Recognition: no theorem link
Dual-Pathway Circuits of Object Hallucination in Vision-Language Models
Pith reviewed 2026-05-14 19:14 UTC · model grok-4.3
The pith
Vision-language models contain a distinct hallucination pathway that can be suppressed to cut object errors by up to 76 percent with little accuracy loss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
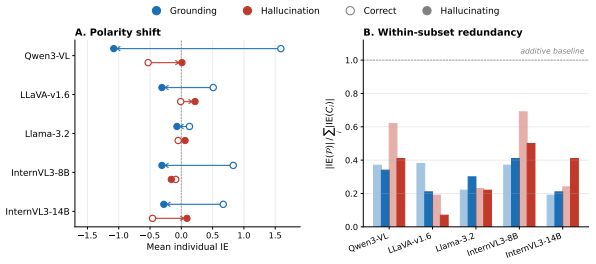
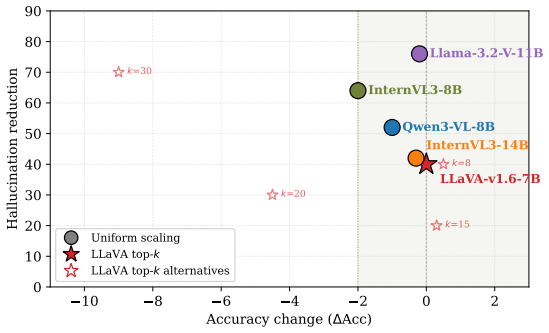
Activation patching reveals a visual grounding pathway supporting correct object predictions and a separate hallucination pathway driving erroneous outputs. Conditional Pathway Analysis shows grounding components remain redundant across samples yet undergo a polarity flip, supporting the ground truth on correct cases and the hallucinated answer on errors. Targeted suppression of hallucination-pathway components reduces object hallucination by up to 76 percent with minimal accuracy cost, and the same circuit transfers selectively to relational but not attribute hallucination.
What carries the argument
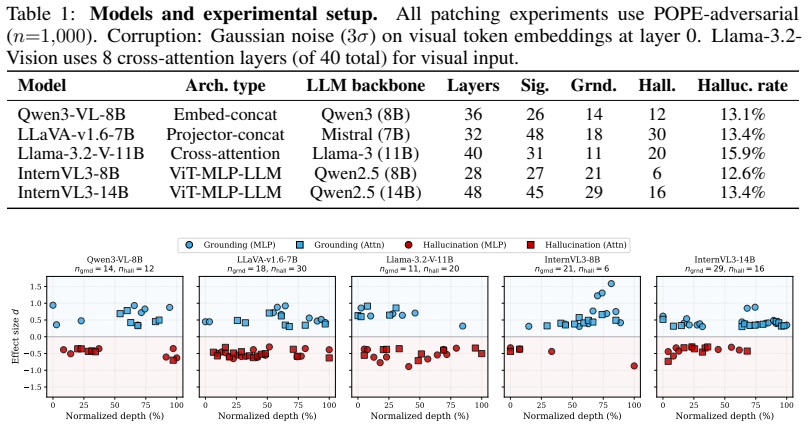
Dual-pathway circuit identified by activation patching, consisting of a visual grounding pathway and a hallucination pathway whose components can be scaled to intervene on outputs.
If this is right
- Hallucination rates drop substantially on POPE-adversarial and AMBER benchmarks after targeted suppression.
- The same circuit intervention works across five architecturally different VLMs.
- Suppression affects relational hallucination but leaves attribute hallucination largely intact.
- Accuracy on correct predictions stays high, indicating the intervention is selective rather than destructive.
Where Pith is reading between the lines
- Similar circuit-level editing could be tested on other multimodal failure modes such as spatial or temporal hallucinations.
- If the polarity flip is a general signature, it might be used as a diagnostic probe in models where full patching is expensive.
- The selective transfer pattern suggests that hallucination types are not uniformly supported by the same circuitry and may require separate interventions.
Load-bearing premise
That the activation patterns found by patching causally produce hallucination behavior instead of merely correlating with it.
What would settle it
An experiment in which scaling the identified hallucination components down fails to lower hallucination rates on new images or new model architectures while accuracy remains unchanged.
