Recognition: 1 theorem link
· Lean TheoremOxyEcomBench: Benchmarking Multimodal Foundation Models across E-Commerce Ecosystems
Pith reviewed 2026-05-14 02:09 UTC · model grok-4.3
The pith
A new benchmark for e-commerce shows leading multimodal models achieve only modest performance because they lack domain-specific knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
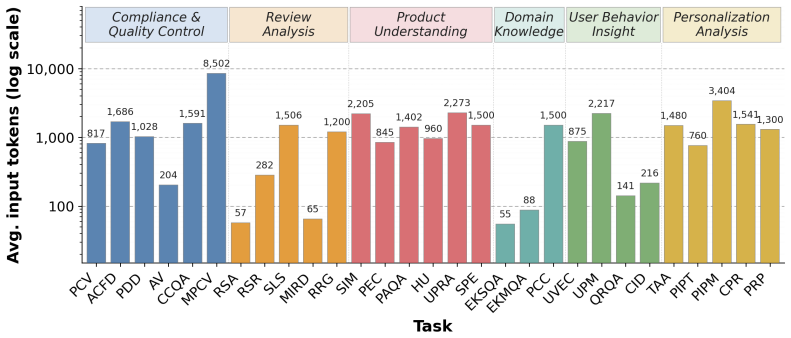
OxyEcomBench is a unified multimodal benchmark of approximately 6300 high-quality instances for real-world bilingual Chinese-English e-commerce. It jointly covers platform operators, merchants and customers across six capability aspects and 29 tasks, supporting text-only, single-image, multi-image, single-turn and multi-turn inputs. All data comes from authentic platforms and is verified by domain experts. A four-level P0-P3 difficulty rubric is applied to every task with priority given to visually salient cases. Tests on 20 LLMs and MLLMs show that even leading models attain modest performance and that performance gaps narrow on this benchmark, indicating that insufficient e-commercepecific
What carries the argument
OxyEcomBench, a multimodal benchmark that integrates stakeholder perspectives across 29 tasks with multimodal configurations and a P0-P3 difficulty rubric focused on visual evidence.
Load-bearing premise
The 29 tasks and four-level P0-P3 difficulty rubric, chosen with expert consensus and emphasis on visually salient cases, faithfully represent the full range of real-world e-commerce challenges without introducing selection bias.
What would settle it
A general-purpose model that scores above 80 percent on the hardest P3 tasks while preserving its usual lead over simpler models would falsify the claim that insufficient e-commerce-specific knowledge is the main reason performance gaps narrow.
Figures





read the original abstract
LLMs and MLLMs have become indispensable tools across a wide range of applications. E-commerce, however, poses distinctive challenges -- including intricate domain knowledge, long-tail product evidence, heterogeneous visual data, and the interplay among multiple stakeholder roles -- that diverge substantially from the general world knowledge these models are primarily trained on, often causing a notable gap between their open-domain and e-commerce performance. To systematically quantify this gap, we introduce OxyEcomBench, a unified multimodal benchmark comprising approximately 6,300 high-quality instances for real-world bilingual Chinese--English e-commerce. Although several e-commerce benchmarks have been proposed, they typically adopt a single stakeholder perspective, target a narrow set of tasks, or address isolated challenges, making it difficult to holistically assess models' understanding of the full e-commerce pipeline. OxyEcomBench addresses these limitations by jointly covering platform operators, merchants, and customers across 6 capability aspects and 29 tasks, supporting text-only and mixed-modality inputs with single-image, multi-image, single-turn, and multi-turn configurations. All data is sourced from authentic e-commerce platforms and verified by domain experts. The benchmark further adopts a difficulty-aware design with a four-level P0--P3 rubric applied to all 29 tasks whose difficulty admits stable expert consensus, and rigorously prioritizes visually salient multimodal cases in which key evidence resides in images rather than text alone. Evaluations on 20 mainstream LLMs and MLLMs show that even the leading models attain modest performance and that performance gaps narrow on OxyEcomBench, suggesting that insufficient e-commerce-specific knowledge infusion mutes the advantages of advanced general-purpose models in this domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OxyEcomBench, a multimodal benchmark with approximately 6,300 expert-verified instances sourced from authentic Chinese-English e-commerce platforms. It covers platform operators, merchants, and customers across 6 capability aspects and 29 tasks, supporting text-only, single-image, multi-image, single-turn, and multi-turn inputs. A four-level P0-P3 difficulty rubric is applied with emphasis on visually salient cases, and evaluations of 20 LLMs and MLLMs show modest absolute performance together with narrowed gaps between leading and other models, which the authors attribute to insufficient e-commerce-specific knowledge infusion.
