Recognition: 2 theorem links
· Lean TheoremUnderstanding Generalization through Decision Pattern Shift
Pith reviewed 2026-05-14 19:15 UTC · model grok-4.3
The pith
Decision pattern shifts in neural networks correlate linearly with generalization gaps, framing failure as internal mechanism drift.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Decision patterns form a highly structured, class-consistent space. The magnitude of a sample's deviation from its class-average pattern, quantified by the DPS metric, correlates linearly with the generalization gap. This drift organizes multiple degradation regimes into one trajectory, revealing generalization as systematic change in the model's internal decision mechanism.
What carries the argument
The DPS metric, which computes the discrepancy between a sample's GradCAM-derived channel-contribution vector and the class-average vector from training.
If this is right
- Generalization risk can be diagnosed by tracking internal pattern drift instead of relying solely on output accuracy.
- Diverse failure modes including domain shift, OOD inputs, and shortcut learning lie on a single ordered spectrum defined by DPS magnitude.
- Channel-level contributions become directly usable for localizing defects that drive poor generalization.
- Early warning systems for generalization failure become feasible by computing DPS on held-out validation samples.
Where Pith is reading between the lines
- The same pattern-stability lens could be applied to non-CNN architectures such as transformers to test whether decision-vector drift remains predictive.
- Regularization methods that penalize deviation from class-average patterns during training might directly improve generalization.
- If DPS captures mechanistic drift, combining it with circuit-level interpretability could link high-level generalization to specific subnetworks.
Load-bearing premise
That a GradCAM channel-contribution vector accurately represents the model's internal decision pattern and that its deviation from the class average correctly quantifies harmful shift.
What would settle it
A model and dataset pair where the Pearson correlation between DPS values and measured generalization gaps falls substantially below 0.8 across multiple runs would falsify the central linear relationship.
Figures

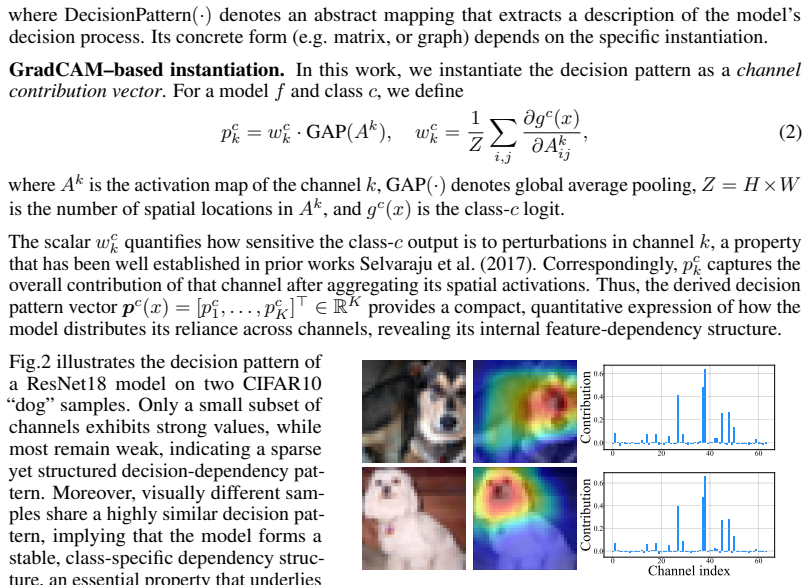

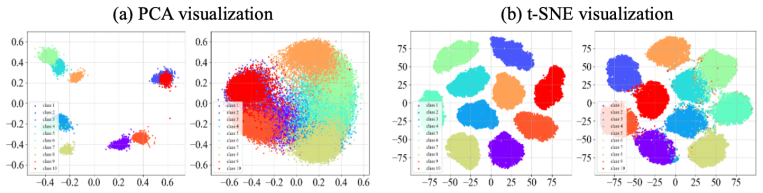
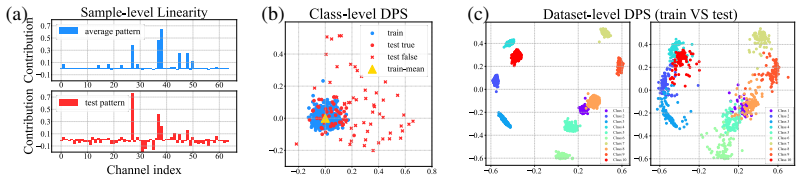







read the original abstract
Understanding why deep neural networks (DNNs) fail to generalize to unseen samples remains a long-standing challenge. Existing studies mainly examine changes in externally observable factors such as data, representations, or outputs, yet offer limited insight into how a model's internal decision mechanism evolves from training to test. To address this gap, we introduce Decision Pattern Shift (DPS), a new perspective that defines generalization through the stability of internal decision patterns and quantifies failure as their deviation from those learned during training. Specifically, we represent each sample's decision pattern as a GradCAM-based channel-contribution vector, which captures how feature channels collectively support a prediction, and we propose the DPS metric to measure its discrepancy from the class-average pattern. Empirical analyses across multiple datasets and architectures show