Recognition: no theorem link
A Standardized Re-evaluation of Conversational Recommender Systems on the ReDial Dataset
Pith reviewed 2026-05-14 18:33 UTC · model grok-4.3
The pith
Standardized tests on ReDial show that nearly half of reported CRS accuracy comes from repetition shortcuts rather than architectural advances or novelty.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
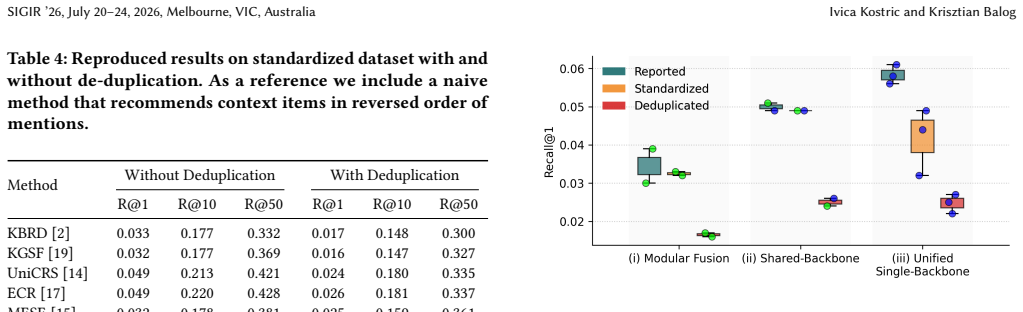
Under standardized conditions the seven methods display a granularity gap where Recall@1 proves highly sensitive to implementation details; replicability analysis attributes nearly 50 percent of reported accuracy to repetition shortcuts absent from novelty-focused evaluation; gains are driven more by LLM backbone capacity than by architectural innovations; and traditional recall metrics overstate conversational effectiveness when measured against user-centric utility.
What carries the argument
A single standardized preprocessing pipeline and evaluation protocol applied uniformly to multiple CRS methods to isolate effects of implementation details, repetition shortcuts, and LLM backbone size.
If this is right
- Fine-grained ranking metrics require strict implementation controls to yield stable comparisons across studies.
- Novelty-focused evaluation protocols remove a large share of the accuracy previously credited to CRS methods.
- Stronger LLM backbones account for much of the observed performance improvement rather than recommender-specific designs.
- User-centric utility metrics reveal that raw recall overstates real conversational value.
- Future CRS papers should report results under fixed preprocessing and novelty-aware metrics to enable direct comparison.
Where Pith is reading between the lines
- Adopting this standardized pipeline as a community reference would make cross-paper comparisons more reliable.
- Testing architectural claims while holding the LLM backbone fixed would clarify which innovations actually add value.
- Similar re-evaluation on other CRS datasets could show whether the granularity gap and repetition effects are widespread.
- Systems that perform well under novelty metrics may require different training objectives focused on interaction efficiency.
Load-bearing premise
The seven selected methods and three architectural families are representative of the wider CRS literature and the single preprocessing pipeline used here serves as the correct reference point for all prior results.
What would settle it
Re-running the seven methods with the exact standardized pipeline produces Recall@1 scores that match the originally published values within a few percentage points and shows no measurable drop when repetition shortcuts are removed.
Figures




read the original abstract
Recent years have seen a surge of research into conversational recommender systems (CRS). Among existing datasets, ReDial is the most widely used benchmark, cited in hundreds of studies. However, variations in how the dataset is preprocessed and used in experiments, particularly in the definition of ground-truth items, make it difficult to compare results across studies. These comparisons are further complicated by confounding factors such as the choice of the underlying large language model (LLM) and the use of external data sources. In this work, we revisit seven prominent CRS methods across three architectural families and evaluate them under standardized conditions. Our reproducibility study reveals a ``granularity gap,'' where fine-grained ranking (Recall@1) is highly sensitive to implementation details, while our replicability analysis shows that nearly 50% of reported accuracy stems from ``repetition shortcuts'' that are absent in novelty-focused evaluation. Furthermore, we find that performance gains are often driven more by the capacity of the LLM backbone than by specific architectural innovations. Finally, by applying user-centric utility metrics, we demonstrate that traditional recall frequently overstates a system's actual conversational effectiveness. This work establishes a transparent, controlled baseline and promotes evaluation practices that prioritize novelty and interaction efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper re-evaluates seven prominent conversational recommender systems across three architectural families on the ReDial dataset under a single standardized preprocessing pipeline. It reports a granularity gap in which Recall@1 is highly sensitive to implementation details, shows that nearly 50% of reported accuracy derives from repetition shortcuts absent under novelty-focused evaluation, finds that performance differences are driven more by LLM backbone capacity than by architectural choices, and demonstrates via user-centric metrics that conventional recall overstates actual conversational utility.
