Recognition: no theorem link
N-vium: Mixture-of-Exits Transformer for Accelerated Exact Generation
Pith reviewed 2026-05-14 20:41 UTC · model grok-4.3
The pith
N-vium mixture-of-exits transformers reach 57.9 percent wall-clock speedup at identical perplexity by routing tokens to multiple exit depths
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
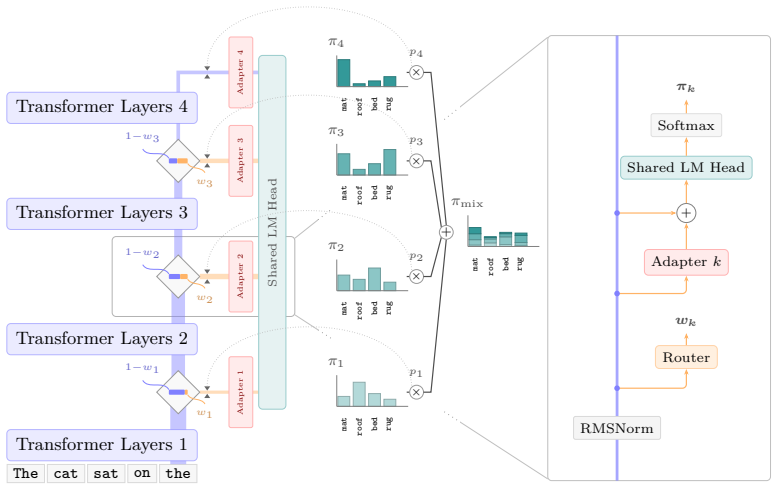
N-vium defines the next-token distribution as a learned mixture over exit heads at multiple depths with token-adaptive routing. This formulation recovers the standard transformer exactly when intermediate heads receive zero weight. Exact sampling is preserved, and complete KV caches are recovered by deferring upper-layer computation and batching it with later tokens. At 1.5B scale the model achieves 57.9 percent wall-clock speedup over a parameter- and data-matched baseline at unchanged perplexity.
What carries the argument
A learned mixture over multiple exit heads with token-adaptive routing that generalizes the standard transformer and enables deferred upper-layer computation for cache recovery
Load-bearing premise
A learned mixture over multiple exit heads can be trained to exactly match the perplexity of the full-depth model while enabling parallelization, cache deferral, and exact sampling without quality degradation or instability.
What would settle it
Training an N-vium model in which the mixture cannot reach the baseline perplexity despite matched compute, or observing that deferred cache recovery produces inconsistent next-token samples compared to the full model.
Figures




read the original abstract
Improving the inference efficiency of autoregressive transformers typically means reducing FLOPs per token, usually through approximations that degrade model quality. We introduce N-vium, a mixture-of-exits transformer that partially parallelizes computation across depth on standard hardware, increasing effective FLOPs per second rather than minimizing compute per token. N-vium attaches prediction heads at multiple depths and defines the next-token distribution as a learned mixture over these exits, with token-adaptive routing. This formulation strictly generalizes the standard transformer, which is recovered exactly when routing assigns zero mass to all intermediate heads. Sampling from the mixture is exact, and complete KV caches are recovered by deferring the upper-layer computation and batching it with later tokens. We pretrain N-vium at scales up to 1.5B parameters. Our largest model reaches 57.9% wall-clock speedup over a parameter- and data-matched standard transformer at no perplexity cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces N-vium, a mixture-of-exits transformer that attaches prediction heads at multiple depths and defines the next-token distribution as a learned mixture over these exits with token-adaptive routing. It claims this architecture strictly generalizes the standard transformer (recovered exactly when routing assigns zero mass to intermediate heads), enables exact sampling from the mixture, recovers complete KV caches by deferring upper-layer computation and batching with later tokens, and achieves up to 57.9% wall-clock speedup over a parameter- and data-matched standard transformer at no perplexity cost, with pretraining demonstrated on models up to 1.5B parameters.
Significance. If the reported training dynamics hold and the mixture reliably matches full-model perplexity while delivering the claimed speedup, the work would provide a concrete method for increasing effective FLOPs per second on standard hardware without quality degradation, addressing a key limitation of approximation-based inference optimizations. The explicit generalization property and exactness guarantees are notable strengths that distinguish it from typical early-exit or speculative decoding approaches.
major comments (2)
- [Abstract] Abstract and training description: the central claim that the mixture reaches the same perplexity minimum as a parameter-matched standard transformer when non-zero mass is placed on intermediate exits lacks any derivation or analysis showing that joint optimization of exit heads, routing network, and backbone avoids gradient interference or shifts from the full-depth optimum; the empirical 'no perplexity cost' statement therefore rests on unverified training dynamics rather than architectural guarantees.