that, (i) decision patterns form a highly structured, class-consistent space with strong intra-class cohesion and low inter-class confusion, enabling direct analysis of a model's decision logic; (ii) the DPS magnitude correlates linearly with the generalization gap (nearly all Pearson r > 0.8), revealing generalization as a systematic drift in the model's internal decision mechanism; (iii) the DPS spectrum organizes diverse generalization degradation scenarios (covering ideal generalization, in-distribution degradation, domain shift, out-of-distribution, and shortcut learning) into a continuous trajectory, providing a unified explanation of their failure modes. These findings open up new possibilities for early generalization-risk detection, failure-mode diagnosis, and channel-level defect localization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Decision Pattern Shift (DPS), a metric that represents each sample's decision pattern via a GradCAM-derived channel-contribution vector and quantifies its deviation from the class-average pattern. It claims that DPS magnitude correlates linearly with the generalization gap (nearly all Pearson r > 0.8 across datasets and architectures), that decision patterns form a structured class-consistent space, and that the DPS spectrum unifies diverse failure modes (ideal generalization, in-distribution degradation, domain shift, OOD, shortcut learning) into a continuous trajectory.
Significance. If the correlation is robust and the GradCAM proxy is shown to be faithful, the work would offer a concrete internal-mechanism account of generalization failure that could support early risk detection and channel-level diagnosis. The unification of failure modes into a single spectrum is a potentially useful organizing idea, but its value depends on the metric's validity.
major comments (3)
- [Abstract / §4] Abstract and experimental sections: the headline claim that DPS magnitude correlates linearly with the generalization gap (Pearson r > 0.8) is presented without reporting data-split protocols, whether the linear model was pre-specified or selected post-hoc, or any multiple-testing / statistical-control procedures. These omissions make it impossible to assess whether the reported correlations are reliable or inflated.
- [§3] §3 (DPS definition): the channel-contribution vector is obtained exclusively via GradCAM, yet no ablation compares it to alternative attribution methods (e.g., Integrated Gradients, occlusion, or causal interventions) or to ground-truth decision-relevant channels. Because GradCAM is known to be sensitive to gradient saturation and non-causal features, the measured deviation from the class-average pattern may not correspond to genuine internal decision-mechanism drift.
- [§4] §4 (failure-mode trajectory): the claim that DPS organizes ideal generalization, in-distribution degradation, domain shift, OOD, and shortcut learning into a single continuous spectrum rests on the same unvalidated GradCAM proxy; without an independent verification that the ordering reflects causal decision changes rather than attribution artifacts, the unification interpretation is not yet supported.
minor comments (2)
- [§3] Notation for the DPS metric (Eq. 3 or equivalent) should explicitly state whether the class-average pattern is computed on training or test samples and whether it is updated during training.
