Recognition: unknown
Variance-Aware Estimation and Inference for Michaelis--Menten Models with Heteroscedastic Errors and Clustered Measurements
Pith reviewed 2026-05-14 18:26 UTC · model grok-4.3
The pith
A variance-aware procedure using simple working models stabilizes Michaelis-Menten estimates of Km and Vmax when errors vary with concentration or data are clustered.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A variance-aware procedure for Michaelis-Menten estimation and inference is motivated by conditional moment restrictions and implemented through simple conditionally Gaussian working models. For single curves the method reduces to one-dimensional root finding for Km followed by closed-form plug-in updates for Vmax and a variance scale parameter; the same score logic yields a cluster-level extension through a random-effect-induced working covariance. In simulation, modeling heteroscedasticity improved variance recovery and interval efficiency relative to homoscedastic nonlinear least squares, while cluster-aware semiparametric and NLME fits restored fixed-effect coverage far more effectively.
What carries the argument
Variance-aware procedure based on conditional moment restrictions and implemented via conditionally Gaussian working models with prespecified variance functions
If this is right
- Modeling heteroscedasticity improves variance recovery and interval efficiency relative to homoscedastic nonlinear least squares.
- Cluster-aware fits restore fixed-effect coverage more effectively than pooled analyses that ignore clustering.
- The square-root variance function gives the most stable empirical fit among the prespecified working models.
- The workflow applies uniformly to single-curve, grouped, and clustered Michaelis-Menten data.
Where Pith is reading between the lines
- The same conditional-moment approach could be applied to other nonlinear kinetic models that currently rely on constant-variance assumptions.
- If the working models prove robust, experimental designs in enzyme assays could deliberately vary substrate concentrations to exploit the stabilized inference.
- Routine adoption would reduce the need for data transformations that alter the original-scale interpretation of Km and Vmax.
Load-bearing premise
The prespecified working variance functions and conditionally Gaussian models sufficiently approximate the true error distribution and clustering structure without biasing the estimates of Km and Vmax.
What would settle it
A dataset in which the square-root or other working variance function produces Km and Vmax point estimates that differ materially from homoscedastic nonlinear least squares while known simulation truth shows no bias would falsify the claim of practical stabilization.
Figures

read the original abstract
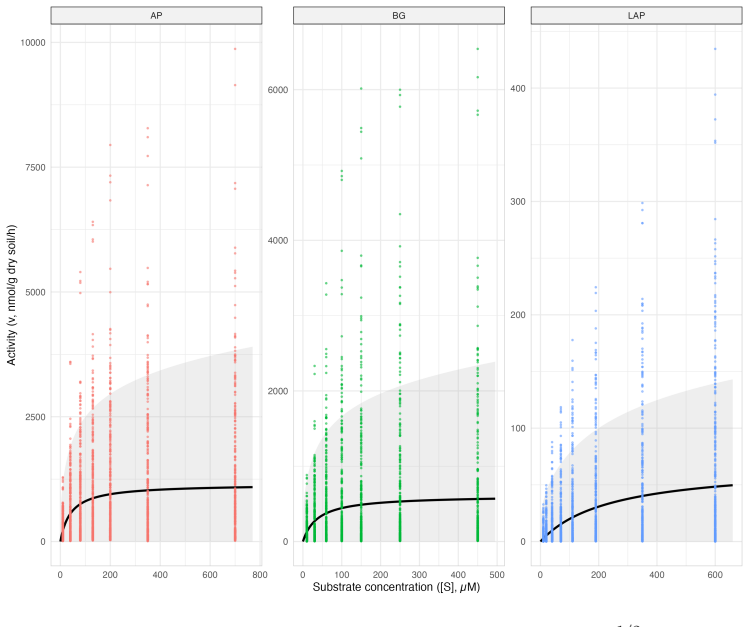
Michaelis--Menten analysis is often conducted by nonlinear least squares under a constant-variance assumption, even though enzyme-kinetic data frequently display concentration-dependent heteroscedasticity and often include repeated or clustered measurements. We develop a variance-aware procedure for Michaelis--Menten estimation and inference that is motivated by conditional moment restrictions and implemented through simple conditionally Gaussian working models. For single curves, the method reduces to one-dimensional root finding for $K_m$ followed by closed-form plug-in updates for $V_{\max}$ and a variance scale parameter; the same score logic yields a cluster-level extension through a random-effect-induced working covariance. In simulation, modeling heteroscedasticity improved variance recovery and interval efficiency relative to homoscedastic nonlinear least squares, while cluster-aware semiparametric and NLME fits restored fixed-effect coverage far more effectively than pooled analyses that ignored clustering. In self-driving laboratory and soil exoenzyme data, heteroscedastic models achieved lower information criteria than homoscedastic nonlinear least squares, with the square-root variance function giving the most stable empirical fit among the prespecified working models. We implement the workflow in the companion \texttt{inferMM} package for single-curve, grouped, and clustered Michaelis--Menten analysis. These results show that simple variance-function and covariance modeling can stabilize original-scale Michaelis--Menten inference when variability changes with substrate concentration or measurements are clustered.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
Derivation is self-contained via standard conditional moment restrictions
full rationale
The paper derives its estimators from conditional moment restrictions on the Michaelis-Menten mean function, yielding unbiased estimating equations for Km and Vmax that remain valid under variance misspecification. Single-curve estimation reduces to explicit one-dimensional root finding for Km followed by closed-form plug-in updates for Vmax and scale; the clustered extension uses a random-effect working covariance that preserves the same unbiasedness property. No step reduces by construction to a fitted input, no self-citation supplies a load-bearing uniqueness theorem, and no ansatz is smuggled in; the procedure is a direct quasi-likelihood application whose consistency and efficiency gains are independently verified by simulation and real-data information criteria.
Axiom & Free-Parameter Ledger
free parameters (1)
- variance scale parameter
axioms (1)
- domain assumption Conditionally Gaussian working models adequately represent the data-generating process for inference purposes.
Reference graph
Works this paper leans on
-
[1]
Michaelis, M
L. Michaelis, M. L. Menten, Die kinetik der invertinwirkung, Biochem. Z. 49 (1913) 333–369
1913
-
[2]
K.A.Johnson, R.S.Goody, TheoriginalMichaelisconstant: translation of the 1913 Michaelis–Menten paper, Biochemistry 50 (39) (2011) 8264– 8269.doi:10.1021/bi201284u
-
[3]
G. N. Wilkinson, Statistical estimations in enzyme kinetics, Biochem. J. 80 (2) (1961) 324–332.doi:10.1042/BJ0800324
-
[4]
R. Eisenthal, A. Cornish-Bowden, The direct linear plot: A new graph- ical procedure for estimating enzyme kinetic parameters, Biochem. J. 139 (3) (1974) 715–720.doi:10.1042/BJ1390715
-
[5]
A. Cornish-Bowden, R. Eisenthal, Statistical considerations in the esti- mation of enzyme kinetic parameters by the direct linear plot and other methods, Biochem.J.139(3)(1974)721–730.doi:10.1042/BJ1390721
-
[6]
G. L. Atkins, I. A. Nimmo, Current trends in the estimation of Michaelis–Menten parameters, Anal. Biochem. 104 (1) (1980) 1–9.doi: 10.1016/0003-2697(80)90268-7
-
[7]
G. F. Mason, J. C. K. Lai, Nonlinear determination of Michaelis–Menten kinetics with model evaluation through estimation of uncertainties, Metab. Brain Dis. 15 (2) (2000) 133–149.doi:10.1007/BF02679980. 31
-
[8]
