Recognition: unknown
Early Semantic Grounding in Image Editing Models for Zero-Shot Referring Image Segmentation
Pith reviewed 2026-05-14 19:39 UTC · model grok-4.3
The pith
Instruction-based image editing models show strong foreground-background separability in their earliest internal features, enabling zero-shot referring image segmentation from a single denoising step.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
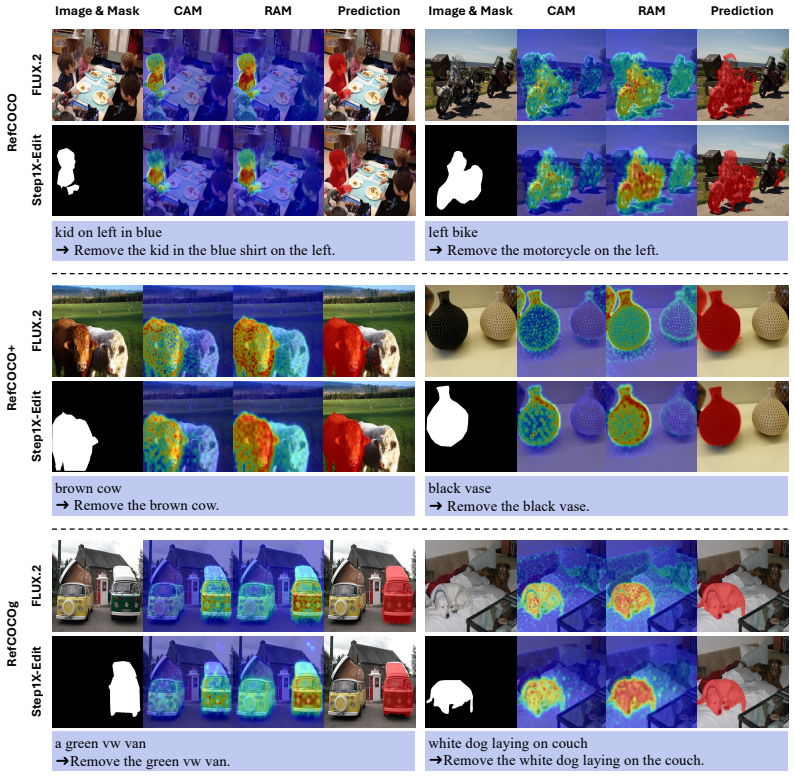
Strong foreground-background separability emerges in the internal representations of these models at the earliest denoising timestep, well before any visible image transformation occurs. This separability supports a training-free framework that decomposes localization into attention-based spatial priors and feature-based semantic discrimination, producing accurate segmentation masks from a single denoising step without full synthesis.
What carries the argument
Feature-space separability at the earliest denoising timestep, which supplies attention-based spatial priors for location and feature-based semantic discrimination for object identity.
If this is right
- Accurate referring segmentation masks can be generated using only a single denoising step without full image synthesis.
- The method achieves higher performance than existing zero-shot baselines on RefCOCO, RefCOCO+, and RefCOCOg.
- Localization decomposes cleanly into attention-driven spatial focus and feature-driven semantic separation.
- Pretrained editing models inherently encode language-conditioned visual grounding that can be read out directly.
Where Pith is reading between the lines
- Semantic understanding in diffusion-based editing models forms very early in the sampling trajectory rather than only at the end.
- The same early internal states could support other zero-shot localization tasks such as detection or referring expression comprehension.
- Reducing computation to one timestep suggests similar early-readout strategies may apply to other generative models for efficiency gains.
- The decomposition into spatial priors and semantic features may transfer to non-editing diffusion models without retraining.
Load-bearing premise
The feature-space separability observed at the earliest denoising timestep is sufficient to produce accurate pixel-level segmentation masks for arbitrary referring expressions without full synthesis or task-specific training.
What would settle it
If extracting masks from first-timestep features alone yields segmentation accuracy no better than random or existing zero-shot baselines on RefCOCO for complex referring expressions, the claim that early separability suffices would be falsified.
