Recognition: unknown
Z-Order Transformer for Feed-Forward Gaussian Splatting
Pith reviewed 2026-05-14 20:27 UTC · model grok-4.3
The pith
A Z-order transformer predicts 3D Gaussian attributes directly from images in one pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
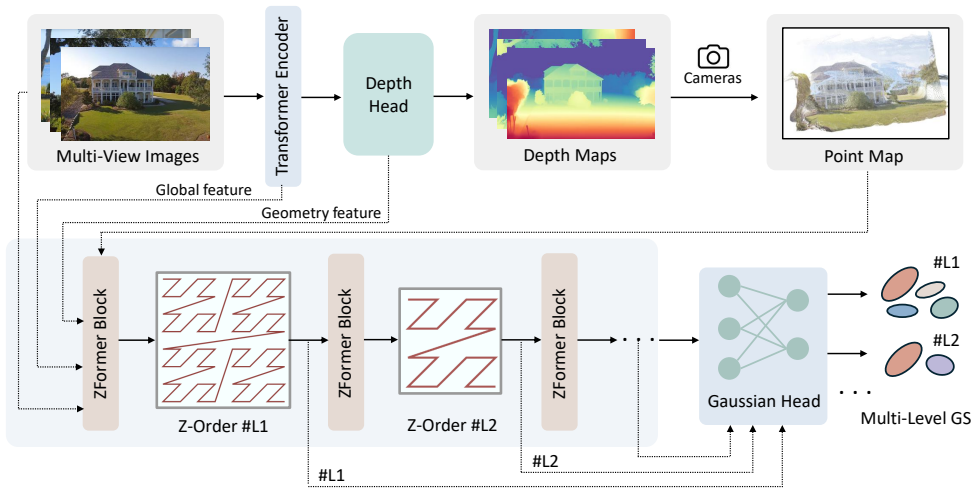
By sorting Gaussians along a Z-order curve to form a spatially coherent sequence, the transformer applies sparse attention to model context among them, adaptively suppresses redundancy while preserving key details, and predicts all Gaussian attributes in a single forward pass, yielding fast high-quality novel view synthesis with fewer primitives than iterative baselines.
What carries the argument
Z-order strategy that converts an unstructured set of Gaussians into a spatially coherent sequence to support sparse attention inside the transformer.
If this is right
- Novel view synthesis completes in a single network pass without per-scene optimization.
- Fewer Gaussian primitives are required while visual fidelity stays high.
- Rendering speed increases because the model avoids iterative refinement.
- The same ordering mechanism can be reused to compress other point-based scene representations.
Where Pith is reading between the lines
- The Z-order sequencing could be applied to dynamic scenes by updating the order frame by frame.
- Memory footprint for stored scenes may drop because redundant primitives are removed before rendering.
- The approach might combine with video encoders to handle streaming 3D content more efficiently.
Load-bearing premise
Ordering Gaussians by Z-order produces sequences in which nearby elements share enough spatial and semantic structure for sparse attention to suppress redundancy without losing important scene details.
What would settle it
On standard benchmarks such as Mip-NeRF 360 or Tanks and Temples, the method produces lower PSNR or SSIM than iterative 3DGS when both are allowed the same small number of primitives.
Figures






read the original abstract
Recent advances in 3D Gaussian Splatting (3DGS) have enabled significant progress in photorealistic novel view synthesis. However, traditional 3DGS relies on a slow, iterative optimization process, which limits its use in scenarios demanding real-time results. To overcome this bottleneck, recent feed-forward methods aim to predict Gaussian attributes directly from images, but they often struggle with the redundancy of Gaussian primitives and rendering quality. In this work, we introduce a transformer-based architecture specifically designed for feed-forward Gaussian Splatting. Our key insight is that spatial and semantic relationships among Gaussians can be effectively captured through a sparse attention mechanism, enabled by a Z-order strategy that organizes the unstructured Gaussian set into a spatially coherent sequence. Furthermore, we incorporate this Z-order strategy to adaptively suppress redundancy while preserving critical structural details. This allows the transformer to efficiently model context, compress Gaussian primitives, and predict Gaussian attributes in a single forward pass. Comprehensive experiments demonstrate that our method achieves fast and high-quality novel view synthesis with fewer Gaussian primitives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Z-Order Transformer, a transformer architecture for feed-forward 3D Gaussian Splatting. Gaussians are organized via a Z-order curve into a spatially coherent sequence that enables sparse attention to model relationships among primitives; this is used to adaptively suppress redundancy while predicting attributes directly from input images in one forward pass. The central claim is that the approach yields fast, high-quality novel view synthesis with substantially fewer Gaussian primitives than prior feed-forward methods, backed by comprehensive experiments.