- [§4] Figure captions and axis labels for the DPS-vs-gap scatter plots should report the exact number of models, seeds, and samples per point so readers can judge the stability of the reported r values.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on statistical reporting and metric validation. We address each major point below and commit to revisions that improve clarity and rigor without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract and experimental sections: the headline claim that DPS magnitude correlates linearly with the generalization gap (Pearson r > 0.8) is presented without reporting data-split protocols, whether the linear model was pre-specified or selected post-hoc, or any multiple-testing / statistical-control procedures. These omissions make it impossible to assess whether the reported correlations are reliable or inflated.
Authors: We agree these details are essential. In the revised version we will add an explicit subsection describing the data-split protocols (standard train/test partitions with 5 random seeds per setting), confirm that the linear model was pre-specified from initial pilot runs on two datasets before full evaluation, and report Pearson r with associated p-values together with Bonferroni-adjusted significance thresholds across all reported correlations. This will allow readers to evaluate reliability directly. revision: yes
-
Referee: [§3] §3 (DPS definition): the channel-contribution vector is obtained exclusively via GradCAM, yet no ablation compares it to alternative attribution methods (e.g., Integrated Gradients, occlusion, or causal interventions) or to ground-truth decision-relevant channels. Because GradCAM is known to be sensitive to gradient saturation and non-causal features, the measured deviation from the class-average pattern may not correspond to genuine internal decision-mechanism drift.
Authors: GradCAM was chosen for its channel-level resolution and low computational cost, which enabled the large-scale experiments across architectures and datasets. We acknowledge its known limitations. The revision will include a new paragraph in §3 discussing these sensitivities and a limited ablation on CIFAR-10 and ImageNet subsets comparing DPS values obtained with GradCAM versus Integrated Gradients; the ordering of samples by DPS magnitude remains largely consistent, supporting robustness. We do not claim GradCAM is causal, only that it yields a useful proxy for decision-pattern deviation. revision: partial
-
Referee: [§4] §4 (failure-mode trajectory): the claim that DPS organizes ideal generalization, in-distribution degradation, domain shift, OOD, and shortcut learning into a single continuous spectrum rests on the same unvalidated GradCAM proxy; without an independent verification that the ordering reflects causal decision changes rather than attribution artifacts, the unification interpretation is not yet supported.
Authors: The spectrum is presented as an empirical organizing observation rather than a causal proof. We will revise §4 to (i) explicitly label the GradCAM proxy limitation, (ii) add a controlled channel-masking experiment on a subset of models showing that increasing DPS via targeted masking reproduces the predicted degradation trajectory, and (iii) frame the unification as a descriptive hypothesis that invites future causal validation with more faithful attribution techniques. revision: partial
Circularity Check
No significant circularity; DPS is an empirical metric with observed correlation
full rationale
The paper defines DPS directly from GradCAM channel-contribution vectors as the discrepancy from class-average patterns, then reports an empirical linear correlation (Pearson r > 0.8) with the generalization gap across datasets. No equation or claim reduces a 'prediction' to a fitted input by construction, nor relies on self-citation chains or imported uniqueness theorems for the central result. The derivation chain is observational and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GradCAM channel-contribution vectors accurately represent a sample's internal decision pattern
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe represent each sample’s decision pattern as a GradCAM-based channel-contribution vector... DPS magnitude correlates linearly with the generalization gap (nearly all Pearson r > 0.8)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearDPS spectrum organizes diverse generalization degradation scenarios... into a continuous trajectory
Reference graph
Works this paper leans on
-
[1]
A closer look at memorization in deep networks
Devansh Arpit, Stanis aw Jastrzebski, Nicolas Ballas, David Krueger, Emmanuel Bengio, Maxinder S Kanwal, Tegan Maharaj, Asja Fischer, Aaron Courville, Yoshua Bengio, et al. A closer look at memorization in deep networks. In International conference on machine learning, pages 233--242. PMLR, 2017