- [Results section] § on experimental setup (implied by results): no details are provided on the training procedure for the exit mixture and routing parameters, baseline matching criteria, routing implementation, or statistical controls (e.g., multiple seeds, variance reporting), which are load-bearing for validating the 57.9% speedup claim at zero perplexity cost.
minor comments (2)
- [Method] Notation for the mixture distribution and routing function should be defined more explicitly with equations to clarify how exact sampling is performed without approximation.
- [Figures] Figure captions and axis labels for speedup and perplexity comparisons could be clarified to indicate whether they report wall-clock time or FLOPs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript to strengthen the presentation of training dynamics and experimental details.
read point-by-point responses
-
Referee: [Abstract] Abstract and training description: the central claim that the mixture reaches the same perplexity minimum as a parameter-matched standard transformer when non-zero mass is placed on intermediate exits lacks any derivation or analysis showing that joint optimization of exit heads, routing network, and backbone avoids gradient interference or shifts from the full-depth optimum; the empirical 'no perplexity cost' statement therefore rests on unverified training dynamics rather than architectural guarantees.
Authors: We agree that the manuscript provides no formal derivation proving identical convergence under joint optimization, as the loss landscape does not admit a simple closed-form guarantee. The architecture strictly recovers the standard transformer when intermediate routing mass is zero, but the claim of no perplexity cost is empirical. In the revision we will add a dedicated paragraph in the methods section and an appendix subsection that (i) describes the mixture loss and separate head gradients, (ii) reports training curves comparing N-vium to matched standard transformers at 350M and 1.5B scale, and (iii) discusses observed mitigation of interference via the token-adaptive router and auxiliary exit losses. We will not claim an unproven theoretical guarantee. revision: partial
-
Referee: [Results section] § on experimental setup (implied by results): no details are provided on the training procedure for the exit mixture and routing parameters, baseline matching criteria, routing implementation, or statistical controls (e.g., multiple seeds, variance reporting), which are load-bearing for validating the 57.9% speedup claim at zero perplexity cost.
Authors: We accept that the current manuscript omits these load-bearing details. The revised version will expand the experimental section with: (1) the exact joint optimization procedure (loss weights, optimizer, schedule, and when routing parameters are introduced); (2) precise baseline matching (total non-embedding parameters, data tokens, and training steps); (3) routing network architecture (input features, layers, and output softmax); and (4) statistical controls (perplexity and wall-clock speedup averaged over three independent seeds with standard deviations). These additions will be placed before the main results tables. revision: yes
Circularity Check
No circularity; empirical speedup and perplexity claims are measured directly against matched baselines.
full rationale
The paper defines N-vium as a strict architectural generalization of the standard transformer (recovered exactly when the router assigns zero mass to intermediate exits). All reported results—57.9% wall-clock speedup at matched perplexity—are obtained by pretraining models up to 1.5B parameters and measuring wall-clock time and validation perplexity against explicitly parameter- and data-matched standard transformers. No equation or claim reduces a derived quantity to its own fitted inputs by construction, no uniqueness theorem is invoked via self-citation, and no ansatz is smuggled in. The training objective and routing are optimized jointly, but the paper presents the outcome as an empirical observation rather than a guaranteed identity.
Axiom & Free-Parameter Ledger
free parameters (1)
- exit mixture and routing parameters
axioms (1)
- standard math Standard autoregressive transformer forward pass and KV cache mechanics
invented entities (1)
-
Mixture-of-exits routing mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ainslie, J
J. Ainslie, J. Lee-Thorp, M. de Jong, Y. Zemlyanskiy, F. Lebron, and S. Sanghai. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[2]
Alizadeh-Vahid, S
K. Alizadeh-Vahid, S. I. Mirzadeh, H. Shahrkokhi, D. Belenko, F. Sun, M. Cho, et al. Duo-LLM: A Framework for Studying Adaptive Computation in Large Language Models. InProceedings of The 4th NeurIPS Efficient Natural Language and Speech Processing Workshop, 2024
2024
-
[3]
S. Bae, J. Ko, H. Song, and S.-Y. Yun. Fast and Robust Early-Exiting Framework for Autoregressive Language Models with Synchronized Parallel Decoding. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[4]
S. Bae, Y. Kim, R. Bayat, S. Kim, J. Ha, T. Schuster, et al. Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation. InAd- vances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[5]