Significance. If the quantitative gains hold, the work provides a practical advance for real-time 3D reconstruction by replacing iterative optimization with a single-pass transformer that exploits spatial locality via Z-order sorting. The technique of using space-filling curves to structure unstructured point sets for efficient attention is a targeted adaptation that could transfer to other sparse 3D tasks. The paper's inclusion of ablation studies and baseline comparisons is a strength that supports evaluation of the redundancy-suppression claim.
major comments (2)
- [§3.2] §3.2, Eq. (3): the Z-order mapping from 3D coordinates to sequence indices is defined via bit-interleaving, but the manuscript does not analyze or bound the locality preservation error for non-uniform Gaussian distributions; this directly affects whether the sparse attention can reliably capture semantic relationships without additional mechanisms.
- [Table 2] Table 2, 'Ours vs. baseline' row: the reported 25% reduction in primitive count is accompanied by a 0.4 dB PSNR drop on the Mip-NeRF 360 dataset, yet the baseline is a generic feed-forward GS model rather than the strongest recent competitor; this weakens the claim that the Z-order strategy uniquely enables fewer primitives at comparable quality.
minor comments (3)
- [§2] The related-work section omits several 2024 feed-forward GS papers that also target primitive reduction; adding them would better situate the novelty of the Z-order component.
- [Figure 5] Figure 5: the attention-map visualizations lack scale bars or quantitative metrics (e.g., sparsity ratio), making it hard to verify the 'sparse' claim visually.
- [§3.1] Notation in §3.1 for Gaussian covariance and opacity is inconsistent with the rendering equation in §3.3; a single symbol table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation. We address the major comments point by point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2, Eq. (3): the Z-order mapping from 3D coordinates to sequence indices is defined via bit-interleaving, but the manuscript does not analyze or bound the locality preservation error for non-uniform Gaussian distributions; this directly affects whether the sparse attention can reliably capture semantic relationships without additional mechanisms.
Authors: We acknowledge that the manuscript does not include a formal bound or analysis of locality preservation error specifically for non-uniform Gaussian distributions. Z-order curves via bit-interleaving are a standard technique for preserving spatial locality in point sets, and our ablations demonstrate that the resulting sparse attention effectively captures relationships in practice. To address the referee's concern directly, we will add an empirical analysis of locality error (including quantitative measures on the Mip-NeRF 360 dataset) and a brief discussion of worst-case bounds for non-uniform distributions in the revised §3.2. revision: yes
-
Referee: [Table 2] Table 2, 'Ours vs. baseline' row: the reported 25% reduction in primitive count is accompanied by a 0.4 dB PSNR drop on the Mip-NeRF 360 dataset, yet the baseline is a generic feed-forward GS model rather than the strongest recent competitor; this weakens the claim that the Z-order strategy uniquely enables fewer primitives at comparable quality.