Significance. If the 29 tasks and P0-P3 rubric provide a representative sample of real-world e-commerce difficulties, the benchmark would usefully quantify the domain gap for general-purpose models and motivate targeted adaptation. The multi-stakeholder coverage, bilingual construction, and explicit difficulty stratification are constructive features that go beyond prior single-perspective e-commerce benchmarks. The reported modest scores and compressed performance gaps would then constitute actionable evidence for the community.
major comments (2)
- [§3.2] §3.2 (Data Collection and Verification): No quantitative inter-annotator agreement figures (Cohen’s kappa, Fleiss’ kappa, or raw agreement percentages) are reported for the expert verification of the 6,300 instances or for the assignment of P0-P3 difficulty labels. Without these statistics, especially for long-tail products, it is impossible to assess the stability of the difficulty rubric or to rule out systematic annotation drift.
- [§4.1 and §5] §4.1 (Task Selection) and §5 (Results): The central interpretation that narrowed gaps reflect missing e-commerce knowledge rests on the assumption that the 29 tasks accurately sample scenarios in which domain knowledge is decisive. The explicit prioritization of visually salient multimodal cases risks overweighting pattern-matching tasks (e.g., single-image attribute extraction) while under-sampling knowledge-heavy ones (multi-turn regulatory pricing, supply-chain reasoning). No usage-frequency statistics from the source platforms are provided to demonstrate that the task distribution matches real-world prevalence.
minor comments (2)
- [Abstract and §3.1] The exact total number of instances (rather than “approximately 6,300”) should be stated in the abstract and §3.1 for reproducibility.
- [Table 2] Table 2 (task taxonomy) would benefit from an additional column indicating the number of instances per task and per difficulty level to allow readers to judge balance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly where feasible.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Data Collection and Verification): No quantitative inter-annotator agreement figures (Cohen’s kappa, Fleiss’ kappa, or raw agreement percentages) are reported for the expert verification of the 6,300 instances or for the assignment of P0-P3 difficulty labels. Without these statistics, especially for long-tail products, it is impossible to assess the stability of the difficulty rubric or to rule out systematic annotation drift.
Authors: We agree that quantitative inter-annotator agreement metrics strengthen claims of annotation quality. The verification involved five domain experts following a structured multi-round protocol. In the revised manuscript we will report Fleiss’ kappa for both instance verification and P0-P3 difficulty assignment, including a breakdown for long-tail product categories, to demonstrate stability and address potential drift. revision: yes
-
Referee: [§4.1 and §5] §4.1 (Task Selection) and §5 (Results): The central interpretation that narrowed gaps reflect missing e-commerce knowledge rests on the assumption that the 29 tasks accurately sample scenarios in which domain knowledge is decisive. The explicit prioritization of visually salient multimodal cases risks overweighting pattern-matching tasks (e.g., single-image attribute extraction) while under-sampling knowledge-heavy ones (multi-turn regulatory pricing, supply-chain reasoning). No usage-frequency statistics from the source platforms are provided to demonstrate that the task distribution matches real-world prevalence.
Authors: Task selection was informed by consultations with e-commerce practitioners to cover representative stakeholder challenges, with visual salience prioritized because images carry decisive evidence in most platform interactions. We acknowledge that proprietary platform data prevent release of exact usage-frequency statistics. In revision we will expand §4.1 with explicit rationale and examples of included knowledge-heavy tasks (e.g., multi-turn regulatory pricing), add a limitations paragraph in §5 qualifying the interpretation of performance gaps, and note the emphasis on visually salient cases as a deliberate design choice rather than an unintended bias. revision: partial
- We cannot provide proprietary usage-frequency statistics from the source e-commerce platforms.