Figures



read the original abstract
Instruction-based image editing (IIE) models have recently demonstrated strong capability in modifying specific image regions according to natural language instructions, which implicitly requires identifying where an edit should be applied. This indicates that such models inherently perform language-conditioned visual semantic grounding. In this work, we investigate whether this implicit grounding can be leveraged for zero-shot referring image segmentation (RIS), a task that requires pixel-level localization of objects described by natural language expressions. Through systematic analysis, we reveal that strong foreground-background separability emerges in the internal representations of these models at the earliest denoising timestep, well before any visible image transformation occurs. Building on this insight, we propose a training-free framework that repurposes pretrained image editing models for RIS by exploiting their intermediate representations. Our approach decomposes localization into two complementary components: attention-based spatial priors that estimate where to focus, and feature-based semantic discrimination that determines what to segment. By leveraging feature-space separability, the framework produces accurate segmentation masks using only a single denoising step, without requiring full image synthesis. Extensive experiments on RefCOCO, RefCOCO+, and RefCOCOg demonstrate that our method achieves superior performance over existing zero-shot baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that instruction-based image editing (IIE) models implicitly perform language-conditioned visual semantic grounding, which can be leveraged for zero-shot referring image segmentation (RIS). It observes that strong foreground-background separability emerges in internal representations at the earliest denoising timestep, before visible changes. A training-free framework is proposed that decomposes localization into attention-based spatial priors and feature-based semantic discrimination, producing accurate masks from a single denoising step. Experiments on RefCOCO, RefCOCO+, and RefCOCOg show superior performance over existing zero-shot baselines.
Significance. If the result holds, the work provides evidence of emergent semantic grounding in diffusion-based editing models and offers an efficient, training-free route to zero-shot RIS. This could advance understanding of early-stage representations in generative models and reduce reliance on full synthesis or task-specific fine-tuning for localization tasks.
major comments (3)
- [Framework description (likely §3)] Framework description (likely §3): The central claim that single-timestep feature separability suffices for pixel-accurate masks requires explicit detail on the aggregation and thresholding procedure that converts attention priors plus feature discrimination into final binary masks; without this, it is unclear whether the method avoids implicit tuning or full synthesis.
- [Experiments section] Experiments section: The abstract asserts superior benchmark performance, yet no quantitative metrics, tables, or ablation results are referenced here; the separability claim at the earliest timestep must be supported by concrete scores (e.g., foreground-background cosine similarity or IoU at t=1) to substantiate emergence before visible transformation.
- [Ablation studies (likely §4.3)] Ablation studies (likely §4.3): To address the sufficiency concern, the paper must include an ablation removing the attention-based spatial priors and reporting performance using only feature-based discrimination; if performance drops sharply, the separability observation alone does not carry the full load-bearing claim.
minor comments (2)
- [Figure 1 or visualization section] Figure 1 or visualization section: Timestep labels and feature-map scales should be added for clarity when showing internal representations at the earliest denoising step.
- [Related work] Related work: Ensure citations to recent zero-shot RIS baselines (e.g., CLIP-based or diffusion segmentation methods) are complete and up-to-date.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped us strengthen the clarity and empirical support in our manuscript. We address each major comment below and have revised the paper accordingly.
read point-by-point responses
-
Referee: Framework description (likely §3): The central claim that single-timestep feature separability suffices for pixel-accurate masks requires explicit detail on the aggregation and thresholding procedure that converts attention priors plus feature discrimination into final binary masks; without this, it is unclear whether the method avoids implicit tuning or full synthesis.
Authors: We agree that additional detail is warranted for reproducibility. In the revised manuscript, Section 3 now explicitly describes the procedure: attention-based spatial priors are obtained by averaging cross-attention maps across relevant layers and heads followed by softmax normalization; these are combined with feature-based semantic discrimination via cosine similarity between the instruction embedding and the t=1 denoised features. The final binary mask is produced by applying a threshold (determined via Otsu's method on the similarity distribution) to the combined map. The entire process remains training-free and does not rely on full synthesis or implicit tuning. revision: yes
-
Referee: Experiments section: The abstract asserts superior benchmark performance, yet no quantitative metrics, tables, or ablation results are referenced here; the separability claim at the earliest timestep must be supported by concrete scores (e.g., foreground-background cosine similarity or IoU at t=1) to substantiate emergence before visible transformation.