Authors: We agree that using only a generic feed-forward baseline in Table 2 limits the strength of the comparison. The manuscript does include results against additional recent feed-forward methods in the main text and supplementary material, where the primitive reduction remains consistent with competitive quality. The observed 0.4 dB PSNR trade-off is presented as acceptable given the efficiency gains. In revision we will expand Table 2 to include the strongest recent competitor and explicitly discuss how the Z-order approach contributes to the observed compression. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents a transformer architecture augmented by Z-order sorting to organize unstructured Gaussians into a coherent sequence for sparse attention and redundancy suppression. No equations, derivations, or parameter-fitting steps are described that reduce the central claims (fast high-quality novel view synthesis with fewer primitives) to self-definitional inputs or fitted quantities by construction. The approach is positioned as a new architecture whose validity rests on experimental results rather than any self-referential loop or load-bearing self-citation chain. This is a standard case of an independent architectural proposal with no detectable circularity in the provided derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Transformer attention mechanisms can model spatial relationships when inputs are suitably ordered
invented entities (1)
-
Z-order strategy for Gaussian organization
no independent evidence
Reference graph
Works this paper leans on
-
[1]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024. 1, 2, 11
2024
-
[2]
Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images
Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, and Jianfei Cai. Mvsplat: Efficient 3d gaussian splatting from sparse multi-view images. InEuropean Conference on Computer Vision, pages 370–386. Springer, 2024. 1, 2, 11
2024
-
[3]
Gaussianpro: 3d gaussian splatting with progressive propagation
Kai Cheng, Xiaoxiao Long, Kaizhi Yang, Yao Yao, Wei Yin, Yuexin Ma, Wenping Wang, and Xuejin Chen. Gaussianpro: 3d gaussian splatting with progressive propagation. InForty- first International Conference on Machine Learning, 2024. 2
2024
-
[4]
Fast construction of k-nearest neighbor graphs for point clouds.IEEE transac- tions on visualization and computer graphics, 16(4):599– 608, 2010
Michael Connor and Piyush Kumar. Fast construction of k-nearest neighbor graphs for point clouds.IEEE transac- tions on visualization and computer graphics, 16(4):599– 608, 2010. 3
2010
-
[5]
Nerf is a valuable assistant for 3d gaussian splatting
Shuangkang Fang, I Shen, Takeo Igarashi, Yufeng Wang, ZeSheng Wang, Yi Yang, Wenrui Ding, Shuchang Zhou, et al. Nerf is a valuable assistant for 3d gaussian splatting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 26230–26240, 2025. 13
2025
-
[6]
Flashgs: Efficient 3d gaussian splatting for large-scale and high-resolution rendering
Guofeng Feng, Siyan Chen, Rong Fu, Zimu Liao, Yi Wang, Tao Liu, Boni Hu, Linning Xu, Zhilin Pei, Hengjie Li, et al. Flashgs: Efficient 3d gaussian splatting for large-scale and high-resolution rendering. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26652– 26662, 2025. 2
2025
-
[7]
Memory-efficient transformers via top-k attention
Ankit Gupta, Guy Dar, Shaya Goodman, David Ciprut, and Jonathan Berant. Memory-efficient transformers via top-k attention. InProceedings of the Second Workshop on Sim- ple and Efficient Natural Language Processing, pages 39– 52, 2021. 5
2021
-
[8]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. Anysplat: Feed-forward 3d gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716,
-
[9]
1, 2, 3, 6, 7, 8, 11
-
[10]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139–1,
-
[11]
Rogsplat: Robust gaussian splatting via generative priors
Hanyang Kong, Xingyi Yang, and Xinchao Wang. Rogsplat: Robust gaussian splatting via generative priors. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 25735–25745, 2025. 2
2025
-
[12]
Z-sky: an efficient skyline query processing framework based on z-order.The VLDB Journal, 19(3):333– 362, 2010