work page 2017
-
[2]
Nearly-tight vc-dimension and pseudodimension bounds for piecewise linear neural networks
Peter L Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian. Nearly-tight vc-dimension and pseudodimension bounds for piecewise linear neural networks. Journal of Machine Learning Research, 20 0 (63): 0 1--17, 2019
work page 2019
-
[3]
Network dissection: Quantifying interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541--6549, 2017
work page 2017
-
[4]
Analysis of representations for domain adaptation
Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. Analysis of representations for domain adaptation. Advances in neural information processing systems, 19, 2006
work page 2006
-
[5]
Estimating generalization under distribution shifts via domain-invariant representations
Ching-Yao Chuang, Antonio Torralba, and Stefanie Jegelka. Estimating generalization under distribution shifts via domain-invariant representations. In International Conference on Machine Learning. PMLR, 2020
work page 2020
-
[6]
Discovering and explaining the representation bottleneck of dnns
Huiqi Deng, Qihan Ren, Hao Zhang, and Quanshi Zhang. Discovering and explaining the representation bottleneck of dnns. In International Conference on Learning Representations, 2022
work page 2022
-
[7]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248--255. Ieee, 2009
work page 2009
-
[8]
Sharp minima can generalize for deep nets
Laurent Dinh, Razvan Pascanu, Samy Bengio, and Yoshua Bengio. Sharp minima can generalize for deep nets. In International Conference on Machine Learning, pages 1019--1028. PMLR, 2017
work page 2017
-
[9]
Stiffness: A new perspective on generalization in neural networks, 2020
Stanislav Fort, Pawe Krzysztof Nowak, Stanis aw Jastrzebski, and Srini Narayanan. Stiffness: A new perspective on generalization in neural networks, 2020
work page 2020
-
[10]
Shortcut learning in deep neural networks
Robert Geirhos, Jorn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2 0 (11): 0 665--673, 2020
work page 2020
-
[11]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770--778, 2016
work page 2016
-
[12]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Saurav Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, et al. The many faces of robustness: A critical analysis of out-of-distribution generalization. In Proceedings of the IEEE/CVF international conference on computer vision, pages 8340--8349, 2021
work page 2021
-
[13]
Sepp Hochreiter and J \"u rgen Schmidhuber. Flat minima. Neural computation, 9 0 (1): 0 1--42, 1997
work page 1997
-
[14]
On feature learning in the presence of spurious correlations
Pavel Izmailov, Polina Kirichenko, Nate Gruver, and Andrew G Wilson. On feature learning in the presence of spurious correlations. Advances in Neural Information Processing Systems, 35: 0 38516--38532, 2022
work page 2022
-
[15]
Catastrophic fisher explosion: Early phase fisher matrix impacts generalization
Stanislaw Jastrzebski, Devansh Arpit, Oliver Astrand, Giancarlo B Kerg, Huan Wang, Caiming Xiong, Richard Socher, Kyunghyun Cho, and Krzysztof J Geras. Catastrophic fisher explosion: Early phase fisher matrix impacts generalization. In International Conference on Machine Learning, pages 4772--4784. PMLR, 2021
work page 2021
-
[16]
On large-batch training for deep learning: Generalization gap and sharp minima
Nitish Shirish Keskar, Dheevatsa Mudigere, Jorge Nocedal, Mikhail Smelyanskiy, and Ping Tak Peter Tang. On large-batch training for deep learning: Generalization gap and sharp minima. In International Conference on Learning Representations, 2017
work page 2017
-
[17]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In International conference on machine learning, pages 2668--2677. PMLR, 2018
work page 2018
-
[18]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. In International conference on machine learning, pages 5338--5348. PMLR, 2020
work page 2020
-
[19]
Wilds: A benchmark of in-the-wild distribution shifts
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. Wilds: A benchmark of in-the-wild distribution shifts. In International conference on machine learning, pages 5637--5664. PMLR, 2021
work page 2021
-
[20]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[21]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015
work page 2015
-
[22]
Visualizing the loss landscape of neural nets
Hao Li, Zheng Xu, Gavin Taylor, Christoph Studer, and Tom Goldstein. Visualizing the loss landscape of neural nets. Advances in neural information processing systems, 31, 2018
work page 2018
-
[23]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30, 2017
work page 2017
-
[24]
Representation learning via invariant causal mechanisms
Jovana Mitrovic, Brian McWilliams, Jacob C Walker, Lars Holger Buesing, and Charles Blundell. Representation learning via invariant causal mechanisms. In International Conference on Learning Representations, 2021