Significance. If the controlled re-runs hold, the work supplies a reproducible baseline that quantifies the contribution of repetition shortcuts and LLM capacity, thereby exposing weaknesses in prior CRS evaluation practices on ReDial and motivating novelty-aware and interaction-efficiency metrics. The direct measurement of the 50% shortcut figure and the backbone-swap controls are concrete strengths that increase the paper's utility to the community.
major comments (1)
- [Introduction and Experiments] Introduction and Experiments sections: the quantitative claims that 'nearly 50%' of accuracy stems from repetition shortcuts and that gains are 'often' driven by LLM capacity rest on a sample of seven methods; the manuscript should add an explicit limitations paragraph stating that these attributions are sample-specific and may not extrapolate to the hundreds of prior ReDial studies that employ different preprocessing pipelines.
minor comments (3)
- [Replicability analysis] The precise operational definition of 'novelty-focused evaluation' (mentioned in the abstract and replicability analysis) should be stated with a short example or pseudocode so that readers can replicate the contrast with standard recall.
- [Replicability analysis] A supplementary table breaking down the repetition-shortcut contribution per method (rather than only the aggregate 50% figure) would make the replicability result easier to inspect and verify.
- Minor notation inconsistency: ensure that 'Recall@1' and 'novelty-focused Recall' are distinguished with distinct symbols or footnotes wherever both appear in the same table or figure.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on clarifying the scope of our findings. We agree that the claims based on our sample of seven methods warrant an explicit limitations statement to avoid overgeneralization, and we will incorporate this in the revised manuscript.
read point-by-point responses
-
Referee: [Introduction and Experiments] Introduction and Experiments sections: the quantitative claims that 'nearly 50%' of accuracy stems from repetition shortcuts and that gains are 'often' driven by LLM capacity rest on a sample of seven methods; the manuscript should add an explicit limitations paragraph stating that these attributions are sample-specific and may not extrapolate to the hundreds of prior ReDial studies that employ different preprocessing pipelines.
Authors: We agree with the referee that our quantitative attributions (the ~50% repetition shortcut contribution and the observation that gains are often driven by LLM capacity) are derived from the specific set of seven methods re-evaluated under our standardized pipeline. To address this, we will add a dedicated limitations paragraph (likely in a new Limitations section or integrated into the Experiments section) that explicitly states these findings are sample-specific to the methods and preprocessing choices studied here, and that they may not extrapolate to the broader body of prior ReDial work employing different pipelines. This addition will be included in the revised version. revision: yes
Circularity Check
No circularity: reproducibility study derives all claims from external benchmarks and published code
full rationale
This is a reproducibility and re-evaluation paper that standardizes preprocessing and metrics for seven existing CRS methods drawn from the literature, then reports empirical outcomes (granularity gap, repetition shortcuts, LLM backbone effects) obtained by re-running published implementations against the fixed ReDial splits and standard metrics. No result is obtained by fitting a parameter to a subset of the paper's own data and then relabeling it a prediction, nor does any derivation reduce to a self-definition or a self-citation chain whose validity is presupposed inside the paper. The central claims rest on direct experimental comparison with external benchmarks rather than on any internal construction that would make the output equivalent to the input by definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The ReDial dataset splits and ground-truth definitions used in the original papers are the appropriate reference points for re-evaluation.