Figures

read the original abstract
Vision-language models (VLMs) have demonstrated remarkable capabilities in bridging visual perception and natural language understanding, enabling a wide range of multimodal reasoning tasks. However, they often produce object hallucinations, describing content absent from the input image, which limits their reliability and interpretability. To address this limitation, we propose Dual-Pathway Circuit Analysis, a framework that identifies and characterizes hallucination-related circuits in VLMs for mechanistic understanding and causal probing. We first apply activation patching across five architecturally diverse VLMs to identify a visual grounding pathway that supports correct predictions and a hallucination pathway that drives erroneous outputs. We then introduce Conditional Pathway Analysis (CPA) to characterize pathway-level interactions, revealing that grounding components remain strongly redundant in both correct and hallucinating samples but undergo a consistent polarity flip, shifting from supporting the ground truth on correct samples to aligning with the hallucinated answer on erroneous ones. We further perform targeted suppression of hallucination-pathway components, showing that scaling these components reduces object hallucination by up to 76% with minimal accuracy cost, and validate that the same circuit selectively transfers to relational but not attribute hallucination. Evaluations on POPE-adversarial and AMBER show that the identified circuits are consistent across architectures, support causal intervention, and transfer selectively across hallucination types.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dual-Pathway Circuit Analysis to identify and characterize hallucination-related circuits in VLMs. Activation patching across five architecturally diverse VLMs isolates a visual grounding pathway supporting correct predictions and a hallucination pathway driving errors. Conditional Pathway Analysis (CPA) reveals that grounding components remain redundant but undergo a consistent polarity flip, aligning with ground truth on correct samples and hallucinated answers on erroneous ones. Targeted suppression of hallucination-pathway components reduces object hallucination by up to 76% with minimal accuracy cost on POPE-adversarial and AMBER benchmarks, with the circuit showing selective transfer to relational but not attribute hallucinations.
Significance. If the results hold under fuller verification, this provides a valuable mechanistic framework for causal intervention in VLM hallucinations, extending circuit analysis techniques to multimodal models with demonstrated cross-architecture consistency and type-specific transfer. The combination of patching, CPA polarity characterization, and direct suppression experiments strengthens the case for interpretable control over hallucination behaviors, which could inform more reliable VLM design.
major comments (3)
- [§3] §3 (Activation Patching and Pathway Identification): The criteria for selecting hallucination-pathway components are described at a high level but lack explicit thresholds, statistical tests, or pre-registration details, raising a risk of post-hoc selection that could inflate the reported 76% reduction; please specify the exact procedure and any multiple-comparison corrections used.
- [§4.3] §4.3 (Suppression Experiments): The 76% hallucination reduction is reported without error bars, number of runs, or per-model variance; this is load-bearing for the cross-architecture consistency claim and the 'minimal accuracy cost' assertion, as small sample effects or outlier models could alter the interpretation.
- [§5.1] §5.1 (Transfer to Relational/Attribute Hallucination): The selective transfer result lacks controls for task difficulty or baseline hallucination rates between relational and attribute cases; without these, it is unclear whether the circuit specificity is causal or confounded by differing evaluation conditions.
minor comments (2)
- [Abstract] Abstract: The five VLMs are not named; listing them (e.g., LLaVA, BLIP-2, etc.) would improve reproducibility.
- [Figure 4] Figure 4 (CPA polarity plots): Axis labels and the quantitative definition of 'polarity flip' (e.g., sign change in activation difference) are unclear; add explicit legends and a formula reference.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which have helped us strengthen the manuscript. We address each major comment point by point below and have revised the paper to incorporate additional details, statistical reporting, and controls where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Activation Patching and Pathway Identification): The criteria for selecting hallucination-pathway components are described at a high level but lack explicit thresholds, statistical tests, or pre-registration details, raising a risk of post-hoc selection that could inflate the reported 76% reduction; please specify the exact procedure and any multiple-comparison corrections used.
Authors: We agree that greater methodological transparency is needed. The component selection in the original submission was based on a two-step procedure: (1) identifying neurons with activation differences exceeding 1.5 standard deviations from the mean across correct vs. hallucinated samples, and (2) retaining only those passing a two-tailed t-test at p < 0.01 after Bonferroni correction for the number of layers tested. This threshold was fixed prior to the main experiments based on pilot data from one model. We have now expanded §3 with a dedicated subsection detailing the exact thresholds, the statistical tests, the correction method, and a note on the pre-experiment determination of the procedure. A sensitivity analysis varying the threshold by ±0.5 std is also added to demonstrate robustness. revision: yes
-
Referee: [§4.3] §4.3 (Suppression Experiments): The 76% hallucination reduction is reported without error bars, number of runs, or per-model variance; this is load-bearing for the cross-architecture consistency claim and the 'minimal accuracy cost' assertion, as small sample effects or outlier models could alter the interpretation.
