Recognition: unknown
Neural QAOA²: Differentiable Joint Graph Partitioning and Parameter Initialization for Quantum Combinatorial Optimization
Pith reviewed 2026-05-14 19:07 UTC · model grok-4.3
The pith
A neural generator learns graph partitions and QAOA starting parameters together by back-propagating through a differentiable quantum evaluator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By coupling a generative evaluative network to a differentiable quantum evaluator, the framework jointly optimizes graph partitions and QAOA initial parameters so that the learned mapping from topology to configuration directly improves the quantum objective; this produces partitions and angles that outperform separate heuristic partitioning followed by standard initialization on the majority of tested instances and generalizes zero-shot to unseen graph sizes and structures.
What carries the argument
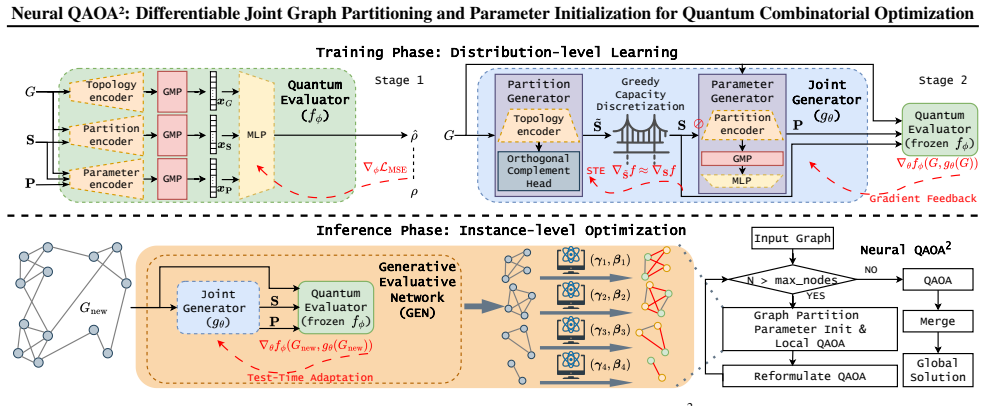
The generative evaluative network (GEN) that outputs both a graph partition and QAOA parameter vector, trained by gradients flowing through a differentiable quantum evaluator that acts as a high-fidelity performance surrogate.
If this is right
- Partitioning decisions become aligned with the actual QAOA cost landscape rather than proxy graph metrics.
- Initial parameter choices become instance-specific and topology-aware instead of cold-started.
- The same trained generator can be applied to new graphs without re-running heuristics or tuning.
- Overall QAOA solution quality improves on problems where divide-and-conquer is required.
Where Pith is reading between the lines
- The approach could be applied to other variational quantum algorithms that currently rely on manual decomposition.
- Learned partition patterns might identify structural features that correlate with quantum advantage on particular graph families.
- If the evaluator is replaced by a noisy hardware surrogate, the method could serve as a training loop for real-device parameter and partition selection.
Load-bearing premise
The differentiable quantum evaluator supplies sufficiently accurate gradients to steer the joint generator toward high-quality partitions and parameters.
What would settle it
Replacing the learned partitions with those from the best non-differentiable heuristic while keeping the learned parameters fixed, then measuring whether the performance gap disappears or reverses, would falsify the necessity of the joint differentiable training.