H. Bai, W. Zhang, L. Hou, L. Shang, J. Jin, X. Jiang, et al. BinaryBERT: Pushing the Limit of BERT Quantization. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021
2021
-
[6]
Eliciting Latent Predictions from Transformers with the Tuned Lens
N. Belrose, I. Ostrovsky, L. McKinney, Z. Furman, L. Smith, D. Halawi, et al. Eliciting Latent Predictions from Transformers with the Tuned Lens, 2023. arXiv:2303.08112
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Biderman, H
S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, L. O’Brien, E. Hallahan, et al. Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling. In Proceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[8]
Y. Bisk, R. Zellers, R. Le Bras, J. Gao, and Y. Choi. PIQA: Reasoning about Physical Commonsense in Natural Language. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
2020
-
[9]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, et al. Language Models are Few-Shot Learners. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[10]
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper. Accelerating Large Language Model Decoding with Speculative Sampling, 2023. arXiv:2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, et al. Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge, 2018. arXiv:1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Dehghani, S
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and L. Kaiser. Universal Transformers. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[13]
Skipdecode: Autoregressive skip decoding with batching and caching for efficient llm inference,
L. Del Corro, A. Del Giorno, S. Agarwal, B. Yu, A. Awadallah, and S. Mukherjee. SkipDecode: Autoregressive Skip Decoding with Batching and Caching for Efficient LLM Inference, 2023. arXiv:2307.02628
-
[14]
N. Du, Y. Huang, A. M. Dai, S. Tong, D. Lepikhin, Y. Xu, et al. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts. InProceedings of the 39th International Conference on Machine Learning (ICML), 2022
2022
-
[15]
Elbayad, J
M. Elbayad, J. Gu, E. Grave, and M. Auli. Depth-Adaptive Transformer. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[16]
Elhoushi, A
M. Elhoushi, A. Shrivastava, D. Liskovich, B. Hosmer, B. Wasti, L. Lai, et al. LayerSkip: Enabling Early Exit Inference and Self-Speculative Decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024. 10
2024
-
[17]
A. Fan, E. Grave, and A. Joulin. Reducing Transformer Depth on Demand with Structured Dropout. InInternational Conference on Learning Representations (ICLR), 2020
2020
-
[18]
Fedus, B
W. Fedus, B. Zoph, and N. Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.Journal of Machine Learning Research, 23 (1), 2022
2022
-
[19]
L. Gao, J. Tow, B. Abbasi, S. Biderman, S. Black, A. DiPofi, et al. A Framework for Few-Shot Language Model Evaluation, 2023. URLhttps://github.com/EleutherAI/ lm-evaluation-harness. Version 0.4.0
2023
-
[20]
M. Geva, A. Caciularu, K. Wang, and Y. Goldberg. Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022
2022
-
[21]
A. Graves. Adaptive Computation Time for Recurrent Neural Networks, 2016. arXiv:1603.08983
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Hendrycks, C
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, et al. Measuring Massive Multitask Language Understanding. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[23]
Hinton, O
G. Hinton, O. Vinyals, and J. Dean. Distilling the Knowledge in a Neural Network,
-
[24]
Hoffmann, S
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, et al. An Empirical Analysis of Compute-Optimal Large Language Model Training. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[25]
L. Hou, Z. Huang, L. Shang, X. Jiang, X. Chen, and Q. Liu. DynaBERT: Dynamic BERT with Adaptive Width and Depth. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[26]
A. Q. Jiang, A. Sablayrolles, A. Roux, A. Mensch, B. Savary, C. Bamford, et al. Mixtral of Experts, 2024. arXiv:2401.04088
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
X. Jiao, Y. Yin, L. Shang, X. Jiang, X. Chen, L. Li, et al. TinyBERT: Distilling BERT for Natural Language Understanding. InFindings of the Association for Computational Linguistics: EMNLP 2020, 2020
2020
-
[28]
Kavehzadeh, M
P. Kavehzadeh, M. Valipour, M. Tahaei, A. Ghodsi, B. Chen, and M. Rezagholizadeh. Sorted LLaMA: Unlocking the Potential of Intermediate Layers of Large Language Models for Dynamic Inference. InFindings of the Association for Computational Linguistics: EACL 2024, 2024
2024
-
[29]
Y. Kaya, S. Hong, and T. Dumitras. Shallow-Deep Networks: Understanding and Mitigating Network Overthinking. InProceedings of the 36th International Conference on Machine Learning (ICML), 2019
2019
-
[30]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, et al. Efficient Memory Management for Large Language Model Serving with Paged Attention. InProceedings of the 29th Symposium on Operating Systems Principles (SOSP), 2023
2023
-
[31]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
N. Lambert, J. Morrison, V. Pyatkin, S. Huang, H. Ivison, F. Brahman, et al. Tulu 3: Pushing Frontiers in Open Language Model Post-Training, 2025. arXiv:2411.15124
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Leviathan, M
Y. Leviathan, M. Kalman, and Y. Matias. Fast Inference from Transformers via Speculative Decoding. InProceedings of the 40th International Conference on Machine Learning (ICML), 2023
