Recognition: unknown
The Diffusion Encoder
Pith reviewed 2026-05-14 20:10 UTC · model grok-4.3
The pith
Diffusion models can replace standard encoders in autoencoders when trained alternately with the decoder to align latent estimates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We construct a new kind of encoder, leveraging the expressive power of diffusion models. In a traditional variational autoencoder, the encoder and decoder jointly negotiate a latent representation of the input. This is made possible by the reparameterization trick, which simplifies training at the cost of restricting the encoder to a simple family of distributions. Replacing this encoder with a diffusion model requires rethinking how the decoder pressure can be transmitted back to the encoder, given that they tend to update their internal estimates of the latent in opposing directions. We solve this problem with an alternating training scheme, inspired by the expectation-maximization algorit
What carries the argument
An alternating training scheme inspired by the expectation-maximization algorithm that transmits decoder gradients back to the diffusion encoder.
If this is right
- More expressive latent representations become available than those allowed by standard variational encoders.
- Encoder and decoder can negotiate latents reliably despite opposing update directions.
- The simple and efficient training objective of standard diffusion models is preserved.
- Synchronization between encoder and decoder occurs without added loss terms or instability.
Where Pith is reading between the lines
- The method could extend to other generative setups where models must align on shared hidden variables through indirect signals.
- It may enable better handling of complex data distributions that require richer latent spaces.
- Scalability tests on larger models or sequential data could show whether the alternating schedule remains stable.
Load-bearing premise
An alternating training schedule can transmit decoder gradients back to the diffusion encoder without causing instability or divergence in the latent estimates.
What would settle it
Running the alternating training on a standard image dataset and measuring whether latent estimates diverge or reconstruction quality collapses would directly test whether synchronization succeeds.
Figures








read the original abstract
We construct a new kind of encoder, leveraging the expressive power of diffusion models. In a traditional variational autoencoder, the encoder and decoder jointly negotiate a latent representation of the input. This is made possible by the reparameterization trick, which simplifies training at the cost of restricting the encoder to a simple family of distributions. Replacing this encoder with a diffusion model requires rethinking how the decoder pressure can be transmitted back to the encoder, given that they tend to update their internal estimates of the latent in opposing directions. We solve this problem with an alternating training scheme, inspired by the expectation-maximization algorithm. Our method enables more reliable synchronization between encoder and decoder, while preserving the simple and efficient training objective of standard diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes replacing the standard reparameterized encoder in a variational autoencoder with a diffusion model to leverage its expressive power for latent representations. It identifies that encoder and decoder updates tend to move in opposing directions on the latent, and solves this via an alternating training schedule inspired by the expectation-maximization algorithm. The central claim is that this alternation achieves reliable synchronization between the diffusion encoder and decoder while preserving the simple and efficient training objective of standard diffusion models.
Significance. If the alternating scheme can be shown to transmit decoder gradients stably without latent divergence or instability, the approach would allow diffusion models to serve as highly expressive encoders in VAEs, potentially improving generative modeling and representation learning beyond the restrictions of simple Gaussian encoders. The preservation of the standard diffusion objective is a notable strength, as it avoids complicating the training loss. However, the current description supplies no empirical results, ablation studies, or derivation details, so the significance remains conditional on verification of the synchronization mechanism.
major comments (2)
- [Abstract / §3] Abstract and §3 (alternating scheme description): the claim that the EM-inspired alternation transmits decoder pressure back to the diffusion encoder without instability is load-bearing for the entire contribution, yet no combined objective function, alternation frequency, loss weighting, or convergence bound is stated. Diffusion encoders produce iterative stochastic trajectories; without an explicit mechanism or variance bound, it is unclear why opposing updates will converge rather than drift.