Authors: We acknowledge the need for explicit quantitative backing in support of the separability claim. The revised manuscript augments the experiments section with concrete metrics, including foreground-background cosine similarity and IoU scores computed at t=1 (prior to any visible image change), along with references to the main results tables. These additions directly substantiate the emergence of separability at the earliest denoising step while preserving the abstract's summary nature. revision: yes
-
Referee: Ablation studies (likely §4.3): To address the sufficiency concern, the paper must include an ablation removing the attention-based spatial priors and reporting performance using only feature-based discrimination; if performance drops sharply, the separability observation alone does not carry the full load-bearing claim.
Authors: We have performed the requested ablation and included the results in the revised Section 4.3. Removing the attention-based spatial priors and relying solely on feature-based discrimination yields a substantial performance drop across RefCOCO, RefCOCO+, and RefCOCOg. This confirms that both components are required to fully exploit the observed early separability and supports the design of the proposed framework. revision: yes
Circularity Check
No circularity: empirical observation of separability drives training-free framework
full rationale
The paper's derivation begins with a systematic empirical analysis revealing foreground-background separability in internal representations at the earliest denoising timestep of pretrained image editing models. This observation is then used to construct a training-free decomposition into attention-based spatial priors and feature-based semantic discrimination for zero-shot referring image segmentation. No steps reduce by construction to fitted parameters, self-definitional loops, or load-bearing self-citations; the framework exploits the observed property without renaming known results or smuggling ansatzes via prior author work. The central claim remains independent of the target task quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instruction-based image editing models inherently perform language-conditioned visual semantic grounding
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[3]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Dvin: Dynamic visual routing network for weakly supervised referring expression comprehension
Xiaofu Chen, Yaxin Luo, Gen Luo, Jiayi Ji, Henghui Ding, and Yiyi Zhou. Dvin: Dynamic visual routing network for weakly supervised referring expression comprehension. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 14347–14357, 2025
2025
-
[6]
Weakmcn: Multi-task collaborative network for weakly supervised referring expression comprehension and segmentation
Silin Cheng, Yang Liu, Xinwei He, Sebastien Ourselin, Lei Tan, and Gen Luo. Weakmcn: Multi-task collaborative network for weakly supervised referring expression comprehension and segmentation. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 9175–9185, 2025
2025
-
[7]
Mask grounding for referring image segmentation
Yong Xien Chng, Henry Zheng, Yizeng Han, Xuchong Qiu, and Gao Huang. Mask grounding for referring image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26573–26583, 2024
2024
-
[8]
Ming Dai, Wenxuan Cheng, Jiang-jiang Liu, Sen Yang, Wenxiao Cai, Yanpeng Sun, and Wankou Yang. Deris: Decoupling perception and cognition for enhanced referring image segmentation through loopback synergy.arXiv preprint arXiv:2507.01738, 2025
-
[9]
Curriculum point prompting for weakly-supervised referring image segmenta- tion
Qiyuan Dai and Sibei Yang. Curriculum point prompting for weakly-supervised referring image segmenta- tion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13711–13722, 2024
2024
-
[10]
The use of multiple measurements in taxonomic problems.Annals of eugenics, 7(2): 179–188, 1936
Ronald A Fisher. The use of multiple measurements in taxonomic problems.Annals of eugenics, 7(2): 179–188, 1936
1936
-
[11]
Chaofan Gan, Yuanpeng Tu, Xi Chen, Tieyuan Chen, Yuxi Li, Mehrtash Harandi, and Weiyao Lin. Unleashing diffusion transformers for visual correspondence by modulating massive activations.arXiv preprint arXiv:2505.18584, 2025
-
[12]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[13]
