Pretraining Language Models with Subword Regularization: An Empirical Study of BPE Dropout in Low-Resource NLP
Pith reviewed 2026-05-14 19:25 UTC · model grok-4.3
The pith
Stochastic tokenization during both pretraining and fine-tuning yields the best results in low-resource NLP tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
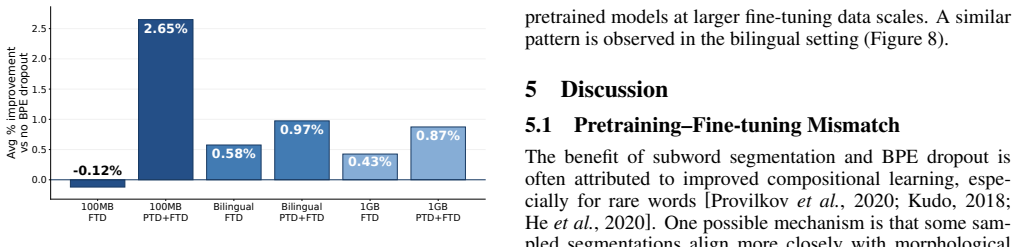
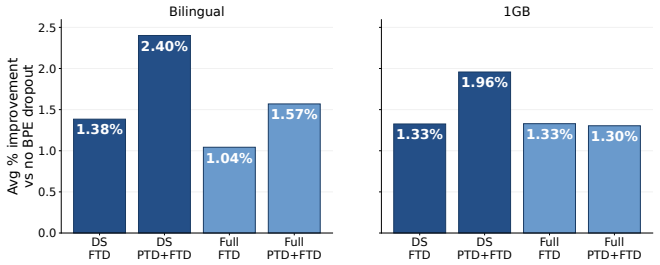
Across the evaluated tasks, the highest performance is achieved when BPE dropout is used during both pretraining and fine-tuning of monolingual and bilingual BERT models. Applying it only during fine-tuning can lead to lower results than deterministic tokenization in smaller-data regimes, with the disadvantage decreasing as fine-tuning data grows. The benefits of pretraining with BPE dropout are largest under data scarcity, and while morphological alignment improves modestly, the consistent exposure during pretraining appears key to the gains.
What carries the argument
BPE dropout as stochastic subword regularization that varies tokenizations by randomly dropping merges, applied during pretraining to reduce segmentation mismatch with fine-tuning.
If this is right
- Using stochastic tokenization in both pretraining and fine-tuning gives the best downstream performance across tasks.
- Applying BPE dropout only during fine-tuning can underperform fully deterministic tokenization when data is scarce.
- The performance gap from fine-tuning-only dropout shrinks as the amount of fine-tuning data increases.
- Pretraining with BPE dropout provides the largest benefits when either pretraining or fine-tuning data is limited.
- Selectively adding morphologically aligned segmentations during fine-tuning helps most for models pretrained deterministically.
Where Pith is reading between the lines
- Standard practice for low-resource models may shift toward stochastic pretraining to avoid tokenization mismatch.
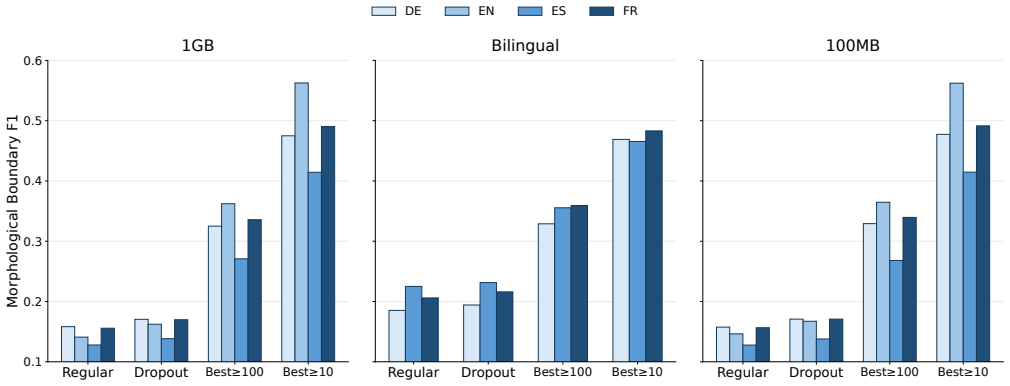
- The modest alignment gains suggest that other mechanisms, such as increased robustness to segmentation, may also play a role.
