Recognition: 2 theorem links
· Lean TheoremPareto-Guided Optimal Transport for Multi-Reward Alignment
Pith reviewed 2026-05-14 19:19 UTC · model grok-4.3
The pith
PG-OT builds prompt-specific Pareto frontiers and applies distribution-aware optimal transport to improve multi-reward alignment while introducing JDR and JCR metrics to measure synergy and hacking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
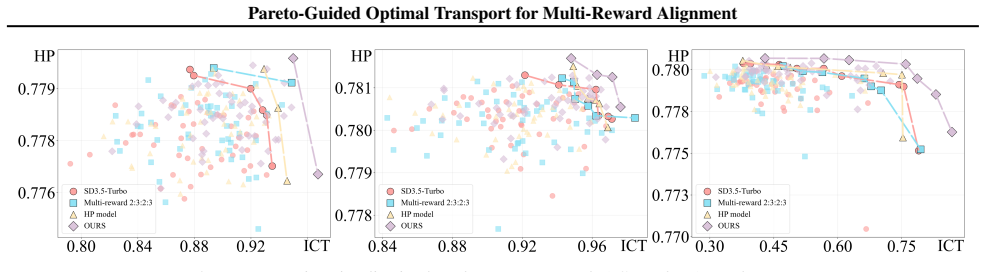
Experimental results show that our approach outperforms strong baselines with an 11% gain in JDR and achieves a near 80% win rate in human evaluations.
Load-bearing premise
That a prompt-specific Pareto frontier can be constructed reliably from the available reward models and that mapping samples to it via optimal transport will consistently reduce reward hacking without introducing new instabilities or excessive compute cost.
Figures








read the original abstract
Text-to-image generation models have achieved remarkable progress in preference optimization, yet achieving robust alignment across diverse reward models remains a significant challenge. Existing multi-reward fusion approaches rely on weighted summation, which is costly to tune and insufficient for balancing conflicting objectives. More critically, optimization with reward models is highly susceptible to reward hacking, where reward scores increase while the perceived quality of generated images deteriorates. We demonstrate that optimizing against a unified global target under heterogeneous reward upper bounds can induce reward hacking, a risk further exacerbated by the inherent instability of weak reward models. To mitigate this, we propose a Pareto Frontier-Guided Optimal Transport (PG-OT) framework. Our method constructs a prompt-specific Pareto frontier and maps dominated samples toward it via distribution-aware optimal transport. Furthermore, we develop both online and offline optimization strategies tailored to diverse reward signal characteristics. To provide a more rigorous assessment, we introduce the Joint Domination Rate (JDR) and Joint Collapse Rate (JCR) as principled metrics to quantify multi-reward synergy and reward hacking. Experimental results show that our approach outperforms strong baselines with an 11% gain in JDR and achieves a near 80% win rate in human evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
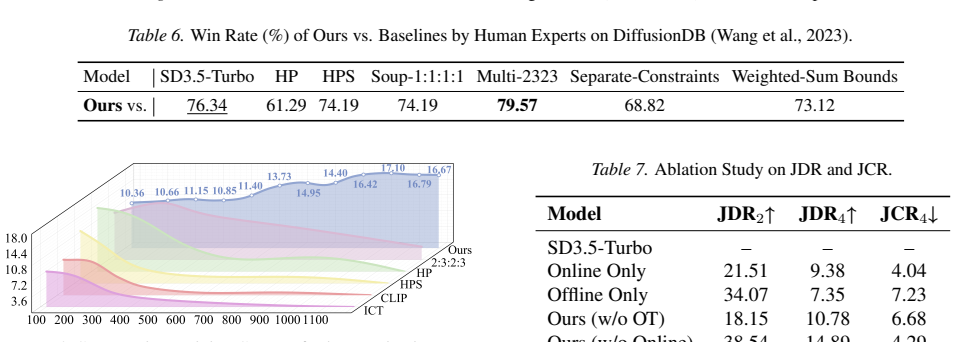
Summary. The manuscript proposes Pareto Frontier-Guided Optimal Transport (PG-OT) for multi-reward alignment in text-to-image models. It constructs a prompt-specific Pareto frontier from available reward models and maps generated samples to this frontier via distribution-aware optimal transport, with online and offline optimization variants. New metrics Joint Domination Rate (JDR) and Joint Collapse Rate (JCR) are introduced to quantify multi-reward synergy and reward hacking. Experiments report an 11% JDR gain over baselines and a near-80% win rate in human evaluations.
