind text image super-resolution. InCVPR, 2024
2024
-
[10]
Text-aware real-world image super-resolution via diffusion model with joint segmentation decoders
Qiming Hu, Linlong Fan, Yiyan Luo, Yuhang Yu, Xiaojie Guo, and Qingnan Fan. Text-aware real-world image super-resolution via diffusion model with joint segmentation decoders. InNeurIPS, 2025
2025
-
[11]
Text-aware image restoration with diffusion models
Jaewon Min, Jin Hyeon Kim, Paul Hyunbin Cho, Jaeeun Lee, Jihye Park, Minkyu Park, Sangpil Kim, Hyunhee Park, and Seungryong Kim. Text-aware image restoration with diffusion models. InICLR, 2026
2026
-
[12]
Texts-diff: Texts-aware diffusion model for real-world text image super-resolution
Haodong He, Xin Zhan, Yancheng Bai, Rui Lan, Lei Sun, and Xiangxiang Chu. Texts-diff: Texts-aware diffusion model for real-world text image super-resolution. InICASSP, 2026
2026
-
[13]
Designing a practical degradation model for deep blind image super-resolution
Kai Zhang, Jingyun Liang, Luc Van Gool, and Radu Timofte. Designing a practical degradation model for deep blind image super-resolution. InICCV, 2021
2021
-
[14]
Real-esrgan: Training real-world blind super- resolution with pure synthetic data
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. Real-esrgan: Training real-world blind super- resolution with pure synthetic data. InICCV, 2021
2021
-
[15]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
2022
-
[16]
Exploiting diffusion prior for real-world image super-resolution.IJCV, 2024
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin CK Chan, and Chen Change Loy. Exploiting diffusion prior for real-world image super-resolution.IJCV, 2024
2024
-
[17]
Diffbir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InECCV, 2024
2024
-
[18]
One-step diffusion model for image motion-deblurring.arXiv preprint arXiv:2503.06537, 2025
Xiaoyang Liu, Yuquan Wang, Zheng Chen, Jiezhang Cao, He Zhang, Yulun Zhang, and Xiaokang Yang. One-step diffusion model for image motion-deblurring.arXiv preprint arXiv:2503.06537, 2025
-
[19]
Fidediff: Efficient diffusion model for high-fidelity image motion deblurring
Xiaoyang Liu, Zhengyan Zhou, Zihang Xu, Jiezhang Cao, Zheng Chen, and Yulun Zhang. Fidediff: Efficient diffusion model for high-fidelity image motion deblurring. InICLR, 2025
2025
-
[20]
Seesr: Towards semantics-aware real-world image super-resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. Seesr: Towards semantics-aware real-world image super-resolution. InCVPR, 2024
2024
-
[21]
Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild
Fanghua Yu, Jinjin Gu, Zheyuan Li, Jinfan Hu, Xiangtao Kong, Xintao Wang, Jingwen He, Yu Qiao, and Chao Dong. Scaling up to excellence: Practicing model scaling for photo-realistic image restoration in the wild. InCVPR, 2024
2024
-
[22]
Sinsr: diffusion-based image super-resolution in a single step
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C Kot, and Bihan Wen. Sinsr: diffusion-based image super-resolution in a single step. InCVPR, 2024. 10
2024
-
[23]
Arbitrary-steps image super-resolution via diffusion inversion
Zongsheng Yue, Kang Liao, and Chen Change Loy. Arbitrary-steps image super-resolution via diffusion inversion. InCVPR, 2025
2025
-
[24]
Harnessing diffusion-yielded score priors for image restoration.SIGGRAPH Asia, 2025
Xinqi Lin, Fanghua Yu, Jinfan Hu, Zhiyuan You, Wu Shi, Jimmy S Ren, Jinjin Gu, and Chao Dong. Harnessing diffusion-yielded score priors for image restoration.SIGGRAPH Asia, 2025
2025
-
[25]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[27]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InICML, 2024
2024
-
[28]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[29]
Dit4sr: Taming diffusion transformer for real-world image super-resolution
Zheng-Peng Duan, Jiawei Zhang, Xin Jin, Ziheng Zhang, Zheng Xiong, Dongqing Zou, Jimmy S Ren, Chunle Guo, and Chongyi Li. Dit4sr: Taming diffusion transformer for real-world image super-resolution. InICCV, 2025
2025
-
[30]
Text prior guided scene text image super-resolution.IEEE TIP, 2023
Jianqi Ma, Shi Guo, and Lei Zhang. Text prior guided scene text image super-resolution.IEEE TIP, 2023
2023
-
[31]
Stirer: A unified model for low-resolution scene text image recovery and recognition
Minyi Zhao, Shijie Xuyang, Jihong Guan, and Shuigeng Zhou. Stirer: A unified model for low-resolution scene text image recovery and recognition. InACM MM, 2023
2023
-
[32]
Towards robust scene text image super-resolution via explicit location enhancement
Hang Guo, Tao Dai, Guanghao Meng, and Shu-Tao Xia. Towards robust scene text image super-resolution via explicit location enhancement. InIJCAI, 2023
2023
-
[33]
Gradient-based graph attention for scene text image super-resolution
