Recognition: no theorem link
TurboGR: An Accelerated Training System for Large-Scale Generative Recommendation
Pith reviewed 2026-05-14 18:13 UTC · model grok-4.3
The pith
TurboGR enables training of up to 0.2 billion parameter generative recommendation models on Ascend NPUs at 54.71 percent MFU with 0.97 scalability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TurboGR addresses the absence of high-performance jagged operators and the architectural mismatch with Ascend NPUs by combining Ascend-affinity jagged acceleration, distributed communication optimization via hierarchical sparse parallelism and semi-asynchronous training with convergence guarantees, and negative sampling optimization through asynchronous offloading and intra-batch logit sharing, resulting in 54.71 percent MFU, 94 percent NPU utilization, and 0.97 scalability for models up to 0.2B parameters.
What carries the argument
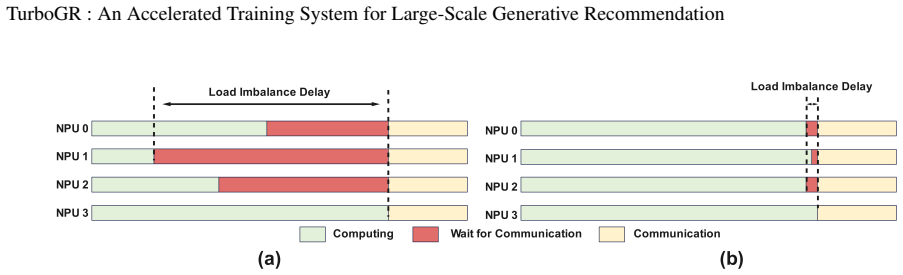
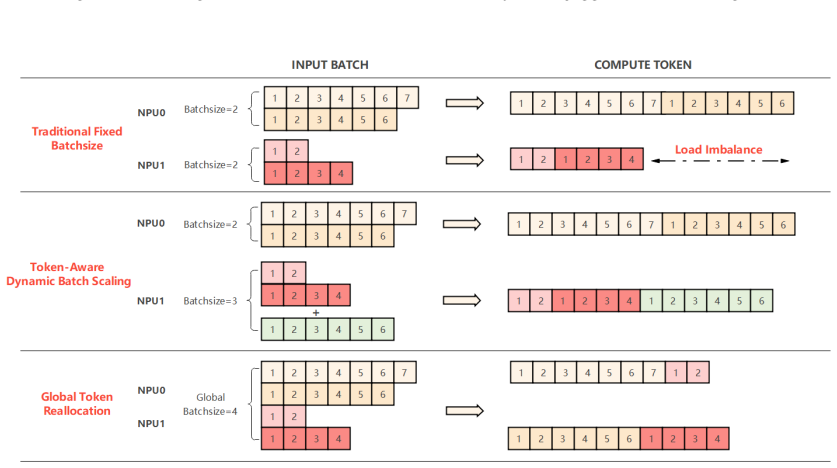
The TurboGR system, built around fusion operators that eliminate padding redundancy, dynamic load balancing that cuts inter-device imbalance from 47 percent to 2.4 percent, hierarchical sparse parallelism, semi-asynchronous training, and jaggedness-aware FP16 quantization for negative sampling.
If this is right
- Models up to 0.2 billion parameters become trainable without prohibitive communication overhead on Ascend NPUs.
- Dynamic load balancing reduces device imbalance to 2.4 percent while sustaining 94 percent NPU utilization.
- Negative sampling expands the effective negative space without additional embedding lookups through asynchronous offloading and intra-batch logit sharing.
- Near-linear scalability of 0.97 allows efficient use of larger clusters for generative recommendation training.
Where Pith is reading between the lines
- The same fusion and pipeline techniques could be adapted to other dense-optimized accelerators facing sparse recommendation workloads.
- Extending the semi-asynchronous guarantees to even larger batch sizes or multi-modal generative recommendation might further improve throughput.
- Testing the system on datasets larger than KuaiRand-27K would show whether the scaling law benefits continue to compound.
Load-bearing premise
The jagged optimizations and semi-asynchronous training preserve model quality and convergence, and the reported MFU and scalability figures extend beyond the KuaiRand-27K dataset and Ascend hardware.