A. J. Cornish-Bowden, Analysis of progress curves in enzyme kinetics, Biochem. J. 130 (2) (1972) 637–639.doi:10.1042/BJ1300637
-
[9]
R. G. Duggleby, Progress-curve analysis in enzyme kinetics: Numerical solution of integrated rate equations, Biochem. J. 235 (2) (1986) 613– 615.doi:10.1042/BJ2350613
-
[10]
I. A. Nimmo, G. L. Atkins, A comparison of two methods for fitting the integrated Michaelis–Menten equation, Biochem. J. 141 (3) (1974) 913–914.doi:10.1042/BJ1410913
-
[11]
L. Matyska, J. Kovář, Comparison of several non-linear-regression meth- ods for fitting the Michaelis–Menten equation, Biochem. J. 231 (1) (1985) 171–177.doi:10.1042/BJ2310171
-
[12]
P. Askelöf, M. Korsfeldt, B. Mannervik, Error structure of enzyme kinetic experiments. implications for weighting in regression analysis of experimental data, Eur. J. Biochem. 69 (1) (1976) 61–67.doi: 10.1111/j.1432-1033.1976.tb10858.x
-
[13]
D. I. Little, P. C. Poat, I. G. Giles, Residual analysis in determining the error structure in enzyme kinetic data. simulation experiments and observations on Carcinus maenas phosphofructokinase, Eur. J. Biochem. 124 (3) (1982) 499–505.doi:10.1111/j.1432-1033.1982.tb06621.x
-
[14]
A.Cornish-Bowden, L.Endrenyi, Fittingofenzymekineticdatawithout prior knowledge of weights, Biochem. J. 193 (3) (1981) 1005–1008.doi: 10.1042/BJ1931005
-
[15]
D.Ruppert, N.Cressie, R.J.Carroll, Atransformation/weightingmodel for estimating Michaelis–Menten parameters, Biometrics 45 (2) (1989) 637–656.doi:10.2307/2531506
-
[16]
R. J. E. Alves, I. A. Callejas, G. L. Marschmann, M. Mooshammer, H. W. Singh, B. Whitney, M. S. Torn, E. L. Brodie, Kinetic properties of microbial exoenzymes vary with soil depth but have similar temperature sensitivities through the soil profile, Front. Microbiol. 12 (2021) 735282. doi:10.3389/fmicb.2021.735282
-
[17]
P. M. Hooper, Z. Yang, Confidence intervals following Box–Cox trans- formation, Can. J. Stat. 25 (3) (1997) 401–416.doi:10.2307/3315787. 32
-
[18]
C. Ritz, J. C. Streibig, Bioassay analysis using r, Journal of Statistical Software 12 (5) (2005) 1–22.doi:10.18637/jss.v012.i05
-
[19]
J. C. Aledo, renz: An r package for the analysis of enzyme ki- netic data, BMC Bioinformatics 23 (1) (2022) 182.doi:10.1186/ s12859-022-04729-4
2022
-
[20]
M. Kim, Y. Ma, The efficiency of the second-order nonlinear least squares estimator and its extension, Ann. Inst. Stat. Math. 64 (4) (2012) 751–764.doi:10.1007/s10463-011-0332-y
-
[21]
Y. Ma, M. G. Genton, Explicit estimating equations for semiparametric generalized linear latent variable models, Journal of the Royal Statistical Society: Series B (Statistical Methodology) 72 (4) (2010) 475–495.doi: 10.1111/j.1467-9868.2010.00741.x
-
[22]
M. Kim, Appropriate use of parametric and nonparametric methods in estimating regression models with various shapes of errors, Stat 12 (1) (2023) e606.doi:10.1002/sta4.606
-
[23]
P. J. Bickel, C. A. J. Klaassen, Y. Ritov, J. A. Wellner, Efficient and Adaptive Estimation for Semiparametric Models, Johns Hopkins Uni- versity Press, Baltimore, 1993
1993
-
[24]
A. A. Tsiatis, Semiparametric Theory and Missing Data, Springer Series in Statistics, Springer, New York, 2006.doi:10.1007/0-387-37345-4
-
[25]
J. T. Rapp, B. J. Bremer, P. A. Romero, Self-driving laboratories to autonomously navigate the protein fitness landscape, Nat. Chem. Eng. 1 (2024) 97–107.doi:10.1038/s44286-023-00002-4. 33
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.