Significance. If the central claims hold, the framework offers a principled alternative to weighted-sum reward fusion that directly targets non-dominated trade-offs, which could improve robustness to reward hacking in heterogeneous multi-objective settings. The JDR/JCR metrics provide a more structured evaluation lens than single-reward scores.
major comments (3)
- [Abstract / Methods] Abstract and Methods: The 11% JDR gain and ~80% human win rate rest on reliable construction of prompt-specific Pareto frontiers from the given reward models. No quantitative diagnostics (frontier coverage, sensitivity to reward scaling or correlations, or ablation on frontier quality) are reported, leaving open whether the gains are artifacts of the particular reward set rather than a general property of PG-OT.
- [Experiments] Experiments: The human-study win rate lacks reported details on number of raters, inter-rater agreement, prompt sampling procedure, and statistical controls. Without these, it is difficult to assess whether the 80% figure generalizes beyond the tested prompts or is inflated by evaluation confounds.
- [Methods] Methods (online/offline strategies): The mapping via optimal transport is claimed to reduce reward hacking without introducing new instabilities or excessive cost, yet no analysis of computational overhead, convergence behavior under weak reward models, or comparison of online vs. offline variants on JCR is provided to support this.
minor comments (2)
- [Methods] Notation for the Pareto frontier and transport plan should be introduced with an explicit equation early in the Methods section for clarity.
- [Related Work] The paper should cite prior work on Pareto optimization in multi-objective RL and optimal transport applications in generative modeling.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: The 11% JDR gain and ~80% human win rate rest on reliable construction of prompt-specific Pareto frontiers from the given reward models. No quantitative diagnostics (frontier coverage, sensitivity to reward scaling or correlations, or ablation on frontier quality) are reported, leaving open whether the gains are artifacts of the particular reward set rather than a general property of PG-OT.
Authors: We acknowledge that additional diagnostics on Pareto frontier construction would strengthen the presentation. In the revised manuscript we will add quantitative metrics for frontier coverage, sensitivity analysis to reward scaling and correlations, and an ablation on frontier quality obtained by varying the reward-model subset. These additions will help confirm that the reported gains are not artifacts of the specific reward set. revision: yes
-
Referee: [Experiments] Experiments: The human-study win rate lacks reported details on number of raters, inter-rater agreement, prompt sampling procedure, and statistical controls. Without these, it is difficult to assess whether the 80% figure generalizes beyond the tested prompts or is inflated by evaluation confounds.
Authors: We agree that these experimental details are necessary for proper evaluation of the human-study results. In the revised manuscript we will expand the Experiments section to report the number of raters, inter-rater agreement, prompt sampling procedure, and statistical controls employed. revision: yes
-
Referee: [Methods] Methods (online/offline strategies): The mapping via optimal transport is claimed to reduce reward hacking without introducing new instabilities or excessive cost, yet no analysis of computational overhead, convergence behavior under weak reward models, or comparison of online vs. offline variants on JCR is provided to support this.