Ken CK Lee, Wang-Chien Lee, Baihua Zheng, Huajing Li, and Yuan Tian. Z-sky: an efficient skyline query processing framework based on z-order.The VLDB Journal, 19(3):333– 362, 2010. 3
2010
-
[13]
3d-hgs: 3d half-gaussian splatting
Haolin Li, Jinyang Liu, Mario Sznaier, and Octavia Camps. 3d-hgs: 3d half-gaussian splatting. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10996–11005, 2025. 2
2025
-
[14]
Pointmamba: A simple state space model for point cloud analysis.Advances in neural information processing systems, 37:32653–32677,
Dingkang Liang, Xin Zhou, Wei Xu, Xingkui Zhu, Zhikang Zou, Xiaoqing Ye, Xiao Tan, and Xiang Bai. Pointmamba: A simple state space model for point cloud analysis.Advances in neural information processing systems, 37:32653–32677,
-
[15]
Hybridgs: Decou- pling transients and statics with 2d and 3d gaussian splatting
Jingyu Lin, Jiaqi Gu, Lubin Fan, Bojian Wu, Yujing Lou, Renjie Chen, Ligang Liu, and Jieping Ye. Hybridgs: Decou- pling transients and statics with 2d and 3d gaussian splatting. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 788–797, 2025. 13
2025
-
[16]
Visualization of large terrains made easy
Peter Lindstrom and Valerio Pascucci. Visualization of large terrains made easy. InProceedings Visualization, 2001. VIS’01., pages 363–574. IEEE, 2001. 3
2001
-
[17]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. 6
2024
-
[18]
Infinite na- ture: Perpetual view generation of natural scenes from a sin- gle image
Andrew Liu, Richard Tucker, Varun Jampani, Ameesh Makadia, Noah Snavely, and Angjoo Kanazawa. Infinite na- ture: Perpetual view generation of natural scenes from a sin- gle image. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14458–14467, 2021. 6
2021
-
[19]
4dgs-craft: Consistent and interactive 4d gaussian splat- ting editing.IEEE Transactions on Circuits and Systems for Video Technology, 2026
Lei Liu, Can Wang, Zhenghao Chen, Zhenhua Liu, and Dong Xu. 4dgs-craft: Consistent and interactive 4d gaussian splat- ting editing.IEEE Transactions on Circuits and Systems for Video Technology, 2026. 1
2026
-
[20]
Monosplat: Generalizable 3d gaussian splat- ting from monocular depth foundation models
Yifan Liu, Keyu Fan, Weihao Yu, Chenxin Li, Hao Lu, and Yixuan Yuan. Monosplat: Generalizable 3d gaussian splat- ting from monocular depth foundation models. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 21570–21579, 2025. 1, 2, 11
2025
-
[21]
Decoupled weight de- cay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight de- cay regularization. InInternational Conference on Learning Representations, 2017. 6
2017
-
[22]
International Business Machines Company, 1966
Guy M Morton.A computer oriented geodetic data base and a new technique in file sequencing. International Business Machines Company, 1966. 2, 3, 4
1966
-
[23]
Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022
Thomas M ¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a mul- tiresolution hash encoding.ACM transactions on graphics (TOG), 41(4):1–15, 2022. 13
2022
-
[24]
Dinov2: Learning robust visual features without super- vision.Transactions on Machine Learning Research, 2025
Maxime Oquab, Timoth ´ee Darcet, Th´eo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without super- vision.Transactions on Machine Learning Research, 2025. 4, 12
2025
-
[25]
Spatial query processing in an object- oriented database system
Jack A Orenstein. Spatial query processing in an object- oriented database system. InProceedings of the 1986 ACM SIGMOD international conference on Management of data, pages 326–336, 1986. 3
1986
-
[26]
Redundancy in spatial databases.ACM SIGMOD Record, 18(2):295–305, 1989
Jack A Orenstein. Redundancy in spatial databases.ACM SIGMOD Record, 18(2):295–305, 1989. 3
1989
-
[27]
Vi- sion transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vi- sion transformers for dense prediction. InProceedings of the IEEE/CVF international conference on computer vision, pages 12179–12188, 2021. 4, 12
2021
-
[28]
Scube: Instant large-scale scene reconstruction us- ing voxsplats.Advances in Neural Information Processing Systems, 37:97670–97698, 2024
Xuanchi Ren, Yifan Lu, Hanxue Liang, Zhangjie Wu, Huan Ling, Mike Chen, Sanja Fidler, Francis Williams, and Jiahui Huang. Scube: Instant large-scale scene reconstruction us- ing voxsplats.Advances in Neural Information Processing Systems, 37:97670–97698, 2024. 2, 3