work page 2021
-
[25]
Abolafia, Jeffrey Pennington, and Jascha Sohl-Dickstein
Roman Novak, Yasaman Bahri, Daniel A. Abolafia, Jeffrey Pennington, and Jascha Sohl-Dickstein. Sensitivity and generalization in neural networks: an empirical study. In International Conference on Learning Representations, 2018
work page 2018
- [26]
-
[27]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, pages 618--626, 2017
work page 2017
-
[28]
Predictive pac learning and process decompositions
Cosma Shalizi and Aryeh Kontorovich. Predictive pac learning and process decompositions. Advances in neural information processing systems, 26, 2013
work page 2013
-
[30]
Samuel L. Smith and Quoc V. Le. A bayesian perspective on generalization and stochastic gradient descent. In International Conference on Learning Representations, 2018
work page 2018
-
[31]
On the geometry of generalization and memorization in deep neural networks
Cory Stephenson, suchismita padhy, Abhinav Ganesh, Yue Hui, Hanlin Tang, and SueYeon Chung. On the geometry of generalization and memorization in deep neural networks. In International Conference on Learning Representations, 2021
work page 2021
-
[32]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1--9, 2015
work page 2015
-
[33]
Nearly optimal vc-dimension and pseudo-dimension bounds for deep neural network derivatives
Yahong Yang, Haizhao Yang, and Yang Xiang. Nearly optimal vc-dimension and pseudo-dimension bounds for deep neural network derivatives. Advances in Neural Information Processing Systems, 36: 0 21721--21756, 2023
work page 2023
-
[34]
Yu Yu, Shahram Khadivi, and Jia Xu. Can data diversity enhance learning generalization? In Proceedings of the 29th international conference on computational linguistics, pages 4933--4945, 2022
work page 2022
-
[35]
Generalization bounds for domain adaptation
Chao Zhang, Lei Zhang, and Jieping Ye. Generalization bounds for domain adaptation. Advances in neural information processing systems, 25, 2012
work page 2012
-
[36]
Delving deep into the generalization of vision transformers under distribution shifts
Chongzhi Zhang, Mingyuan Zhang, Shanghang Zhang, Daisheng Jin, Qiang Zhou, Zhongang Cai, Haiyu Zhao, Xianglong Liu, and Ziwei Liu. Delving deep into the generalization of vision transformers under distribution shifts. In Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 7277--7286, 2022
work page 2022
-
[37]
Interpreting and boosting dropout from a game-theoretic view
Hao Zhang, Sen Li, YinChao Ma, Mingjie Li, Yichen Xie, and Quanshi Zhang. Interpreting and boosting dropout from a game-theoretic view. In International Conference on Learning Representations, 2021
work page 2021
-
[38]
Interpreting cnns via decision trees
Quanshi Zhang, Yu Yang, Haotian Ma, and Ying Nian Wu. Interpreting cnns via decision trees. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6261--6270, 2019
work page 2019
-
[39]
On learning invariant representations for domain adaptation
Han Zhao, Remi Tachet Des Combes, Kun Zhang, and Geoffrey Gordon. On learning invariant representations for domain adaptation. In International conference on machine learning, pages 7523--7532. PMLR, 2019
work page 2019
-
[40]
Proceedings of the IEEE international conference on computer vision , pages=
Grad-cam: Visual explanations from deep networks via gradient-based localization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[41]
Stiffness: A New Perspective on Generalization in Neural Networks , author=. 2020 , url=
work page 2020
-
[42]
Journal of Machine Learning Research , volume=
Nearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks , author=. Journal of Machine Learning Research , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Nearly optimal VC-dimension and pseudo-dimension bounds for deep neural network derivatives , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Advances in neural information processing systems , volume=
Rademacher complexity bounds for non-iid processes , author=. Advances in neural information processing systems , volume=
-
[45]
Journal of machine learning research , volume=
-
[46]
Advances in neural information processing systems , volume=
Predictive PAC learning and process decompositions , author=. Advances in neural information processing systems , volume=
-
[47]
Flat minima , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[48]
Advances in neural information processing systems , volume=
-
[49]
International Conference on Learning Representations , year=
On large-batch training for deep learning: Generalization gap and sharp minima , author=. International Conference on Learning Representations , year=
-
[50]
Advances in neural information processing systems , volume=
Visualizing the loss landscape of neural nets , author=. Advances in neural information processing systems , volume=