What would settle it
Retraining the same 0.2B parameter model on KuaiRand-27K once with full synchronous updates and once with the semi-asynchronous mode, then comparing final recommendation quality metrics such as AUC or NDCG.
Figures











read the original abstract
Generative recommendation (GR) has emerged as a promising paradigm that replaces fragmented, scenario-specific architectures with unified Transformer-based models, exhibiting scaling-law behavior where recommendation quality improves systematically with increased model capacity and training data. However, deploying GR at scale on Ascend NPUs faces fundamental system-level challenges. These challenges are further exacerbated on Ascend NPUs due to the absence of high-performance implementations for jagged operators and the architectural mismatch between irregular sparse primitives and NPU's dense-computation-optimized design. In this paper, we present \model, an Ascend-affinity training system for generative recommendation that systematically addresses these bottlenecks through three core innovations: (i) Ascend-affinity jagged acceleration, including fusion operators that eliminate padding redundancy and dynamic load balancing that reduces inter-device imbalance from 47\% to 2.4\%; (ii) distributed communication optimization, comprising hierarchical sparse parallelism, semi-asynchronous training with proven convergence guarantees, and fine-grained pipeline orchestration that sustains 94\% NPU utilization; and (iii) negative sampling optimization via asynchronous offloading, jaggedness-aware FP16 quantization, and intra-batch logit sharing that expand the effective negative space without additional embedding lookups. Evaluated on the KuaiRand-27K dataset, \model supports training at up to 0.2B parameters and achieves 54.71\% MFU with near-linear scalability (0.97).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TurboGR, an Ascend-affinity training system for large-scale generative recommendation. It addresses NPU-specific challenges with three innovations: (i) Ascend-affinity jagged acceleration via fusion operators and dynamic load balancing that reduces inter-device imbalance from 47% to 2.4%; (ii) distributed communication optimizations including hierarchical sparse parallelism, semi-asynchronous training with claimed convergence guarantees, and pipeline orchestration achieving 94% NPU utilization; and (iii) negative sampling optimizations via asynchronous offloading, jaggedness-aware FP16 quantization, and intra-batch logit sharing. Evaluated on KuaiRand-27K, the system trains models up to 0.2B parameters with 54.71% MFU and 0.97 scalability.
Significance. If the semi-asynchronous and jagged optimizations preserve recommendation quality (AUC/NDCG), the work would be significant for enabling efficient scaling of Transformer-based generative recommendation on Ascend NPUs, a hardware platform where sparse and jagged primitives are poorly supported. The empirical measurements on a named dataset with concrete system metrics (MFU, scalability, imbalance reduction) provide practical evidence for hardware-specific distributed training techniques.
major comments (3)
- [Evaluation] Evaluation section: the central claims rest on 54.71% MFU and 0.97 scalability while preserving generative recommendation performance, yet no AUC, NDCG, or other quality metrics are reported comparing the semi-asynchronous/jagged setup against a synchronous baseline. This omission leaves the load-bearing assumption that model quality is unaffected unsubstantiated.
- [Section on semi-asynchronous training] Section on semi-asynchronous training: the abstract asserts 'proven convergence guarantees' for semi-asynchronous training, but the manuscript provides only system-level metrics (NPU utilization, MFU) without a theorem, proof sketch, or empirical convergence curves versus the synchronous case.
- [Abstract] Abstract: the specific numeric results (54.71% MFU, 0.97 scalability, imbalance reduction from 47% to 2.4%) are stated without baselines, error bars, or protocol details, weakening the ability to assess whether the gains generalize beyond the KuaiRand-27K/Ascend configuration.
minor comments (2)
- Clarify the precise definition and measurement of MFU for generative recommendation workloads, as it may differ from standard dense LLM usage due to the sparse and jagged components.
- The description of hierarchical sparse parallelism would benefit from a diagram or pseudocode showing the interaction between levels.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for strengthening the evaluation of model quality, convergence properties, and result reporting. We address each point below and will revise the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claims rest on 54.71% MFU and 0.97 scalability while preserving generative recommendation performance, yet no AUC, NDCG, or other quality metrics are reported comparing the semi-asynchronous/jagged setup against a synchronous baseline. This omission leaves the load-bearing assumption that model quality is unaffected unsubstantiated.