- Similar regularization during pretraining could benefit other subword methods or even cross-lingual transfer setups.
- Testing on a wider range of truly indigenous low-resource languages would strengthen the generalization of these findings.
Load-bearing premise
That the performance benefits are primarily due to exposure to better-aligned segmentations from stochastic pretraining, and that the downsampled datasets adequately proxy real low-resource conditions.
What would settle it
An experiment showing no performance difference on native low-resource language data when using pretraining BPE dropout versus deterministic, or finding equivalent gains from fine-tuning exposure alone without pretraining stochasticity.
Figures



read the original abstract
Subword regularization methods such as BPE dropout are typically applied only during fine-tuning, while pretraining is usually done with deterministic tokenization. This creates a potential segmentation mismatch between pretraining and fine-tuning. We investigate whether applying BPE dropout during pretraining improves downstream performance in low-resource NLP. We train monolingual and bilingual BERT models on downsampled subsets of English, German, French, Spanish, Kiswahili, and isiXhosa, and evaluate them on XNLI, PAWS-X, PAN-X, and MasakhaNER 2.0. Across tasks, the best results are typically obtained when stochastic tokenization is applied during both pretraining and fine-tuning, whereas applying BPE dropout only during fine-tuning can underperform deterministic tokenization in smaller-data settings. This disadvantage diminishes as fine-tuning data increases, while the benefits of pretraining-time BPE dropout are largest when either pretraining or fine-tuning data is scarce. The benefits of BPE dropout are often attributed to better compositional representations, especially for rare words. To examine this, we measure morphological boundary alignment under BPE dropout and find only modest improvements in expected alignment, while better-aligned segmentations remain rare. This suggests that fine-tuning alone may provide limited exposure to such segmentations, whereas stochastic tokenization during pretraining exposes the model to them more consistently. We further show that selectively introducing morphologically aligned segmentations during fine-tuning improves performance mainly for models pretrained without BPE dropout. Overall, these findings suggest that exposure to better-aligned segmentations may contribute to the downstream benefits of applying BPE dropout during pretraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical study on applying BPE dropout during pretraining of BERT models for low-resource NLP. It trains monolingual and bilingual models on downsampled subsets of English, German, French, Spanish, Kiswahili, and isiXhosa, evaluating on XNLI, PAWS-X, PAN-X, and MasakhaNER 2.0. The central claim is that stochastic tokenization during both pretraining and fine-tuning typically yields the best results, while BPE dropout only at fine-tuning can underperform deterministic tokenization in smaller-data settings; benefits are largest when pretraining or fine-tuning data is scarce. The paper also measures morphological boundary alignment, reporting only modest improvements, and suggests that pretraining exposure to varied segmentations contributes to gains.
Significance. If the results hold, the work provides actionable guidance on consistent subword regularization for low-resource pretraining, with the multi-language and multi-task design lending some robustness. The analysis of morphological alignment offers a partial mechanistic probe, though the modest scale of alignment gains limits its explanatory power.
major comments (2)
- [Abstract] Abstract and experimental setup: the central claim that joint pretraining/fine-tuning dropout outperforms other regimes rests on downsampled high-resource languages (plus Kiswahili/isiXhosa) as proxies for low-resource conditions; downsampling preserves high-resource morphological simplicity, vocabulary coverage, and distributions that differ from native low-resource corpora, weakening attribution of benefits specifically to pretraining-time exposure.