Xiangyuan Zhu, Kehua Guo, Hui Fang, Rui Ding, Zheng Wu, and Gerald Schaefer. Gradient-based graph attention for scene text image super-resolution. InAAAI, 2023
2023
-
[34]
Improving scene text image super-resolution via dual prior modulation network
Shipeng Zhu, Zuoyan Zhao, Pengfei Fang, and Hui Xue. Improving scene text image super-resolution via dual prior modulation network. InAAAI, 2023
2023
-
[35]
Pean: A diffusion-based prior-enhanced attention network for scene text image super-resolution
Zuoyan Zhao, Hui Xue, Pengfei Fang, and Shipeng Zhu. Pean: A diffusion-based prior-enhanced attention network for scene text image super-resolution. InACM MM, 2024
2024
-
[36]
Glyphsr: A simple glyph-aware framework for scene text image super-resolution
Baole Wei, Yuxuan Zhou, Liangcai Gao, and Zhi Tang. Glyphsr: A simple glyph-aware framework for scene text image super-resolution. InAAAI, 2025
2025
-
[37]
Enhanced generative structure prior for chinese text image super-resolution.IEEE TPAMI, 2025
Xiaoming Li, Wangmeng Zuo, and Chen Change Loy. Enhanced generative structure prior for chinese text image super-resolution.IEEE TPAMI, 2025
2025
-
[38]
Dcdm: Diffusion-conditioned- diffusion model for scene text image super-resolution
Shrey Singh, Prateek Keserwani, Masakazu Iwamura, and Partha Pratim Roy. Dcdm: Diffusion-conditioned- diffusion model for scene text image super-resolution. InECCV, 2024
2024
-
[39]
Distillation-free one-step diffusion for real-world image super-resolution
Jianze Li, Jiezhang Cao, Zichen Zou, Xiongfei Su, Xin Yuan, Yulun Zhang, Yong Guo, and Xiaokang Yang. Distillation-free one-step diffusion for real-world image super-resolution. InNeurIPS, 2025
2025
-
[40]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
2020
-
[41]
Learning using privileged information: similarity control and knowledge transfer.JMLR, 2015
Vladimir Vapnik and Rauf Izmailov. Learning using privileged information: similarity control and knowledge transfer.JMLR, 2015
2015
-
[42]
Learning with privileged information for efficient image super-resolution
Wonkyung Lee, Junghyup Lee, Dohyung Kim, and Bumsub Ham. Learning with privileged information for efficient image super-resolution. InECCV, 2020
2020
-
[43]
Diffir: Efficient diffusion model for image restoration
Bin Xia, Yulun Zhang, Shiyin Wang, Yitong Wang, Xinglong Wu, Yapeng Tian, Wenming Yang, and Luc Van Gool. Diffir: Efficient diffusion model for image restoration. InICCV, 2023
2023
-
[44]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[45]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[46]
What uncertainties do we need in bayesian deep learning for computer vision? InNeurIPS, 2017
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? InNeurIPS, 2017. 11
2017
-
[47]
Uncertainty-driven loss for single image super-resolution
Qian Ning, Weisheng Dong, Xin Li, Jinjian Wu, and GUANGMING Shi. Uncertainty-driven loss for single image super-resolution. InNeurIPS, 2021
2021
-
[48]
Self-supervised non-uniform kernel estimation with flow-based motion prior for blind image deblurring
Zhenxuan Fang, Fangfang Wu, Weisheng Dong, Xin Li, Jinjian Wu, and Guangming Shi. Self-supervised non-uniform kernel estimation with flow-based motion prior for blind image deblurring. InCVPR, 2023
2023
-
[49]
A benchmark for chinese-english scene text image super-resolution
Jianqi Ma, Zhetong Liang, Wangmeng Xiang, Xi Yang, and Lei Zhang. A benchmark for chinese-english scene text image super-resolution. InICCV, 2023
2023
-
[50]
Haiyang Yu, Jingye Chen, Bin Li, Jianqi Ma, Mengnan Guan, Xixi Xu, Xiaocong Wang, Shaobo Qu, and Xiangyang Xue. Benchmarking chinese text recognition: Datasets, baselines, and an empirical study.arXiv preprint arXiv:2112.15093, 2021
-
[51]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InICCV, 2021
2021
-
[52]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. InCVPRW, 2022
2022
-
[53]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InAAAI, 2023
2023
-
[54]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. InICLR, 2022
2022
-
[55]
OSDFace: One-step diffusion model for face restoration
Jingkai Wang, Jue Gong, Lin Zhang, Zheng Chen, Xing Liu, Hong Gu, Yutong Liu, Yulun Zhang, and Xiaokang Yang. OSDFace: One-step diffusion model for face restoration. InCVPR, 2025
2025
-
[56]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
-
[57]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, 2017
2017
-
[58]
PaddleOCR 3.0 Technical Report
Cheng Cui, Ting Sun, Manhui Lin, Tingquan Gao, Yubo Zhang, Jiaxuan Liu, Xueqing Wang, Zelun Zhang, Changda Zhou, Hongen Liu, et al. Paddleocr 3.0 technical report.arXiv preprint arXiv:2507.05595, 2025. 12 A Details of BTL Dataset Construction Motivation and source data.Existing text-image datasets cover different aspects of Text-SR, but no single resource...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.