Recognition: 1 theorem link
· Lean TheoremMPINeuralODE: Multiple-Initial-Condition Physics-Informed Neural ODEs for Globally Consistent Dynamical System Learning
Pith reviewed 2026-05-14 19:18 UTC · model grok-4.3
The pith
Combining a soft physics residual with multiple-initial-condition shooting lets Neural ODEs recover the true vector field from few trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a soft physics-informed residual and a Multiple-Initial-Condition multiple-shooting curriculum are structurally complementary; the residual anchors vector-field magnitude on the enlarged support created by the curriculum, thereby recovering the underlying dynamics and producing globally consistent forecasts.
What carries the argument
MPINeuralODE, the model that integrates a soft physics-informed residual loss with a Multiple-Initial-Condition (MIC) multiple-shooting training curriculum.
If this is right
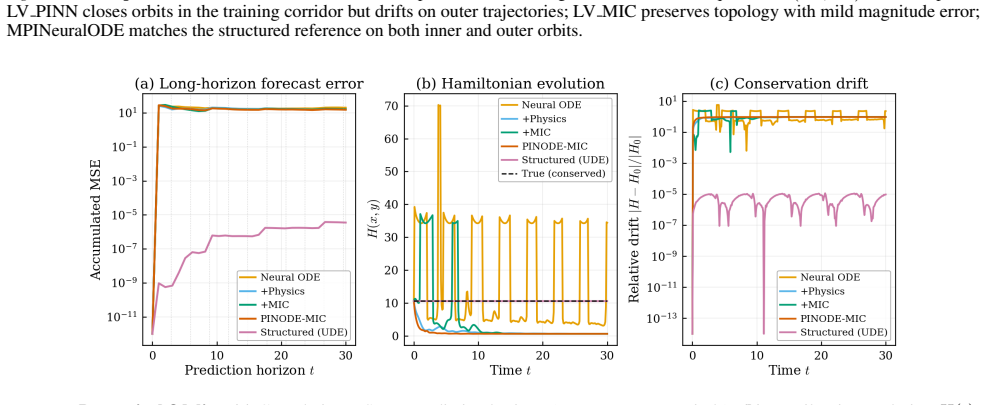
- Out-of-sample trajectories remain stable over long horizons without accumulating drift.
- Hamiltonian quantities are preserved at levels comparable to a dedicated physics-informed network.
- The same architecture yields lower mean-squared error than either a baseline Neural ODE or a pure data-driven multiple-shooting method on the Lotka-Volterra equations.
- The learned dynamics generalize to initial conditions never seen during training.
Where Pith is reading between the lines
- The same complementary pairing could be tested on other partially known ODE systems such as rigid-body rotation or chemical kinetics where only some conserved quantities are available.
- The curriculum may lower the total number of observed trajectories needed to reach a given accuracy level.
- Forecasting tasks that require both data fidelity and conservation laws could adopt the same training schedule without changing the underlying network architecture.
Load-bearing premise
The soft physics-informed residual and the MIC multiple-shooting curriculum are structurally complementary so that the physics term anchors the vector-field magnitude on the support enlarged by MIC.
What would settle it
A direct numerical check on the Lotka-Volterra equations showing that the learned vector field on out-of-sample initial conditions either matches the true right-hand side within a stated tolerance or fails to reduce long-horizon MSE below the plain Neural ODE baseline.
Figures

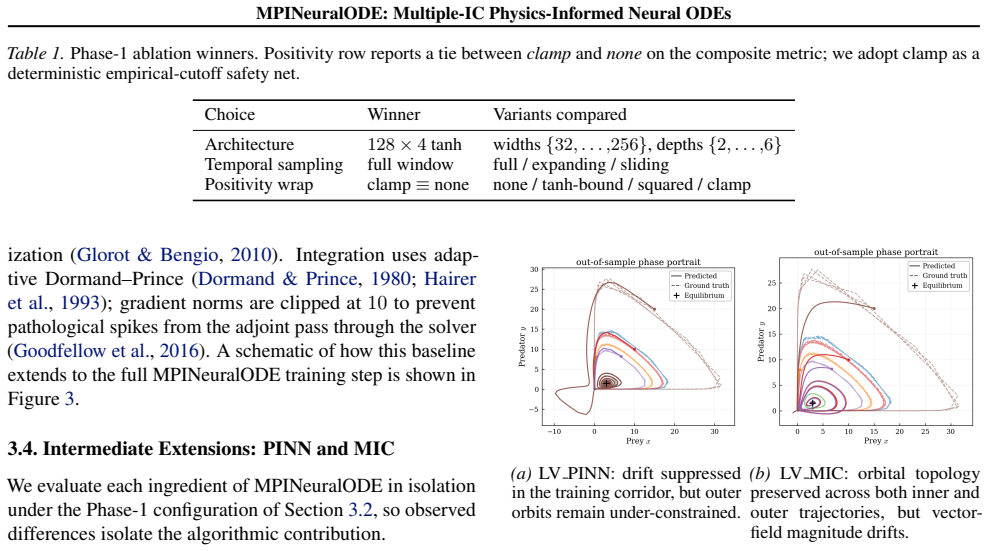
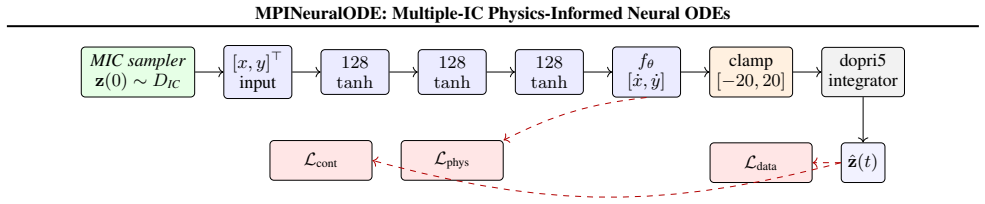





read the original abstract
