Recognition: unknown
On a posteriori stopping rules of adaptive stochastic heavy ball method for ill-posed problems
Pith reviewed 2026-05-14 18:37 UTC · model grok-4.3
The pith
Adaptive stochastic heavy ball method with a posteriori stopping rule converges almost surely for ill-posed inverse problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The adaptive stochastic heavy ball method, which performs single-equation random updates with momentum and stops according to an a posteriori discrepancy rule applied only to the selected equation, converges almost surely and in expectation for ill-posed linear inverse problems when the adaptive parameters obey the stated bounds and convex penalty functions are employed.
What carries the argument
The a posteriori stopping rule that compares the residual of the randomly selected equation against a discrepancy threshold, paired with the adaptive choice of step size and momentum coefficient inside the heavy-ball update.
If this is right
- Only one equation is processed per iteration, so the per-step cost stays linear in the dimension of a single row even for very large systems.
- Convex penalties encode prior structural information while preserving the almost-sure and expectation convergence guarantees.
- The discrepancy-based stopping rule eliminates the need to compute the full residual vector at every iteration or at fixed intervals.
- Both almost-sure and mean-square convergence together guarantee reliable recovery in the presence of noise.
Where Pith is reading between the lines
- The same adaptive stopping idea may transfer to other stochastic first-order methods for inverse problems without requiring new convergence proofs from scratch.
- Because the rule avoids full residual computations, it opens a route to online or streaming formulations where data arrive sequentially.
- Numerical evidence in the paper suggests the method remains stable when the number of equations greatly exceeds the dimension of the unknown, an extension that could be tested on nonlinear forward operators.
Load-bearing premise
The noise level, the adaptive parameters, and the convex penalty functions must satisfy specific bounds and growth conditions for the convergence statements to hold.
What would settle it
A concrete linear ill-posed system with known exact solution and controlled additive noise in which the generated sequence fails to converge almost surely or the stopping rule terminates with error bounded away from zero.
Figures


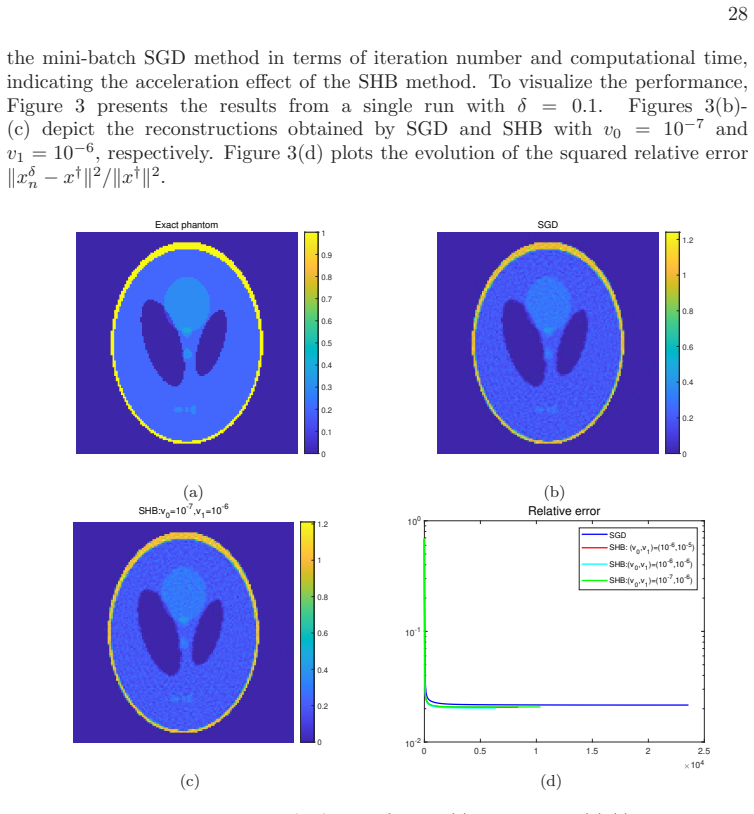


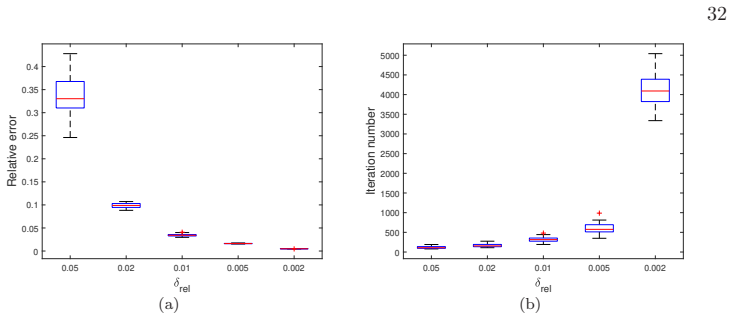
read the original abstract
In this paper we develop a stochastic heavy ball method for solving ill-posed inverse problems. The method updates the iterate using only a randomly selected equation at each iteration step while incorporating a momentum term into the process. To facilitate fast convergence, we propose an adaptive strategy for selecting the step size and the momentum coefficient. Inspired by the spirit of the discrepancy principle, we introduce an {\it a posteriori} stopping rule for our adaptive stochastic heavy ball method. This rule avoids the need to compute residuals of all equations in the system at every iteration or at fixed frequency intervals, thereby enhancing computational efficiency and practicality. Additionally, convex penalty functions are employed to capture the specific features of the desired solutions. Under suitable conditions, we establish almost sure convergence as well as convergence in expectation. Extensive numerical experiments are conducted to evaluate the performance of the proposed method, demonstrating its efficiency and promising potential for solving large-scale ill-posed problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops an adaptive stochastic heavy-ball method for ill-posed linear inverse problems. The iteration performs randomized single-equation updates with a momentum term, adapts the step-size and momentum coefficient on the fly, incorporates convex penalty functions, and terminates via an a-posteriori discrepancy-type stopping rule that avoids evaluating the full residual at every step. Under suitable conditions on the noise level, adaptation rules, and penalties, the paper proves almost-sure convergence and convergence in expectation; numerical experiments on large-scale problems are reported to illustrate practical performance.