2024
-
[29]
Flashattention-3: Fast and accurate attention with asynchrony and low-precision
Jay Shah, Ganesh Bikshandi, Ying Zhang, Vijay Thakkar, Pradeep Ramani, and Tri Dao. Flashattention-3: Fast and accurate attention with asynchrony and low-precision. Advances in Neural Information Processing Systems, 37: 68658–68685, 2024. 6
2024
-
[30]
Ambient occlusion and edge cueing for enhancing real time molecular visualization.IEEE transactions on visualization and com- puter graphics, 12(5):1237–1244, 2006
Marco Tarini, Paolo Cignoni, and Claudio Montani. Ambient occlusion and edge cueing for enhancing real time molecular visualization.IEEE transactions on visualization and com- puter graphics, 12(5):1237–1244, 2006. 3
2006
-
[31]
Fast transformers with clustered attention.Advances in Neu- ral Information Processing Systems, 33:21665–21674, 2020
Apoorv Vyas, Angelos Katharopoulos, and Franc ¸ois Fleuret. Fast transformers with clustered attention.Advances in Neu- ral Information Processing Systems, 33:21665–21674, 2020. 5
2020
-
[32]
Vggt: Vi- sual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Vi- sual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025. 6, 12
2025
-
[33]
Octformer: Octree-based transformers for 3d point clouds.ACM Transactions on Graphics (TOG), 42(4):1–11, 2023
Peng-Shuai Wang. Octformer: Octree-based transformers for 3d point clouds.ACM Transactions on Graphics (TOG), 42(4):1–11, 2023. 3
2023
-
[34]
Learning efficient fuse-and-refine for feed- forward 3d gaussian splatting
Yiming Wang, Lucy Chai, Xuan Luo, Michael Niemeyer, Manuel Lagunas, Stephen Lombardi, Siyu Tang, and Tiancheng Sun. Learning efficient fuse-and-refine for feed- forward 3d gaussian splatting. InThe Thirty-ninth An- nual Conference on Neural Information Processing Systems,
-
[35]
Hyrf: Hybrid radiance fields for memory-efficient and high-quality novel view synthesis
Zipeng Wang and Dan Xu. Hyrf: Hybrid radiance fields for memory-efficient and high-quality novel view synthesis. arXiv preprint arXiv:2509.17083, 2025. 13
-
[36]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Si- moncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 6
2004
-
[37]
Point transformer v3: Simpler faster stronger
Xiaoyang Wu, Li Jiang, Peng-Shuai Wang, Zhijian Liu, Xi- hui Liu, Yu Qiao, Wanli Ouyang, Tong He, and Hengshuang Zhao. Point transformer v3: Simpler faster stronger. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4840–4851, 2024. 3, 4
2024
-
[38]
Depthsplat: Connecting gaussian splatting and depth
Haofei Xu, Songyou Peng, Fangjinhua Wang, Hermann Blum, Daniel Barath, Andreas Geiger, and Marc Pollefeys. Depthsplat: Connecting gaussian splatting and depth. In Proceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 16453–16463, 2025. 1, 2, 6, 7, 8, 11
2025
-
[39]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. 5, 12
2024
-
[40]
No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse un- posed images
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no prob- lem: Surprisingly simple 3d gaussian splats from sparse un- posed images. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 2, 11
2025
-
[41]
gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025
Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, et al. gsplat: An open-source library for gaussian splatting.Journal of Machine Learning Research, 26(34):1–17, 2025. 1, 2
2025
-
[42]
Mip-splatting: Alias-free 3d gaussian splat- ting
Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splat- ting. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 19447–19456,
-
[43]
arXiv preprint arXiv:2502.11089 , year=
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, YX Wei, Lean Wang, Zhiping Xiao, et al. Native sparse attention: Hardware- aligned and natively trainable sparse attention.arXiv preprint arXiv:2502.11089, 2025. 5
-
[44]
Zeta: Lever- agingz-order curves for efficient top-kattention
QIUHAO Zeng, Jerry Huang, Peng Lu, Gezheng Xu, Box- ing Chen, Charles Ling, and Boyu Wang. Zeta: Lever- agingz-order curves for efficient top-kattention. InThe Thirteenth International Conference on Learning Represen- tations, 2025. 4