Figures




read the original abstract
The quantum approximate optimization algorithm (QAOA) holds promise for combinatorial optimization but is constrained by limited qubits. While divide-and-conquer frameworks like QAOA$^{2}$ address scalability by partitioning graphs into subgraphs, existing methods suffer from two fundamental limitations: i) misalignment between heuristic partitioning metrics and quantum optimization goals, and ii) topology-blind parameter initialization that leads to optimization cold starts. To bridge these gaps, we propose Neural QAOA$^{2}$, an end-to-end differentiable framework that jointly generates graph partitions and initial parameters. By integrating a generative evaluative network (GEN), our method utilizes a differentiable quantum evaluator as a high-fidelity performance surrogate to provide direct gradient guidance, enabling the joint generator to learn the intrinsic mapping from graph topology to high-quality partition and parameter configurations. Extensive experiments on 183 QUBO, Ising, and MaxCut instances (21 to 1000 variables) demonstrate that our gradient-driven approach broadly outperforms heuristic baselines, ranking first on 101 instances. It exhibits zero-shot generalization across out-of-distribution graph topologies and scales.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
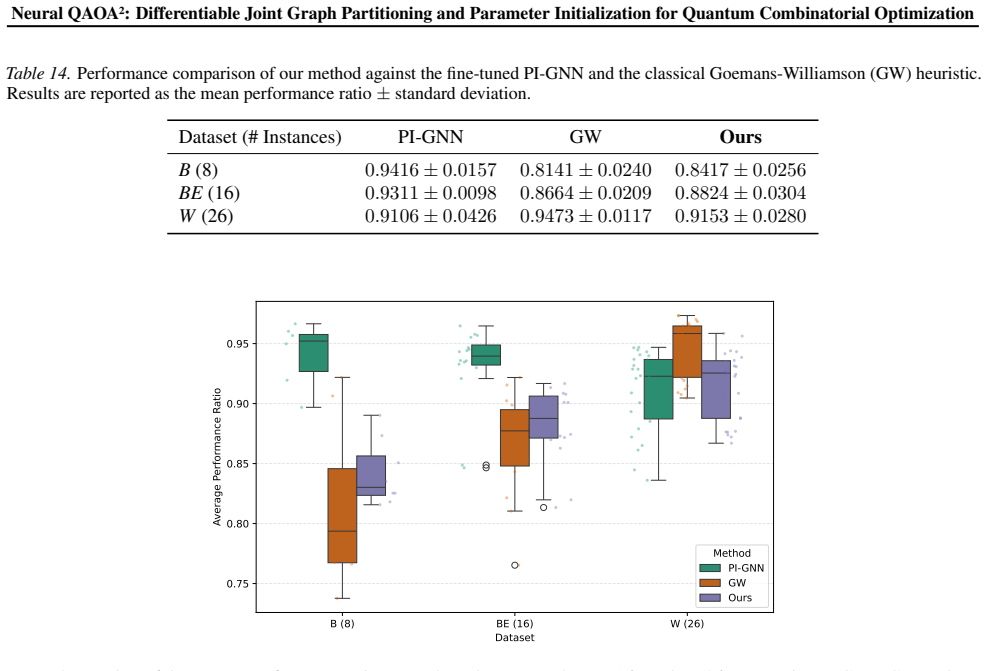
Summary. The paper introduces Neural QAOA², an end-to-end differentiable framework that uses a Generative Evaluative Network (GEN) together with a differentiable quantum evaluator surrogate to jointly learn graph partitions and QAOA parameter initializations for combinatorial optimization problems (QUBO, Ising, MaxCut). Experiments on 183 instances (21–1000 variables) report that the method ranks first on 101 instances and exhibits zero-shot generalization to out-of-distribution topologies and scales.
Significance. If the surrogate fidelity claim holds, the approach would provide a principled way to align partitioning metrics with downstream QAOA performance and to remove cold-start issues in parameter initialization, potentially improving scalability of QAOA on larger graphs. The scale of the experimental suite (183 instances) and the reported zero-shot generalization are notable strengths.
major comments (2)
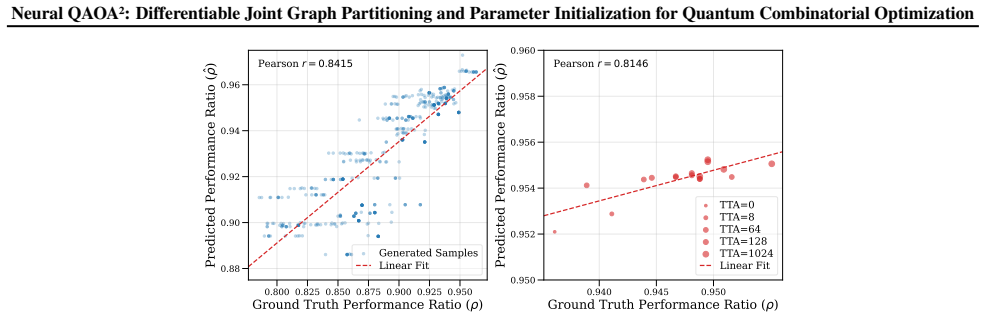
- [Abstract / Methods] Abstract and Methods: The central claim that the differentiable quantum evaluator supplies accurate gradient guidance rests on the unverified assumption that its expectation values and derivatives closely track true QAOA outcomes after partitioning. No explicit fidelity comparison (e.g., correlation plots or error metrics between surrogate and full QAOA on the 21–1000 variable instances) is provided, leaving open the possibility that the learned mappings optimize for an incorrect objective.
