Recognition: unknown
Intelligence Delivery Network: Toward an Internet Architecture for the AI Age
Pith reviewed 2026-05-14 18:28 UTC · model grok-4.3
The pith
The Intelligence Delivery Network treats AI capabilities as deliverable network services positioned across cloud, edge, and local environments based on demand and resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an Internet architecture called the Intelligence Delivery Network can treat AI capabilities as deliverable services, positioning, selecting, reusing, and verifying them across cloud, regional, edge, and local environments according to demand locality, resource availability, and policy constraints, through the combined operation of capability abstraction, compute resource integration, demand-driven deployment, service routing, state-aware caching, and trust management.
What carries the argument
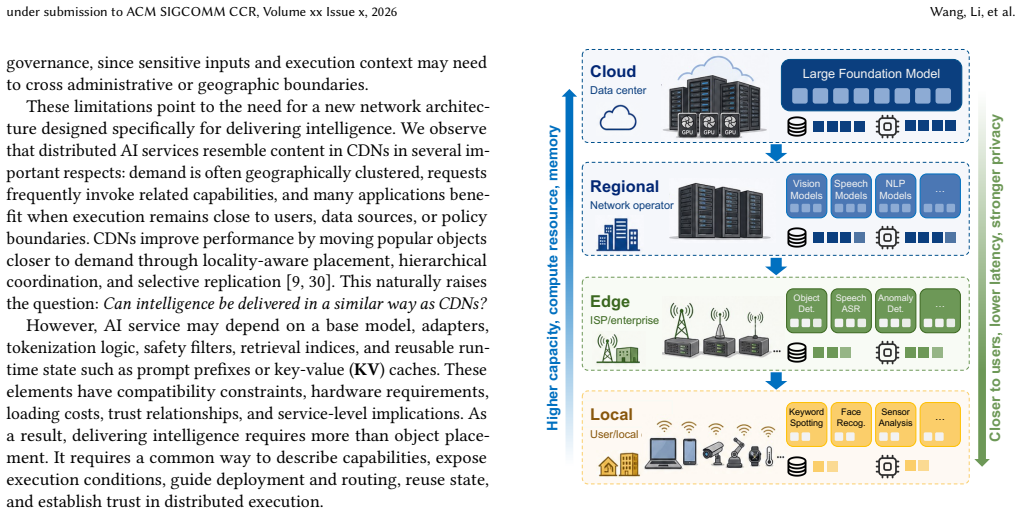
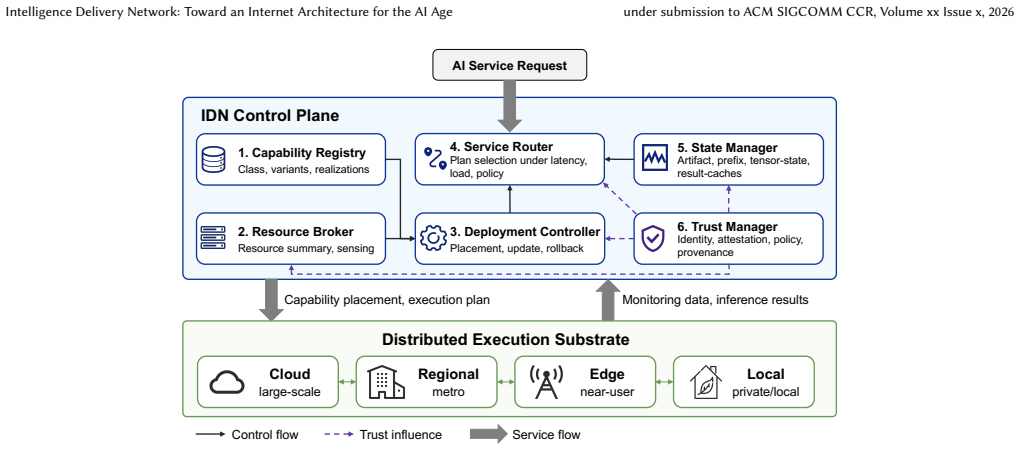
The Intelligence Delivery Network (IDN) architecture, which abstracts AI capabilities for dynamic positioning, routing, and verification across distributed compute environments.
