Recognition: 2 theorem links
· Lean TheoremLearning Perturbations to Extrapolate Your LLM
Pith reviewed 2026-05-14 17:40 UTC · model grok-4.3
The pith
Perturbing token prefixes via a learnable continuous latent vector transformation improves LLM extrapolation to unseen domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a framework where token prefixes are perturbed by a learnable transformation of a continuous latent vector within an embedding space. To overcome the challenge of an intractable marginal likelihood, we derive unbiased estimating equations for model parameters and optimize them via stochastic gradient descent. We establish the statistical properties of the resulting estimator in over-parameterized regimes. Empirical evaluations on both synthetic and real-world datasets demonstrate that our proposal yields significant gains in out-of-domain settings over a range of state-of-the-art baseline methods.
What carries the argument
Learnable transformation of a continuous latent vector that perturbs token prefixes in embedding space, optimized through unbiased estimating equations via SGD.
If this is right
- Significant gains in out-of-domain performance over state-of-the-art baselines on both synthetic and real-world datasets.
- Optimization remains feasible via stochastic gradient descent despite the intractable marginal likelihood.
- Statistical properties of the estimator hold in over-parameterized regimes.
- Perturbations become more flexible than fixed discrete designs by operating on a continuous latent vector.
Where Pith is reading between the lines
- The same continuous perturbation mechanism could be tested on non-language sequence models facing distribution shifts, such as time-series predictors.
- Models trained this way might require less frequent full retraining when encountering gradual domain changes in deployment.
- The latent-vector dimension could be tuned as a practical hyperparameter to balance extrapolation strength against computational cost.
Load-bearing premise
The intractable marginal likelihood can be effectively handled by unbiased estimating equations that support SGD optimization and produce better extrapolation in over-parameterized regimes.
What would settle it
A replication study that finds no significant out-of-domain performance gains on the real-world datasets or shows that the estimator fails to converge under the stated over-parameterized conditions would falsify the central claim.
Figures

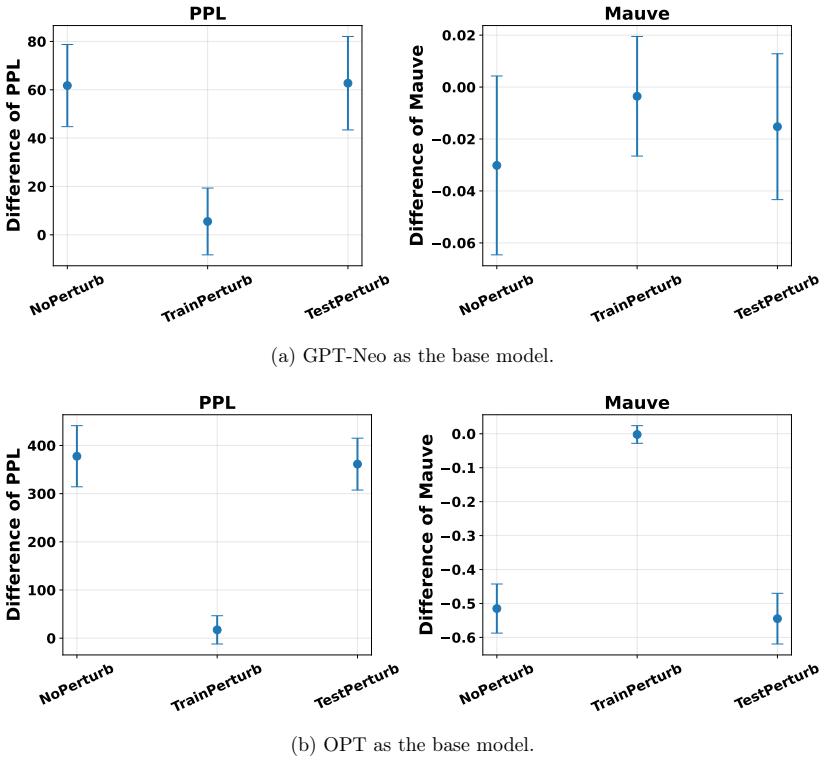
read the original abstract
Recent advancements in large language models demonstrate that injecting perturbations can substantially enhance extrapolation performance. However, current approaches often rely on discrete perturbations with fixed designs, which limits their flexibility. In this work, we propose a framework where token prefixes are perturbed by a learnable transformation of a continuous latent vector within an embedding space. To overcome the challenge of an intractable marginal likelihood, we derive unbiased estimating equations for model parameters and optimize them via stochastic gradient descent. We establish the statistical properties of the resulting estimator in over-parameterized regimes. Empirical evaluations on both synthetic and real-world datasets demonstrate that our proposal yields significant gains in out-of-domain settings over a range of state-of-the-art baseline methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for improving LLM extrapolation by perturbing token prefixes via a learnable continuous transformation of a latent vector in embedding space. It derives unbiased estimating equations to optimize the intractable marginal likelihood via SGD, establishes statistical properties of the resulting estimator in over-parameterized regimes, and reports empirical gains over baselines on synthetic and real-world out-of-domain tasks.