Segmentation from natural language expressions
Ronghang Hu, Marcus Rohrbach, and Trevor Darrell. Segmentation from natural language expressions. In European conference on computer vision, pages 108–124. Springer, 2016
2016
-
[14]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[15]
Refam: Attention magnets for zero-shot referral segmentation.arXiv preprint arXiv:2509.22650, 2025
Anna Kukleva, Enis Simsar, Alessio Tonioni, Muhammad Ferjad Naeem, Federico Tombari, Jan Eric Lenssen, and Bernt Schiele. Refam: Attention magnets for zero-shot referral segmentation.arXiv preprint arXiv:2509.22650, 2025
-
[16]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[17]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[18]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[19]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Rotated multi-scale interaction network for referring remote sensing image segmentation
Sihan Liu, Yiwei Ma, Xiaoqing Zhang, Haowei Wang, Jiayi Ji, Xiaoshuai Sun, and Rongrong Ji. Rotated multi-scale interaction network for referring remote sensing image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26658–26668, 2024
2024
-
[21]
Hybrid global-local representation with augmented spatial guidance for zero-shot referring image segmentation
Ting Liu and Siyuan Li. Hybrid global-local representation with augmented spatial guidance for zero-shot referring image segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29634–29643, 2025
2025
-
[22]
Random walks on graphs.Combinatorics, Paul erdos is eighty, 2(1-46):4, 1993
László Lovász. Random walks on graphs.Combinatorics, Paul erdos is eighty, 2(1-46):4, 1993
1993
-
[23]
Generation and comprehension of unambiguous object descriptions
Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 11–20, 2016
2016
-
[24]
Modeling context between objects for referring expression understanding
Varun K Nagaraja, Vlad I Morariu, and Larry S Davis. Modeling context between objects for referring expression understanding. InEuropean Conference on Computer Vision, pages 792–807. Springer, 2016
2016
-
[25]
Minheng Ni, Yabo Zhang, Kailai Feng, Xiaoming Li, Yiwen Guo, and Wangmeng Zuo. Ref-diff: Zero-shot referring image segmentation with generative models.arXiv preprint arXiv:2308.16777, 2023
-
[26]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[28]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[29]
Learning affinity from attention: End-to-end weakly- supervised semantic segmentation with transformers
Lixiang Ru, Yibing Zhan, Baosheng Yu, and Bo Du. Learning affinity from attention: End-to-end weakly- supervised semantic segmentation with transformers. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16846–16855, 2022
2022
-
[30]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618–626, 2017
2017
-
[31]
Lqmformer: Language-aware query mask transformer for referring image segmentation
Nisarg A Shah, Vibashan VS, and Vishal M Patel. Lqmformer: Language-aware query mask transformer for referring image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12903–12913, 2024
2024
-
[32]
Prompt-driven referring image segmentation with instance contrasting
Chao Shang, Zichen Song, Heqian Qiu, Lanxiao Wang, Fanman Meng, and Hongliang Li. Prompt-driven referring image segmentation with instance contrasting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4124–4134, 2024
2024
-
[33]
Clip as rnn: Segment countless visual concepts without training endeavor
Shuyang Sun, Runjia Li, Philip Torr, Xiuye Gu, and Siyang Li. Clip as rnn: Segment countless visual concepts without training endeavor. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13171–13182, 2024
2024
-
[34]
Yucheng Suo, Linchao Zhu, and Yi Yang. Text augmented spatial-aware zero-shot referring image segmentation.arXiv preprint arXiv:2310.18049, 2023
-
[35]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025
2025
-
[36]
Longcat-image technical report
Meituan LongCat Team, Hanghang Ma, Haoxian Tan, Jiale Huang, Junqiang Wu, Jun-Yan He, Lishuai Gao, Songlin Xiao, Xiaoming Wei, Xiaoqi Ma, et al. Longcat-image technical report.arXiv preprint arXiv:2512.07584, 2025
-
[37]
Learning visual grounding from generative vision and language model