Load-bearing premise
Capability abstraction, resource integration, demand-driven deployment, routing, caching, and trust management can operate together to support distributed AI services without creating prohibitive overhead or new security vulnerabilities.
What would settle it
A controlled deployment of IDN mechanisms on a multi-site testbed with representative AI workloads, measuring whether end-to-end latency and bandwidth drop while resource utilization rises and security events remain comparable to cloud-only baselines.
Figures




read the original abstract
The rapid emergence of AI-powered applications is reshaping the role of the Internet. Users increasingly rely on the network to obtain intelligence services derived from large foundation models, rather than merely to reach remote endpoints or retrieve specific content. Today's dominant deployment paradigm for AI services remains cloud-centric, where user requests are transmitted to remote data centers for centralized inference. Although operationally convenient, this paradigm suffers from latency and jitter, heavy wide-area traffic, limited utilization of distributed heterogeneous compute resources, and growing privacy and governance concerns. In this paper, we propose the Intelligence Delivery Network (IDN), an Internet architecture that treats AI capabilities as deliverable network services. The key idea is to position, select, reuse, and verify intelligence across cloud, regional, edge, and local environments according to demand locality, resource availability, and policy constraints. We present the system assumptions of IDN, define its core architectural mechanisms, and discuss how capability abstraction, compute resource integration, demand-driven deployment, service routing, state-aware caching, and trust management can jointly support distributed AI services. We believe that IDN provides a practical path toward an Internet architecture for the AI age, making AI capabilities more accessible, efficient, trustworthy, and responsive to diverse application needs.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: purely descriptive architecture proposal with no derivations or fitted results
full rationale
The manuscript is a high-level architectural proposal for the Intelligence Delivery Network (IDN). It defines concepts such as capability abstraction, compute resource integration, demand-driven deployment, service routing, state-aware caching, and trust management at the level of system assumptions and mechanisms, without any equations, quantitative models, fitted parameters, or derivation chains. No step reduces a claimed prediction or result to its own inputs by construction, self-citation, or renaming. The central claim is an existence argument for a new architecture rather than a derived quantity, so the proposal is self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI capabilities can be abstracted as network-deliverable services
- domain assumption Distributed heterogeneous compute resources can be integrated and selected based on locality and policy
invented entities (1)
-
Intelligence Delivery Network (IDN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ramjee. 2024. Tam- ing Throughput-Latency tradeoff in LLM inference with Sarathi-Serve. In18th USENIX symposium on operating systems design and implementation (OSDI 24). USENIX Association, Santa Clara, United States, 117–134
2024
-
[2]
AMD. 2020. AMD SEV-SNP: Strengthening VM Isolation with Integrity Protec- tion and More. https://docs.amd.com/v/u/en-US/SEV-SNP-strengthening-vm- isolation-with-integrity-protection-and-more Accessed May 6, 2026
2020
-
[3]
Sergei Arnautov, Bohdan Trach, Franz Gregor, Thomas Knauth, Andre Martin, Christian Priebe, Joshua Lind, Divya Muthukumaran, Dan O’keeffe, Mark L Stillwell, et al. 2016. SCONE: Secure linux containers with intel SGX. In12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16). USENIX Association, Savannah, United States, 689–703
2016
-
[4]
Vinton Cerf and Robert Kahn. 1974. A protocol for packet network intercommu- nication.IEEE Transactions on communications22, 5 (1974), 637–648
1974
-
[5]
David Clark. 1988. The design philosophy of the DARPA Internet protocols. In Symposium proceedings on Communications architectures and protocols. Associa- tion for Computing Machinery, Stanford, United States, 106–114
1988
-
[6]