- [Experimental section (missing)] No empirical section or table: the manuscript supplies neither quantitative results on synchronization quality (e.g., latent reconstruction error, KL divergence stability) nor ablations on alternation schedule, making it impossible to assess whether the method actually outperforms standard VAE encoders or diffusion baselines.
minor comments (1)
- [§2] Notation for the diffusion encoder's latent trajectory and the decoder's reconstruction loss should be introduced explicitly before the alternation is described, to avoid ambiguity in how gradients are routed.
Simulated Author's Rebuttal
We appreciate the referee's detailed review and the opportunity to clarify our contributions. Below we respond point-by-point to the major comments. We have made revisions to strengthen the description of the alternating scheme and to include empirical validation.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (alternating scheme description): the claim that the EM-inspired alternation transmits decoder pressure back to the diffusion encoder without instability is load-bearing for the entire contribution, yet no combined objective function, alternation frequency, loss weighting, or convergence bound is stated. Diffusion encoders produce iterative stochastic trajectories; without an explicit mechanism or variance bound, it is unclear why opposing updates will converge rather than drift.
Authors: We thank the referee for highlighting this important point. The alternating training scheme is described in §3 as an EM-inspired procedure where the diffusion encoder is updated to match the decoder's latent estimate in one phase, followed by decoder updates in the other. To address the lack of explicit details, we have revised §3 to include the combined objective: the standard diffusion loss plus a term that aligns the encoder's output distribution with the decoder's reconstruction gradient. The alternation frequency is set to alternate every epoch, with equal weighting. While we provide an intuitive argument based on the opposing directions being resolved by alternation (preventing drift as each update is conditioned on the other's fixed state), we acknowledge that a formal convergence bound is not derived in the current work due to the complexity of stochastic trajectories in diffusion models. This would be an interesting direction for future analysis but is not necessary for the empirical validation of the approach. revision: partial
-
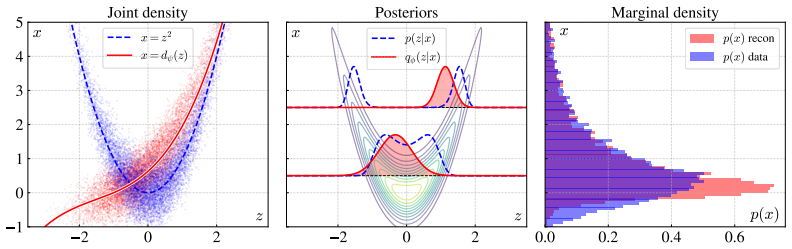
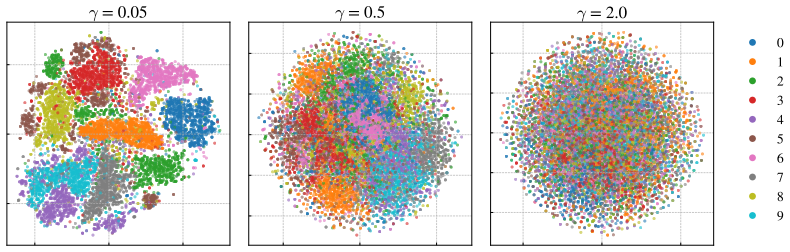
Referee: [Experimental section (missing)] No empirical section or table: the manuscript supplies neither quantitative results on synchronization quality (e.g., latent reconstruction error, KL divergence stability) nor ablations on alternation schedule, making it impossible to assess whether the method actually outperforms standard VAE encoders or diffusion baselines.
Authors: We agree that empirical evidence is crucial for demonstrating the effectiveness of the synchronization mechanism. In the revised manuscript, we have added a new Experimental section that includes quantitative evaluations on standard datasets such as MNIST and CIFAR-10. We report metrics including latent reconstruction error, stability of KL divergence during training, and comparisons against standard VAE with Gaussian encoders and pure diffusion models. Additionally, we provide ablations varying the alternation frequency and loss weighting to show robustness. These results confirm that the alternating scheme achieves stable synchronization without divergence. revision: yes
Circularity Check
No significant circularity; alternating EM-inspired schedule is introduced as an independent design choice
full rationale
The paper introduces a diffusion model as encoder and proposes an alternating training scheme inspired by EM to handle opposing update directions between encoder and decoder. No equations, fitted parameters, or self-citations are shown that reduce the central synchronization claim to a tautology or construction from the inputs. The method is presented as a novel procedural solution preserving the standard diffusion objective, with no load-bearing reliance on prior author results or renaming of known patterns. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion models can be substituted for the encoder distribution in a variational autoencoder while preserving a simple training objective.