Neural ordinary differential equations (Neural ODEs) often fit training trajectories while generalizing poorly to unseen initial conditions and long horizons. We propose MPINeuralODE, which combines a soft physics-informed residual with a Multiple-Initial-Condition (MIC) multiple-shooting curriculum whose ingredients are structurally complementary: the physics term anchors the vector-field magnitude on the support that MIC enlarges. We evaluate along three axes: out-of-sample error, long-horizon stability, and Hamiltonian drift, which together expose whether the learned dynamics recover the underlying vector field. On Lotka-Volterra, MPINeuralODE achieves the lowest out-of-sample and long-horizon MSE among data-driven methods, with a 26% reduction over the baseline Neural ODE, while essentially matching the PINN ablation on Hamiltonian drift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MPINeuralODE, which augments Neural ODEs by combining a soft physics-informed residual with a Multiple-Initial-Condition (MIC) multiple-shooting curriculum. The authors claim these ingredients are structurally complementary—the physics term anchors the vector-field magnitude on the enlarged support created by MIC—yielding improved generalization. On the Lotka-Volterra benchmark, MPINeuralODE is reported to achieve the lowest out-of-sample and long-horizon MSE among data-driven methods (26% reduction relative to baseline Neural ODE) while matching a PINN ablation on Hamiltonian drift.
Significance. If the empirical results hold under controlled and reproducible conditions, the work would offer a practical demonstration that soft physics constraints and multiple-shooting curricula can be combined to improve long-horizon consistency in learned dynamical systems. The three-axis evaluation (out-of-sample error, long-horizon stability, Hamiltonian drift) is well-chosen for assessing vector-field recovery. The absence of detailed experimental protocols, however, currently limits the strength of this contribution.
major comments (1)
- [Abstract] Abstract: The reported 26% MSE reduction and lowest out-of-sample/long-horizon error on Lotka-Volterra are presented without details on data splits, hyperparameter selection, error bars, or the full training procedure. These omissions make the central quantitative claims impossible to verify or reproduce from the given information.
minor comments (1)
- [§3] The complementarity between the soft physics residual and MIC curriculum is presented as an explanatory hypothesis; a brief additional ablation isolating the effect on vector-field magnitude would make this claim more concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract requires additional context to support the reported quantitative claims and will revise it accordingly while ensuring all experimental details appear in the main text and appendices.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 26% MSE reduction and lowest out-of-sample/long-horizon error on Lotka-Volterra are presented without details on data splits, hyperparameter selection, error bars, or the full training procedure. These omissions make the central quantitative claims impossible to verify or reproduce from the given information.