Reference graph
Works this paper leans on
-
[1]
Nolwenn Bernard and Krisztian Balog. 2025. Limitations of Current Evaluation Practices for Conversational Recommender Systems and the Potential of User Simulation. InProceedings of the 2025 Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region (SIGIR-AP ’25). 261–271. arXiv:2510.05624
-
[2]
Qibin Chen, Junyang Lin, Yichang Zhang, Ming Ding, Yukuo Cen, Hongxia Yang, and Jie Tang. 2019. Towards Knowledge-Based Recommender Dialog System. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Pro- cessing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) (EMNLP ’19). 1803–1813
work page 2019
-
[3]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Maurizio Ferrari Dacrema, Simone Boglio, Paolo Cremonesi, and Dietmar Jannach
-
[5]
A Troubling Analysis of Reproducibility and Progress in Recommender Systems Research.ACM Trans. Inf. Syst.39, 2 (2021), 20:1–20:49
work page 2021
-
[6]
Shirley Anugrah Hayati, Dongyeop Kang, Qingxiaoyang Zhu, Weiyan Shi, and Zhou Yu. 2020. INSPIRED: Toward Sociable Recommendation Dialog Systems. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (EMNLP ’20). 8142–8152
work page 2020
-
[7]
Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian Mcauley. 2023. Large Language Models as Zero-Shot Conversational Recommenders. InProceedings of the 32nd ACM International Conference on Information and Knowledge Manage- ment (CIKM ’23). 720–730
work page 2023
-
[8]
Dietmar Jannach. 2022. Evaluating conversational recommender systems: A landscape of research.Artificial Intelligence Review(2022)
work page 2022
-
[9]
Dongyeop Kang, Anusha Balakrishnan, Pararth Shah, Paul Crook, Y-Lan Boureau, and Jason Weston. 2019. Recommendation as a Communication Game: Self- Supervised Bot-Play for Goal-oriented Dialogue. InProceedings of the 2019 Con- ference on Empirical Methods in Natural Language Processing and the 9th Interna- tional Joint Conference on Natural Language Proces...
work page 2019
-
[10]
Raymond Li, Samira Ebrahimi Kahou, Hannes Schulz, Vincent Michalski, Laurent Charlin, and Chris Pal. 2018. Towards Deep Conversational Recommendations. InAdvances in Neural Information Processing Systems (NIPS ’18, Vol. 31)
work page 2018
-
[11]
Tingting Liang, Chenxin Jin, Lingzhi Wang, Wenqi Fan, Congying Xia, Kai Chen, and Yuyu Yin. 2024. LLM-REDIAL: A Large-Scale Dataset for Conversational Recommender Systems Created from User Behaviors with LLMs. InFindings of the Association for Computational Linguistics: ACL 2024 (Findings ’24). 8926–8939
work page 2024
-
[12]
Zeming Liu, Haifeng Wang, Zheng-Yu Niu, Hua Wu, and Wanxiang Che. 2021. DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP ’21). 4335–4347
work page 2021
-
[13]
Mathieu Ravaut, Hao Zhang, Lu Xu, Aixin Sun, and Yong Liu. 2024. Parameter- Efficient Conversational Recommender System as a Language Processing Task. InProceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) (EACL ’24). 152–165
work page 2024
- [14]
-
[15]
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. 2022. Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22). 1929–1937
work page 2022
-
[16]
Bowen Yang, Cong Han, Yu Li, Lei Zuo, and Zhou Yu. 2022. Improving Con- versational Recommendation Systems’ Quality with Context-Aware Item Meta- Information. InFindings of the Association for Computational Linguistics: NAACL 2022 (NAACL ’22). 38–48
work page 2022
-
[17]
Ting Yang and Li Chen. 2024. Unleashing the Retrieval Potential of Large Lan- guage Models in Conversational Recommender Systems. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). 43–52
work page 2024
-
[18]
Xiaoyu Zhang, Ruobing Xie, Yougang Lyu, Xin Xin, Pengjie Ren, Mingfei Liang, Bo Zhang, Zhanhui Kang, Maarten de Rijke, and Zhaochun Ren. 2024. Towards Empathetic Conversational Recommender Systems. InProceedings of the 18th ACM Conference on Recommender Systems (RecSys ’24). 84–93
work page 2024
-
[19]
Kun Zhou, Xiaolei Wang, Yuanhang Zhou, Chenzhan Shang, Yuan Cheng, Wayne Xin Zhao, Yaliang Li, and Ji-Rong Wen. 2021. CRSLab: An Open-Source Toolkit for Building Conversational Recommender System. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Proces...
work page 2021
-
[20]
Kun Zhou, Wayne Xin Zhao, Shuqing Bian, Yuanhang Zhou, Ji-Rong Wen, and Jingsong Yu. 2020. Improving Conversational Recommender Systems via Knowl- edge Graph based Semantic Fusion. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD ’20). 1006– 1014
work page 2020
-
[21]
Kun Zhou, Yuanhang Zhou, Wayne Xin Zhao, Xiaoke Wang, and Ji-Rong Wen
-
[22]
InProceed- ings of the 28th International Conference on Computational Linguistics (COLING ’20)
Towards Topic-Guided Conversational Recommender System. InProceed- ings of the 28th International Conference on Computational Linguistics (COLING ’20). 4128–4139
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.