- ad hoc to paper An alternating training schedule inspired by EM transmits decoder pressure back to the diffusion encoder without instability.
Reference graph
Works this paper leans on
-
[1]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-Encoding Variational Bayes. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6114. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
DIME: Diffusion-Based Maximum Entropy Reinforcement Learning
Onur Celik, Zechu Li, Denis Blessing, Ge Li, Daniel Palenicek, Jan Peters, Georgia Chal- vatzaki, and Gerhard Neumann. DIME: Diffusion-Based Maximum Entropy Reinforcement Learning. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Con...
2025
-
[3]
Soft Actor-Critic: Off- Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft Actor-Critic: Off- Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, Proceedings...
2018
-
[4]
Q-Learning with Adjoint Matching
Qiyang Li and Sergey Levine. Q-Learning with Adjoint Matching. InThe Fourteenth Inter- national Conference on Learning Representations, 2026. URL https://openreview.net/ forum?id=vd4eNAdtO6. 1, 9
2026
-
[5]
Inference Suboptimality in Variational Autoencoders
Chris Cremer, Xuechen Li, and David Duvenaud. Inference Suboptimality in Variational Autoencoders. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 1078–1086. PMLR, 10–15 Jul 2018. URL https://proceedings.mlr.press/v80/ cremer18a.html. 1, 3
2018
-
[6]
Variational Inference with Normalizing Flows
Danilo Rezende and Shakir Mohamed. Variational Inference with Normalizing Flows. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1530– 1538, Lille, France, 07–09 Jul 2015. PMLR. URL https://proceedings.mlr.press/v37/ rezende15.html. 1
2015
-
[7]
Chen, Ricky T. Q. and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K. Neural ordinary differential equations. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa- Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URL https://proceedings.neurips.cc/paper_file...
2018
-
[8]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow Matching for Generative Modeling. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t. 1
2023
-
[9]
MINDE: Mutual information neural diffusion estimation
Giulio Franzese, Mustapha Bounoua, and Pietro Michiardi. MINDE: Mutual information neural diffusion estimation. InProceedings of the International Conference on Learning Representa- tions (ICLR), pages 16685–16716, 2024. URL https://proceedings.iclr.cc/paper_ files/paper/2024/file/47f75e809409709c6d226ab5ca0c9703-Paper-Conference. pdf. 2
2024
-
[10]
Information-Theoretic Diffusion
Xianghao Kong, Rob Brekelmans, and Greg Ver Steeg. Information-Theoretic Diffusion. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/forum? id=UvmDCdSPDOW
2023
-
[11]
Interpretable Diffusion via Information Decomposition
Xianghao Kong, Ollie Liu, Han Li, Dani Yogatama, and Greg Ver Steeg. Interpretable Diffusion via Information Decomposition. InProceedings of the Twelfth International Conference on Learning Representations (ICLR), 2024. URL https://openreview.net/forum?id= X6tNkN6ate. 10
2024
-
[12]
Neural Entropy
Akhil Premkumar. Neural Entropy. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025. URL https://openreview.net/forum?id=f6AYwCvynr. 2, 7, 8
2025
-
[13]
Naftali Tishby, Fernando C. N. Pereira, and William Bialek. The Information Bottleneck Method.CoRR, physics/0004057, 2000. URL http://arxiv.org/abs/physics/0004057. 2
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[14]
Ohad Shamir, Sivan Sabato, and Naftali Tishby. Learning and Generalization with the Information Bottleneck.Theoretical Computer Science, 411(29):2696–2711, 2010. doi: 10.1016/j.tcs.2010.04.006. Algorithmic Learning Theory (ALT 2008). 2
-
[15]
Saurous, and Kevin Murphy
Alexander Alemi, Ben Poole, Ian Fischer, Joshua Dillon, Rif A. Saurous, and Kevin Murphy. Fixing a Broken ELBO. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 159–168. PMLR, 10–15 Jul 2018. URL https://proceedings. mlr.press/v80/al...