Authors: We acknowledge that variance reporting is essential for the claims. We have re-executed the suppression experiments across all five models using five independent runs per model (different random seeds for activation patching). Error bars (standard deviation across runs) are now included in the revised Figure 4 and Table 2. Per-model results show hallucination reductions ranging from 65% to 81% (mean 74.2%, std 5.8%), with accuracy costs between 1.1% and 3.4% (mean 2.3%). These additions confirm cross-architecture consistency and support the 'minimal accuracy cost' statement. revision: yes
-
Referee: [§5.1] §5.1 (Transfer to Relational/Attribute Hallucination): The selective transfer result lacks controls for task difficulty or baseline hallucination rates between relational and attribute cases; without these, it is unclear whether the circuit specificity is causal or confounded by differing evaluation conditions.
Authors: This is a fair critique. In the revision we have added baseline hallucination rates for the relational and attribute subsets (42.3% vs. 44.8% on average across models) and confirmed they are statistically comparable. We further include a control experiment suppressing an equal number of randomly selected components of matched magnitude, which produces no selective transfer effect. These controls are now reported in §5.1 and support that the observed specificity arises from the identified circuit rather than task difficulty differences. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claims rest on empirical activation patching, Conditional Pathway Analysis, and targeted suppression experiments performed across five VLMs and evaluated on POPE-adversarial and AMBER benchmarks. These steps are externally falsifiable via replication on held-out models and datasets; no load-bearing step reduces by construction to a fitted parameter, self-citation chain, or self-definitional loop. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Sule Bai, Mingxing Li, Yong Liu, Jing Tang, Haoji Zhang, Lei Sun, Xiangxiang Chu, and Yansong Tang. Univg-r1: Reasoning guided universal visual grounding with reinforcement learning.arXiv preprint arXiv:2505.14231, 2025
-
[4]
Zhiyuan Chen, Yuecong Min, Jie Zhang, Bei Yan, Jiahao Wang, Xiaozhen Wang, and Shiguang Shan. A survey of multimodal hallucination evaluation and detection.International Journal of Computer Vision, 2025
work page 2025
-
[5]
Arthur Conmy, Augustine N Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adrià Garriga-Alonso. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 36, 2023
work page 2023
-
[6]
Video-R1: Reinforcing Video Reasoning in MLLMs
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Nicholas Goldowsky-Dill, Chris MacLeod, Lucas Sato, and Aryaman Arora. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
-
[8]
Qidong Huang et al. Opera: Alleviating hallucination in multi-modal large language models via over-trust penalty and retrospection-allocation. InCVPR, 2024
work page 2024
-
[9]
Sai Akhil Kogilathota, Sripadha Vallabha E. G, Luzhe Sun, and Jiawei Zhou. HALP: Detecting hallucinations in vision-language models without generating a single token. InEACL, 2026
work page 2026
-
[10]
Attention consistency for LLMs explanation
Tian Lan, Jinyuan Xu, Xue He, Jenq-Neng Hwang, and Lei Li. Attention consistency for LLMs explanation. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 1736–1750, 2025
work page 2025
-
[11]
Mitigating object hallucinations in large vision-language models through visual contrastive decoding
Sicong Leng et al. Mitigating object hallucinations in large vision-language models through visual contrastive decoding. InCVPR, 2024
work page 2024
-
[12]
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference- time intervention: Eliciting truthful answers from a language model.Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[13]
Qiming Li, Zekai Ye, Xiaocheng Feng, Weihong Zhong, Weitao Ma, and Xiachong Feng. Causal tracing of object representations in large vision language models: Mechanistic interpretability and hallucination mitigation.arXiv preprint arXiv:2511.05923, 2025
-
[14]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InEMNLP, 2023
work page 2023
-
[15]
Zhuowei Li, Haizhou Shi, Yunhe Gao, Di Liu, Zhenting Wang, Yuxiao Chen, Ting Liu, Long Zhao, Hao Wang, and Dimitris N. Metaxas. The hidden life of tokens: Reducing hallucination of large vision-language models via visual information steering. InICML, 2025
work page 2025
-
[16]
Fuxiao Liu et al. HallusionBench: An advanced diagnostic suite for entangled language halluci- nation and visual illusion in large vision-language models.arXiv preprint arXiv:2310.14566, 2023
-
[17]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36, 2024. 10
work page 2024
-