Significance. If the convergence statements hold, the work supplies a computationally attractive a-posteriori rule for a class of stochastic first-order methods that is already popular for large-scale ill-posed problems. The combination of momentum, adaptive parameters, and penalty terms is standard, but the explicit stopping criterion that remains cheap to evaluate adds a concrete practical contribution.
minor comments (3)
- [Abstract and §1] The abstract and introduction repeatedly invoke “suitable conditions” without giving even a high-level list of the required assumptions on the noise level, the adaptation maps, or the penalty functions. Adding one compact paragraph that enumerates the main hypotheses would improve readability.
- [Numerical experiments] In the numerical section the authors compare the new method only against a few existing stochastic schemes; a direct comparison against the same iteration run with a fixed discrepancy stopping rule (or with oracle knowledge of the noise level) would quantify the practical gain of the proposed a-posteriori rule.
- [§2 and §3] Notation for the adaptive step-size and momentum sequences is introduced without a single consolidated table or list of symbols; readers must hunt through several paragraphs to recall the definitions.
Simulated Author's Rebuttal
We thank the referee for the careful reading of the manuscript and the positive overall assessment. The recommendation for minor revision is appreciated. No specific major comments were provided in the report, so we will incorporate any minor editorial or technical clarifications in the revised version to further improve the presentation.
Circularity Check
No significant circularity detected
full rationale
The paper derives almost sure and expectation convergence for the adaptive stochastic heavy-ball iteration from explicitly listed assumptions on the forward operator, noise level, adaptive step-size/momentum rules, convex penalty, and the discrepancy-type a-posteriori stopping criterion. No equation or theorem reduces the claimed convergence to a fitted parameter, a self-referential definition, or a load-bearing self-citation whose validity is presupposed by the present work. The stopping rule is constructed independently of the convergence statement and does not force the result by construction. The argument therefore remains self-contained once the stated conditions hold.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. N. Bhattacharya and E. C. W aymire. A basic course in probability theory . New York: Springer, 2007
2007
-
[2]
R. I. Bot ¸ and T. Hein. Iterative regularization with a general penalty term-theo ry and application to L1 and TV regularization . Inverse Problems, 28 (2011), 104010
2011
-
[3]
L. Bottou. Large-scale machine learning with stochastic gradient des cent. Proceedings of COMPSTAT2010 (Berlin: Springer), 2010, pp. 177-186
2010
-
[4]
Bottou, F
L. Bottou, F. E. Curtis and J. Nocedal. Optimization methods for large-scale machine learning. SIAM Review, 60 (2018), pp. 223-311
2018
-
[5]
Cioranescu
I. Cioranescu. Geometry of Banach spaces, duality mappings and nonlinear p roblems. Kluwer Academic Pub, 1990
1990
-
[6]
H. W. Engl, M. Hanke and A. Neubauer. Regularization of inverse problems . Kluwer Academic Pub, 1996
1996
-
[7]
R. Gu, Z. Fu, B. Han, H. Fu. Stochastic gradient descent method with convex penalty for ill-posed problems in Banach space. Inverse Problems, 41 (2025), 055003