Significance. If the unbiasedness of the estimating equations and the over-parameterized analysis hold with independent verification, the work would provide a principled, flexible alternative to fixed discrete perturbations, with potential impact on robust generalization in language models. The empirical claims of significant gains would strengthen the case for learnable perturbations if supported by detailed ablations and reproducible setups.
major comments (2)
- [Method (derivation of estimating equations)] The derivation of the unbiased estimating equations (referenced in the abstract and method) requires an explicit proof that their expectation equals the true score of the marginal likelihood. Without this, it is unclear whether the equations are independent of the fitted quantities or reduce by construction, which is load-bearing for the SGD optimization and the claimed statistical properties.
- [§4] §4 (over-parameterized analysis): the statistical properties of the estimator are asserted but the specific assumptions on the latent vector distribution and the regime where they apply are not sufficiently detailed to confirm they support improved extrapolation without hidden bias.
minor comments (2)
- [Abstract] The abstract and introduction should include a brief equation or pseudocode for the learnable transformation to clarify its form before discussing the marginal likelihood.
- [Experiments] Empirical section: add explicit dataset sizes, exact baseline implementations, and variance across runs to strengthen the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications and proofs.
read point-by-point responses
-
Referee: [Method (derivation of estimating equations)] The derivation of the unbiased estimating equations (referenced in the abstract and method) requires an explicit proof that their expectation equals the true score of the marginal likelihood. Without this, it is unclear whether the equations are independent of the fitted quantities or reduce by construction, which is load-bearing for the SGD optimization and the claimed statistical properties.
Authors: We agree that an explicit proof is needed for rigor. In the revised manuscript, we will add a dedicated subsection in the Methods deriving the estimating equations and proving that their expectation equals the score of the marginal likelihood under the model assumptions. This will confirm unbiasedness and that the equations do not reduce trivially by construction, directly supporting the SGD procedure and the statistical properties claimed later. revision: yes
-
Referee: [§4] §4 (over-parameterized analysis): the statistical properties of the estimator are asserted but the specific assumptions on the latent vector distribution and the regime where they apply are not sufficiently detailed to confirm they support improved extrapolation without hidden bias.
Authors: We acknowledge the need for greater detail on the assumptions. In the revision of §4, we will explicitly state that the latent vector is drawn from a standard Gaussian distribution N(0, I) and specify the over-parameterized regime as one where the embedding dimension d satisfies d = ω(n) with n the effective sample size. We will also add a short argument showing that these conditions ensure the estimator remains consistent for extrapolation without introducing hidden bias from the perturbation mechanism. revision: yes
Circularity Check
No significant circularity; derivation of unbiased estimating equations is self-contained
full rationale
The paper derives unbiased estimating equations from the proposed perturbation model to address the intractable marginal likelihood, then optimizes via SGD and establishes statistical properties in over-parameterized regimes. These steps are presented as following from the model definition and standard statistical techniques for handling intractability, with empirical evaluations on synthetic and real-world datasets serving as independent validation rather than part of the derivation. No self-definitional structures, fitted inputs renamed as predictions, load-bearing self-citations, or reductions of central claims to inputs by construction appear in the abstract or described chain. The approach remains externally falsifiable through the reported out-of-domain gains over baselines.
