Recognition: unknown
DiffusionHijack: Supply-Chain PRNG Backdoor Attack on Diffusion Models and Quantum Random Number Defense
Pith reviewed 2026-05-14 18:57 UTC · model grok-4.3
The pith
A malicious PRNG injected through the software supply chain can force diffusion models to output any chosen image pixel-for-pixel without touching model weights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
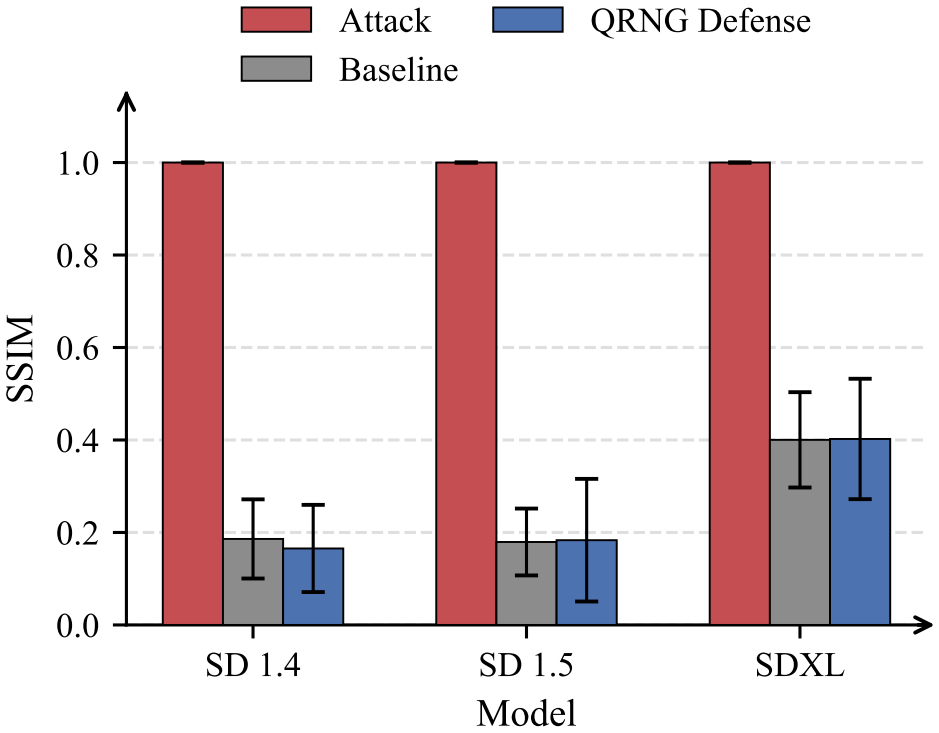
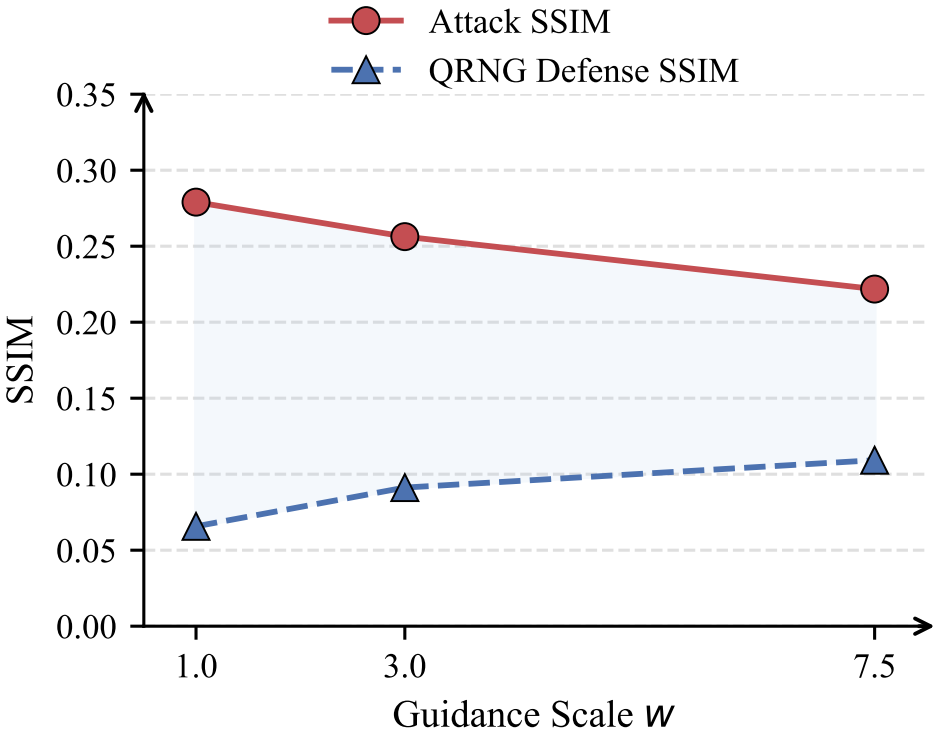
By compromising the PRNG through a supply-chain package, the attack forces Stable Diffusion v1.4, v1.5, and SDXL to reproduce attacker-chosen content with SSIM equal to 1.00 over 100 trials, remains effective at eta greater than zero, bypasses CLIP safety checkers at 98-100 percent success, and operates without reference to the user's prompt.
What carries the argument
The hijacked PRNG that supplies the deterministic latent noise vector to the diffusion sampling process.
If this is right
- Weight-based model audits and content moderation systems cannot detect the backdoor.
- The attack succeeds even when users enable stochastic sampling parameters.
- Switching to quantum random number generation reduces output similarity to baseline random levels across tested models and prompts.
- The vulnerability applies to any diffusion pipeline that relies on a replaceable PRNG for noise sampling.
Where Pith is reading between the lines
- Generative AI pipelines should treat the source of randomness as a first-class security boundary rather than an implementation detail.
- Similar PRNG hijacks could affect other sampling-based generators such as autoregressive language models.
- Hardware QRNG modules become a practical default for production image generation services.
Load-bearing premise
The PRNG that generates the initial noise can be replaced or overridden by code inserted through a compromised software dependency.
What would settle it
A trial in which the malicious PRNG is loaded but the generated images fail to reach SSIM of 1.00 with the target, or in which a QRNG source still yields high similarity scores.