- [Results] Results presentation: performance comparisons across tasks and data regimes report no error bars, statistical tests, or full hyperparameter schedules, leaving open the possibility that observed advantages reflect selection effects rather than reliable patterns.
minor comments (1)
- [Abstract] The abstract states that 'selectively introducing morphologically aligned segmentations during fine-tuning improves performance mainly for models pretrained without BPE dropout' but provides no quantitative breakdown of the size of this improvement or its interaction with data size.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, acknowledging valid concerns while defending the core experimental design where it is supported by the manuscript's inclusion of native low-resource languages and controlled data-size variation.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental setup: the central claim that joint pretraining/fine-tuning dropout outperforms other regimes rests on downsampled high-resource languages (plus Kiswahili/isiXhosa) as proxies for low-resource conditions; downsampling preserves high-resource morphological simplicity, vocabulary coverage, and distributions that differ from native low-resource corpora, weakening attribution of benefits specifically to pretraining-time exposure.
Authors: We agree that downsampling high-resource languages is an imperfect proxy and does not fully replicate the morphological complexity or vocabulary distributions of native low-resource corpora. However, the study also includes two genuinely low-resource languages (Kiswahili and isiXhosa) that are not derived from downsampling, providing direct evidence on authentic low-resource data. The downsampling design was chosen specifically to enable controlled isolation of data-size effects while holding language family and domain relatively constant. In revision we will add an explicit limitations paragraph discussing the proxy limitations and will emphasize the results on the two native low-resource languages as the strongest support for the claims. revision: partial
-
Referee: [Results] Results presentation: performance comparisons across tasks and data regimes report no error bars, statistical tests, or full hyperparameter schedules, leaving open the possibility that observed advantages reflect selection effects rather than reliable patterns.
Authors: We acknowledge the absence of error bars, statistical tests, and complete hyperparameter reporting as a genuine weakness that reduces confidence in the reliability of the observed patterns. In the revised manuscript we will (1) report standard deviations from at least three random seeds for the main pretraining and fine-tuning comparisons, (2) add paired statistical tests for key contrasts, and (3) include a supplementary table or section summarizing the full hyperparameter grid and final selected values. Because of the high computational cost of pretraining, we cannot rerun every condition with additional seeds, but we will clearly flag this limitation and focus variance reporting on the most critical settings. revision: yes
Circularity Check
No circularity: purely empirical comparisons with external benchmarks
full rationale
The paper conducts direct experimental training of monolingual and bilingual BERT models on downsampled corpora and evaluates them on standard tasks (XNLI, PAWS-X, PAN-X, MasakhaNER). No equations, fitted parameters, or predictions are defined in terms of the target outcomes. Claims rest on observed performance differences across tokenization regimes, with no self-definitional loops, fitted-input predictions, or load-bearing self-citations that reduce the central result to its own inputs. The derivation chain is self-contained against external data splits and metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard BERT masked language modeling and next-sentence prediction objectives produce useful representations for the evaluated tasks
Reference graph
Works this paper leans on
-
[1]
[Adelaniet al., 2022 ] David Ifeoluwa Adelani, Graham Neubig, Sebastian Ruder, Shruti Rijhwani, Michael Beuk- man, Chester Palen-Michel, Constantine Lignos, Je- sujoba O. Alabi, Shamsuddeen H. Muhammad, Peter Nabende, Cheikh M. Bamba Dione, Andiswa Bukula, Rooweither Mabuya, Bonaventure F. P. Dossou, Bless- ing Sibanda, Happy Buzaaba, Jonathan Mukiibi, Go...