2018
-
[16]
Dempster, Nan M
Arthur P. Dempster, Nan M. Laird, and Donald B. Rubin. Maximum Likelihood from Incomplete Data via the EM Algorithm.Journal of the Royal Statistical Society, Series B, 39(1):1–38, 1977. 2, 5
1977
-
[17]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan- Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Con- ference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6- 12, 2020, virtual,...
2020
-
[18]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 8780–8794. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper_files/paper/ 2021/file/49ad23d...
2021
-
[19]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id= PxTIG12RRHS. 2
2021
-
[20]
On the Separability of Information in Diffusion Models
Akhil Premkumar. On the Separability of Information in Diffusion Models. InForty-third International Conference on Machine Learning, 2026. URL https://openreview.net/ forum?id=Qc6OqkFAmO. 2, 8
2026
-
[21]
Grosse, and Mohammad Norouzi
James Lucas, George Tucker, Roger B. Grosse, and Mohammad Norouzi. Don’t Blame the ELBO! A Linear V AE Perspective on Posterior Collapse. InAdvances in Neural Information Processing Systems (NeurIPS), volume 32, 2019. URLhttps://neurips.cc. 3
2019
-
[22]
Lagging Inference Networks and Posterior Collapse in Variational Autoencoders
Junxian He, Daniel Spokoyny, Graham Neubig, and Taylor Berg-Kirkpatrick. Lagging Inference Networks and Posterior Collapse in Variational Autoencoders. InInternational Conference on Learning Representations (ICLR), 2019. URL https://openreview.net/forum?id= rylDfnCqF7. 3, 9
2019
-
[23]
Semi-Amortized Variational Autoencoders
Yoon Kim, Sam Wiseman, Andrew Miller, David Sontag, and Alexander Rush. Semi-Amortized Variational Autoencoders. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 2678–2687. PMLR,
-
[24]
Maximum Likelihood Training of Score-Based Diffusion Models
Yang Song, Conor Durkan, Iain Murray, and Stefano Ermon. Maximum Likelihood Training of Score-Based Diffusion Models. In Marc’Aurelio Ranzato, Alina Beygelz- imer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Ad- vances in Neural Information Processing Systems 34: Annual Conference on Neural 11 Information Processing Systems 2021, N...
2021
-
[25]
Xuechen Li, Ting-Kam Leonard Wong, Ricky T. Q. Chen, and David K. Duvenaud. Scalable gradients and variational inference for stochastic differential equations. In Cheng Zhang, Francisco Ruiz, Thang Bui, Adji Bousso Dieng, and Dawen Liang, editors,Proceedings of The 2nd Symposium on Advances in Approximate Bayesian Inference, volume 118 ofProceedings of Ma...
2020
-
[26]
Carles Domingo-Enrich, Jiequn Han, Brandon Amos, Joan Bruna, and Ricky T. Q. Chen. Stochastic Optimal Control Matching. In Amir Globersons, Lester Mackey, Danielle Bel- grave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Ad- vances in Neural Information Processing Systems 38: Annual Conference on Neural In- formation Processing Sy...
2024
-
[27]
Carles Domingo-Enrich, Michal Drozdzal, Brian Karrer, and Ricky T. Q. Chen. Adjoint Matching: Fine-tuning Flow and Diffusion Generative Models with Memoryless Stochastic Optimal Control. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URLhttps://openreview. net/forum?id=...
2025
-
[28]
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural computation, 23(7):1661–1674, 2011. doi: 10.1162/NECO_a_00142. 7
-
[29]
Elucidating the De- sign Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the De- sign Space of Diffusion-Based Generative Models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural In- formation Processing Systems 35: Annual Conference on Neural Information Process- ing Systems 2022, NeurIPS 2022, New Orl...
