Recognition: unknown
MAP: A Map-then-Act Paradigm for Long-Horizon Interactive Agent Reasoning
Pith reviewed 2026-05-14 19:43 UTC · model grok-4.3
The pith
The Map-then-Act Paradigm lets LLM agents build environment maps before execution to escape trial-and-error cycles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
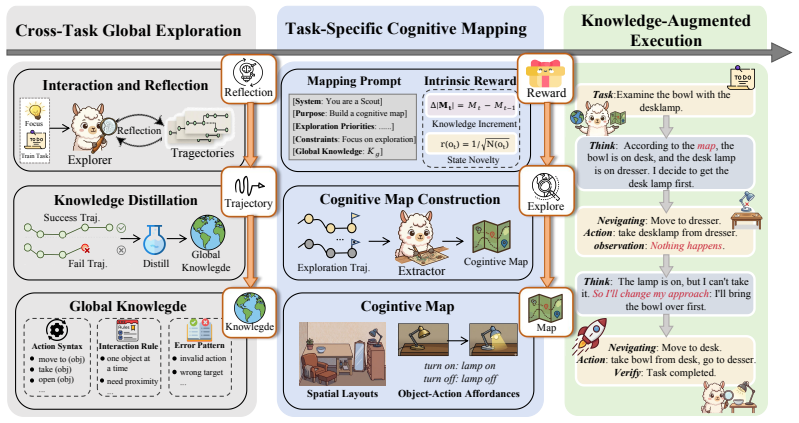
MAP consists of three stages: global exploration to acquire environment-general priors, task-specific mapping to construct a structured cognitive map, and knowledge-augmented execution that solves tasks by referencing the map. By moving environment understanding ahead of action rather than acquiring it through trial-and-error, the paradigm directly targets the epistemic bottleneck that traps agents in inefficient failure loops.
What carries the argument
The three-stage Map-then-Act Paradigm (MAP) that acquires environment-general priors through exploration, constructs a cognitive map, and grounds subsequent execution on that map.
If this is right
- Frontier models reach positive performance in 22 of 25 ARC-AGI-3 game environments.
- Training on MAP-2K map-then-act trajectories outperforms training on expert execution traces.
- Environment understanding is positioned as more fundamental than imitation for long-horizon agent success.
Where Pith is reading between the lines
- Pre-mapping stages could be added to agents operating in robotics or web-navigation domains where environments are only partially known.
- The cognitive-map representation may combine with external memory or symbolic planners in future agent designs.
- Scaling global exploration to many environments might produce reusable priors that transfer across related tasks without re-exploration.
Load-bearing premise
Global exploration produces an accurate cognitive map that stays valid and useful during the entire task-execution phase without adding new errors or excessive cost.
What would settle it
Replace the pre-built cognitive map with a random or empty structure and measure whether success rates on ARC-AGI-3 games fall back to baseline near-zero levels.
Figures









read the original abstract
Current interactive LLM agents rely on goal-conditioned stepwise planning, where environmental understanding is acquired reactively during execution rather than established beforehand. This temporal inversion leads to Delayed Environmental Perception: agents must infer environmental constraints through trial-and-error, resulting in an Epistemic Bottleneck that traps them in inefficient failure cycles. Inspired by human affordance perception and cognitive map theory, we propose the Map-then-Act Paradigm (MAP), a plug-and-play framework that shifts environment understanding before execution. MAP consists of three stages: (1) Global Exploration, acquiring environment-general priors; (2) Task-Specific Mapping, constructing a structured cognitive map; and (3) Knowledge-Augmented Execution, solving tasks grounded on the map. Experiments show consistent gains across benchmarks and LLMs. On ARC-AGI-3, MAP enables frontier models to surpass near-zero baseline performance in 22 of 25 game environments. We further introduce MAP-2K, a dataset of map-then-act trajectories, and show that training on it outperforms expert execution traces, suggesting that understanding environments is more fundamental than imitation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Map-then-Act Paradigm (MAP), a plug-and-play framework for long-horizon interactive LLM agents that inverts the typical reactive planning process. MAP consists of three stages: (1) Global Exploration to acquire environment-general priors, (2) Task-Specific Mapping to construct a structured cognitive map, and (3) Knowledge-Augmented Execution to solve tasks grounded in the map. The central claims are that this addresses Delayed Environmental Perception and the Epistemic Bottleneck, yields consistent gains across benchmarks and models, enables frontier models to succeed in 22 of 25 ARC-AGI-3 game environments (versus near-zero baselines), and that the introduced MAP-2K dataset of map-then-act trajectories produces better training outcomes than expert execution traces.