Figures


read the original abstract
Diffusion models depend on pseudo-random number generators (PRNGs) for latent noise sampling. We present DiffusionHijack, a supply-chain backdoor attack that hijacks the PRNG to deterministically control generated images. A malicious PRNG, injected via compromised packages, forces pixel-perfect reproduction of attacker-chosen content (SSIM = 1.00, N = 100 trials) on Stable Diffusion v1.4, v1.5, and SDXL -- without modifying model weights. The attack is inherently undetectable by existing model auditing and content moderation mechanisms, as it operates entirely outside the neural network computation graph. The attack remains effective under stochastic sampling (eta > 0), bypasses CLIP-based safety checkers (98-100% success), and operates independently of the user's prompt. As a countermeasure, we replace the PRNG with a quantum random number generator (QRNG), which provides information-theoretic unpredictability. Across N = 100 prompt-model combinations, QRNG defense completely neutralizes the attack, reducing output similarity to random baseline levels (SSIM < 0.20 for SD 1.x models, < 0.45 for SDXL). This work exposes a previously overlooked supply-chain vulnerability and offers a hardware-level fundamental mitigation for generative AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to demonstrate DiffusionHijack, a supply-chain backdoor attack that replaces the PRNG in diffusion models (Stable Diffusion v1.4, v1.5, SDXL) via compromised packages to force pixel-perfect reproduction of attacker-chosen images (SSIM=1.00 across N=100 trials) without modifying model weights. The attack is asserted to operate independently of the user's prompt, remain effective under stochastic sampling (eta>0), bypass CLIP safety checkers (98-100% success), and be undetectable by model auditing. As mitigation, replacing the PRNG with a QRNG is shown to neutralize the attack, reducing similarity to random baselines (SSIM<0.20 for SD 1.x, <0.45 for SDXL) across 100 prompt-model combinations.