work page 2022
-
[2]
[Arnett and Bergen, 2025] Catherine Arnett and Ben- jamin K
Association for Computational Linguistics. [Arnett and Bergen, 2025] Catherine Arnett and Ben- jamin K. Bergen. Why do language models perform worse for morphologically complex languages? In Proceedings of the 31st International Conference on Computational Linguistics, pages 6607–6623. Associa- tion for Computational Linguistics, jan
work page 2025
-
[3]
Morphynet: A large multilin- gual database of derivational and inflectional morphol- ogy
[Batsurenet al., 2021 ] Khuyagbaatar Batsuren, G´abor Bella, and Fausto Giunchiglia. Morphynet: A large multilin- gual database of derivational and inflectional morphol- ogy. InProceedings of the 18th SIGMORPHON Workshop on Computational Research in Phonetics, Phonology, and Morphology, pages 39–48. Association for Computational Linguistics,
work page 2021
-
[4]
[Bauwens and Delobelle, 2024] Thomas Bauwens and Pieter Delobelle. BPE-knockout: Pruning pre-existing BPE tokenisers with backwards-compatible morpho- logical semi-supervision. InProceedings of the 2024 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 58...
work page 2024
-
[5]
[Cognettaet al., 2024 ] Marco Cognetta, Vil ´em Zouhar, and Naoaki Okazaki
Association for Computational Linguistics. [Cognettaet al., 2024 ] Marco Cognetta, Vil ´em Zouhar, and Naoaki Okazaki. Distributional properties of subword regularization. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Confer- ence on Empirical Methods in Natural Language Process- ing, pages 10753–10763, Miami, Flori...
work page 2024
-
[6]
[Conneauet al., 2018 ] Alexis Conneau, Ruty Rinott, Guil- laume Lample, Adina Williams, Samuel R
Association for Computational Linguistics. [Conneauet al., 2018 ] Alexis Conneau, Ruty Rinott, Guil- laume Lample, Adina Williams, Samuel R. Bowman, Hol- ger Schwenk, and Veselin Stoyanov. Xnli: Evaluating cross-lingual sentence representations. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Association for Compu...
work page 2018
-
[7]
BERT: Pre-training of deep bidirectional transformers for language understand- ing
[Devlinet al., 2019 ] Jacob Devlin, Ming-Wei Chang, Ken- ton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understand- ing. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human L...
work page 2019
-
[8]
[Edunovet al., 2018 ] Sergey Edunov, Myle Ott, Michael Auli, and David Grangier
Association for Computational Linguistics. [Edunovet al., 2018 ] Sergey Edunov, Myle Ott, Michael Auli, and David Grangier. Understanding back-translation at scale. In Ellen Riloff, David Chiang, Julia Hocken- maier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 489–500, Brussels...
work page 2018
-
[9]
Association for Computational Linguis- tics. [Fenget al., 2021 ] Steven Y . Feng, Varun Gangal, Jason Wei, Sarath Chandar, Soroush V osoughi, Teruko Mita- mura, and Eduard Hovy. A survey of data augmenta- tion approaches for NLP. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors,Findings of the Association for Computational Linguistics: ...
work page 2021
-
[10]
[Heet al., 2020 ] Xuanli He, Gholamreza Haffari, and Mo- hammad Norouzi
Association for Computational Linguistics. [Heet al., 2020 ] Xuanli He, Gholamreza Haffari, and Mo- hammad Norouzi. Dynamic programming encoding for subword segmentation in neural machine translation. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Lingu...
work page 2020
-
[11]
Association for Compu- tational Linguistics. [Huet al., 2020a ] Junjie Hu, Sebastian Ruder, Aditya Sid- dhant, Graham Neubig, Orhan Firat, and Melvin John- son. Xtreme: A massively multilingual multi-task bench- mark for evaluating cross-lingual generalization.CoRR, abs/2003.11080,
-
[12]
False Friends are not foes: Investigating vocabulary overlap in multilingual lan- guage models
[Kalliniet al., 2025 ] Julie Kallini, Dan Jurafsky, Christo- pher Potts, and Martijn Bartelds. False Friends are not foes: Investigating vocabulary overlap in multilingual lan- guage models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguis- tics: EMNLP 2025, p...
