Recognition: no theorem link
PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning
Pith reviewed 2026-05-14 19:16 UTC · model grok-4.3
The pith
Decomposing confidence rewards into perception and reasoning clusters improves vision-language model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
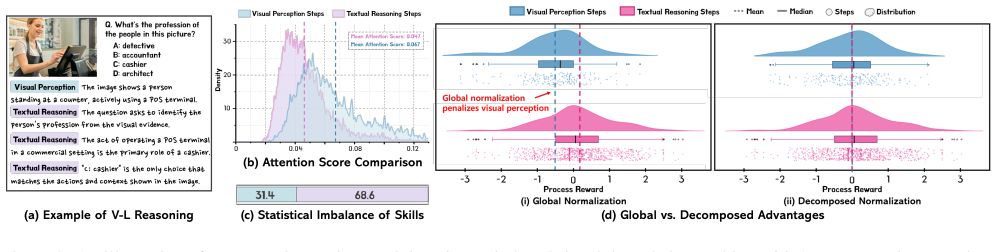
PDCR solves mixture-induced signal degradation in RLVR for vision-language tasks by introducing a Visual Dependence Score to quantify each step's visual reliance, applying unsupervised clustering to partition steps into perception and reasoning clusters, and computing decomposed advantages through intra-cluster normalization of confidence gains, which supplies a stable and properly scaled training signal aligned with the heterogeneous structure of the task.
What carries the argument
Visual Dependence Score plus unsupervised clustering that enables intra-cluster normalization of confidence gains for the decomposed reward.
If this is right
- PDCR produces higher benchmark scores than both global-reward and sparse-reward baselines on vision-language reasoning tasks.
- Intra-cluster normalization supplies correctly scaled signals for perception steps that would otherwise be drowned out by textual steps.
- The approach delivers step-level guidance while remaining fully model-intrinsic and free of external verifiers.
- The decomposition aligns the reward structure directly with the mix of sparse visual and dense textual components in the task.
Where Pith is reading between the lines
- The same clustering idea could be tested on other mixed-density multimodal tasks such as video-text or audio-text reasoning.
- Preventing one skill type from dominating the reward signal may allow stable training on longer multi-step chains.
- Because the decomposition is unsupervised, it opens the possibility of models that discover their own skill partitions during training.
Load-bearing premise
The unsupervised clustering driven by the model-internal Visual Dependence Score accurately partitions steps into perception and reasoning without any labeled supervision or external verification.
What would settle it
Training a model with PDCR on a V-L benchmark and measuring no gain in final accuracy or step-level metrics compared with the global-reward baseline.
Figures






read the original abstract
Reinforcement Learning with Verifiable Rewards (RLVR) traditionally relies on a sparse, outcome-based signal. Recent work shows that providing a fine-grained, model-intrinsic signal (rewarding the confidence growth in the ground-truth answer) effectively improves language reasoning training by providing step-level guidance without costly external models. While effective for unimodal text, we find that naively applying this global reward to vision-language (V-L) reasoning is a suboptimal strategy, as the task is a heterogeneous mix of sparse visual perception and dense textual reasoning. This global normalization creates mixture-induced signal degradation, where the training signal for visual steps is statistically distorted by the predominant textual steps. We propose Perception-Decomposed Confidence Reward (PDCR), a framework that solves this by aligning the reward structure with the task's heterogeneous nature. PDCR first performs an unsupervised skill decomposition, introducing a model-internal Visual Dependence Score to quantify visual reliance and applying a clustering algorithm to separate perception and reasoning steps. Based on this, PDCR computes a decomposed advantage by normalizing confidence gains within each skill cluster. This intra-cluster normalization provides a stable, correctly-scaled signal for both perception and reasoning. We demonstrate that PDCR outperforms the naive, global-reward formulation and sparse-reward baselines on key V-L reasoning benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Perception-Decomposed Confidence Reward (PDCR) for RLVR in vision-language reasoning. It argues that global confidence rewards suffer from mixture-induced signal degradation because V-L tasks mix sparse visual perception steps with dense textual reasoning steps. PDCR introduces a model-internal Visual Dependence Score, applies unsupervised clustering to separate perception and reasoning steps, and computes intra-cluster normalized advantages on confidence gains. The authors claim this outperforms both naive global-reward formulations and sparse-reward baselines on key V-L reasoning benchmarks.
