Recognition: 2 theorem links
· Lean TheoremSwitching Successor Measures for Hierarchical Zero-shot Reinforcement Learning
Pith reviewed 2026-05-14 20:23 UTC · model grok-4.3
The pith
Switching successor measures arise naturally from classical ones and let a single forward-backward representation produce both high-level subgoals and low-level actions in zero-shot hierarchical RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Switching successor measures arise naturally from classical successor measures while preserving their underlying structure. Building on this result, FB π-Switch extracts both a high-level subgoal-selection policy and a low-level control policy directly from forward-backward representations, allowing hierarchical behavior to emerge from a single learned representation without additional supervision, fixed horizons, or manually designed subgoals.
What carries the argument
Switching successor measures, an extension of classical successor measures that decomposes long-horizon decisions into subproblems while preserving the original representation structure for direct policy extraction.
If this is right
- Hierarchical control emerges without fixed temporal abstractions or goal-conditioned objectives.
- The same representation supports both subgoal selection and primitive actions for general rewards.
- Performance improves over non-hierarchical baselines on the tested domains.
- Results match state-of-the-art hierarchical methods in goal-conditioned settings.
Where Pith is reading between the lines
- Single-representation hierarchies could reduce the engineering overhead of training separate high-level and low-level modules.
- The approach may extend naturally to environments with sparse or non-stationary rewards where manual subgoal design is costly.
- Testing preservation of the switching property under changes in dynamics or reward sparsity would clarify the method's robustness.
Load-bearing premise
Switching successor measures can be derived from classical ones in a way that preserves enough structure to support emergent hierarchical behavior from a single forward-backward representation across both goal-conditioned and general reward tasks.
What would settle it
A test showing that the derived high-level policy selects incoherent subgoals or the low-level policy fails to achieve them on a general reward task without goal conditioning would falsify the central claim.
Figures










read the original abstract
Hierarchical reinforcement learning can improve generalization by decomposing long-horizon decision-making into simpler subproblems. However, existing approaches often rely on restrictive design choices, such as fixed temporal abstractions or goal-conditioned objectives, which largely confine them to goal-reaching tasks and limit their applicability to general reward functions. In this paper, we introduce switching successor measures, an extension of successor measures that enables hierarchical control in zero-shot reinforcement learning without additional supervision, fixed horizons, or manually designed subgoals. We show that switching successor measures arise naturally from classical successor measures while preserving their underlying structure. Building on this result, we propose FB $\pi$-Switch, an algorithm that extracts both a high-level subgoal-selection policy and a low-level control policy directly from forward-backward (FB) representations, allowing hierarchical behavior to emerge from a single learned representation. Experiments on both goal-conditioned and general reward-based tasks show that FB $\pi$-Switch improves over non-hierarchical baselines and matches state-of-the-art hierarchical methods in goal-conditioned settings. These results demonstrate that structured successor representations provide a flexible foundation for hierarchical zero-shot reinforcement learning beyond goal-reaching tasks. Our project website is available at: https://stestokth.github.io/switching-successors/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that switching successor measures arise naturally from classical successor measures while preserving their underlying structure, enabling the FB π-Switch algorithm to extract both a high-level subgoal-selection policy and a low-level control policy directly from a single forward-backward (FB) representation. This supports hierarchical zero-shot RL for both goal-conditioned and general-reward tasks without additional supervision, fixed horizons, or manually designed subgoals. Experiments show improvements over non-hierarchical baselines and parity with state-of-the-art hierarchical methods on goal-conditioned tasks.
Significance. If the derivation of switching successor measures holds with exact structure preservation for arbitrary rewards, the work would provide a principled foundation for emergent hierarchical behavior in zero-shot RL using successor representations, extending beyond the typical goal-reaching restriction of prior FB and successor-measure methods. The single-representation extraction of both policy levels is a notable strength for generalization in long-horizon settings.
major comments (1)
- [§3] §3 (Switching Successor Measures): The central claim requires an explicit derivation showing that the switching construction extends classical successor measures without introducing hidden dependencies on goal-indicator structure when the reward is an arbitrary function. The current presentation does not clarify whether the switching operator preserves the FB representation properties exactly under general rewards, which is load-bearing for the extension to non-goal-reaching zero-shot RL.
minor comments (2)
- [Abstract] The abstract asserts natural emergence and structure preservation but would benefit from a one-sentence reference to the key preserved property or equation.