work page 2025
-
[13]
[Kreutzer and Sokolov, 2018] Julia Kreutzer and Artem Sokolov
Association for Computational Linguis- tics. [Kreutzer and Sokolov, 2018] Julia Kreutzer and Artem Sokolov. Learning to segment inputs for nmt favors character-level processing. InProceedings of the 15th In- ternational Conference on Spoken Language Translation, pages 166–172,
work page 2018
-
[14]
[Kudo, 2018] Taku Kudo. Subword regularization: Improv- ing neural network translation models with multiple sub- word candidates. In Iryna Gurevych and Yusuke Miyao, editors,Proceedings of the 56th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 66–75, Melbourne, Australia, July
work page 2018
-
[15]
Association for Computational Linguistics. [Lecunet al., 1998 ] Y . Lecun, L. Bottou, Y . Bengio, and P. Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324,
work page 1998
-
[16]
[Leeet al., 2017 ] Jason Lee, Kyunghyun Cho, and Thomas Hofmann. Fully character-level neural machine translation without explicit segmentation.Transactions of the Associ- ation for Computational Linguistics, 5:365–378,
work page 2017
-
[17]
[Meyer and Buys, 2023] Francois Meyer and Jan Buys. Sub- word segmental machine translation: Unifying seg- mentation and target sentence generation.ArXiv, abs/2305.07005,
-
[18]
A systematic analysis of subwords and cross-lingual transfer in multilingual translation
[Meyer and Buys, 2024] Francois Meyer and Jan Buys. A systematic analysis of subwords and cross-lingual transfer in multilingual translation. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Findings of the Association for Computational Linguistics: NAACL 2024, pages 2194– 2200, Mexico City, Mexico, June
work page 2024
-
[19]
Association for Computational Linguistics. [Mroczkowskiet al., 2021 ] Robert Mroczkowski, Piotr Ry- bak, Alina Wr ´oblewska, and Ireneusz Gawlik. HerBERT: Efficiently pretrained transformer-based language model for Polish. In Bogdan Babych, Olga Kanishcheva, Preslav Nakov, Jakub Piskorski, Lidia Pivovarova, Vasyl Starko, Josef Steinberger, Roman Yangarber...
work page 2021
-
[20]
[Poelmanet al., 2025 ] Wessel Poelman, Thomas Bauwens, and Miryam de Lhoneux
Association for Computational Linguistics. [Poelmanet al., 2025 ] Wessel Poelman, Thomas Bauwens, and Miryam de Lhoneux. Confounding factors in re- lating model performance to morphology. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language ...
work page 2025
-
[21]
[Provilkovet al., 2020 ] Ivan Provilkov, Dmitrii Emelia- nenko, and Elena V oita
Association for Computational Linguistics. [Provilkovet al., 2020 ] Ivan Provilkov, Dmitrii Emelia- nenko, and Elena V oita. BPE-dropout: Simple and effec- tive subword regularization. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Compu- tational Linguistics, pages ...
work page 2020
-
[22]
[Sennrichet al., 2016 ] Rico Sennrich, Barry Haddow, and Alexandra Birch
Association for Computational Linguistics. [Sennrichet al., 2016 ] Rico Sennrich, Barry Haddow, and Alexandra Birch. Improving neural machine translation models with monolingual data. In Katrin Erk and Noah A. Smith, editors,Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 86–96, Berlin...
work page 2016
-
[23]
[Shahamet al., 2023 ] Uri Shaham, Maha Elbayad, Vedanuj Goswami, Omer Levy, and Shruti Bhosale
Association for Computational Linguistics. [Shahamet al., 2023 ] Uri Shaham, Maha Elbayad, Vedanuj Goswami, Omer Levy, and Shruti Bhosale. Causes and cures for interference in multilingual translation. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki, edi- tors,Proceedings of the 61st Annual Meeting of the As- sociation for Computational Linguistics...