Victor Costan, Ilia Lebedev, and Srinivas Devadas. 2016. Sanctum: Minimal hard- ware extensions for strong software isolation. In25th USENIX Security Symposium (USENIX Security 16). USENIX Association, Austin, United States, 857–874
2016
-
[7]
Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J Franklin, Joseph E Gonzalez, and Ion Stoica. 2017. Clipper: A Low-Latency online prediction serving system. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). USENIX Association, Boston, United States, 613–627
2017
-
[8]
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. LLM.int8(): 8-bit matrix multiplication for transformers at scale. InAdvances in neural information processing systems. Curran Associates, New Orleans, United States, 30318–30332
2022
-
[9]
John Dilley, Bruce M Maggs, Jay Parikh, Harald Prokop, Ramesh Sitaraman, and Bill Weihl. 2002. Globally distributed content delivery.IEEE Internet Computing 6, 5 (2002), 50–58
2002
-
[10]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research23, 120 (2022), 1–39
2022
-
[11]
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. 2024. ServerlessLLM: Low-Latency serverless inference for large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, United States, 135–153
2024
-
[12]
In Gim, Guojun Chen, Seung-seob Lee, Nikhil Sarda, Anurag Khandelwal, and Lin Zhong. 2024. Prompt cache: Modular attention reuse for low-latency inference. In Proceedings of Machine Learning and Systems. PMLR, Santa Clara, United States, 325–338
2024
-
[13]
Tianyu Gu, Brendan Dolan-Gavitt, and Siddharth Garg. 2017. Badnets: Identifying vulnerabilities in the machine learning model supply chain.ArXivabs/1708.06733 (2017), 1–13
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Arpan Gujarati, Reza Karimi, Safya Alzayat, Wei Hao, Antoine Kaufmann, Ymir Vigfusson, and Jonathan Mace. 2020. Serving DNNs like clockwork: Performance predictability from the bottom up. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, Virtual Event, 443–462
2020
-
[15]
Jashwant Raj Gunasekaran, Cyan Subhra Mishra, Prashanth Thinakaran, Bikash Sharma, Mahmut Taylan Kandemir, and Chita R Das. 2022. Cocktail: A multidi- mensional optimization for model serving in cloud. In19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22). USENIX Association, Renton, United States, 1041–1057
2022
-
[16]
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. 2015. Distilling the knowledge in a neural network.ArXivabs/1503.02531 (2015), 1–9
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. 2022. Lora: Low-rank adaptation of large language models.ArXivabs/2106.09685 (2022), 1–26
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Van Jacobson, Diana K Smetters, James D Thornton, Michael F Plass, Nicholas H Briggs, and Rebecca L Braynard. 2009. Networking named content. InProceed- ings of the 5th international conference on Emerging networking experiments and technologies. Association for Computing Machinery, Rome, Italy, 1–12
2009
-
[19]
Kubernetes Authors. 2026. Kubernetes: Production-Grade Container Orchestra- tion. https://kubernetes.io/ Accessed May 6, 2026
2026
-
[20]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles. Association for Computing Machinery, Koblenz, Germany, 611–626
2023
-
[21]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient generative inference of large language models with dynamic KV cache management. In18th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI 24). USENIX Association, Santa Clara, United States, 155–172
2024
-
[22]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in neural information processing systems. Curran Associates, Inc., Vancouver, Canada, 9459–9474
2020
-
[23]
Cheng Li, Zongpeng Du, Mohamed Boucadair, Luis M Contreras, and J Drake
-
[24]
https: //datatracker.ietf.org/doc/draft-ietf-cats-framework/ Accessed May 6, 2026
A framework for computing-aware traffic steering (CATS). https: //datatracker.ietf.org/doc/draft-ietf-cats-framework/ Accessed May 6, 2026
2026
-
[25]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E Gonzalez, et al. 2023. Al- paServe: Statistical multiplexing with model parallelism for deep learning serving. In17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, Boston, United State...
2023
-
[26]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. 2024. Cachegen: Kv cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference. Association for Computing Machinery, Sydney, Australia, 38–56. 8 Intelligen...