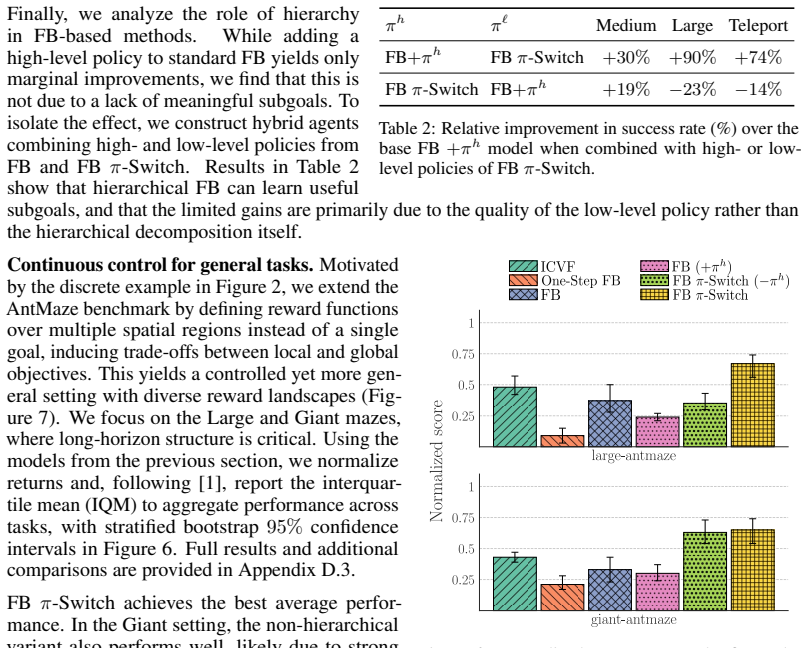
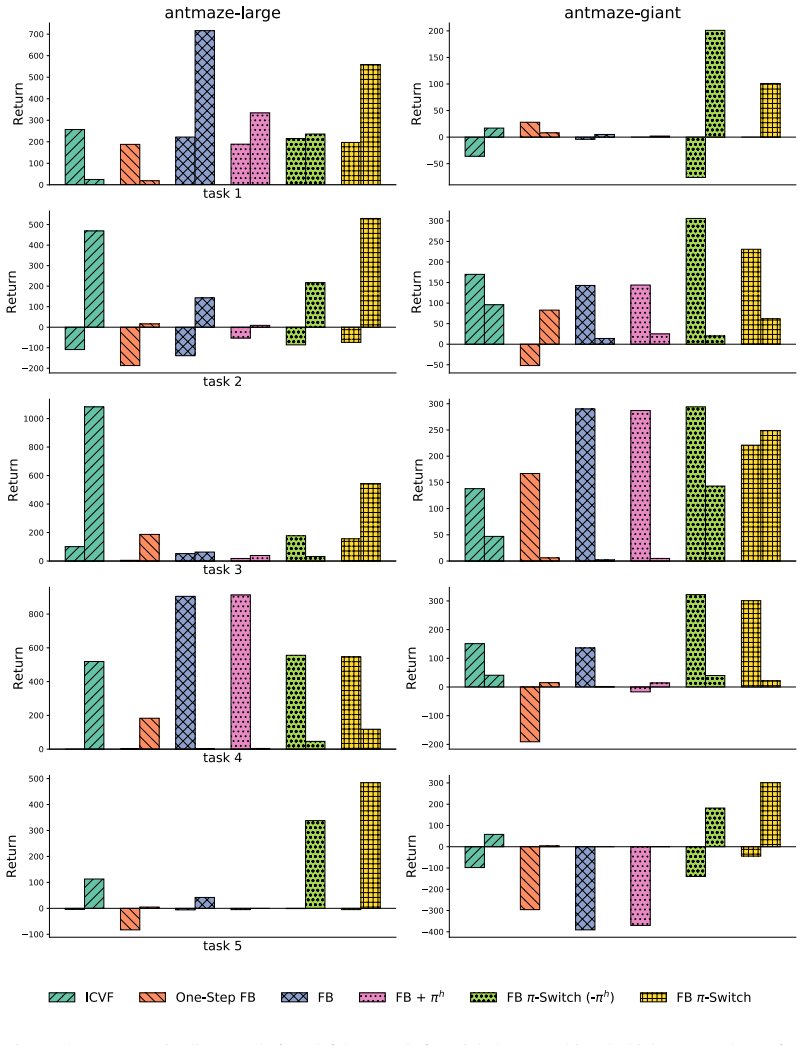
- [Experiments] Figure captions and experimental setup descriptions should explicitly state the reward functions used in the general-reward tasks to allow verification of the non-goal-conditioned claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and for recognizing the potential significance of switching successor measures for hierarchical zero-shot RL. We address the single major comment below and will incorporate the requested clarification in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Switching Successor Measures): The central claim requires an explicit derivation showing that the switching construction extends classical successor measures without introducing hidden dependencies on goal-indicator structure when the reward is an arbitrary function. The current presentation does not clarify whether the switching operator preserves the FB representation properties exactly under general rewards, which is load-bearing for the extension to non-goal-reaching zero-shot RL.