Significance. If the unsupervised decomposition is reliable, PDCR supplies a parameter-free, model-intrinsic mechanism for skill-aligned step-level rewards in multimodal settings. This could reduce reliance on external verifiers while mitigating variance distortion across heterogeneous step types, offering a practical advance for training vision-language models on reasoning tasks.
major comments (2)
- [Method] Method section (description of Visual Dependence Score and clustering): the central claim that intra-cluster normalization supplies a 'correctly-scaled signal' rests on the assumption that the unsupervised partitions accurately separate perception from reasoning. No validation, human labels, proxy-task correlation, or ablation on cluster stability/quality is reported, so it remains possible that reported gains arise from altered normalization variance rather than the intended decomposition.
- [Experiments] Experiments section: the abstract asserts outperformance on benchmarks, yet the manuscript supplies no quantitative results, error bars, baseline implementations, statistical significance tests, or ablation studies isolating the contribution of the decomposition. Without these, the headline claim cannot be evaluated.
minor comments (2)
- [Method] Notation for the Visual Dependence Score is introduced without an explicit equation or algorithmic pseudocode, making the clustering procedure difficult to reproduce.
- [Abstract] The abstract states 'key V-L reasoning benchmarks' without naming them or reporting any numbers; this should be expanded even in the abstract for clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on our manuscript. We address the two major comments below and will revise the paper accordingly to strengthen the validation of the decomposition and the presentation of experimental evidence.
read point-by-point responses
-
Referee: [Method] Method section (description of Visual Dependence Score and clustering): the central claim that intra-cluster normalization supplies a 'correctly-scaled signal' rests on the assumption that the unsupervised partitions accurately separate perception from reasoning. No validation, human labels, proxy-task correlation, or ablation on cluster stability/quality is reported, so it remains possible that reported gains arise from altered normalization variance rather than the intended decomposition.
Authors: We agree that demonstrating the quality of the unsupervised partitions is essential to support the claim of skill-aligned rewards. The Visual Dependence Score is computed from model-internal attention patterns over visual tokens, and clustering is performed via k-means on these scores. In the revision we will add: (1) stability analysis across random seeds and different numbers of clusters, (2) correlation of cluster assignments with proxy signals such as per-step visual grounding accuracy on a held-out VQA subset, and (3) a small human annotation study on 200 randomly sampled steps to measure agreement between clusters and human perception/reasoning labels. These additions will directly test whether the decomposition isolates the intended step types rather than merely changing normalization variance. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts outperformance on benchmarks, yet the manuscript supplies no quantitative results, error bars, baseline implementations, statistical significance tests, or ablation studies isolating the contribution of the decomposition. Without these, the headline claim cannot be evaluated.
Authors: We apologize for the insufficient detail in the experimental reporting. The full manuscript does contain benchmark results comparing PDCR against global-reward and sparse-reward baselines on standard V-L reasoning datasets, but these were not presented with sufficient rigor. In the revised version we will: (1) report mean performance with standard deviation across 5 random seeds, (2) include statistical significance via paired t-tests against each baseline, (3) provide explicit implementation details and hyperparameters for all baselines, and (4) add an ablation table that isolates the effect of intra-cluster normalization versus global normalization while keeping the decomposition fixed. These changes will make the quantitative claims fully evaluable. revision: yes
Circularity Check
No significant circularity in PDCR derivation chain
full rationale
The paper derives PDCR from model-internal Visual Dependence Score, unsupervised clustering of steps into perception vs. reasoning, and intra-cluster normalization of confidence gains. These steps are defined directly from the model's own signals without reducing to fitted parameters drawn from the target benchmarks, self-citations that bear the central claim, or any renaming of known results. Performance is measured on external V-L benchmarks, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision-language reasoning is a heterogeneous mix of sparse visual perception and dense textual reasoning steps whose signals are statistically distorted by global normalization.