Authors: We note that the current manuscript already shows JCR reductions for the proposed method, yet we did not include explicit overhead or convergence analysis. In the revision we will add runtime benchmarks, convergence plots under varying reward-model quality, and a side-by-side JCR comparison of the online and offline variants. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper introduces the PG-OT framework by constructing prompt-specific Pareto frontiers from reward models and applying distribution-aware optimal transport to map samples, along with online/offline optimization variants. It defines the new metrics JDR and JCR independently to quantify multi-reward synergy and reward hacking. The reported 11% JDR gain and human win rates are presented as empirical results from applying the method to baselines, not as quantities that define or are fitted into the method itself. No equations reduce by construction to inputs, no predictions are statistically forced from fits, and no load-bearing self-citations or uniqueness theorems are invoked in the provided text. The derivation from method description to metrics to experimental outcomes remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose a Pareto Frontier-Guided Optimal Transport (PG-OT) framework. Our method constructs a prompt-specific Pareto frontier and maps dominated samples toward it via distribution-aware optimal transport.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearJDRK = 1/N Σ 1(Ri ≻ Ri,b); JCRK = 1/N Σ 1(Ri,b ≻ Ri)
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization , booktitle =
Luca Eyring and Shyamgopal Karthik and Karsten Roth and Alexey Dosovitskiy and Zeynep Akata , editor =. ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization , booktitle =. 2024 , url =
work page 2024
-
[5]
T-VSL: text-guided visual sound source localization in mixtures
Yanyu Li and Xian Liu and Anil Kag and Ju Hu and Yerlan Idelbayev and Dhritiman Sagar and Yanzhi Wang and Sergey Tulyakov and Jian Ren , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.00763 , timestamp =
-
[6]
Seung Hyun Lee and Yinxiao Li and Junjie Ke and Innfarn Yoo and Han Zhang and Jiahui Yu and Qifei Wang and Fei Deng and Glenn Entis and Junfeng He and Gang Li and Sangpil Kim and Irfan Essa and Feng Yang , editor =. Parrot: Pareto-Optimal Multi-reward Reinforcement Learning Framework for Text-to-Image Generation , booktitle =. 2024 , url =. doi:10.1007/97...
-
[7]
Kyungmin Lee and Xiahong Li and Qifei Wang and Junfeng He and Junjie Ke and Ming. Calibrated Multi-Preference Optimization for Aligning Diffusion Models , booktitle =. 2025 , url =. doi:10.1109/CVPR52734.2025.01721 , timestamp =
-
[8]
BalancedDPO: Adaptive Multi-Metric Alignment
Dipesh Tamboli and Souradip Chakraborty and Aditya Malusare and Biplab Banerjee and Amrit Singh Bedi and Vaneet Aggarwal , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.12575 , eprinttype =. 2503.12575 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.12575 2025
-
[9]
Learning Transferable Visual Models From Natural Language Supervision , booktitle =
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , editor =. Learning Transferable Visual Models From Natural Language Supervision , booktitle =. 2021 , url =
work page 2021
-
[10]
Junnan Li and Dongxu Li and Caiming Xiong and Steven C. H. Hoi , editor =. International Conference on Machine Learning,. 2022 , url =
work page 2022
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Enhancing reward models for high-quality image generation: Beyond text-image alignment , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2026 , eprint=
work page 2026
- [13]
-
[14]
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , booktitle =
Jiazheng Xu and Xiao Liu and Yuchen Wu and Yuxuan Tong and Qinkai Li and Ming Ding and Jie Tang and Yuxiao Dong , editor =. ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation , booktitle =. 2023 , url =
work page 2023
-
[15]
Xiaoshi Wu and Yiming Hao and Keqiang Sun and Yixiong Chen and Feng Zhu and Rui Zhao and Hongsheng Li , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2306.09341 , eprinttype =. 2306.09341 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.09341 2023
-
[16]
Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , booktitle =
Yuval Kirstain and Adam Polyak and Uriel Singer and Shahbuland Matiana and Joe Penna and Omer Levy , editor =. Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation , booktitle =. 2023 , url =
work page 2023
-
[17]
T-VSL: text-guided visual sound source localization in mixtures
Bram Wallace and Meihua Dang and Rafael Rafailov and Linqi Zhou and Aaron Lou and Senthil Purushwalkam and Stefano Ermon and Caiming Xiong and Shafiq Joty and Nikhil Naik , title =. 2024 , url =. doi:10.1109/CVPR52733.2024.00786 , timestamp =
-
[18]
Sinkhorn Distances: Lightspeed Computation of Optimal Transport , booktitle =
Marco Cuturi , editor =. Sinkhorn Distances: Lightspeed Computation of Optimal Transport , booktitle =. 2013 , url =
work page 2013
-
[19]
Histoire de l'Académie Royale des Sciences de Paris , year =
Gaspard Monge , title =. Histoire de l'Académie Royale des Sciences de Paris , year =
-
[20]
Directly Fine-Tuning Diffusion Models on Differentiable Rewards , author=. 2024 , eprint=
work page 2024
-
[21]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[22]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation , author=. 2022 , eprint=
work page 2022
-
[23]
DiffusionDB: A Large-scale Prompt Gallery Dataset for Text-to-Image Generative Models , author=. 2023 , eprint=
work page 2023
-
[24]
Training Diffusion Models with Reinforcement Learning , author=. 2024 , eprint=
work page 2024
-
[25]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis , author=. 2023 , eprint=
work page 2023
-
[26]
High-Resolution Image Synthesis with Latent Diffusion Models , author=. 2022 , eprint=
work page 2022
-
[27]
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis , author=. 2024 , eprint=
work page 2024
-
[28]
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author=. 2015 , eprint=
work page 2015
-
[29]
Generative Modeling by Estimating Gradients of the Data Distribution , author=. 2020 , eprint=
work page 2020
-
[30]
Fine-Tuning Language Models from Human Preferences , author=. 2020 , eprint=
work page 2020
- [31]
-
[32]
Diffusion Models Beat GANs on Image Synthesis , author=. 2021 , eprint=
work page 2021
-
[33]
Large-scale Reinforcement Learning for Diffusion Models , author=. 2024 , eprint=
work page 2024
-
[34]
TextCraftor: Your Text Encoder Can be Image Quality Controller , author=. 2024 , eprint=
work page 2024
-
[35]
Reinforcement Learning with Human Feedback: Learning Dynamic Choices via Pessimism , author=. 2024 , url=
work page 2024
-
[36]
Reinforcement Learning for Joint Optimization of Multiple Rewards , author=. 2023 , eprint=
work page 2023
-
[37]
Powerful and Flexible: Personalized Text-to-Image Generation via Reinforcement Learning , author=. 2024 , eprint=
work page 2024
-
[38]
PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models , author=. 2024 , eprint=
work page 2024
-
[39]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
work page 2024
-
[40]
DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models , author=. 2023 , eprint=
work page 2023
-
[41]
Human Preference Score: Better Aligning Text-to-Image Models with Human Preference , author=. 2023 , eprint=
work page 2023
-
[42]
Dynamic Multi-Reward Weighting for Multi-Style Controllable Generation , author=. 2024 , eprint=
work page 2024
-
[43]
On the Plasticity and Stability for Post-Training Large Language Models , author=. 2026 , eprint=
work page 2026
-
[44]
Group Causal Policy Optimization for Post-Training Large Language Models , author=. 2025 , eprint=
work page 2025
-
[45]
Learning to Think: Information-Theoretic Reinforcement Fine-Tuning for LLMs , author=. 2025 , eprint=
work page 2025
-
[46]
Causal Reward Adjustment: Mitigating Reward Hacking in External Reasoning via Backdoor Correction , author=. 2025 , eprint=
work page 2025
-
[47]
PrefGen: Multimodal Preference Learning for Preference-Conditioned Image Generation , author=. 2025 , eprint=
work page 2025
-
[48]
Learning User Preferences for Image Generation Model , author=. 2025 , eprint=
work page 2025
-
[49]
Say Cheese! Detail-Preserving Portrait Collection Generation via Natural Language Edits , author=. 2026 , eprint=
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.