Authors: We agree that an explicit derivation would strengthen the presentation. In the revised version we will expand §3 with a step-by-step derivation that begins from the classical successor measure M^π(s,a) = E[∑_t γ^t r(s_t,a_t,s_{t+1}) | s_0=s,a_0=a] for an arbitrary bounded reward function r and shows that the switching operator S(M^π, g) = M^π(s,a) · 1_{g(s)} + (1-1_{g(s)})M^π(s,a) preserves the linear structure of the forward-backward representation exactly. The derivation relies only on the linearity of expectation and the definition of the indicator for the switching event; it does not embed any goal-specific structure beyond the arbitrary reward itself. Consequently the same FB π-Switch extraction procedure applies unchanged to general-reward tasks. We will also add a short corollary stating that the fixed-point properties of the FB representation remain invariant under this operator. revision: yes
Circularity Check
No significant circularity; switching successor measures introduced as independent extension
full rationale
The paper defines switching successor measures as an extension of classical successor measures that arises naturally while preserving structure, then builds FB π-Switch to extract hierarchical policies from a single FB representation. No equations, fitted parameters, or self-citations are quoted that reduce this construction to its inputs by definition. The derivation is presented as a structural preservation result enabling zero-shot hierarchical control for both goal-conditioned and general rewards, with experimental validation provided separately. The central claim retains independent content beyond renaming or self-referential fitting.
Axiom & Free-Parameter Ledger
invented entities (1)
-
switching successor measures
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesTheorem 1. For any s, w, s′ ∈ S and policy π, the following identity holds: M^{π_w→π}_s(s′) = M^{π_w}_s(s′) + [M^{π_w}_s(w)/M^{π_w}_w(w)] (M^π_w(s′) − M^{π_w}_w(s′)).
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective echoesCorollary 1. A^{π_w→π}_s(r) = V^{π_w}(s;r) + [M^{π_w}_s(w)/M^{π_w}_w(w)] (V^π(w;r) − V^{π_w}(w;r)) − V^π(s;r).
Reference graph
Works this paper leans on
-
[1]
Deep reinforcement learning at the edge of the statistical precipice
Rishabh Agarwal, Max Schwarzer, Pablo Samuel Castro, Aaron C Courville, and Marc Belle- mare. Deep reinforcement learning at the edge of the statistical precipice. InAdvances in Neural Information Processing Systems, volume 34, pages 29304–29320, 2021
2021
-
[2]
A unified framework for unsupervised reinforcement learning al- gorithms
Siddhant Agarwal, Caleb Chuck, Harshit Sikchi, Jiaheng Hu, Max Rudolph, Scott Niekum, Peter Stone, and Amy Zhang. A unified framework for unsupervised reinforcement learning al- gorithms. InWorkshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference, 2025
2025
-
[3]
Siddhant Agarwal, Harshit Sikchi, Peter Stone, and Amy Zhang. Proto successor measure: Representing the behavior space of an RL agent.arXiv preprint arXiv:2411.19418, 2024
-
[4]
Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning
Hongjoon Ahn, Heewoong Choi, Jisu Han, and Taesup Moon. Option-aware temporally abstracted value for offline goal-conditioned reinforcement learning. InAdvances in Neural Information Processing Systems, volume 38, pages 99833–99861, 2025
2025
-
[5]
OPAL: Offline primitive discovery for accelerating offline reinforcement learning
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. OPAL: Offline primitive discovery for accelerating offline reinforcement learning. InInternational Conference on Learning Representations, 2021
2021
-
[6]
Hindsight experience replay
Marcin Andrychowicz, Filip Wolski, Alex Ray, Jonas Schneider, Rachel Fong, Peter Welinder, Bob McGrew, Josh Tobin, OpenAI Pieter Abbeel, and Wojciech Zaremba. Hindsight experience replay. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[7]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. InProceedings of the AAAI Conference on Artificial Intelligence, volume 31, 2017
2017
-
[8]