Circularity Check
No circularity: benchmark construction relies on external data collection and expert protocols
full rationale
The paper constructs OxyEcomBench by sourcing instances from authentic e-commerce platforms, applying expert-verified difficulty rubrics, and evaluating 20 external models. No equations, fitted parameters, or self-referential derivations exist. Central claims about performance gaps rest on the benchmark's task coverage and results, not on any reduction to prior self-citations or definitions. Self-citations, if present, are not load-bearing for any derivation chain. This is a standard benchmark paper with independent empirical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Domain experts can reliably assign stable P0-P3 difficulty labels and identify visually salient cases
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearOxyEcomBench ... 29 tasks ... four-level P0–P3 rubric ... visually salient multimodal cases
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Y ong Jae Lee. Visual instruction tuning. In Advances in Neural Information Processing Systems , 2023
work page 2023
-
[3]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Y ang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shopping MMLU: A massive multi-task online shopping benchmark for large language models
Yilun Jin, Zheng Li, Chenwei Zhang, Tianyu Cao, Yifan Gao, Pratik Jayarao, Mao Li, Xin Liu, Ritesh Sarkhel, Xianfeng Tang, Haodong Wang, Zhengyang Wang, Wenju Xu, Jingfeng Y ang, Qingyu Yin, Xian Li, Priyanka Nigam, Yi Xu, Kai Chen, Qiang Y ang, Meng Jiang, and Bing Yin. Shopping MMLU: A massive multi-task online shopping benchmark for large language mode...
work page 2024
-
[5]
Haoxin Wang, Xianhan Peng, Huang Cheng, Yizhe Huang, Ming Gong, Chenghan Y ang, Y ang Liu, and Jiang Lin. ECom-Bench: Can LLM agent resolve real-world e-commerce customer support issues? In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2025
work page 2025
-
[6]
Shuyi Xie, Ziqin Liew, Hailing Zhang, Haibo Zhang, Ling Hu, Zhiqiang Zhou, Shuman Liu, and Anxiang Zeng. EcomEval: Towards reliable evaluation of large language models for mul- tilingual and multimodal e-commerce applications. arXiv preprint arXiv:2510.20632, 2025
-
[7]
RAIR: A rule-aware multimodal benchmark for challenging e-commerce relevance assessment
Chenji Lu, Zhuo Chen, Hui Zhao, Zhenyi Wang, Pengjie Wang, Chuan Y u, and Jian Xu. RAIR: A rule-aware multimodal benchmark for challenging e-commerce relevance assessment. arXiv preprint arXiv:2512.24943, 2025
-
[8]
VQA: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. VQA: Visual question answering. In Proceedings of the IEEE international conference on computer vision , 2015
work page 2015
-
[9]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna V edantam, Saurabh Gupta, Piotr Dollar, and C Lawrence Zitnick. Microsoft COCO captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
OK-VQA: A visual question answering benchmark requiring external knowledge
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. OK-VQA: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019
work page 2019
-
[11]
Towards VQA models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Y u Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2019
work page 2019
-
[12]
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models
Chaoyou Fu, Peixian Chen, Y unhang Shen, Y ulei Qin, Mengdan Zhang, Xu Lin, Jinrui Y ang, Xiawu Zheng, Ke Li, Xing Sun, Y unsheng Wu, Rongrong Ji, Caifeng Shan, and Ran He. MME: A comprehensive evaluation benchmark for multimodal large language models. arXiv preprint arXiv:2306.13394, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Y uan Liu, Haodong Duan, Y uanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Y uan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. MMBench: Is your multi-modal model an all-around player? In European Conference on Computer Vision, 2024
work page 2024
-
[14]
MM-V et: Evaluating large multimodal models for integrated capabil- ities
Weihao Y u, Zhengyuan Y ang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. MM-V et: Evaluating large multimodal models for integrated capabil- ities. In International Conference on Machine Learning , 2024
work page 2024
-
[15]
TouchStone: Evaluating vision-language models by language models