Shijie Wang, Dahun Kim, Ali Taalimi, Chen Sun, and Weicheng Kuo. Learning visual grounding from generative vision and language model. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 8057–8067. IEEE, 2025
2025
-
[38]
Freesolo: Learning to segment objects without annotations
Xinlong Wang, Zhiding Yu, Shalini De Mello, Jan Kautz, Anima Anandkumar, Chunhua Shen, and Jose M Alvarez. Freesolo: Learning to segment objects without annotations. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14176–14186, 2022. 11
2022
-
[39]
Iterprime: Zero-shot referring image segmentation with iterative grad-cam refinement and primary word emphasis
Yuji Wang, Jingchen Ni, Yong Liu, Chun Yuan, and Yansong Tang. Iterprime: Zero-shot referring image segmentation with iterative grad-cam refinement and primary word emphasis. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 8159–8168, 2025
2025
-
[40]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Omnigen: Unified image generation
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xingrun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13294–13304, 2025
2025
-
[43]
Multi-class token transformer for weakly supervised semantic segmentation
Lian Xu, Wanli Ouyang, Mohammed Bennamoun, Farid Boussaid, and Dan Xu. Multi-class token transformer for weakly supervised semantic segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4310–4319, 2022
2022
-
[44]
Boosting weakly supervised referring image segmentation via progressive comprehension.Advances in Neural Information Processing Systems, 37:93213–93239, 2024
Zaiquan Yang, Yuhao Liu, Jiaying Lin, Gerhard Hancke, and Rynson Lau. Boosting weakly supervised referring image segmentation via progressive comprehension.Advances in Neural Information Processing Systems, 37:93213–93239, 2024
2024
-
[45]
ReasonEdit: Towards reasoning-enhanced image editing models.arXiv preprint arXiv:2511.22625, 2025
Fukun Yin, Shiyu Liu, Yucheng Han, Zhibo Wang, Peng Xing, Rui Wang, Wei Cheng, Yingming Wang, Aojie Li, Zixin Yin, et al. Reasonedit: Towards reasoning-enhanced image editing models.arXiv preprint arXiv:2511.22625, 2025
-
[46]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26125–26135, 2025
2025
-
[47]
Zero-shot referring image segmentation with global- local context features
Seonghoon Yu, Paul Hongsuck Seo, and Jeany Son. Zero-shot referring image segmentation with global- local context features. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19456–19465, 2023
2023
-
[48]
Pseudo-ris: Distinctive pseudo-supervision generation for referring image segmentation
Seonghoon Yu, Paul Hongsuck Seo, and Jeany Son. Pseudo-ris: Distinctive pseudo-supervision generation for referring image segmentation. InEuropean Conference on Computer Vision, pages 18–36. Springer, 2024
2024
-
[49]
Latent expression generation for referring image segmentation and grounding
Seonghoon Yu, Joonbeom Hong, Joonseok Lee, and Jeany Son. Latent expression generation for referring image segmentation and grounding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21374–21383, 2025
2025
-
[50]
Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
2023
-
[51]
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer.arXiv preprint arXiv:2504.20690, 2025
-
[52]
Enabling instructional image editing with in-context generation in large scale diffusion transformer
Zechuan Zhang, Ji Xie, Yu Lu, Zongxin Yang, and Yi Yang. Enabling instructional image editing with in-context generation in large scale diffusion transformer. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[53]
Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Processing Systems, 37:3058–3093, 2024
Haozhe Zhao, Xiaojian Ma, Liang Chen, Shuzheng Si, Rujie Wu, Kaikai An, Peiyu Yu, Minjia Zhang, Qing Li, and Baobao Chang. Ultraedit: Instruction-based fine-grained image editing at scale.Advances in Neural Information Processing Systems, 37:3058–3093, 2024
2024
-
[54]
Extract free dense labels from clip
Chong Zhou, Chen Change Loy, and Bo Dai. Extract free dense labels from clip. InEuropean conference on computer vision, pages 696–712. Springer, 2022. 12 Appendix A1 Feature Separability: Definition, Rationale, and Implementation Definition.Let F(t,l) ∈R Nv×D denote MMSA output features of clean image tokens within the l-th DiT block at timestep t. Given ...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.