Provably efficient Q-learning with low switching cost
Yu Bai, Tengyang Xie, Nan Jiang, and Yu-Xiang Wang. Provably efficient Q-learning with low switching cost. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[9]
Successor features for transfer in reinforcement learning
André Barreto, Will Dabney, Rémi Munos, Jonathan J Hunt, Tom Schaul, Hado P van Hasselt, and David Silver. Successor features for transfer in reinforcement learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[10]
Léonard Blier, Corentin Tallec, and Yann Ollivier. Learning successor states and goal-dependent values: A mathematical viewpoint.arXiv preprint arXiv:2101.07123, 2021
-
[11]
Finer behavioral foundation models via auto-regressive features and advantage weighting
Edoardo Cetin, Ahmed Touati, and Yann Ollivier. Finer behavioral foundation models via auto-regressive features and advantage weighting. InReinforcement Learning Conference, 2025
2025
-
[12]
Goal-conditioned reinforcement learning with imagined subgoals
Elliot Chane-Sane, Cordelia Schmid, and Ivan Laptev. Goal-conditioned reinforcement learning with imagined subgoals. InProceedings of the 38th International Conference on Machine Learning, volume 139, pages 1430–1440. PMLR, 2021
2021
-
[13]
PlanDQ: Hierarchical plan orchestration via D-conductor and Q-performer
Chang Chen, Junyeob Baek, Fei Deng, Kenji Kawaguchi, Caglar Gulcehre, and Sungjin Ahn. PlanDQ: Hierarchical plan orchestration via D-conductor and Q-performer. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 6397–6412. PMLR, 2024
2024
-
[14]
Jinwoo Choi, Sang-Hyun Lee, and Seung-Woo Seo. Chain-of-goals hierarchical policy for long-horizon offline goal-conditioned RL.arXiv preprint arXiv:2602.03389, 2026. 10
-
[15]
Optimal policy switching algorithms for reinforcement learning
Gheorghe Comanici and Doina Precup. Optimal policy switching algorithms for reinforcement learning. InProceedings of the 9th International Conference on Autonomous Agents and Multiagent Systems, volume 1, pages 709–714, 2010
2010
-
[16]
Shift before you learn: Enabling low-rank representations in reinforcement learning
Bastien Dubail, Stefan Stojanovic, and Alexandre Proutière. Shift before you learn: Enabling low-rank representations in reinforcement learning. InAdvances in Neural Information Pro- cessing Systems, volume 38, pages 72243–72305, 2025
2025
-
[17]
Diversity is all you need: Learning skills without a reward function
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. InInternational Conference on Learning Representations, 2019
2019
-
[18]
Contrastive learning as goal-conditioned reinforcement learning
Benjamin Eysenbach, Tianjun Zhang, Sergey Levine, and Russ R Salakhutdinov. Contrastive learning as goal-conditioned reinforcement learning. InAdvances in Neural Information Processing Systems, volume 35, pages 35603–35620, 2022
2022
-
[19]
Compositional planning with jumpy world models
Jesse Farebrother, Matteo Pirotta, Andrea Tirinzoni, Marc G Bellemare, Alessandro Lazaric, and Ahmed Touati. Compositional planning with jumpy world models. InICLR 2026 the 2nd Workshop on World Models: Understanding, Modelling and Scaling, 2026
2026
-
[20]
Unsupervised zero-shot rein- forcement learning via functional reward encodings
Kevin Frans, Seohong Park, Pieter Abbeel, and Sergey Levine. Unsupervised zero-shot rein- forcement learning via functional reward encodings. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 13927–13942. PMLR, 2024
2024
-
[21]
Reinforcement learning from passive data via latent intentions
Dibya Ghosh, Chethan Anand Bhateja, and Sergey Levine. Reinforcement learning from passive data via latent intentions. InProceedings of the 40th International Conference on Machine Learning, volume 202, pages 11321–11339. PMLR, 2023
2023
-
[22]
Physics-informed value learner for offline goal-conditioned reinforcement learning
Vittorio Giammarino, Ruiqi Ni, and Ahmed H Qureshi. Physics-informed value learner for offline goal-conditioned reinforcement learning. InAdvances in Neural Information Processing Systems, volume 38, pages 137769–137796, 2025
2025
-