Authors: We agree that the abstract as written does not contain sufficient detail for independent verification. In the revised manuscript we will update the abstract to briefly state the data protocol (trajectories generated from 100 random initial conditions drawn from a uniform distribution over the phase space, with an 80/20 train/test split on initial conditions), the hyperparameter procedure (grid search over learning rate, network width, and physics-residual weight on a held-out validation set of 20 trajectories), and the reporting convention (mean and standard deviation over five independent random seeds). The complete training procedure, including the MIC curriculum schedule, multiple-shooting loss formulation, and soft physics residual implementation, is already described in Sections 3.2–3.3 and Appendix B with pseudocode; we will add an explicit reproducibility paragraph with a link to the code repository. These changes will be reflected in both the abstract and the experimental section. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript presents an empirical demonstration that combining a soft physics-informed residual with a Multiple-Initial-Condition multiple-shooting curriculum yields lower out-of-sample and long-horizon MSE on Lotka-Volterra (26% reduction vs. baseline Neural ODE) while matching a PINN ablation on Hamiltonian drift. These results are obtained via direct experimental comparison on concrete metrics; no derivation chain, uniqueness theorem, or first-principles prediction is invoked that reduces by the paper's own equations to a fitted parameter or self-citation. The stated complementarity of the two ingredients is offered as an explanatory hypothesis rather than a formally derived equivalence. The work is therefore self-contained against external benchmarks and receives a score of 0.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
combines a soft physics-informed residual with a Multiple-Initial-Condition (MIC) multiple-shooting curriculum whose ingredients are structurally complementary: the physics term anchors the vector-field magnitude on the support that MIC enlarges
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
L. S. Pontryagin and V. G. Boltyanskii and R. V. Gamkrelidze and E. F. Mishchenko , title =
- [4]
- [5]
-
[6]
J. R. Dormand and P. J. Prince , title =. Journal of Computational and Applied Mathematics , volume =
-
[7]
Ernst Hairer and Syvert P. N. Solving Ordinary Differential Equations
-
[8]
Hans Georg Bock and Karl-Josef Plitt , title =. Proceedings of the 9th. 1984 , note =
work page 1984
-
[9]
Henning U. Voss and Jens Timmer and J. Nonlinear dynamical system identification from uncertain and indirect measurements , journal =
-
[10]
Multiple shooting for training neural differential equations on time series , journal =
Evren Mert Turan and Johannes J. Multiple shooting for training neural differential equations on time series , journal =. 2022 , doi =
work page 2022
- [11]
-
[12]
Proceedings of the 13th International Conference on Artificial Intelligence and Statistics , pages =
Xavier Glorot and Yoshua Bengio , title =. Proceedings of the 13th International Conference on Artificial Intelligence and Statistics , pages =
-
[13]
Diederik P. Kingma and Jimmy Ba , title =. International Conference on Learning Representations , year =
-
[14]
Ian Goodfellow and Yoshua Bengio and Aaron Courville , title =
-
[15]
Steven L. Brunton and Joshua L. Proctor and J. Nathan Kutz , title =. Proceedings of the National Academy of Sciences , volume =
-
[16]
Physical Review Letters , volume =
Jaideep Pathak and Brian Hunt and Michelle Girvan and Zhixin Lu and Edward Ott , title =. Physical Review Letters , volume =
-
[17]
Kathleen Champion and Bethany Lusch and J. Nathan Kutz and Steven L. Brunton , title =. Proceedings of the National Academy of Sciences , volume =
-
[18]
Maziar Raissi and Paris Perdikaris and George E. Karniadakis , title =. arXiv preprint arXiv:1711.10561 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Maziar Raissi and Paris Perdikaris and George E. Karniadakis , title =. Journal of Computational Physics , volume =
-
[20]
Christopher Rackauckas and Yingbo Ma and Julius Martensen and Collin Warner and Kirill Zubov and Rohit Supekar and Dominic Skinner and Ali Ramadhan and Alan Edelman , title =. arXiv preprint arXiv:2001.04385 , year =
-
[21]
Krishnapriyan and Amir Gholami and Shandian Zhe and Robert M
Aditi S. Krishnapriyan and Amir Gholami and Shandian Zhe and Robert M. Kirby and Michael W. Mahoney , title =. Advances in Neural Information Processing Systems , volume =
-
[22]
SIAM Journal on Scientific Computing , volume =
Sifan Wang and Yujun Teng and Paris Perdikaris , title =. SIAM Journal on Scientific Computing , volume =
-
[23]
Ricky T. Q. Chen and Yulia Rubanova and Jesse Bettencourt and David K. Duvenaud , title =. Advances in Neural Information Processing Systems , volume =
-
[24]
Advances in Neural Information Processing Systems , volume =
Emilien Dupont and Arnaud Doucet and Yee Whye Teh , title =. Advances in Neural Information Processing Systems , volume =
-
[25]
Yulia Rubanova and Ricky T. Q. Chen and David Duvenaud , title =. Advances in Neural Information Processing Systems , volume =
-
[26]
Advances in Neural Information Processing Systems , volume =
Patrick Kidger and James Morrill and James Foster and Terry Lyons , title =. Advances in Neural Information Processing Systems , volume =
-
[27]
Advances in Neural Information Processing Systems , volume =
Samuel Greydanus and Misko Dzamba and Jason Yosinski , title =. Advances in Neural Information Processing Systems , volume =
-
[28]
Tom Bertalan and Felix Dietrich and Igor Mezi. On learning. Chaos: An Interdisciplinary Journal of Nonlinear Science , volume =
-
[29]
Pengzhan Jin and Zhen Zhang and Aiqing Zhu and Yifa Tang and George Em Karniadakis , title =. Neural Networks , volume =
-
[30]
Yang, Lake and Malpica-Morales, Antonio and Papadakis Wood, Frank Ioannis and Kalliadasis, Serafim , title =. 2026 , url =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.