2025
-
[45]
Gaussian in the wild: 3d gaussian splatting for unconstrained image collections
Dongbin Zhang, Chuming Wang, Weitao Wang, Peihao Li, Minghan Qin, and Haoqian Wang. Gaussian in the wild: 3d gaussian splatting for unconstrained image collections. In European Conference on Computer Vision, pages 341–359. Springer, 2024. 2
2024
-
[46]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5, 6
2018
-
[47]
Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views
Shangzhan Zhang, Jianyuan Wang, Yinghao Xu, Nan Xue, Christian Rupprecht, Xiaowei Zhou, Yujun Shen, and Gor- don Wetzstein. Flare: Feed-forward geometry, appearance and camera estimation from uncalibrated sparse views. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21936–21947, 2025. 1, 2, 11
2025
-
[48]
Gps- gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis
Shunyuan Zheng, Boyao Zhou, Ruizhi Shao, Boning Liu, Shengping Zhang, Liqiang Nie, and Yebin Liu. Gps- gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19680–19690, 2024. 1, 2
2024
-
[49]
Generative object insertion in gaussian splatting with a multi-view diffusion model.Visual Informatics, 9(2): 100238, 2025
Hongliang Zhong, Can Wang, Jingbo Zhang, and Jing Liao. Generative object insertion in gaussian splatting with a multi-view diffusion model.Visual Informatics, 9(2): 100238, 2025. 1
2025
-
[50]
Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: learning view synthesis using multiplane images.ACM Transactions on Graphics (TOG), 37(4):1–12, 2018. 6, 11 Supplemental Material
2018
-
[51]
Here, we include the detailed description of this algorithm, as shown in Algorithm 1
Z-order Based Maximum Coverage View- point Selection Algorithm In the main paper, we provide a high-level introduction to the proposed Z-order based Maximum Coverage View- point Selection algorithm. Here, we include the detailed description of this algorithm, as shown in Algorithm 1. The proposed algorithm aims to select at mostMviewpoints from a dense ca...
-
[52]
All methods are trained and evaluated on the RealEstate10K dataset [49] using the same training and test- ing split at a resolution of256×256with 2 input views
More Comparisons with Related Works While our comparison baseline, AnySplat [8], has al- ready been shown to outperform NoPoSplat [39] and FLARE [46], and DepthSplat [37] has been shown to sur- pass MVSplat [2] and PixelSplat [1], we have also in- cluded direct comparisons with these methods, as well as MonoSplat [19], to further validate the effectivenes...
-
[53]
Ours w/o sel
Ablation Studies of Sparse Attention To quantify the contribution of each component in our sparse attention module, we perform ablation experiments on the RealEstate10K dataset with 12 input views under Algorithm 1Z-order Based Maximum Coverage Viewpoint Selection with Max-Heap Require:Viewpoint setV={V 1, V2, . . . , VN }, Number of viewpoints to selectM...
-
[54]
Since VGGT also utilizes DINOv2 [23] and DPT head [26] structures, we fused the global and geo- metric features extracted from VGGT
Analysis of Using the VGGT Backbone We also considered using VGGT [31] as the backbone for feature extraction instead of the depth-anything-v2- small [38]. Since VGGT also utilizes DINOv2 [23] and DPT head [26] structures, we fused the global and geo- metric features extracted from VGGT. The experiment was also conducted on the RealEstate10K dataset with ...
-
[55]
We highly recommend watching it to better appreciate the view consis- tency and high fidelity achieved by our method
Supplementary Video We provide a supplementary video showcasing additional visual results rendered from multiple viewpoints. We highly recommend watching it to better appreciate the view consis- tency and high fidelity achieved by our method
-
[56]
Limitations and Future Work Although our proposed method demonstrates improvements in feed-forward 3D Gaussian Splatting for novel view syn- thesis, there are still certain limitations that could be ad- dressed in future work. One key limitation of our model is that, although it is efficient, it may still face difficulties when processing very high-resolu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.