[23]
Hierarchical reinforcement learning with timed subgoals
Nico Gürtler, Dieter Büchler, and Georg Martius. Hierarchical reinforcement learning with timed subgoals. InAdvances in Neural Information Processing Systems, volume 34, pages 21732–21743, 2021
2021
-
[24]
Long-horizon planning with predictable skills
Nico Gürtler and Georg Martius. Long-horizon planning with predictable skills. InReinforce- ment Learning Conference, 2025
2025
-
[25]
Hierarchical world models as visual whole-body humanoid controllers
Nicklas Hansen, Jyothir SV , Vlad Sobal, Yann LeCun, Xiaolong Wang, and Hao Su. Hierarchical world models as visual whole-body humanoid controllers. InInternational Conference on Learning Representations, 2025
2025
-
[26]
Successor feature landmarks for long-horizon goal-conditioned reinforcement learning
Christopher Hoang, Sungryull Sohn, Jongwook Choi, Wilka Carvalho, and Honglak Lee. Successor feature landmarks for long-horizon goal-conditioned reinforcement learning. In Advances in Neural Information Processing Systems, volume 34, pages 26963–26975, 2021
2021
-
[27]
Goal-reaching policy learning from non-expert observations via effective subgoal guidance
RenMing Huang, Shaochong Liu, Yunqiang Pei, Peng Wang, Guoqing Wang, Yang Yang, and Hengtao Shen. Goal-reaching policy learning from non-expert observations via effective subgoal guidance. InProceedings of the 8th Conference on Robot Learning, volume 270, pages 1744–1762. PMLR, 2024
2024
-
[28]
Mapping state space using landmarks for universal goal reaching
Zhiao Huang, Fangchen Liu, and Hao Su. Mapping state space using landmarks for universal goal reaching. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[29]
Gamma-models: Generative temporal dif- ference learning for infinite-horizon prediction
Michael Janner, Igor Mordatch, and Sergey Levine. Gamma-models: Generative temporal dif- ference learning for infinite-horizon prediction. InAdvances in Neural Information Processing Systems, volume 33, pages 1724–1735, 2020
2020
-
[30]
Zero-shot reinforcement learning from low quality data
Scott Jeen, Tom Bewley, and Jonathan Cullen. Zero-shot reinforcement learning from low quality data. InAdvances in Neural Information Processing Systems, volume 37, pages 16894– 16942, 2024. 11
2024
-
[31]
Conservative offline goal-conditioned implicit V-learning
Kaiqiang Ke, Qian Lin, Zongkai Liu, Shenghong He, and Chao Yu. Conservative offline goal-conditioned implicit V-learning. InProceedings of the 42nd International Conference on Machine Learning, volume 267, pages 29591–29607. PMLR, 2025
2025
-
[32]
Discovering temporal structure: An overview of hierarchical reinforcement learning
Martin Klissarov, Akhil Bagaria, Ziyan Luo, George Konidaris, Doina Precup, and Marlos C Machado. Discovering temporal structure: An overview of hierarchical reinforcement learning. arXiv preprint arXiv:2506.14045, 2025
-
[33]
Offline reinforcement learning with implicit Q-learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit Q-learning. InInternational Conference on Learning Representations, 2022
2022
-
[34]
DDCO: Discovery of deep continuous options for robot learning from demonstrations
Sanjay Krishnan, Roy Fox, Ion Stoica, and Ken Goldberg. DDCO: Discovery of deep continuous options for robot learning from demonstrations. InProceedings of the 1st Annual Conference on Robot Learning, pages 418–437. PMLR, 2017
2017
-
[35]
Composing Meta-Policies for Autonomous Driving Using Hierarchical Deep Reinforcement Learning
Richard Liaw, Sanjay Krishnan, Animesh Garg, Daniel Crankshaw, Joseph E Gonzalez, and Ken Goldberg. Composing meta-policies for autonomous driving using hierarchical deep reinforcement learning.arXiv preprint arXiv:1711.01503, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Tao Ma, Xuzhi Yang, and Zoltan Szabo. To switch or not to switch? Balanced policy switching in offline reinforcement learning.arXiv preprint arXiv:2407.01837, 2024
-
[37]
Learning temporal distances: Contrastive successor features can provide a metric structure for decision- making