Axiom & Free-Parameter Ledger
free parameters (1)
- parameters of the learnable transformation
axioms (1)
- domain assumption Marginal likelihood is intractable
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
derive unbiased estimating equations for model parameters and optimize them via stochastic gradient descent... ψ(γ;•) ... Ψ(γ) = 0
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
over-parameterized regimes... Γ∗ non-empty set of stationary points... d(bγ,Γ∗) → 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Doubly robust alignment for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
(2026), ‘Statistical early stopping for reasoning models’,arXiv preprint arXiv:2602.13935
Statistical Early Stopping for Reasoning Models , author=. arXiv preprint arXiv:2602.13935 , year=
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2602.08259 , year=
A statistical framework for alignment with biased ai feedback , author=. arXiv preprint arXiv:2602.08259 , year=
-
[5]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[6]
arXiv preprint arXiv:2410.02504 , year=
Dual active learning for reinforcement learning from human feedback , author=. arXiv preprint arXiv:2410.02504 , year=
-
[7]
Wang, Mengdi and Fang, Ethan X. and Liu, Han , title =. Math. Program. , month = jan, pages =. 2017 , issue_date =. doi:10.1007/s10107-016-1017-3 , abstract =
-
[8]
On perturbed proximal gradient algorithms , year =
Atchad\'. On perturbed proximal gradient algorithms , year =. J. Mach. Learn. Res. , month = jan, pages =
-
[9]
Handbook of econometrics , volume=
Large sample estimation and hypothesis testing , author=. Handbook of econometrics , volume=. 1994 , publisher=
1994
-
[10]
Vaart, A. W. van der , year=. Asymptotic Statistics , publisher=
-
[11]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =
Shen, Xinwei and Meinshausen, Nicolai , title =. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume =. 2025 , month =. doi:10.1093/jrsssb/qkae108 , eprint =
-
[12]
arXiv preprint arXiv:2603.01162v3 , year=
Demystifying Group Relative Policy Optimization: Its Policy Gradient is a U-Statistic , author=. arXiv preprint arXiv:2603.01162v3 , year=
-
[13]
2023 , publisher=
Weak Convergence and Empirical Processes , author=. 2023 , publisher=
2023
-
[14]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MixCE: Training autoregressive language models by mixing forward and reverse cross-entropies , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
2018 , institution=
Improving language understanding by generative pre-training , author=. 2018 , institution=
2018
-
[16]
2019 , institution=
Language models are unsupervised multitask learners , author=. 2019 , institution=
2019
-
[17]
2022 , journal=
OPT: Open Pre-trained Transformer Language Models , author=. 2022 , journal=
2022
-
[18]
The Eleventh International Conference on Learning Representations , year=
Tailoring Language Generation Models under Total Variation Distance , author=. The Eleventh International Conference on Learning Representations , year=
-
[19]
Zhu , booktitle=
Siyu Ren and Zhiyong Wu and Kenny Q. Zhu , booktitle=
-
[20]
and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard
Feng, Steven Y. and Gangal, Varun and Kang, Dongyeop and Mitamura, Teruko and Hovy, Eduard. G en A ug: Data Augmentation for Finetuning Text Generators. Proceedings of Deep Learning Inside Out (DeeLIO): The First Workshop on Knowledge Extraction and Integration for Deep Learning Architectures. 2020. doi:10.18653/v1/2020.deelio-1.4
-
[21]
Feng, Steven Y. and Li, Aaron W. and Hoey, Jesse. Keep Calm and Switch On! Preserving Sentiment and Fluency in Semantic Text Exchange. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1272
-
[22]
EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
Wei, Jason and Zou, Kai. EDA : Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1670
-
[23]
5th International Conference on Learning Representations , year=
Pointer sentinel mixture models , author=. 5th International Conference on Learning Representations , year=
-
[24]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hierarchical neural story generation , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[25]
Proceedings of the 6th ACM SIGPLAN international symposium on machine programming , pages=
A systematic evaluation of large language models of code , author=. Proceedings of the 6th ACM SIGPLAN international symposium on machine programming , pages=
-
[26]