Significance. If the empirical results hold under scrutiny, the work offers a substantive shift in agent design from reactive trial-and-error to proactive environment mapping, which could improve sample efficiency and success rates in long-horizon interactive settings. The MAP-2K dataset is a concrete contribution that could support further research on training agents to prioritize environmental understanding over pure imitation.
major comments (2)
- [Experiments] Experiments section (ARC-AGI-3 results): the claim of success in 22 of 25 environments is presented without reported baselines, number of trials, variance, or statistical tests, making it impossible to verify that the gains are attributable to the mapping stage rather than other factors.
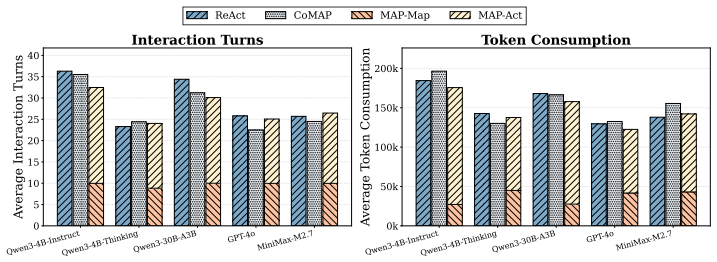
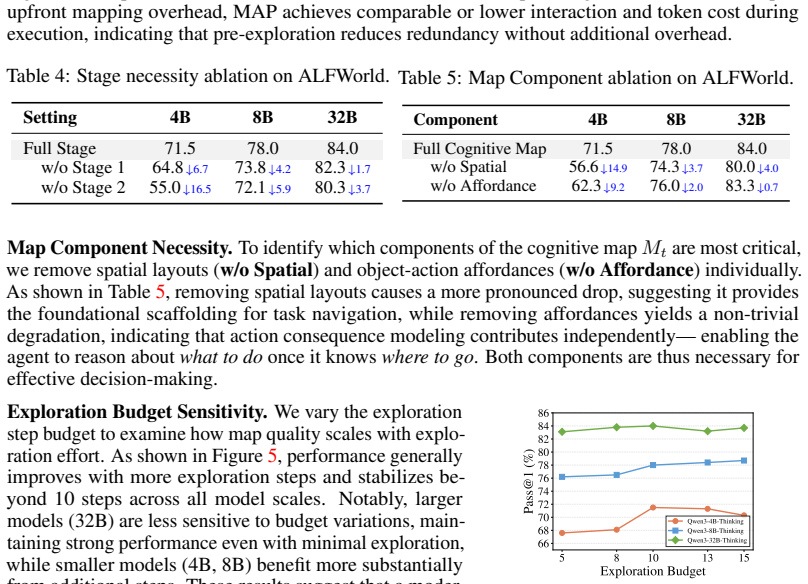
- [Framework] Framework description (stages 1-3): no analysis or ablation is provided on the overhead or error accumulation of maintaining the cognitive map during execution, which directly bears on whether the map remains valid and low-cost as assumed in the weakest point of the argument.
minor comments (2)
- [Abstract] Abstract: replace qualitative phrases such as 'consistent gains' with at least one concrete metric (e.g., average success rate or delta over baseline) to allow readers to assess the scale of improvement immediately.