Shuai Bai, Shusheng Y ang, Jinze Bai, Peng Wang, Xingxuan Zhang, Junyang Lin, Xinggang Wang, Chang Zhou, and Jingren Zhou. TouchStone: Evaluating vision-language models by language models. arXiv preprint arXiv:2308.16890, 2023. 10
-
[16]
L VLM-eHub: A comprehensive evaluation benchmark for large vision-language models
Peng Xu, Wenqi Shao, Kaipeng Zhang, Peng Gao, Shuo Liu, Meng Lei, Fanqing Meng, Siyuan Huang, Y u Qiao, and Ping Luo. L VLM-eHub: A comprehensive evaluation benchmark for large vision-language models. arXiv preprint arXiv:2306.09265, 2023
-
[17]
LAMM: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark
Zhenfei Yin, Jiong Wang, Jianjian Cao, Zhelun Shi, Dingning Liu, Mukai Li, Xiaoshui Huang, Zhiyong Wang, Lu Sheng, Lei Bai, Jing Shao, and Wanli Ouyang. LAMM: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. In Advances in Neural Information Processing Systems, 2023
work page 2023
-
[18]
Learn to explain: Multimodal reasoning via thought chains for science question answering
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[19]
MathVista: Evaluating mathematical rea- soning of foundation models in visual contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. MathVista: Evaluating mathematical rea- soning of foundation models in visual contexts. In International Conference on Learning Representations, 2024
work page 2024
-
[20]
MMMU: A massive multi-discipline mul- timodal understanding and reasoning benchmark for expert AGI
Xiang Y ue, Y uansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Y uxuan Sun, et al. MMMU: A massive multi-discipline mul- timodal understanding and reasoning benchmark for expert AGI. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
work page 2024
-
[21]
CMMU: A benchmark for chinese multi-modal multi-type question understanding and reasoning
Zheqi He, Xinya Wu, Pengfei Zhou, Richeng Xuan, Guang Liu, Xi Y ang, Qiannan Zhu, and Hua Huang. CMMU: A benchmark for chinese multi-modal multi-type question understanding and reasoning. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024
work page 2024
-
[22]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. ChartQA: A benchmark for question answering about charts with visual and logical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022 , 2022
work page 2022
-
[23]
BLINK: Multimodal large language models can see but not perceive
Xingyu Fu, Y ushi Hu, Bangzheng Li, Y u Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. BLINK: Multimodal large language models can see but not perceive. In European Conference on Computer Vision, 2024
work page 2024
-
[24]
MAN- TIS: Interleaved multi-image instruction tuning
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. MAN- TIS: Interleaved multi-image instruction tuning. Transactions on Machine Learning Research, 2024
work page 2024
-
[25]
MuirBench: A comprehensive benchmark for robust multi-image understanding
Fei Wang, Xingyu Fu, James Y Huang, Zekun Li, Qin Liu, Xiaogeng Liu, Mingyu Derek Ma, Nan Xu, Wenxuan Zhou, Kai Zhang, et al. MuirBench: A comprehensive benchmark for robust multi-image understanding. In International Conference on Learning Representations , 2025
work page 2025
-
[26]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , 2023
work page 2023
-
[27]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Y aser Y acoob, Dinesh Manocha, and Tianyi Zhou. Hallusion- Bench: An advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Visi...
work page 2024
-
[28]
SEED-Bench: Benchmarking multimodal large language models
Bohao Li, Y uying Ge, Yixiao Ge, Guangzhi Wang, Rui Wang, Ruimao Zhang, and Ying Shan. SEED-Bench: Benchmarking multimodal large language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , 2024
work page 2024
-
[29]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Y uhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Y u Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? arXiv preprint arXiv:2403.20330, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Aligning large multimodal models with factually augmented RLHF
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Y an Gui, Y u-Xiong Wang, Yiming Y ang, Kurt Keutzer, and Trevor Dar- rell. Aligning large multimodal models with factually augmented RLHF. arXiv preprint arXiv:2309.14525, 2023
-
[31]
AMBER: An LLM-free multi-dimensional benchmark for MLLMs hallucination evaluation