Authors: We agree that direct evidence of preserved recommendation quality is essential. In the revised manuscript, we will add AUC and NDCG comparisons on the KuaiRand-27K dataset between models trained under the semi-asynchronous/jagged setup and a fully synchronous baseline. These results will be presented in the evaluation section to substantiate that the optimizations maintain generative recommendation performance. revision: yes
-
Referee: [Section on semi-asynchronous training] Section on semi-asynchronous training: the abstract asserts 'proven convergence guarantees' for semi-asynchronous training, but the manuscript provides only system-level metrics (NPU utilization, MFU) without a theorem, proof sketch, or empirical convergence curves versus the synchronous case.
Authors: The convergence guarantees are based on adaptations of established asynchronous SGD theory to our hierarchical sparse parallelism and semi-asynchronous pipeline. To address the gap, the revised section will include a concise proof sketch outlining the key assumptions and convergence rate. We will also add empirical convergence curves (training loss and AUC versus steps) comparing the semi-asynchronous and synchronous cases on KuaiRand-27K. revision: yes
-
Referee: [Abstract] Abstract: the specific numeric results (54.71% MFU, 0.97 scalability, imbalance reduction from 47% to 2.4%) are stated without baselines, error bars, or protocol details, weakening the ability to assess whether the gains generalize beyond the KuaiRand-27K/Ascend configuration.
Authors: We will revise the abstract to reference the baseline configuration (standard distributed training without the proposed jagged acceleration, hierarchical parallelism, and negative sampling optimizations) and note that results are averaged over multiple runs. Error bars and full protocol details (e.g., run count, hyperparameters) will be reported in the evaluation section and figures, with the abstract updated to direct readers there for assessment of generalizability. revision: yes
Circularity Check
No circularity: all claims are empirical system measurements
full rationale
The paper is a systems/engineering contribution describing optimizations for training generative recommendation models on Ascend NPUs. Key reported outcomes (54.71% MFU, 0.97 scalability at 0.2B parameters on KuaiRand-27K) are direct runtime measurements on a named dataset and hardware, not quantities derived from equations, fitted parameters, or self-referential definitions. No derivation chain, uniqueness theorem, ansatz, or prediction step is present that reduces outputs to inputs by construction. The phrase 'proven convergence guarantees' for semi-asynchronous training is asserted without an exhibited self-citation chain or equation that would make it circular under the defined criteria. This is a standard non-circular empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semi-asynchronous training with the described pipeline maintains convergence guarantees
Reference graph
Works this paper leans on
-
[1]
Personalized news recommendation: Methods and challenges.ACM Transactions on Information Systems, 41(1):1–50, 2023
Chuhan Wu, Fangzhao Wu, Yongfeng Huang, and Xing Xie. Personalized news recommendation: Methods and challenges.ACM Transactions on Information Systems, 41(1):1–50, 2023
2023
-
[2]
Analysis of recommendation algorithms for e-commerce
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. Analysis of recommendation algorithms for e-commerce. InProceedings of the 2nd ACM Conference on Electronic Commerce, pages 158–167, 2000
2000
-
[3]
Analyzing user engagement with tiktok’s short format video recommendations using data donations
Savvas Zannettou, Olivia Nemes-Nemeth, Oshrat Ayalon, Angelica Goetzen, Krishna P Gummadi, Elissa M Redmiles, and Franziska Roesner. Analyzing user engagement with tiktok’s short format video recommendations using data donations. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–16, 2024
2024
-
[4]
Item-based collaborative filtering recommen- dation algorithms
Badrul Sarwar, George Karypis, Joseph Konstan, and John Riedl. Item-based collaborative filtering recommen- dation algorithms. InProceedings of the 10th international conference on World Wide Web, pages 285–295, 2001