Vivek Myers, Chongyi Zheng, Anca Dragan, Sergey Levine, and Benjamin Eysenbach. Learning temporal distances: Contrastive successor features can provide a metric structure for decision- making. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 37076–37096. PMLR, 2024
2024
-
[38]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[39]
Evaluation-time policy switching for offline reinforcement learning
Natinael Solomon Neggatu, Jeremie Houssineau, and Giovanni Montana. Evaluation-time policy switching for offline reinforcement learning. InProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, pages 1520–1528, 2025
2025
-
[40]
OGBench: Benchmark- ing offline goal-conditioned RL
Seohong Park, Kevin Frans, Benjamin Eysenbach, and Sergey Levine. OGBench: Benchmark- ing offline goal-conditioned RL. InInternational Conference on Learning Representations, 2025
2025
-
[41]
HIQL: Offline goal- conditioned RL with latent states as actions
Seohong Park, Dibya Ghosh, Benjamin Eysenbach, and Sergey Levine. HIQL: Offline goal- conditioned RL with latent states as actions. InAdvances in Neural Information Processing Systems, volume 36, pages 34866–34891, 2023
2023
-
[42]
Foundation policies with Hilbert represen- tations
Seohong Park, Tobias Kreiman, and Sergey Levine. Foundation policies with Hilbert represen- tations. InProceedings of the 41st International Conference on Machine Learning, volume 235, pages 39737–39761. PMLR, 2024
2024
-
[43]
Temporal distance-aware subgoal generation for offline hierarchical reinforcement learning
Taegeon Park, Seungho Baek, Jongchan Park, Seungjun Oh, and Yusung Kim. Temporal distance-aware subgoal generation for offline hierarchical reinforcement learning. InProceed- ings of the 34th ACM International Conference on Information and Knowledge Management, pages 2305–2314, 2025
2025
-
[44]
DeepLoco: Dy- namic locomotion skills using hierarchical deep reinforcement learning.ACM Transactions on Graphics, 36(4):1–13, 2017
Xue Bin Peng, Glen Berseth, KangKang Yin, and Michiel Van De Panne. DeepLoco: Dy- namic locomotion skills using hierarchical deep reinforcement learning.ACM Transactions on Graphics, 36(4):1–13, 2017
2017
-
[45]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Xue Bin Peng, Aviral Kumar, Grace Zhang, and Sergey Levine. Advantage-weighted regression: Simple and scalable off-policy reinforcement learning.arXiv preprint arXiv:1910.00177, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[46]
Fast imitation via behavior foundation models
Matteo Pirotta, Andrea Tirinzoni, Ahmed Touati, Alessandro Lazaric, and Yann Ollivier. Fast imitation via behavior foundation models. InNeurIPS 2023 Foundation Models for Decision Making Workshop, 2023. 12
2023
-
[47]
Successor Options: An Option Discovery Framework for Reinforcement Learning
Rahul Ramesh, Manan Tomar, and Balaraman Ravindran. Successor options: An option discovery framework for reinforcement learning.arXiv preprint arXiv:1905.05731, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[48]
Alfredo Reichlin, Miguel Vasco, Hang Yin, and Danica Kragic. Learning goal-conditioned policies from sub-optimal offline data via metric learning.arXiv preprint arXiv:2402.10820, 2024
-
[49]
La- tent plans for task-agnostic offline reinforcement learning
Erick Rosete-Beas, Oier Mees, Gabriel Kalweit, Joschka Boedecker, and Wolfram Burgard. La- tent plans for task-agnostic offline reinforcement learning. InProceedings of the 6th Conference on Robot Learning, volume 205, pages 1838–1849. PMLR, 2022
2022
-
[50]
Universal value function approxi- mators
Tom Schaul, Daniel Horgan, Karol Gregor, and David Silver. Universal value function approxi- mators. InProceedings of the 32nd International Conference on Machine Learning, volume 37, pages 1312–1320. PMLR, 2015
2015
-
[51]
Skill-based model-based reinforcement learning
Lucy Xiaoyang Shi, Joseph J Lim, and Youngwoon Lee. Skill-based model-based reinforcement learning. InProceedings of the 6th Conference on Robot Learning, volume 205, pages 2262–
-
[52]
Fast adaptation with behavioral foundation models