Junyang Wang, Y uhang Wang, Jing Zhang, Y ukai Gu, Haitao Jia, Jiaqi Wang, Jitao Sang, Guohai Xu, Haiyang Xu, Ming Y an, and Ji Zhang. AMBER: An LLM-free multi-dimensional benchmark for MLLMs hallucination evaluation. arXiv preprint arXiv:2311.07397, 2023
-
[32]
ChineseEcomQA: A scal- able e-commerce concept evaluation benchmark for large language models
Haibin Chen, Kangtao Lv, Chengwei Hu, Y anshi Li, Y ujin Y uan, Y ancheng He, Xingyao Zhang, Langming Liu, Shilei Liu, Wenbo Su, and Bo Zheng. ChineseEcomQA: A scal- able e-commerce concept evaluation benchmark for large language models. arXiv preprint arXiv:2502.20196, 2025
-
[33]
Mix-ECom: Towards mixed-type e-commerce dialogues with complex domain rules
Chenyu Zhou, Xiaoming Shi, Hui Qiu, Y ankai Jiang, Shaoguo Liu, Tingting Gao, Haitao Leng, Xiawu Zheng, and Rongrong Ji. Mix-ECom: Towards mixed-type e-commerce dialogues with complex domain rules. In International Conference on Learning Representations , 2026
work page 2026
-
[34]
EcomMMMU: Strategic utilization of visuals for robust multimodal e-commerce models
Xinyi Ling, Hanwen Du, Zhihui Zhu, and Xia Ning. EcomMMMU: Strategic utilization of visuals for robust multimodal e-commerce models. In Proceedings of the International Joint Conference on Natural Language Processing and the Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , 2025
work page 2025
-
[35]
Daoze Zhang, Zhanheng Nie, Jianyu Liu, Chenghan Fu, Wanxian Guan, Y uan Gao, Jun Song, Pengjie Wang, Jian Xu, and Bo Zheng. MOON: Generative MLLM-based multimodal repre- sentation learning for e-commerce product understanding. In Proceedings of the 19th ACM International Conference on Web Search and Data Mining , 2026
work page 2026
- [36]
-
[37]
EcomBench: Towards holistic evaluation of foundation agents in e-commerce
Rui Min, Zile Qiao, Ze Xu, Jiawen Zhai, Wenyu Gao, Xuanzhong Chen, Haozhen Sun, Zhen Zhang, Xinyu Wang, Hong Zhou, et al. EcomBench: Towards holistic evaluation of foundation agents in e-commerce. arXiv preprint arXiv:2512.08868, 2025
-
[38]
EComStage: Stage-wise and orientation-specific benchmarking for large language models in e-commerce
Kaiyan Zhao, Zijie Meng, Zheyong Xie, Jin Duan, Y ao Hu, Zuozhu Liu, and Shaosheng Cao. EComStage: Stage-wise and orientation-specific benchmarking for large language models in e-commerce. arXiv preprint arXiv:2601.02752, 2026
-
[39]
WebShop: Towards scalable real-world web interaction with grounded language agents
Shunyu Y ao, Howard Chen, John Y ang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. In Advances in Neural Information Processing Systems, 2022
work page 2022
-
[40]
OpenAI. GPT-5 system card. https://cdn.openai.com/gpt-5-system-card.pdf , 2025
work page 2025
-
[41]
Google DeepMind. Gemini 3.1 Pro model card. https://deepmind.google/models/ model-cards/gemini-3-1-pro/ , 2026. 12 A Per-task Evaluation Results To complement the aggregated results in Section 4.2, Table 4 reports the per-task scores of all evalu- ated models on the 29 tasks in O XYECOM BENCH . The final Average row uses the same non-missing task-level mac...
work page 2026
-
[42]
Visual Hallucination and Fine-Grained Recognition Difficulties. E-commerce applications necessitate highly precise visual inspection. In tasks like Product Damage Detection or MGC-to- Product Consistency V erification, models must detect subtle defects, texture differences, or minor missing accessories. General MLLMs frequently suffer from visual hallucinat...
-
[43]
1" if there is damage, and output
Lack of Domain-Specific Professional Knowledge. The e-commerce ecosystem operates on specialized terminology and distinct operational concepts. General MLLMs lack sufficient expo- 15 You are a professional e-commerce visual quality control expert. Your task is to check whether the product display image for advertising (the right image) faithfully restores t...
-
[44]
Incomplete product display (main body or key components missing)
Complex Visual Distributions in E-commerce Scenarios. Unlike standard natural images, e- commerce visuals (e.g., product detail pages, promotional posters, and user-generated reviews) are highly complex. They typically feature intricate layouts, dense text overlays, multiple sub-images, and varied professional photography styles. This significant distribut...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.