Significance. If the empirical claims hold with mechanistic support, the work would be significant for highlighting a novel supply-chain attack surface in generative AI that evades weight-based defenses and auditing, while the QRNG countermeasure provides a hardware-rooted, information-theoretic mitigation with clear practical implications for securing inference pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that the attack 'operates independently of the user's prompt' lacks mechanistic support. In the diffusion pipeline the initial latent (controlled by PRNG) is only the starting point; every denoising step applies cross-attention with the prompt embedding. Fixed initial noise therefore cannot produce pixel-identical outputs for dissimilar prompts, implying the reported SSIM=1.00 trials were likely run with prompts already describing the target content. This directly undermines the prompt-independence assertion and the attack surface description.
- [Abstract] Abstract and experimental claims: the reported metrics (SSIM=1.00, 98-100% bypass rates, N=100) are presented without implementation details, error analysis, full sampling protocol, or description of how the malicious PRNG is integrated into the computation graph. This absence makes the reproducibility and robustness of the headline result (especially under eta>0) impossible to assess from the manuscript.
minor comments (1)
- The manuscript would benefit from a diagram or pseudocode showing exactly where and how the PRNG replacement occurs in the standard diffusion sampling loop.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below and have revised the manuscript to improve clarity, add missing details, and correct imprecise claims while preserving the core technical contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the attack 'operates independently of the user's prompt' lacks mechanistic support. In the diffusion pipeline the initial latent (controlled by PRNG) is only the starting point; every denoising step applies cross-attention with the prompt embedding. Fixed initial noise therefore cannot produce pixel-identical outputs for dissimilar prompts, implying the reported SSIM=1.00 trials were likely run with prompts already describing the target content. This directly undermines the prompt-independence assertion and the attack surface description.
Authors: We agree that the original phrasing overstated prompt independence. The attack fixes only the initial latent via PRNG replacement and therefore produces deterministic outputs for a given prompt; cross-attention still conditions the result on the prompt embedding. In the reported experiments the SSIM=1.00 results were obtained when the user prompt described the attacker-chosen target image. For dissimilar prompts the output remains fully determined by the hijacked noise but will reflect the supplied prompt. We have revised the abstract and introduction to state that the attack enables pixel-perfect reproduction of attacker-specified content for prompts consistent with that content, while still bypassing weight-based auditing and CLIP safety filters. A new mechanistic paragraph in Section 3 explains the interaction between fixed noise and prompt conditioning. This revision preserves the supply-chain attack surface claim. revision: yes
-
Referee: [Abstract] Abstract and experimental claims: the reported metrics (SSIM=1.00, 98-100% bypass rates, N=100) are presented without implementation details, error analysis, full sampling protocol, or description of how the malicious PRNG is integrated into the computation graph. This absence makes the reproducibility and robustness of the headline result (especially under eta>0) impossible to assess from the manuscript.