Proceedings of the 3rd workshop on machine reading for question answering , pages=
GermanQuAD and GermanDPR: Improving non-English question answering and passage retrieval , author=. Proceedings of the 3rd workshop on machine reading for question answering , pages=
-
[27]
3rd International Conference on Learning Representations , year=
Adam: A method for stochastic optimization , author=. 3rd International Conference on Learning Representations , year=
-
[28]
Zenodo , year=
Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow , author=. Zenodo , year=
-
[29]
Perturbation is All You Need for Extrapolating Language Models
Perturbation is All You Need for Extrapolating Language Models , author=. arXiv preprint arXiv:2605.04344v1 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Probabilistic Linguistic Knowledge and Token-Level Text Augmentation
Wang, Zhengxiang. Probabilistic Linguistic Knowledge and Token-Level Text Augmentation. Practical Solutions for Diverse Real-World NLP Applications. 2024. doi:10.1007/978-3-031-44260-5_1
-
[31]
ICLR 2024 Workshop on Data-centric Machine Learning Research (DMLR): Harnessing Momentum for Science , year=
Empowering Large Language Models for Textual Data Augmentation , author=. ICLR 2024 Workshop on Data-centric Machine Learning Research (DMLR): Harnessing Momentum for Science , year=
2024
-
[32]
Liang, Kung-Yee and Zeger, Scott L. , title =. Biometrika , volume =. 1986 , month =. doi:10.1093/biomet/73.1.13 , url =
-
[33]
Shanshan Song and Yuanyuan Lin and Yong Zhou , title =. Journal of the American Statistical Association , volume =. 2024 , publisher =. doi:10.1080/01621459.2023.2169699 , URL =
-
[34]
arXiv preprint arXiv:2410.04398v1 , year=
Transfer Learning with General Estimating Equations , author=. arXiv preprint arXiv:2410.04398v1 , year=
-
[35]
Estimation of Non-Normalized Statistical Models by Score Matching , journal =
Aapo Hyv. Estimation of Non-Normalized Statistical Models by Score Matching , journal =. 2005 , volume =
2005
-
[36]
Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =
Noise-contrastive estimation: A new estimation principle for unnormalized statistical models , author =. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages =. 2010 , editor =
2010
-
[37]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Noise Contrastive Alignment of Language Models with Explicit Rewards , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[38]
Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =
Yang Song and Jascha Sohl. Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =. 2021 , url =
2021
-
[39]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Lou, Aaron and Meng, Chenlin and Ermon, Stefano , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[40]
International Conference on Learning Representations , volume=
Neftune: Noisy embeddings improve instruction finetuning , author=. International Conference on Learning Representations , volume=
-
[41]
2025 , institution=
Qwen3 Technical Report , author=. 2025 , institution=
2025
-
[42]
Journal of Machine Learning Research , volume=
Mauve scores for generative models: Theory and practice , author=. Journal of Machine Learning Research , volume=
-
[43]
Text summarization branches out , pages=
Rouge: A package for automatic evaluation of summaries , author=. Text summarization branches out , pages=
-
[44]
The journal of the Acoustical Society of America , volume=
Perplexity—a measure of the difficulty of speech recognition tasks , author=. The journal of the Acoustical Society of America , volume=. 1977 , publisher=
1977
-
[45]
International Conference on Learning Representations , year=
Decoupled weight decay regularization , author=. International Conference on Learning Representations , year=
-
[46]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
2025 , journal=
Qwen3 Technical Report , author=. 2025 , journal=
2025
-
[48]
On the Algorithmic Bias of Aligning Large Language Models with
Xiao, Jiancong and Li, Ziniu and Xie, Xingyu and Getzen, Emily and Fang, Cong and Long, Qi and Su, Weijie , journal =. On the Algorithmic Bias of Aligning Large Language Models with. 2025 , publisher =
2025
-
[49]
Kernelized Advantage Estimation: From Nonparametric Statistics to LLM Reasoning
Kernelized Advantage Estimation: From Nonparametric Statistics to LLM Reasoning , author=. arXiv preprint arXiv:2604.28005 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
The Implicit Curriculum: Learning Dynamics in RL with Verifiable Rewards