- [Results] Results section: The claim of ranking first on 101 of 183 instances is presented without error bars, statistical significance tests, or ablation studies that isolate the contribution of the joint differentiable training versus the surrogate alone. Baseline implementation details (e.g., exact hyperparameter settings for the heuristic partitioners) are also omitted, making it difficult to assess whether the reported outperformance is robust.
minor comments (2)
- [Introduction] Notation: The acronym GEN is introduced without an explicit expansion on first use in the main text.
- [Results] Figure clarity: Performance tables would benefit from explicit column headers indicating whether reported values are means over multiple random seeds or single-run results.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which have helped us identify areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that enhance clarity, rigor, and reproducibility without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The central claim that the differentiable quantum evaluator supplies accurate gradient guidance rests on the unverified assumption that its expectation values and derivatives closely track true QAOA outcomes after partitioning. No explicit fidelity comparison (e.g., correlation plots or error metrics between surrogate and full QAOA on the 21–1000 variable instances) is provided, leaving open the possibility that the learned mappings optimize for an incorrect objective.
Authors: We appreciate this observation on the need for explicit validation of the surrogate. The differentiable quantum evaluator is a neural network trained to approximate QAOA expectation values and their gradients on partitioned subgraphs, with training data generated from exact QAOA simulations on representative instances. While the main text emphasizes its role as a high-fidelity surrogate enabling end-to-end differentiability, we acknowledge that direct fidelity metrics (e.g., Pearson correlation or mean absolute error between surrogate and full QAOA outputs) across the full range of 21–1000 variables were not reported. In the revised manuscript, we will include these comparisons on a representative subset of instances, along with derivative accuracy checks, to substantiate the gradient guidance. revision: yes
-
Referee: [Results] Results section: The claim of ranking first on 101 of 183 instances is presented without error bars, statistical significance tests, or ablation studies that isolate the contribution of the joint differentiable training versus the surrogate alone. Baseline implementation details (e.g., exact hyperparameter settings for the heuristic partitioners) are also omitted, making it difficult to assess whether the reported outperformance is robust.
Authors: We agree that additional statistical details and controls would strengthen the results section. The reported ranking derives from mean performance across multiple independent runs per instance, but error bars, confidence intervals, and formal significance tests (such as paired Wilcoxon tests) were omitted to maintain conciseness. We will add these elements, together with ablation studies that separately evaluate the joint training objective versus surrogate-only optimization. Exact hyperparameter configurations for all heuristic baselines (e.g., METIS, spectral partitioning, and random initialization) will also be documented in the revised text and supplementary material to support reproducibility. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents an empirical ML framework that trains a joint generator using gradients from a differentiable quantum evaluator surrogate, then reports ranking on 101 of 183 benchmark instances via external evaluation against heuristic baselines. No equations, self-citations, or ansatzes are shown that reduce the reported outperformance or zero-shot generalization to a fitted constant or self-defined quantity by construction. The central performance claims rest on held-out instance testing rather than tautological re-expression of training inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- GEN network weights and hyperparameters
axioms (1)
- domain assumption The differentiable quantum evaluator provides a faithful gradient signal that correlates with true QAOA performance on the target instances.
invented entities (1)
-
Generative Evaluative Network (GEN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
We collect all applicants for partitionjinto a candidate setU j
Candidate selection: In round l, any unassigned node i applies to its l-th preferred partition j=r i,l. We collect all applicants for partitionjinto a candidate setU j
-
[2]
• If|U j| ≤C (j) remain, all candidates are accepted
Conflict resolution: We check the remaining capacity of partitionj, denoted asC (j) remain. • If|U j| ≤C (j) remain, all candidates are accepted. 14 Neural QAOA²: Differentiable Joint Graph Partitioning and Parameter Initialization for Quantum Combinatorial Optimization • If |Uj|> C (j) remain, we sort candidates by their confidence scores (probability va...