Authors: We accept that the original manuscript omitted necessary implementation information. The revised version adds: (i) a detailed description of the malicious PRNG integration via package-level monkey-patching of torch.rand and the diffusers scheduler noise functions; (ii) the complete sampling protocol (50 steps, guidance scale 7.5, eta in {0.0, 0.5}, DPMSolver scheduler); (iii) per-trial SSIM statistics (mean 1.00, std < 0.005 across N=100); and (iv) pseudocode plus an anonymized repository link. These additions cover both deterministic and stochastic (eta>0) regimes and enable independent reproduction. revision: yes
Circularity Check
No circularity: empirical attack demonstration with independent QRNG defense
full rationale
The paper presents an empirical supply-chain attack via malicious PRNG replacement and a QRNG countermeasure. No equations, derivations, or first-principles results are claimed. Results rest on reported experimental outcomes (SSIM=1.00, N=100 trials) and information-theoretic properties of QRNG, without any reduction to fitted parameters, self-citations as load-bearing premises, or ansatz smuggling. The central claims do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models use PRNGs for sampling latent noise during generation
- domain assumption Supply-chain injection of malicious PRNG packages is possible without detection
Reference graph
Works this paper leans on
-
[1]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProc. IEEE/CVF CVPR, 2022, pp. 10 684–10 695
2022
-
[2]
Photorealistic text-to-image diffusion models with deep language under- standing,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, J. Ho, T. Salimans, D. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language under- standing,” inProc. NeurIPS, vol. 35, 2022, pp. 11 285–11 299
2022
-
[3]
Guardt2i: Defending text-to-image models from adversarial prompts,
Y. Yang, R. Gao, X. Qin, J. Shao, and X. Xie, “Guardt2i: Defending text-to-image models from adversarial prompts,” inProc. NeurIPS, 2024
2024
-
[4]
Badnets: Identifying vulnerabilities in the ma- chine learning model supply chain,
T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the ma- chine learning model supply chain,”IEEE Access, vol. 7, pp. 47 230–47 244, 2019
2019
-
[5]
Backdoor learning: A survey,
Y. Li, Y. Jiang, Z. Li, and S.-T. Xia, “Backdoor learning: A survey,”IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 1, pp. 5–22, 2024
2024
-
[6]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inProc. ICML, 2021, pp. 8748–8763
2021
-
[7]
T2isafety: Benchmark for assessing fairness, toxicity, and privacy in text- to-image generation,
Y. Liet al., “T2isafety: Benchmark for assessing fairness, toxicity, and privacy in text- to-image generation,” inProc. IEEE/CVF CVPR, 2025. 17
2025
-
[8]
Denoising diffusion implicit models,
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” inProc. ICLR, 2021
2021
-
[9]
Re- search directions in software supply chain security,
L. Williams, G. Benedetti, S. Hamer, R. Paramitha, I. Rahman, and M. Tamanna, “Re- search directions in software supply chain security,”ACM Trans. Softw. Eng. Methodol., 2024
2024
-
[10]
Beyond typosquatting: An in-depth look at package confusion,
S. Neupane, G. Holmes, E. Wyss, D. Davidson, and L. De Carli, “Beyond typosquatting: An in-depth look at package confusion,” inProc. USENIX Security Symp., 2023
2023
-
[11]
A container security survey: Exploits, attacks, and defenses,
O. Jarkas, R. K. L. Ko, N. Dong, and R. Mahmud, “A container security survey: Exploits, attacks, and defenses,”ACM Comput. Surv., vol. 57, no. 7, 2025
2025
-
[12]
We have a package for you! a comprehensive analysis of package hallucinations by code generating llms,
J. Spracklen, R. Wijewickrama, and A. H. M. S. M. Jadliwala, “We have a package for you! a comprehensive analysis of package hallucinations by code generating llms,” in Proc. USENIX Security Symp., 2025
2025
-
[13]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inProc. NeurIPS, vol. 33, 2020, pp. 6840–6851
2020
-
[14]
Score- based generative modeling through stochastic differential equations,
