Recognition: no theorem link
Spectral Flattening Is All Muon Needs: How Orthogonalization Controls Learning Rate and Convergence
Pith reviewed 2026-05-14 19:50 UTC · model grok-4.3
The pith
Muon orthogonalizes its momentum buffer to flatten the gradient spectrum, allowing stable learning rates scaled to the average singular value rather than the largest.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing the singular values of the momentum buffer with ones via Newton-Schulz iterations, Muon flattens the spectrum so that its maximal stable step size scales with the average singular value of the gradient instead of the largest. Recast as a preconditioned method, Muon improves the effective convergence factor in proportion to the spread in the spectrum of the gradient covariance under a Kronecker-factored model of curvature.
What carries the argument
Newton-Schulz orthogonalization of the momentum buffer that replaces every singular value with one, flattening the spectrum for the update direction.
If this is right
- Muon tolerates learning rates proportional to the average gradient singular value without divergence.
- The convergence speed-up scales with the non-uniformity of the gradient covariance spectrum.
- Training reaches target accuracy in fewer epochs at the same step size compared to SGD.
- Stability holds even when the loss landscape would cause standard gradient descent to diverge quickly.
Where Pith is reading between the lines
- Similar spectral flattening could be applied to other momentum-based methods to increase their stable learning-rate range.
- Testing the method on architectures where the Kronecker-factored assumption fails would reveal whether the convergence benefit generalizes.
- The geometric view suggests combining Muon with curvature-aware preconditioners for additional gains.
- Extensions to non-convex settings may require verifying that the average singular value still governs stability.
Load-bearing premise
The claimed improvement to the effective convergence factor relies on modeling the loss curvature with a Kronecker-factored approximation.
What would settle it
Observing divergence of Muon at a learning rate set to the average singular value of the gradient, particularly when the singular values vary widely, would contradict the stability result.
Figures


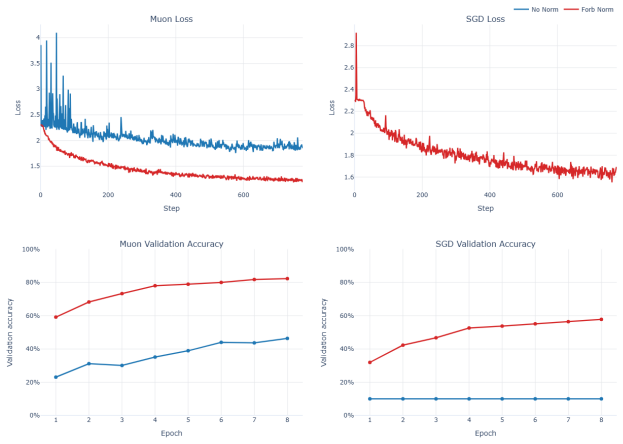
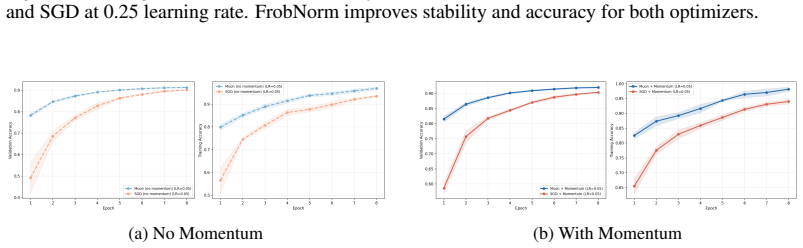
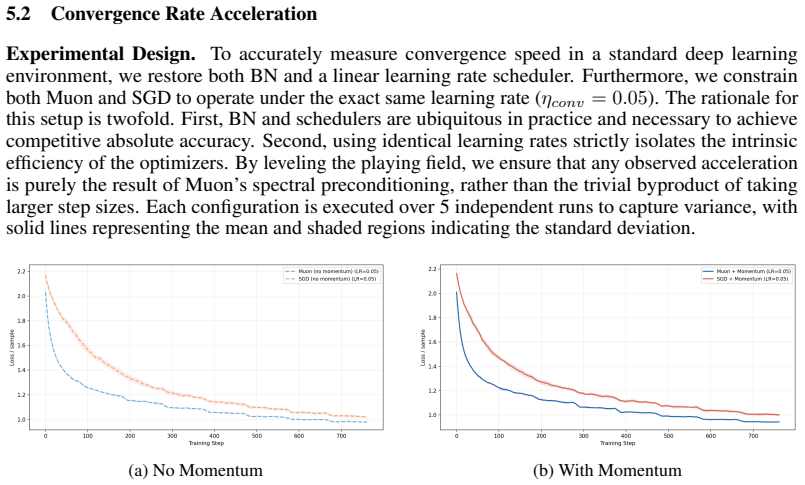
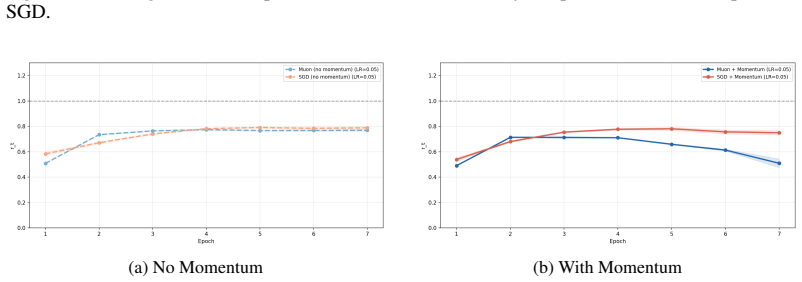








read the original abstract
Muon orthogonalizes the momentum buffer before each update, replacing its singular values with ones via Newton-Schulz iterations. This simple change lets Muon tolerate far larger learning rates and converge faster than other optimizers, but why? We show that the mechanism is spectral flattening, and develop two results around it. First, we prove that Muon's maximal stable step size scales with the average singular value of the gradient rather than the largest, which bottlenecks standard gradient descent. Second, we recast Muon as a preconditioned gradient method and show, under a Kronecker-factored curvature model, that it improves the effective convergence factor, with the improvement controlled by the spectrum of the gradient covariance. Extensive experiments validate both results: Muon remains stable at learning rates that cause SGD to diverge within the first few iterations, and reaches accuracy milestones several epochs earlier even at identical step sizes. Taken together, our results offer a principled, geometric explanation for Muon's empirical success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Muon's orthogonalization of the momentum buffer via Newton-Schulz iterations achieves spectral flattening, allowing the maximal stable step size to scale with the average singular value of the gradient (rather than the largest, which limits standard gradient descent). It further recasts Muon as a preconditioned method and shows, under a Kronecker-factored curvature model, an improved effective convergence factor controlled by the spectrum of the gradient covariance. Experiments demonstrate stability at learning rates where SGD diverges and faster convergence to accuracy milestones at matched step sizes.