- [Framework] Notation: the term 'cognitive map' is introduced without a precise formal definition or pseudocode for how it is represented and updated, which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the empirical reporting and framework analysis as outlined.
read point-by-point responses
-
Referee: Experiments section (ARC-AGI-3 results): the claim of success in 22 of 25 environments is presented without reported baselines, number of trials, variance, or statistical tests, making it impossible to verify that the gains are attributable to the mapping stage rather than other factors.
Authors: We acknowledge that the current presentation of the ARC-AGI-3 results would be strengthened by additional statistical rigor. The manuscript currently contrasts MAP-enabled performance against a near-zero baseline, but we agree this is insufficient for full verification. In the revised version, we will expand the Experiments section to report the exact baseline success rates per environment, the number of independent trials run, variance measures (e.g., standard deviation across runs), and appropriate statistical tests (such as paired t-tests or McNemar's test) to demonstrate that the observed gains are attributable to the mapping stage rather than other factors. revision: yes
-
Referee: Framework description (stages 1-3): no analysis or ablation is provided on the overhead or error accumulation of maintaining the cognitive map during execution, which directly bears on whether the map remains valid and low-cost as assumed in the weakest point of the argument.
Authors: We agree this is an important gap. The current manuscript assumes the cognitive map remains valid and low-cost but does not empirically examine overhead or error accumulation. In the revised manuscript, we will add an ablation study and analysis section that quantifies the computational overhead of map maintenance (e.g., token usage and latency per update), measures error accumulation rates over execution steps, and reports how map validity affects downstream task success. This will include comparisons of performance with and without periodic map refresh to address the concern directly. revision: yes
Circularity Check
No significant circularity in the MAP derivation chain
full rationale
The paper defines MAP as a three-stage empirical framework (Global Exploration for priors, Task-Specific Mapping for cognitive maps, Knowledge-Augmented Execution) without equations, fitted parameters, or predictions that reduce to inputs by construction. Central claims of gains on ARC-AGI-3 (22/25 environments) and MAP-2K superiority are presented as experimental outcomes of applying the stages, not as self-referential derivations. No self-citations, uniqueness theorems, or ansatzes are load-bearing; the paradigm is introduced as a plug-and-play shift inspired by external cognitive map theory, with results treated as falsifiable benchmarks rather than tautological outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human affordance perception and cognitive map theory provide a valid basis for designing agent reasoning systems
invented entities (1)
-
Cognitive map
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learn- ing to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[3]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.arXiv preprint arXiv:2512.10696, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Learning to self-verify makes language models better reasoners
Yuxin Chen, Yu Wang, Yi Zhang, Ziang Ye, Zhengzhou Cai, Yaorui Shi, Qi Gu, Hui Su, Xunliang Cai, Xiang Wang, et al. Learning to self-verify makes language models better reasoners.arXiv preprint arXiv:2602.07594, 2026
-
[6]
Jinyuan Fang, Yanwen Peng, Xi Zhang, Yingxu Wang, Xinhao Yi, Guibin Zhang, Yi Xu, Bin Wu, Siwei Liu, Zihao Li, et al. A comprehensive survey of self-evolving ai agents: A new paradigm bridging foundation models and lifelong agentic systems.arXiv preprint arXiv:2508.07407, 2025
-
[7]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence