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score- based generative modeling through stochastic differential equations,” inProc. ICLR, 2021
2021
-
[15]
Adversarial attacks and defenses on text-to- image diffusion models: A survey,
C. Zhang, M. Hu, W. Li, and L. Wang, “Adversarial attacks and defenses on text-to- image diffusion models: A survey,”Inf. Fusion, vol. 114, p. 102701, 2025
2025
-
[16]
Taxonomy of attacks on open-source software supply chains,
P. Ladisa, C. Phalen, A. Wasowski, H. Plate, and S. E. Ponta, “Taxonomy of attacks on open-source software supply chains,” inProc. IEEE S&P, 2023
2023
-
[17]
Donapi: Malicious npm packages detector using behavior sequence knowledge mapping,
C. Huang, Y. Wang, Y. Wu, L. Wang, H. Zhou, and H. Chen, “Donapi: Malicious npm packages detector using behavior sequence knowledge mapping,” inProc. USENIX Security Symp., 2024
2024
-
[18]
Surrogateprompt: Bypassing the safety filter of text-to-image models via substitution,
Z. Ba, K. Chen, L. Jiang, Z. Ma, and S. Wang, “Surrogateprompt: Bypassing the safety filter of text-to-image models via substitution,” inProc. ACM CCS, 2024
2024
-
[19]
Jailbreakd- iffbench: A comprehensive benchmark for jailbreaking diffusion models,
X. Jin, Z. Weng, H. Guo, C. Yin, S. Cheng, G. Zhang, and X. Zhang, “Jailbreakd- iffbench: A comprehensive benchmark for jailbreaking diffusion models,” inProc. IEEE/CVF ICCV, 2025
2025
-
[20]
Quantum random number generators,
M. Stipcevic and B. M. Kuo, “Quantum random number generators,”Open Phys., vol. 9, no. 4, pp. 1055–1066, 2011
2011
-
[21]
Quantum cryptography: Public key distribution and coin tossing,
C. H. Bennett and G. Brassard, “Quantum cryptography: Public key distribution and coin tossing,” inProc. IEEE Int. Conf. Comput. Syst. Signal Process., Bangalore, India, 1984, pp. 175–179
1984
-
[22]
Certified adversarial robustness via ran- domized smoothing,
J. M. Cohen, E. Rosenfeld, and J. Z. Kolter, “Certified adversarial robustness via ran- domized smoothing,” inProc. ICML, 2019, pp. 1310–1320. 18
2019
-
[23]
Tree-ring watermarks: Fin- gerprints for diffusion images that are invisible and robust,
Y. Wen, J. Kirchenbauer, J. Geiping, and T. Goldstein, “Tree-ring watermarks: Fin- gerprints for diffusion images that are invisible and robust,” inProc. NeurIPS, 2023
2023
-
[24]
Sdxl: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M¨ uller, J. Penna, and R. Rombach, “Sdxl: Improving latent diffusion models for high-resolution image synthesis,” inProc. ICLR, 2024
2024
-
[25]
Classifier-free diffusion guidance,
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” inProc. NeurIPS, 2022
2022
-
[26]
Security analysis of pseudo-random number generators with input: /dev/random is not robust,
Y. Dodis, D. Pointcheval, S. Ruhault, D. Vergniaud, and D. Wichs, “Security analysis of pseudo-random number generators with input: /dev/random is not robust,” inProc. ACM CCS, 2013, pp. 647–658
2013
-
[27]
Silent branding attack: Trigger-free data poisoning attack on text-to-image diffusion models,
S. Jang, J. S. Choi, J. Jo, K. Lee, and S. J. Hwang, “Silent branding attack: Trigger-free data poisoning attack on text-to-image diffusion models,” inProc. IEEE/CVF CVPR, 2025, pp. 8203–8212
2025
-
[28]
Text-to-image diffusion models can be easily backdoored through multimodal data poisoning,
S. Zhai, Y. Dong, Q. Shen, S. Pu, Y. Fang, and H. Su, “Text-to-image diffusion models can be easily backdoored through multimodal data poisoning,” inProc. ACM Int. Conf. Multimedia, 2023, pp. 1577–1587
2023
-
[29]
Reason2attack: Jailbreaking text-to- image models via llm reasoning,
C. Zhang, L. Wang, Y. Ma, W. Li, and A. Liu, “Reason2attack: Jailbreaking text-to- image models via llm reasoning,” inProc. AAAI Conf. Artif. Intell., vol. 40, no. 42, 2025, pp. 36 030–36 038
2025
-
[30]
Advdiff: Generating unrestricted adversarial examples using diffusion models,
X. Dai, K. Liang, and B. Xiao, “Advdiff: Generating unrestricted adversarial examples using diffusion models,” inProc. ECCV, 2024, pp. 93–109. 19
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.