-
[51]
International Conference on Machine Learning , pages=
Sharp minima can generalize for deep nets , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[52]
Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages=
Delving deep into the generalization of vision transformers under distribution shifts , author=. Proceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition , pages=
-
[53]
International Conference on Learning Representations , year=
Optimal Representations for Covariate Shift , author=. International Conference on Learning Representations , year=
-
[54]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
work page 2020
-
[55]
International conference on machine learning , pages=
A closer look at memorization in deep networks , author=. International conference on machine learning , pages=. 2017 , organization=
work page 2017
-
[56]
International Conference on Learning Representations , year=
On the geometry of generalization and memorization in deep neural networks , author=. International Conference on Learning Representations , year=
-
[57]
Journal of Statistical Mechanics: Theory and Experiment , volume=. 2021 , publisher=
work page 2021
-
[58]
Advances in Neural Information Processing Systems , volume=
On feature learning in the presence of spurious correlations , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Proceedings of the 29th international conference on computational linguistics , pages=
Can data diversity enhance learning generalization? , author=. Proceedings of the 29th international conference on computational linguistics , pages=
-
[60]
International Conference on Learning Representations , year=
A Bayesian Perspective on Generalization and Stochastic Gradient Descent , author=. International Conference on Learning Representations , year=
-
[61]
International Conference on Machine Learning , pages=
Catastrophic fisher explosion: Early phase fisher matrix impacts generalization , author=. International Conference on Machine Learning , pages=. 2021 , organization=
work page 2021
-
[62]
International conference on machine learning , pages=
On learning invariant representations for domain adaptation , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[63]
arXiv preprint arXiv:1907.02893 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[64]
International Conference on Learning Representations , year=
Representation Learning via Invariant Causal Mechanisms , author=. International Conference on Learning Representations , year=
-
[65]
Advances in neural information processing systems , volume=
Analysis of representations for domain adaptation , author=. Advances in neural information processing systems , volume=
-
[66]
International Conference on Learning Representations , year=
Interpreting and Boosting Dropout from a Game-Theoretic View , author=. International Conference on Learning Representations , year=
-
[67]
International Conference on Learning Representations , year=
Sensitivity and Generalization in Neural Networks: an Empirical Study , author=. International Conference on Learning Representations , year=
-
[68]
International Conference on Learning Representations , year=
Discovering and Explaining the Representation Bottleneck of DNNs , author=. International Conference on Learning Representations , year=
-
[69]
Advances in neural information processing systems , volume=
Generalization bounds for domain adaptation , author=. Advances in neural information processing systems , volume=
-
[70]
International Conference on Machine Learning , year=
Estimating generalization under distribution shifts via domain-invariant representations , author=. International Conference on Machine Learning , year=
-
[71]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
The many faces of robustness: A critical analysis of out-of-distribution generalization , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[72]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[73]
Advances in neural information processing systems , volume=
A unified approach to interpreting model predictions , author=. Advances in neural information processing systems , volume=
-
[74]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[75]
International conference on machine learning , pages=
Concept bottleneck models , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[76]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Network dissection: Quantifying interpretability of deep visual representations , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[77]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Interpreting cnns via decision trees , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
- [78]
-
[79]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
work page 2009
-
[80]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[81]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.