2025
-
[8]
Haltmeier, R
M. Haltmeier, R. Kowar, A. Leit˜ ao and O. Scherzer. Kaczmarz methods for regularizing nonlinear ill-posed equations. II. applications . Inverse Problems and Imaging, 3 (2007), pp. 507-523
2007
-
[9]
Hanafy and C
A. Hanafy and C. I. Zanelli. Quantitative real-time pulsed Schlieren imaging of ultras onic waves . Proceedings of IEEE Ultrasonics Symposium, 2 (1991), pp. 12 23-1227
1991
-
[10]
Hanke, A
M. Hanke, A. Neubauer, and O. Scherzer. A convergence analysis of the Landweber iteration for nonlinear ill-posed problems . Numerische Mathematik, 72 (1995), pp. 21-37
1995
-
[11]
P. C. Hansen and M. Saxild-Hansen. AIR tools-a MATLAB package of algebraic iterative 33 reconstruction methods. Journal of Computational and Applied Mathematics, 236 (20 12), pp. 2167-2178
-
[12]
Huang, Q
J. Huang, Q. Jin, X. Lu, L. Zhang. On early stopping of stochastic mirror descent method for ill-posed inverse problems. Numerische Mathematik, 157 (2025), pp. 539-571
2025
-
[13]
Jin and X
B. Jin and X. Lu. On the regularization property of stochastic gradient desc ent. Inverse Problems, 35 (2019), 015004
2019
-
[14]
B. Jin, Z. Zhou and J. Zou. On the convergence of stochastic gradient descent for nonli near ill-posed problems. SIAM Journal on Optimization, 30 (2020), pp. 1421-1450
2020
-
[15]
B. Jin, Z. Zhou and J. Zou. An analysis of stochastic variance reduced gradient for lin ear inverse problems. Inverse Problems, 38 (2022), 025009
2022
-
[16]
Q. Jin. Adaptive Nesterov momentum method for solving ill-posed in verse problems. Inverse Problems, 41 (2025), 025005
2025
-
[17]
Jin, Lectures on Nonsmooth Optimization , Texts in Applied Mathematics, 82
Q. Jin, Lectures on Nonsmooth Optimization , Texts in Applied Mathematics, 82. Springer, Cham, 2025
2025
-
[18]
Q. Jin, L. Chen. Stochastic variance reduced gradient method for linear ill -posed inverse problems. Inverse Problems, 41 (2025), 055014
2025
-
[19]
Jin and Q
Q. Jin and Q. Huang. An adaptive heavy ball method for ill-posed inverse problem s. SIAM Journal on Imaging Sciences, 17 (2024), pp. 2212-2241
2024
-
[20]
Jin and Y
Q. Jin and Y. Liu. Convergence analysis of a stochastic heavy-ball method for linear ill-posed problems. Journal of Computational and Applied Mathematics, 470 (202 5), 116702
-
[21]
Q. Jin, X. Lu and L. Zhang. Stochastic mirror descent method for linear ill-posed prob lems in Banach spaces. Inverse Problems, 39 (2023), 065010
2023
-
[22]
Jin and W
Q. Jin and W. W ang. Landweber iteration of Kaczmarz type with general non-smoo th convex penalty functionals . Inverse Problems, 29 (2013), pp. 1400–1416
2013
-
[23]
Kaltenbacher, A
B. Kaltenbacher, A. Neubauer, and O. Scherzer. Iterative regularization methods for nonlinear ill-posed problems. W alter de Gruyter GmbH & Co. KG, Berlin, 2008
2008
-
[24]
Lu and P
S. Lu and P. Math´ e. Stochastic gradient descent for linear inverse problems in Hilbert spaces. Mathematics of Computation, 91 (2022), pp. 1763-1788
2022
-
[25]
Natterer
F. Natterer. The Mathematics of Computerized Tomography . Philadelphia, PA: SIAM, 2001
2001
-
[26]
Robbins and S
H. Robbins and S. Monro. A stochastic approximation method . The Annals of Mathematical Statistics, 22 (1951), pp. 400-407
1951
-
[27]
L. I. Rudin, S. Osher, and E. Fatemi. Nonlinear total variation based noise removal algorithms . Physica D., 60 (1992), 259–268
1992
-
[28]
Schuster, B
T. Schuster, B. Kaltenbacher, B. Hofmann, and K. S. Kazi mierski. Regularization methods in Banach Spaces. De Gruyter, 2012
2012
-
[29]
Zalinescu
C. Zalinescu. Convex analysis in general vector spaces . W orld Scientific, 2002
2002
-
[30]
Zhu and T
M. Zhu and T. Chan. An efficient primal-dual hybrid gradient algorithm for total variation image restoration. CAM Report, 08-34, UCLA, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.