ARC Foundation. Arc-agi-3: A new challenge for frontier agentic intelligence.arXiv preprint arXiv:2603.24621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Yao Fu, Dong-Ki Kim, Jaekyeom Kim, Sungryull Sohn, Lajanugen Logeswaran, Kyunghoon Bae, and Honglak Lee. Autoguide: Automated generation and selection of context-aware guidelines for large language model agents.Advances in Neural Information Processing Systems, 37:119919–119948, 2024
work page 2024
-
[9]
James J Gibson.The ecological approach to visual perception: classic edition. Psychology press, 2014
work page 2014
-
[10]
Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis.arXiv preprint arXiv:2307.12856, 2023
-
[11]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps. InProceedings of the 28th International Conference on Computational Linguistics, pp. 6609–6625, 2020
work page 2020
-
[12]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
work page 2022
-
[14]
Siyuan Liu, Hongbang Yuan, Xinze Li, Ziyue Zhu, Yixin Cao, and Yu-Gang Jiang. What do llm agents know about their world? task2quiz: A paradigm for studying environment understanding. arXiv preprint arXiv:2601.09503, 2026
-
[15]
Zeyuan Liu, Jeonghye Kim, Xufang Luo, Dongsheng Li, and Yuqing Yang. Exploratory memory-augmented llm agent via hybrid on-and off-policy optimization.arXiv preprint arXiv:2602.23008, 2026
-
[16]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025. 10
work page 2025
-
[17]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Procmem: Learning reusable procedural memory from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[19]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceed- ings of the 36th annual acm symposium on user interface software and technology, pp. 1–22, 2023
work page 2023
-
[20]
Causal diagrams for empirical research (with discussions)
Judea Pearl. Causal diagrams for empirical research (with discussions). InProbabilistic and causal inference: The works of Judea Pearl, pp. 255–316. 2022
work page 2022
-
[21]
Tree-of-reasoning: Towards complex medical diagnosis via multi-agent reasoning with evidence tree
Qi Peng, Jialin Cui, Jiayuan Xie, Yi Cai, and Qing Li. Tree-of-reasoning: Towards complex medical diagnosis via multi-agent reasoning with evidence tree. InProceedings of the 33rd ACM International Conference on Multimedia, pp. 1744–1753, 2025
work page 2025
-
[22]
Textcraft: Zero-shot generation of high fidelity and diverse shapes from text
Aditya Sanghi, Rao Fu, Vivian Liu, Karl Willis, Hooman Shayani, Amir Hosein Khasahmadi, Srinath Sridhar, and Daniel Ritchie. Textcraft: Zero-shot generation of high fidelity and diverse shapes from text. 2022
work page 2022
-
[23]
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Zifeng Wang, Sayna Ebrahimi, and Hao Wang. Continual learning of large language models: A comprehensive survey.ACM Computing Surveys, 58(5):1–42, 2025
work page 2025
-
[24]
Look back to reason forward: Revisitable memory for long-context llm agents
Yaorui Shi, Yuxin Chen, Siyuan Wang, Sihang Li, Hengxing Cai, Qi Gu, Xiang Wang, and An Zhang. Look back to reason forward: Revisitable memory for long-context llm agents. arXiv preprint arXiv:2509.23040, 2025
-
[25]
Tool learning in the wild: Empowering language models as automatic tool agents
Zhengliang Shi, Shen Gao, Lingyong Yan, Yue Feng, Xiuyi Chen, Zhumin Chen, Dawei Yin, Suzan Verberne, and Zhaochun Ren. Tool learning in the wild: Empowering language models as automatic tool agents. InProceedings of the ACM on Web Conference 2025, pp. 2222–2237, 2025
work page 2025
-
[26]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
work page 2023
-
[27]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning.arXiv preprint arXiv:2010.03768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[28]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Y Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, et al. Kimi k2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
work page 1948
-
[30]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Scienceworld: Is your agent smarter than a 5th grader? InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 11279–11298, 2022