2001
-
[5]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018
2018
-
[6]
Friendbook: a semantic-based friend recommen- dation system for social networks.IEEE transactions on mobile computing, 14(3):538–551, 2014
Zhibo Wang, Jilong Liao, Qing Cao, Hairong Qi, and Zhi Wang. Friendbook: a semantic-based friend recommen- dation system for social networks.IEEE transactions on mobile computing, 14(3):538–551, 2014
2014
-
[7]
Kuan Zou and Aixin Sun. A survey of real-world recommender systems: Challenges, constraints, and industrial perspectives.arXiv preprint arXiv:2509.06002, 2025
-
[8]
Scenario-wise rec: A multi-scenario recommendation benchmark
Xiaopeng Li, Jingtong Gao, Pengyue Jia, Xiangyu Zhao, Yichao Wang, Wanyu Wang, Yejing Wang, Yuhao Wang, Huifeng Guo, and Ruiming Tang. Scenario-wise rec: A multi-scenario recommendation benchmark. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 1685–1695, 2025
2025
-
[9]
Building a performance model for deep learning recommendation model training on gpus
Zhongyi Lin, Louis Feng, Ehsan K Ardestani, Jaewon Lee, John Lundell, Changkyu Kim, Arun Kejariwal, and John D Owens. Building a performance model for deep learning recommendation model training on gpus. In 2022 IEEE 29th International Conference on High Performance Computing, Data, and Analytics (HiPC), pages 48–58. IEEE, 2022
2022
-
[10]
Wenjie Wang, Xinyu Lin, Fuli Feng, Xiangnan He, and Tat-Seng Chua. Generative recommendation: Towards next-generation recommender paradigm.arXiv preprint arXiv:2304.03516, 2023
-
[11]
Wukong: towards a scaling law for large-scale recommendation
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Shen Li, Yanli Zhao, Yuchen Hao, Yantao Yao, Ellie Dingqiao Wen, et al. Wukong: towards a scaling law for large-scale recommendation. InProceedings of the 41st International Conference on Machine Learning, pages 59421–59434, 2024
2024
-
[12]
Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, et al. Actions speak louder than words: trillion-parameter sequential transducers for generative recommendations. InProceedings of the 41st International Conference on Machine Learning, pages 58484–58509, 2024
2024
-
[13]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20, 2020. 15 TurboGR : An Accelerated Training System for Large-Scale Ge...
2020
-
[14]
Yufei Ye, Wei Guo, Jin Yao Chin, Hao Wang, Hong Zhu, Xi Lin, Yuyang Ye, Yong Liu, Ruiming Tang, Defu Lian, et al. Fuxi-alpha: Scaling recommendation model with feature interaction enhanced transformer.arXiv preprint arXiv:2502.03036, 2025
-
[15]
Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness.Advances in neural information processing systems, 35:16344–16359, 2022
2022
-
[16]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Dmytro Ivchenko, D. V . Staay, Colin Taylor, Xing Liu, Will Feng, Rahul Kindi, Anirudh Sudarshan, and S. Sefati. Torchrec: a pytorch domain library for recommendation systems.Proceedings of the 16th ACM Conference on Recommender Systems, 2022
2022
-
[18]
Xin Zhang, Quanyu Zhu, Liangbei Xu, Zain Huda, Wang Zhou, Jin Fang, Dennis van der Staay, Yuxi Hu, Jade Nie, Jiyan Yang, et al. Two-dimensional sparse parallelism for large scale deep learning recommendation model training.arXiv preprint arXiv:2508.03854, 2025
-
[19]
Dezhi Yi, Wei Guo, Wenyang Cui, Wenxuan He, Huifeng Guo, Yong Liu, Zhenhua Dong, and Ye Lu. Fuxi- \gamma: Efficient sequential recommendation with exponential-power temporal encoder and diagonal-sparse positional mechanism.arXiv preprint arXiv:2512.12740, 2025. 16 TurboGR : An Accelerated Training System for Large-Scale Generative Recommendation A Experim...
-
[20]
The backward pass of batchi’s dense model to overlap with the forward pass of batch (i+1)’s sparse model
-
[21]
D 6-Batch Pipelined Overlapping Execution In this appendix we present the algorithm of the fine-grained pipeline orchestration
The forward pass of batch (i+ 2) ’s dense model to overlap with the backward pass of batch(i+ 1) ’s sparse model. D 6-Batch Pipelined Overlapping Execution In this appendix we present the algorithm of the fine-grained pipeline orchestration. Note that throughout training, cross-device transfers (host-to-device and device-to-host) introduce mandatory synch...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.