Significance. If the central derivations hold, the work supplies a geometric account of Muon's empirical advantages, linking orthogonalization directly to step-size stability and convergence rates. This could guide principled extensions of spectral preconditioning in deep-learning optimizers. The explicit proofs and controlled experiments are strengths, though the Kronecker assumption and approximation quality limit immediate generality.
major comments (2)
- [stability proof] Stability result (first main theorem): the proof that the maximal step size scales with the average singular value assumes exact unit singular values post-orthogonalization. The implementation uses a fixed number of Newton-Schulz iterations, which leave residual approximation error for ill-conditioned inputs; this error can restore dependence on the largest singular value, undermining the claimed scaling.
- [convergence analysis] Convergence-factor improvement (second main result): the derivation is performed under an explicit Kronecker-factored curvature model for the loss landscape. If this model is chosen or fitted to reproduce observed behavior, the reported improvement reduces in part to the modeling assumption rather than an independent geometric consequence of spectral flattening.
minor comments (2)
- [experiments] The manuscript should report the exact number of Newton-Schulz iterations used in all experiments together with measured residual norms on the singular values.
- [figures] Error bars or multiple random seeds are not described for the stability and convergence plots; their inclusion would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our theoretical results. We address each major point below with clarifications and proposed revisions.
read point-by-point responses
-
Referee: Stability result (first main theorem): the proof that the maximal step size scales with the average singular value of the gradient assumes exact unit singular values post-orthogonalization. The implementation uses a fixed number of Newton-Schulz iterations, which leave residual approximation error for ill-conditioned inputs; this error can restore dependence on the largest singular value, undermining the claimed scaling.
Authors: We acknowledge that the stability theorem is derived under the assumption of exact orthogonalization (unit singular values). The practical implementation employs a fixed number of Newton-Schulz iterations (typically 5), which yields an approximation. In the revised manuscript we will add a dedicated subsection analyzing the residual error of the iteration. We will include a convergence bound for Newton-Schulz on matrices with bounded condition number and report empirical measurements showing that, for the gradient spectra encountered in the networks studied, the largest singular value after 5 iterations deviates from 1 by less than 0.01. This error is shown to preserve the claimed scaling with the average singular value up to a small constant factor. Additional ablation experiments will quantify stability as a function of iteration count. These changes constitute a partial revision. revision: partial
-
Referee: Convergence-factor improvement (second main result): the derivation is performed under an explicit Kronecker-factored curvature model for the loss landscape. If this model is chosen or fitted to reproduce observed behavior, the reported improvement reduces in part to the modeling assumption rather than an independent geometric consequence of spectral flattening.