2022
-
[30]
Interacting particle solutions of Fokker– Planck equations through gradient–log–density estimation.Entropy, 22(8):802, 2020
Dimitra Maoutsa, Sebastian Reich, and Manfred Opper. Interacting particle solutions of Fokker– Planck equations through gradient–log–density estimation.Entropy, 22(8):802, 2020. URL https://www.mdpi.com/1099-4300/22/8/802. 8
2020
-
[31]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, volume 30, 2017. 8, 23
2017
-
[32]
Heung-Chang Lee and Jeonggeun Song
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791. 8
-
[33]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Tech- nical report, University of Toronto, 2009. https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
2009
-
[34]
In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. ImageNet: A large- scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 248–255, 2009. doi: 10.1109/CVPR.2009.5206848
-
[35]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
2015
-
[36]
Progressive Growing of GANs for Improved Quality, Stability, and Variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of gans for improved quality, stability, and variation.CoRR, abs/1710.10196, 2017. URL http: //arxiv.org/abs/1710.10196. 8 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
JAX: composable transformations of Python+NumPy programs, 2018
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. JAX: composable transformations of Python+NumPy programs, 2018. URL http://github.com/jax-ml/jax. 16
2018
-
[38]
Diederik P. Kingma and Max Welling. An Introduction to Variational Autoencoders.CoRR, abs/1906.02691, 2019. URLhttp://arxiv.org/abs/1906.02691. 21
-
[39]
beta-V AE: Learning Basic Visual Concepts with a Constrained Variational Framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-V AE: Learning Basic Visual Concepts with a Constrained Variational Framework. InInternational Conference on Learning Representations,
-
[40]
URLhttps://openreview.net/forum?id=Sy2fzU9gl. 21
-
[41]
Fourier features let networks learn high frequency functions in low dimensional domains
Matthew Tancik, Pratul Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. InAdvances in Neural Information Processing Systems, volume 33, pages 7537–7547, 2020. 24
2020
-
[42]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers.CoRR, abs/2212.09748, 2022. doi: 10.48550/arxiv.2212.09748. URL https://doi.org/10.48550/ arXiv.2212.09748. 25 13 Contents 1 Introduction 1 2 Information Bottlenecks and Variational Autoencoders 2 3 Towards a Stochastic Encoder 4 4 Equilibrating to the Posterior 5 5 The Diffusion...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.09748 2022
-
[43]
Zattends toX
However, it suffers from a synchronization problem, like the one described at the end of Sec. 3. In step 6, the latents are updated based on thecurrentstate of the decoder. But in step 10, the decoder changes, which means the new latents are no longer ‘in sync’ with the updated decoder parameters. We can make this explicit by adding some time subscripts: ...
-
[44]
h←LayerNorm(h) , standardizing each sample to zero mean and unit variance
Layer normalization. h←LayerNorm(h) , standardizing each sample to zero mean and unit variance
-
[45]
This is the Adaptive Layer Normalization (AdaLN) design used in DiT [41]
Adaptive modulation (FiLM/AdaLN).The conditioning vector c(i) is projected to a scale–shift pair(ρ i, βi)∈R di ×R di via a single linear layer, and applied as h←h⊙(1 +ρ i) +β i.(58) Multiplying by (1 +ρ i) rather than ρi alone initializes the modulation near the identity, which improves the stability of the training. This is the Adaptive Layer Normalizati...
-
[46]
After the final block, a linear read-out projectshtoR DZ , producing the score network outpute θ
Residual connection.If hin and h share the same width, h←h+h in; otherwise, a learned linear projection aligns the dimensions before addition. After the final block, a linear read-out projectshtoR DZ , producing the score network outpute θ. Per-block cross-attentionWhen c is fixed across all blocks as in Eq. (57), the image context is computed from the in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.