2023
-
[33]
Y. Liu, F. Meng, J. Zhou, Y. Chen, and J. Xu. Faster Depth-Adaptive Transformers. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2021. 11
2021
-
[34]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations (ICLR), 2019
2019
-
[35]
Michel, O
P. Michel, O. Levy, and G. Neubig. Are Sixteen Heads Really Better than One? In Advances in Neural Information Processing Systems (NeurIPS), 2019
2019
-
[36]
Mihaylov, P
T. Mihaylov, P. Clark, T. Khot, and A. Sabharwal. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018
2018
-
[37]
Interpreting GPT: The Logit Lens, 2020
nostalgebraist. Interpreting GPT: The Logit Lens, 2020. URLhttps://www.lesswrong. com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens. LessWrong blog post
2020
-
[38]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, et al. Training Language Models to Follow Instructions with Human Feedback. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[39]
Raffel, N
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
2020
-
[40]
D. Raposo, S. Ritter, B. Richards, T. Lillicrap, P. C. Humphreys, and A. Santoro. Mixture-of-Depths: Dynamically Allocating Compute in Transformer-based Language Models, 2024. arXiv:2404.02258
-
[41]
Sakaguchi, R
K. Sakaguchi, R. Le Bras, C. Bhagavatula, and Y. Choi. WinoGrande: An Adversarial Winograd Schema Challenge at Scale. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
2020
-
[42]
V. Sanh, L. Debut, J. Chaumond, and T. Wolf. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter, 2019. arXiv:1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
Schuster, A
T. Schuster, A. Fisch, T. Jaakkola, and R. Barzilay. Consistent Accelerated Inference via Confident Adaptive Transformers. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021
2021
-
[44]
Schuster, A
T. Schuster, A. Fisch, J. Gupta, M. Dehghani, D. Bahri, V. Tran, et al. Confident Adaptive Language Modeling. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
- [45]
-
[46]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, et al. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, 2024. arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
S. Shen, Z. Dong, J. Ye, L. Ma, Z. Yao, A. Gholami, et al. Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
2020
-
[48]
Stern, N
M. Stern, N. Shazeer, and J. Uszkoreit. Blockwise Parallel Decoding for Deep Autore- gressive Models. InAdvances in Neural Information Processing Systems (NeurIPS), 2018
2018
-
[49]
Z. Sun, H. Yu, X. Song, R. Liu, Y. Yang, and D. Zhou. MobileBERT: a Compact Task-Agnostic BERT for Resource-Limited Devices. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[50]
Taori, I
R. Taori, I. Gulrajani, T. Zhang, Y. Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto. Alpaca: A Strong, Replicable Instruction-Following Model, 2023. URL https://crfm.stanford.edu/2023/03/13/alpaca.html. Accessed May 2, 2026. 12
2023
-
[51]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, et al. Llama 2: Open Foundation and Fine-Tuned Chat Models, 2023. arXiv:2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[53]
X. Wang, F. Yu, Z.-Y. Dou, T. Darrell, and J. E. Gonzalez. SkipNet: Learning Dynamic Routing in Convolutional Networks. InComputer Vision – ECCV 2018, 2018
2018
-
[54]
H. Xia, Z. Yang, Q. Dong, P. Wang, Y. Li, T. Ge, et al. Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding. In Findings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[55]
J. Xin, R. Tang, J. Lee, Y. Yu, and J. Lin. DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[56]
J. Xin, R. Tang, Y. Yu, and J. Lin. BERxiT: Early Exiting for BERT with Better Fine-Tuning and Extension to Regression. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2021
2021
-
[57]
H. Yin, A. Vahdat, J. M. Alvarez, A. Mallya, J. Kautz, and P. Molchanov. A-ViT: Adaptive Tokens for Efficient Vision Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[58]
Zellers, A
R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi. HellaSwag: Can a Machine Really Finish Your Sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[59]
Z. Zeng, Y. Hong, H. Dai, H. Zhuang, and C. Chen. ConsistentEE: A Consistent and Hardness-Guided Early Exiting Method for Accelerating Language Models Inference. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024
2024
-
[60]
Zhang, J
J. Zhang, J. Wang, H. Li, L. Shou, K. Chen, G. Chen, et al. Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
2024
-
[61]
W. Zhou, C. Xu, T. Ge, J. McAuley, K. Xu, and F. Wei. BERT Loses Patience: Fast and Robust Inference with Early Exit. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[62]
Y. Zhou, T. Lei, H. Liu, N. Du, Y. Huang, V. Y. Zhao, et al. Mixture-of-Experts with Expert Choice Routing. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[63]
Scaling Latent Reasoning via Looped Language Models
R.-J. Zhu, Z. Wang, K. Hua, T. Zhang, Z. Li, H. Que, et al. Scaling Latent Reasoning via Looped Language Models, 2025. arXiv:2510.25741. 13 A Implementation Details Training schedule.Optimizing Lmix without any routing regularization leads to router collapse, where all tokens are routed to the same exit. We therefore split training into two phases. In the...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.