Harshit Sikchi, Andrea Tirinzoni, Ahmed Touati, Yingchen Xu, Anssi Kanervisto, Scott Niekum, Amy Zhang, Alessandro Lazaric, and Matteo Pirotta. Fast adaptation with behavioral foundation models. InReinforcement Learning Conference, 2025
2025
-
[53]
Learning from reward-free offline data: A case for planning with latent dynamics models
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim GJ Rudner, and Yann LeCun. Learning from reward-free offline data: A case for planning with latent dynamics models. InAdvances in Neural Information Processing Systems, volume 38, pages 43905–43941, 2025
2025
-
[54]
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1- 2):181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence, 112(1- 2):181–211, 1999
1999
-
[55]
Generalised policy improvement with geometric policy composition
Shantanu Thakoor, Mark Rowland, Diana Borsa, Will Dabney, Rémi Munos, and André Barreto. Generalised policy improvement with geometric policy composition. InProceedings of the 39th International Conference on Machine Learning, volume 162, pages 21272–21307. PMLR, 2022
2022
-
[56]
Zero-shot whole-body humanoid control via behavioral foundation models
Andrea Tirinzoni, Ahmed Touati, Jesse Farebrother, Mateusz Guzek, Anssi Kanervisto, Yingchen Xu, Alessandro Lazaric, and Matteo Pirotta. Zero-shot whole-body humanoid control via behavioral foundation models. InInternational Conference on Learning Representations, 2025
2025
-
[57]
Learning one representation to optimize all rewards
Ahmed Touati and Yann Ollivier. Learning one representation to optimize all rewards. In Advances in Neural Information Processing Systems, volume 34, pages 13–23, 2021
2021
-
[58]
Does zero-shot reinforcement learning exist? InInternational Conference on Learning Representations, 2023
Ahmed Touati, Jérémy Rapin, and Yann Ollivier. Does zero-shot reinforcement learning exist? InInternational Conference on Learning Representations, 2023
2023
-
[59]
1000 layer networks for self-supervised RL: Scaling depth can enable new goal-reaching capabilities
Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzci´nski, and Benjamin Eysenbach. 1000 layer networks for self-supervised RL: Scaling depth can enable new goal-reaching capabilities. InAdvances in Neural Information Processing Systems, volume 38, pages 157643– 157670, 2025
2025
-
[60]
Planning, fast and slow: Online reinforcement learning with action-free offline data via multiscale planners
Chengjie Wu, Hao Hu, Yiqin Yang, Ning Zhang, and Chongjie Zhang. Planning, fast and slow: Online reinforcement learning with action-free offline data via multiscale planners. In Proceedings of the 41st International Conference on Machine Learning, volume 235, pages 53515–53541. PMLR, 2024
2024
-
[61]
QMP: Q-switch mixture of policies for multi-task behavior sharing
Grace Zhang, Ayush Jain, Injune Hwang, Shao-Hua Sun, and Joseph J Lim. QMP: Q-switch mixture of policies for multi-task behavior sharing. InInternational Conference on Learning Representations, 2025
2025
-
[62]
Can we really learn one representation to optimize all rewards?arXiv preprint arXiv:2602.11399, 2026
Chongyi Zheng, Royina Karegoudra Jayanth, and Benjamin Eysenbach. Can we really learn one representation to optimize all rewards?arXiv preprint arXiv:2602.11399, 2026. 13
-
[63]
Towards robust zero-shot reinforcement learning
Kexin Zheng, Lauriane Teyssier, Yinan Zheng, Yu Luo, and Xianyuan Zhan. Towards robust zero-shot reinforcement learning. InAdvances in Neural Information Processing Systems, volume 38, pages 131049–131084, 2025. 14 A Additional discussions A.1 Further related work In this section, we highlight additional works related to our approach. For a more comprehen...
2025
-
[64]
defines the objective L(F, B) := F ⊤Bρ− Id +γP πF ⊤Bρ 2 ρ, which expands to the FB loss used in our work (Equation (1)): E(st,at,st+1)∼D s′∼ρ,z∼Z 1{st =s ′} ρ(s′) +γ F(s t+1, πz(st+1), z)⊤B(s′)−F(s t, at, z)⊤B(s′) 2 Finally, under a quadratic objective, this loss function simplifies (up to a constant) to: E(st,at,st+1)∼D s′∼ρ,z∼Z h γF(s t+1, πz(st+1), z)⊤...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.