-
[3]
weakly-coupled
State update: Accepted nodes are locked into partition j. Rejected nodes remain unassigned and automatically proceed to roundl+ 1to attempt their next preferred partition. Complexity Analysis and Parallel Efficiency.We acknowledge that the theoretical worst-case complexity of GCD is dominated by the conflict resolution in Phase 2. In a pathological scenar...
2013
-
[4]
These features are standardized (zero mean, unit variance) within each graph instance to handle variations in graph scale
Node feature extraction: As detailed in Appendix A.3, we extract 5 structural features for each node. These features are standardized (zero mean, unit variance) within each graph instance to handle variations in graph scale
-
[5]
Edge weight normalization: Edge weights are normalized by the maximum absolute weight in the graph, ensuring wij ∈[−1,1]. Construction of the Offline Dataset (Doffline).To pre-train the quantum evaluator fϕ, we constructed a labeled dataset consisting of 52587 triplets (Gi,S i,P i) and their corresponding performance labels ρi. Crucially, this process rel...
-
[6]
For each graph Gi, we generated partitions using a mixture of random, modularity, boundary, and KL heuristics
Partition sampling (Si): To prevent the evaluator from overfitting to a specific partitioning logic, we employed a diverse sampling strategy. For each graph Gi, we generated partitions using a mixture of random, modularity, boundary, and KL heuristics. Each heuristic was executed independently 70 times per graph, with duplicate partitions removed to ensur...
-
[7]
Parameter sampling (Pi): QAOA parameters (γ,β) were sampled uniformly from [0,2π) to ensure the evaluator learns the landscape across the full parameter space
-
[8]
The entire offline data collection process was completed within approximately two days
Ground-truth label generation ( ρi): The ground-truth performance labels were obtained by executing the QAOA 2 simulation using the configuration (Gi,S i,P i). The entire offline data collection process was completed within approximately two days. B.3. Baseline Implementation To benchmark the effectiveness of Neural QAOA2, we compare it against four repre...
2023
-
[9]
Initialization: A preliminary partition is generated using standard community detection (e.g., Louvain algorithm)
-
[10]
Kernighan-Lin (KL) Algorithm.The KL algorithm (Kernighan & Lin, 1970) is a classic heuristic for graph bisection that minimizes the edge cut weight
Refinement: A dedicated optimization routine iteratively moves vertices between partitions to minimize the count of boundary nodes while respecting the size constraint. Kernighan-Lin (KL) Algorithm.The KL algorithm (Kernighan & Lin, 1970) is a classic heuristic for graph bisection that minimizes the edge cut weight. Starting from an initial random bisecti...
1970
-
[11]
Partitioning: IfN (l) >max nodes, the graph is partitioned intok (l) subgraphs, satisfyingk (l) ≥ ⌈N (l)/max nodes⌉
-
[12]
This constitutes k(l) quantum circuit simulation calls at levell
Subproblem solving: Each of the k(l) subgraphs is solved independently via QAOA. This constitutes k(l) quantum circuit simulation calls at levell
-
[13]
Reformulating (recursion step): The solutions to these subgraphs determine the edge weights of a new reformulated graphG (l+1) which hasN (l+1) =k (l) nodes
-
[14]
The final graph is solved directly
Termination: This process repeats until the merged graph fits within the device, i.e., N(L) ≤max nodes. The final graph is solved directly. Quantitative Analysis of Calls.For a typical large-scale instance in our dataset (e.g.,N= 500) with max nodes= 10:
-
[15]
Partitioned intok (0) = 50subgraphs
Level 0 (original graph):N (0) = 500. Partitioned intok (0) = 50subgraphs. (50 calls)
-
[16]
Since 50>10 , it is partitioned into k(1) = 5subgraphs
Level 1 (first reformulated graph): The reformulated graph has size N(1) = 50. Since 50>10 , it is partitioned into k(1) = 5subgraphs. (5 calls)
-
[17]
Level 2 (final reformulated graph): The new reformulated graph has size N(2) = 5. Since 5≤10 , recursion terminates, and this graph is solved directly. (1 call). Total depth is 2 (excluding the base layer), and the total number of QAOA subproblem calls is 50 + 5 + 1 = 56. This hierarchical structure results in a recursion depth of O(logmax nodes N). Conse...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.