work page 2022
-
[32]
Ruoyu Wang, Xinshu Li, Chen Wang, and Lina Yao. Efficient and generalizable environmental understanding for visual navigation.arXiv preprint arXiv:2506.15377, 2025. 11
-
[33]
arXiv preprint arXiv:2601.12538 (2026)
Tianxin Wei, Ting-Wei Li, Zhining Liu, Xuying Ning, Ze Yang, Jiaru Zou, Zhichen Zeng, Ruizhong Qiu, Xiao Lin, Dongqi Fu, et al. Agentic reasoning for large language models.arXiv preprint arXiv:2601.12538, 2026
-
[34]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Siyu Xia, Zekun Xu, Jiajun Chai, Wentian Fan, Yan Song, Xiaohan Wang, Guojun Yin, Wei Lin, Haifeng Zhang, and Jun Wang. From experience to strategy: Empowering llm agents with trainable graph memory.arXiv preprint arXiv:2511.07800, 2025
-
[36]
Reagent: Reversible multi-agent reasoning for knowledge-enhanced multi-hop qa
Zhao Xinjie, Fan Gao, Xingyu Song, Yingjian Chen, Rui Yang, Yanran Fu, Yuyang Wang, Yusuke Iwasawa, Yutaka Matsuo, and Irene Li. Reagent: Reversible multi-agent reasoning for knowledge-enhanced multi-hop qa. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp. 4067–4089, 2025
work page 2025
-
[37]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Cheng Yang, Xuemeng Yang, Licheng Wen, Daocheng Fu, Jianbiao Mei, Rong Wu, Pinlong Cai, Yufan Shen, Nianchen Deng, Botian Shi, et al. Learning on the job: An experience-driven self-evolving agent for long-horizon tasks.arXiv preprint arXiv:2510.08002, 2025
-
[40]
Coarse- to-fine grounded memory for llm agent planning.arXiv preprint arXiv:2508.15305, 2025
Wei Yang, Jinwei Xiao, Hongming Zhang, Qingyang Zhang, Yanna Wang, and Bo Xu. Coarse- to-fine grounded memory for llm agent planning.arXiv preprint arXiv:2508.15305, 2025
-
[41]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
work page 2022
-
[42]
Spatial mental modeling from limited views
Baiqiao Yin, Qineng Wang, Pingyue Zhang, Jianshu Zhang, Kangrui Wang, Zihan Wang, Jieyu Zhang, Keshigeyan Chandrasegaran, Han Liu, Ranjay Krishna, et al. Spatial mental modeling from limited views. InStructural Priors for Vision Workshop at ICCV’25, 2025
work page 2025
-
[43]
Learning to discover at test time.arXiv preprint arXiv:2601.16175, 2026
Mert Yuksekgonul, Daniel Koceja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time. arXiv preprint arXiv:2601.16175, 2026
-
[44]
Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
Yunpeng Zhai, Shuchang Tao, Cheng Chen, Anni Zou, Ziqian Chen, Qingxu Fu, Shinji Mai, Li Yu, Jiaji Deng, Zouying Cao, et al. Agentevolver: Towards efficient self-evolving agent system.arXiv preprint arXiv:2511.10395, 2025
-
[45]
arXiv preprint arXiv:2506.07398 , year=
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G-memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025
-
[46]
Guibin Zhang, Muxin Fu, and Shuicheng Yan. Memgen: Weaving generative latent memory for self-evolving agents.arXiv preprint arXiv:2509.24704, 2025
-
[47]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Kai Zhang, Xiangchao Chen, Bo Liu, Tianci Xue, Zeyi Liao, Zhihan Liu, Xiyao Wang, Yuting Ning, Zhaorun Chen, Xiaohan Fu, et al. Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
-
[48]
Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022
Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models.arXiv preprint arXiv:2210.03493, 2022
-
[49]
arXiv preprint arXiv:2506.15841 , year =
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. Mem1: Learning to synergize memory and reasoning for efficient long-horizon agents.arXiv preprint arXiv:2506.15841, 2025. 12 A Limitations and Future Works While MAP demonstrates strong performance across diverse interactive rea...
-
[50]
I need to go directly to get the correct cup, heat it while holding it, then place in cabinet. > Action: go to countertop 3 → You see a cup 2 → You pick up the cup 2. > Action: go to microwave 1 → open microwave 1. heat cup 2 with microwave 1. > Action: go to cabinet 1 → move cup 2 to cabinet 1 → Task completed. Failed: 37 Steps. Succeeded: 7 Steps Action...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.