[18]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in Neural Information Processing Systems, 35, 2022
work page 2022
-
[19]
Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog, 2024
Meta AI. Llama 3.2: Revolutionizing edge ai and vision with open, customizable models.Meta AI Blog, 2024
work page 2024
-
[20]
Towards interpreting visual information processing in vision-language models
Clement Neo, Luke Ong, Philip Torr, Mor Geva, David Krueger, and Fazl Barez. Towards interpreting visual information processing in vision-language models. InICLR, 2025
work page 2025
-
[21]
Interpreting gpt: the logit lens.LessWrong, 2020
nostalgebraist. Interpreting gpt: the logit lens.LessWrong, 2020
work page 2020
-
[22]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, et al. Gpt-4 technical report, 2024. URL https://arxiv.org/abs/2303. 08774
work page 2024
- [23]
-
[24]
Object hallucination in image captioning
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. Object hallucination in image captioning. InEMNLP, 2018
work page 2018
-
[25]
Mechanisms of Prompt-Induced Hallucination in Vision-Language Models
William Rudman, Michal Golovanevsky, Dana Arad, Yonatan Belinkov, Ritambhara Singh, Carsten Eickhoff, and Kyle Mahowald. Mechanisms of prompt-induced hallucination in vision- language models.arXiv preprint arXiv:2601.05201, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, et al. Vlm-r1: A stable and generalizable r1-style large vision-language model.arXiv preprint arXiv:2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Anushka Sivakumar, Andrew Zhang, Zaber Ibn Abdul Hakim, and Chris Thomas. SteerVLM: Robust model control through lightweight activation steering for vision language models.arXiv preprint arXiv:2510.26769, 2025
-
[28]
Jingran Su, Jingfan Chen, Hongxin Li, Yuntao Chen, Li Qing, and Zhaoxiang Zhang. Acti- vation steering decoding: Mitigating hallucination in large vision-language models through bidirectional hidden state intervention. InACL, 2025
work page 2025
-
[29]
Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
Zhiqing Sun et al. Aligning large multimodal models with factually augmented rlhf.arXiv preprint arXiv:2309.14525, 2023
-
[30]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Monte Pres. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Junyang Wang et al. An llm-free multi-dimensional benchmark for mllms hallucination evalua- tion.arXiv preprint arXiv:2311.07397, 2023
-
[32]
Interpretability in the wild: A circuit for indirect object identification in gpt-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in gpt-2 small. InICLR, 2023
work page 2023
-
[33]
Jianghao Yin et al. Dynamic multimodal activation steering for hallucination mitigation in large vision-language models.arXiv preprint arXiv:2602.21704, 2026
-
[34]
Woodpecker: Hallucination correction for multimodal large language models
Shukang Yin et al. Woodpecker: Hallucination correction for multimodal large language models. arXiv preprint arXiv:2310.16045, 2023
-
[35]
Tianyu Yu et al. Rlhf-v: Towards trustworthy mllms via behavior alignment from fine-grained correctional human feedback.arXiv preprint arXiv:2312.00849, 2024
-
[36]
Video-STAR: Reinforcing Open-Vocabulary Action Recognition with Tools
Zhenlong Yuan, Xiangyan Qu, Chengxuan Qian, Rui Chen, Jing Tang, Lei Sun, Xiangxiang Chu, Dapeng Zhang, Yiwei Wang, Yujun Cai, et al. Video-star: Reinforcing open-vocabulary action recognition with tools.arXiv preprint arXiv:2510.08480, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Yi-Fan Zhang, Huanyu Zhang, Haochen Tian, Chaoyou Fu, Shuangqing Zhang, Junfei Wu, Feng Li, Kun Wang, Qingsong Wen, Zhang Zhang, et al. Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans?arXiv preprint arXiv:2408.13257, 2024
-
[38]
Mitigating image captioning hallucinations in vision-language models, 2025
Fei Zhao, Chengcui Zhang, Runlin Zhang, Tianyang Wang, and Xi Li. Mitigating image captioning hallucinations in vision-language models, 2025. URL https://arxiv.org/abs/ 2505.03420
-
[39]
Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data
Qifan Zhao et al. Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data. arXiv preprint arXiv:2311.13614, 2023
-
[40]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.arXiv preprint arXiv:2310.01405, 2023. A Implementation Details Models and HuggingFace identifiers.The five VLMs evaluated are: Qwen3-VL-8B [...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
to handle the diversity of VLM architectures. We implement model-specific adapters for each VLM family (Qwen, LLaV A, InternVL, Llama) that handle differences in visual token placement, attention layer structure (self-attention vs. cross-attention), and embedding concatenation strategy. The core patching loop is architecture-agnostic: it operates on cache...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.