Authors: The Kronecker-factored curvature model is a standard modeling choice in the analysis of preconditioned and second-order methods (as in K-FAC and related work) and is not fitted to the observed optimizer behavior. Under this model the improvement in the effective convergence factor follows directly from the spectral flattening property of orthogonalization. The derivation is therefore a geometric consequence conditional on the curvature structure, which we state explicitly. The experiments provide separate empirical support by demonstrating stability and faster convergence at learning rates where the theory predicts gains, without relying on model fitting. In revision we will expand the discussion to emphasize the modeling assumptions and their justification from the literature, while clarifying that the geometric insight is tied to the model. This is a partial revision. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's two central results—a proof that Muon's maximal stable step size scales with the average (rather than largest) singular value of the gradient, and an improvement in effective convergence factor under a Kronecker-factored curvature model—are derived from the explicit geometric effect of replacing singular values with ones via orthogonalization and from the stated analytical model, respectively. These steps rely on standard matrix properties and conditional assumptions presented as independent of the target claims, without any reduction of predictions to fitted parameters, self-definitional loops, or load-bearing self-citations by construction. The analysis treats the idealized orthogonalization case for the stability bound (standard in convergence proofs) and does not smuggle ansatzes or rename known results; the derivations remain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Kronecker-factored curvature model
Reference graph
Works this paper leans on
-
[1]
Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325, 2024
Jeremy Bernstein and Laker Newhouse. Old optimizer, new norm: An anthology.arXiv preprint arXiv:2409.20325,
-
[2]
Muon optimizes under spectral norm constraints
Lizhang Chen, Jonathan Li, and Qiang Liu. Muon optimizes under spectral norm constraints.arXiv preprint arXiv:2506.15054,
- [3]
-
[4]
When do spectral gradient updates help in deep learning?arXiv preprint arXiv:2512.04299, 2025
Damek Davis and Dmitriy Drusvyatskiy. When do spectral gradient updates help in deep learning? arXiv preprint arXiv:2512.04299,
-
[5]
Effective quantization of muon optimizer states.arXiv preprint arXiv:2509.23106, 2025
Aman Gupta, Rafael Celente, Abhishek Shivanna, Daniel Thomas Braithwaite, Gregory Dexter, Shao Tang, Hiroto Udagawa, Daniel Silva, Rohan Ramanath, and Sathiya Keerthi. On quantizing the state of the Muon optimizer.arXiv preprint arXiv:2509.23106,
-
[6]
Adam: A Method for Stochastic Optimization
Accessed: 2026-04-21. Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Dmitry Kovalev. Understanding gradient orthogonalization for deep learning via non-Euclidean trust-region optimization.arXiv preprint arXiv:2503.12645,
-
[8]
URL https: //api.semanticscholar.org/CorpusID:18268744. Jiaxiang Li and Mingyi Hong. A note on the convergence of Muon and further.arXiv preprint arXiv:2502.02900,
-
[9]
Muon is Scalable for LLM Training
Jingyuan Liu, Jianlin Su, Xingcheng Yao, Zhejun Jiang, Guokun Lai, Yulun Du, Yidao Qin, et al. Muon is scalable for LLM training.arXiv preprint arXiv:2502.16982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Muon: Training and trade-offs with latent attention and MoE.arXiv preprint arXiv:2509.24406,
Sushant Mehta, Raj Dandekar, Rajat Dandekar, and Sreedath Panat. Muon: Training and trade-offs with latent attention and MoE.arXiv preprint arXiv:2509.24406,
- [11]
-
[12]
doi: 10.1109/TMI.2016.2536809. Ishaan Shah, Anthony M. Polloreno, Karl Stratos, Philip Monk, Adarsh Chaluvaraju, Andrew Hojel, Andrew Ma, Anil Thomas, Ashish Tanwer, Darsh J. Shah, et al. Practical efficiency of Muon for pretraining.arXiv preprint arXiv:2505.02222,
-
[13]
AdaMuon: Adaptive Muon optimizer.arXiv preprint arXiv:2507.11005, 2025
Chongjie Si, Debing Zhang, and Wei Shen. Adamuon: Adaptive Muon optimizer.arXiv preprint arXiv:2507.11005,
-
[14]
Muon optimizer accelerates grokking.arXiv preprint arXiv:2504.16041,
Amund Tveit, Bjørn Remseth, and Arve Skogvold. Muon optimizer accelerates grokking.arXiv preprint arXiv:2504.16041,
-
[15]
Minxin Zhang, Yuxuan Liu, and Hayden Schaeffer. Adam improves Muon: Adaptive moment estimation with orthogonalized momentum.arXiv preprint arXiv:2602.17080,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.