On the Learning Dynamics of RLVR at the Edge of Competence , author=. arXiv preprint arXiv:2602.14872 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Journal of the American Statistical Association , volume=
Ranking inferences based on the top choice of multiway comparisons , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
2025
-
[52]
arXiv preprint arXiv:2509.01847 , year=
Uncertainty Quantification for Ranking with Heterogeneous Preferences , author=. arXiv preprint arXiv:2509.01847 , year=
-
[53]
The Annals of Statistics , volume=
A statistical framework of watermarks for large language models: Pivot, detection efficiency and optimal rules , author=. The Annals of Statistics , volume=. 2025 , publisher=
2025
-
[54]
arXiv preprint arXiv:2601.06586 , year=
Detecting LLM-Generated Text with Performance Guarantees , author=. arXiv preprint arXiv:2601.06586 , year=
-
[55]
Journal of the American Statistical Association , volume=
Debiasing watermarks for large language models via maximal coupling , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
2025
-
[56]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Robust detection of watermarks for large language models under human edits , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2026 , publisher=
2026
-
[57]
Proceedings of the 28th International Conference on Computational Linguistics , pages=
Is MAP decoding all you need? the inadequacy of the mode in neural machine translation , author=. Proceedings of the 28th International Conference on Computational Linguistics , pages=
-
[58]
P erturb S core: Connecting Discrete and Continuous Perturbations in NLP
Li, Linyang and Ren, Ke and Shao, Yunfan and Wang, Pengyu and Qiu, Xipeng. P erturb S core: Connecting Discrete and Continuous Perturbations in NLP. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.442
-
[59]
Consistency Training with Virtual Adversarial Discrete Perturbation
Park, Jungsoo and Kim, Gyuwan and Kang, Jaewoo. Consistency Training with Virtual Adversarial Discrete Perturbation. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10.18653/v1/2022.naacl-main.414
-
[60]
arXiv preprint arXiv:2507.15868v1 , year=
Small Edits, Big Consequences: Telling Good from Bad Robustness in Large Language Models , author=. arXiv preprint arXiv:2507.15868v1 , year=
-
[61]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[62]
and Leike, Jan and Brown, Tom B
Christiano, Paul F. and Leike, Jan and Brown, Tom B. and Martic, Miljan and Legg, Shane and Amodei, Dario , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
2017
-
[63]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
and Chadwick, Martin J
Bakker, Michiel A. and Chadwick, Martin J. and Sheahan, Hannah R. and Tessler, Michael Henry and Campbell-Gillingham, Lucy and Balaguer, Jan and McAleese, Nat and Glaese, Amelia and Aslanides, John and Botvinick, Matthew M. and Summerfield, Christopher , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , a...
2022
-
[65]
Adversarial Example Generation with Syntactically Controlled Paraphrase Networks
Iyyer, Mohit and Wieting, John and Gimpel, Kevin and Zettlemoyer, Luke. Adversarial Example Generation with Syntactically Controlled Paraphrase Networks. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10.18653/v1/N18-1170
-
[66]
Semantically Equivalent Adversarial Rules for Debugging NLP models
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. Semantically Equivalent Adversarial Rules for Debugging NLP models. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1079
-
[67]
Ren, Shuhuai and Deng, Yihe and He, Kun and Che, Wanxiang. Generating Natural Language Adversarial Examples through Probability Weighted Word Saliency. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1103
-
[68]
Word-level Textual Adversarial Attacking as Combinatorial Optimization
Zang, Yuan and Qi, Fanchao and Yang, Chenghao and Liu, Zhiyuan and Zhang, Meng and Liu, Qun and Sun, Maosong. Word-level Textual Adversarial Attacking as Combinatorial Optimization. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.540
-
[69]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Combating adversarial misspellings with robust word recognition , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
-
[70]
International Conference on Learning Representations , year=
FreeLB: Enhanced Adversarial Training for Natural Language Understanding , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.