work page 2023
-
[24]
[Shorten and Khoshgoftaar, 2019] Connor Shorten and Taghi M
Association for Computational Linguistics. [Shorten and Khoshgoftaar, 2019] Connor Shorten and Taghi M. Khoshgoftaar. A survey on image data augmen- tation for deep learning.Journal of Big Data, 6:1–48,
work page 2019
-
[25]
Simard, Dave Steinkraus, and John C
[Simardet al., 2003 ] Patrice Y . Simard, Dave Steinkraus, and John C. Platt. Best practices for convolutional neural networks applied to visual document analysis. InProceed- ings of the Seventh International Conference on Document Analysis and Recognition - Volume 2, ICDAR ’03, page 958, USA,
work page 2003
-
[26]
IEEE Computer Society. [Songet al., 2024 ] Haiyue Song, Francois Meyer, Raj Dabre, Hideki Tanaka, Chenhui Chu, and Sadao Kuro- hashi. SubMerge: Merging equivalent subword tok- enizations for subword regularized models in neural ma- chine translation. In Carolina Scarton, Charlotte Prescott, Chris Bayliss, Chris Oakley, Joanna Wright, Stuart Wrigley, Xingy...
work page 2024
-
[27]
[Visseret al., 2025 ] Ruan Visser, Trienko Grobler, and Mar- cel Dunaiski
European Association for Machine Translation (EAMT). [Visseret al., 2025 ] Ruan Visser, Trienko Grobler, and Mar- cel Dunaiski. Scaling behavior of encoder language mod- els in low-resource settings. InArtificial Intelligence Re- search, volume 2784 ofCommunications in Computer and Information Science, pages 349–367. Springer,
work page 2025
-
[28]
Multi-view subword regularization
[Wanget al., 2021 ] Xinyi Wang, Sebastian Ruder, and Gra- ham Neubig. Multi-view subword regularization. InNorth American Chapter of the Association for Computational Linguistics,
work page 2021
-
[29]
EDA: Easy data augmentation techniques for boosting performance on text classification tasks
[Wei and Zou, 2019] Jason Wei and Kai Zou. EDA: Easy data augmentation techniques for boosting performance on text classification tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Lan- guage Processing and the 9th International Joint Confer- ence on Natural Language ...
work page 2019
-
[30]
[Williamset al., 2018 ] Adina Williams, Nikita Nangia, and Samuel R
Association for Computational Linguistics. [Williamset al., 2018 ] Adina Williams, Nikita Nangia, and Samuel R. Bowman. A broad-coverage challenge cor- pus for sentence understanding through inference. InPro- ceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume ...
work page 2018
-
[31]
Data Noising as Smoothing in Neural Network Language Models
Association for Computational Linguistics. [Xieet al., 2017 ] Ziang Xie, Sida I. Wang, Jiwei Li, Daniel L´evy, Allen Nie, Dan Jurafsky, and A. Ng. Data noising as smoothing in neural network language models.ArXiv, abs/1703.02573,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
[Xueet al., 2022 ] Linting Xue, Aditya Barua, Noah Con- stant, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Mono- jit Choudhury, and Adam Roberts. Byt5: Towards a token- free future with pre-trained byte-to-byte models.Trans- actions of the Association for Computational Linguistics, 10:291–306,
work page 2022
-
[33]
PAWS-X: A cross-lingual adversarial dataset for paraphrase identification
[Yanget al., 2019 ] Yinfei Yang, Yuan Zhang, Chris Tar, and Jason Baldridge. PAWS-X: A cross-lingual adversarial dataset for paraphrase identification. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natu- ral Language Processing and the 9th International Joint Conference on Natu...
work page 2019
-
[34]
[Zhanget al., 2019 ] Yuan Zhang, Jason Baldridge, and Luheng He
Association for Computational Linguistics. [Zhanget al., 2019 ] Yuan Zhang, Jason Baldridge, and Luheng He. Paws: Paraphrase adversaries from word scrambling. InProceedings of the 2019 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technologies, Vol- ume 1 (Long and Short Papers), pages 1298–130...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.