2024
-
[27]
Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. 2018. Trojaning attack on neural networks. In25th Annual Network And Distributed System Security Symposium (NDSS 2018). Internet Society, San Diego, United States, 1–15
2018
-
[28]
Yuyi Mao, Changsheng You, Jun Zhang, Kaibin Huang, and Khaled B Letaief
-
[29]
A survey on mobile edge computing: The communication perspective.IEEE communications surveys & tutorials19, 4 (2017), 2322–2358
2017
-
[30]
Pratyush Mishra, Ryan Lehmkuhl, Akshayaram Srinivasan, Wenting Zheng, and Raluca Ada Popa. 2020. Delphi: A cryptographic inference system for neural networks. InProceedings of the 2020 workshop on privacy-preserving machine learning in practice. Association for Computing Machinery, Virtual Event, 27–30
2020
-
[31]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I Jordan, et al. 2018. Ray: A distributed framework for emerging AI applications. In13th USENIX symposium on operating systems design and implementation (OSDI 18). USENIX Association, Carlsbad, United States, 561–577
2018
-
[32]
Erik Nygren, Ramesh K Sitaraman, and Jennifer Sun. 2010. The akamai network: a platform for high-performance internet applications.ACM SIGOPS Operating Systems Review44, 3 (2010), 2–19
2010
-
[33]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). IEEE, Buenos Aires, Argentina, 118–132
2024
-
[34]
Francisco Romero, Qian Li, Neeraja J Yadwadkar, and Christos Kozyrakis. 2021. INFaaS: Automated model-less inference serving. In2021 USENIX Annual Techni- cal Conference (USENIX ATC 21). USENIX Association, Virtual Event, 397–411
2021
-
[35]
Jerome H Saltzer, David P Reed, and David D Clark. 1984. End-to-end arguments in system design.ACM Transactions on Computer Systems (TOCS)2, 4 (1984), 277–288
1984
-
[36]
Mahadev Satyanarayanan. 2017. The emergence of edge computing.computer 50, 1 (2017), 30–39
2017
-
[37]
Ying Sheng, Shiyi Cao, Dacheng Li, Banghua Zhu, Zhuohan Li, Danyang Zhuo, Joseph E Gonzalez, and Ion Stoica. 2024. Fairness in serving large language models. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, United States, 965–988
2024
-
[38]
Weisong Shi, Jie Cao, Quan Zhang, Youhuizi Li, and Lanyu Xu. 2016. Edge computing: Vision and challenges.IEEE internet of things journal3, 5 (2016), 637–646
2016
-
[39]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24). USENIX Association, Santa Clara, United States, 173–191
2024
-
[40]
Florian Tramer and Dan Boneh. 2018. Slalom: Fast, verifiable and private ex- ecution of neural networks in trusted hardware.ArXivabs/1806.03287 (2018), 1–19
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[41]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. Smoothquant: Accurate and efficient post-training quantization for large language models. InInternational conference on machine learning. PMLR, Honolulu, United States, 38087–38099
2023
-
[42]
George Xylomenos, Christopher N Ververidis, Vasilios A Siris, Nikos Fotiou, Christos Tsilopoulos, Xenofon Vasilakos, Konstantinos V Katsaros, and George C Polyzos. 2013. A survey of information-centric networking research.IEEE communications surveys & tutorials16, 2 (2013), 1024–1049
2013
-
[43]
Kehan Yao, Dirk Trossen, Mohamed Boucadair, Luis M Contreras, Hang Shi, Yizhou Li, Shuai Zhang, and Qing An. 2024. Computing-aware traffic steering (CATS) problem statement, use cases, and requirements. https://datatracker.ietf. org/doc/draft-ietf-cats-usecases-requirements/ Accessed May 6, 2026
2024
-
[44]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung- Gon Chun. 2022. Orca: A distributed serving system for Transformer-Based generative models. In16th USENIX symposium on operating systems design and implementation (OSDI 22). USENIX Association, Carlsbad, United States, 521–538
2022
-
[45]
Lixia Zhang, Alexander Afanasyev, Jeffrey Burke, Van Jacobson, KC Claffy, Patrick Crowley, Christos Papadopoulos, Lan Wang, and Beichuan Zhang. 2014. Named data networking.ACM SIGCOMM Computer Communication Review44, 3 (2014), 66–73
2014
-
[46]
Wenting Zheng, Ankur Dave, Jethro G Beekman, Raluca Ada Popa, Joseph E Gonzalez, and Ion Stoica. 2017. Opaque: An oblivious and encrypted distributed analytics platform. In14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). USENIX Association, Boston, United States, 283–298
2017
-
[47]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating prefill and decoding for goodput-optimized large language model serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). USENIX Association, Santa Clara, United States, 193–210
2024
-
[48]
Zhi Zhou, Xu Chen, En Li, Liekang Zeng, Ke Luo, and Junshan Zhang. 2019. Edge intelligence: Paving the last mile of artificial intelligence with edge computing. Proc. IEEE107, 8 (2019), 1738–1762. 9
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.