invented entities (1)
-
Visual Dependence Score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gpt-4v(ision) system card. 2023. 1
2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Vrprm: Process reward modeling via visual reasoning.arXiv preprint arXiv:2508.03556, 2025
Xinquan Chen, Bangwei Liu, Xuhong Wang, Yingchun Wang, and Chaochao Lu. Vrprm: Process reward modeling via visual reasoning.arXiv preprint arXiv:2508.03556, 2025. 1, 2
-
[4]
Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, and Weiping Li. Qwen look again: Guiding vision-language reasoning mod- els to re-attention visual information.arXiv preprint arXiv:2505.23558, 2025. 2
-
[5]
Ultrafeedback: Boosting language models with scaled ai feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingx- iang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, et al. Ultrafeedback: Boosting language models with scaled ai feedback. InForty-first International Confer- ence on Machine Learning. 2
-
[6]
Yizhuo Ding, Mingkang Chen, Zhibang Feng, Tong Xiao, Wanying Qu, Wenqi Shao, and Yanwei Fu. Vtperception-r1: Enhancing multimodal reasoning via explicit visual and tex- tual perceptual grounding.arXiv preprint arXiv:2509.24776,
-
[7]
Sophiavl-r1: Reinforcing mllms reasoning with thinking reward.arXiv preprint arXiv:2505.17018, 2025
Kaixuan Fan, Kaituo Feng, Haoming Lyu, Dongzhan Zhou, and Xiangyu Yue. Sophiavl-r1: Reinforcing mllms reasoning with thinking reward.arXiv preprint arXiv:2505.17018, 2025. 2
-
[8]
Hallusionbench: an advanced diag- nostic suite for entangled language hallucination and visual illusion in large vision-language models
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, et al. Hallusionbench: an advanced diag- nostic suite for entangled language hallucination and visual illusion in large vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, p...
2024
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token percep- tion for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025. 2, 8
-
[11]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Structured co-reference graph attention for video-grounded dialogue
Junyeong Kim, Sunjae Yoon, Dahyun Kim, and Chang D Yoo. Structured co-reference graph attention for video-grounded dialogue. InProceedings of the AAAI Conference on Artificial Intelligence, pages 1789–1797, 2021. 2
2021
-
[13]
Rethinking reward models for multi-domain test-time scaling.arXiv preprint arXiv:2510.00492, 2025
Dong Bok Lee, Seanie Lee, Sangwoo Park, Minki Kang, Jinheon Baek, Dongki Kim, Dominik Wagner, Jiongdao Jin, Heejun Lee, Tobias Bocklet, et al. Rethinking reward models for multi-domain test-time scaling.arXiv preprint arXiv:2510.00492, 2025. 3
-
[14]
Pengyi Li, Matvey Skripkin, Alexander Zubrey, Andrey Kuznetsov, and Ivan Oseledets. Confidence is all you need: Few-shot rl fine-tuning of language models.arXiv preprint arXiv:2506.06395, 2025. 2
-
[15]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Zongxia Li, Wenhao Yu, Chengsong Huang, Rui Liu, Zhen- wen Liang, Fuxiao Liu, Jingxi Che, Dian Yu, Jordan Boyd-Graber, Haitao Mi, et al. Self-rewarding vision- language model via reasoning decomposition.arXiv preprint arXiv:2508.19652, 2025. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1
2023
-
[17]
Gdpo: Group reward-decoupled normalization policy optimization for multi-reward rl optimization,
Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe Diao, Peter Belcak, Mingjie Liu, Min-Hung Chen, Hongxu Yin, Yu- Chiang Frank Wang, Kwang-Ting Cheng, et al. Gdpo: Group reward-decoupled normalization policy optimiza- tion for multi-reward rl optimization.arXiv preprint arXiv:2601.05242, 2026. 2
-
[18]
Yuliang Liu, Junjie Lu, Zhaoling Chen, Chaofeng Qu, Ja- son Klein Liu, Chonghan Liu, Zefan Cai, Yunhui Xia, Li Zhao, Jiang Bian, et al. Adaptivestep: Automatically divid- ing reasoning step through model confidence.arXiv preprint arXiv:2502.13943, 2025. 3
-
[19]
Yuqi Liu, Tianyuan Qu, Zhisheng Zhong, Bohao Peng, Shu Liu, Bei Yu, and Jiaya Jia. Visionreasoner: Unified visual perception and reasoning via reinforcement learning.arXiv preprint arXiv:2505.12081, 2025. 2
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Unlocking multimodal mathematical reason- ing via process reward model
Ruilin Luo, Zhuofan Zheng, Lei Wang, Yifan Wang, Xinzhe Ni, Zicheng Lin, Songtao Jiang, Yiyao Yu, Chufan Shi, Rui- hang Chu, et al. Unlocking multimodal mathematical reason- ing via process reward model. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. 1, 2
-
[23]
Brandon Ong, Tej Deep Pala, Vernon Toh, William Chan- dra Tjhi, and Soujanya Poria. Training vision-language pro- cess reward models for test-time scaling in multimodal rea- soning: Key insights and lessons learned.arXiv preprint arXiv:2509.23250, 2025. 1, 2
-
[24]
A threshold selection method from gray- level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66, 1979
Nobuyuki Otsu. A threshold selection method from gray- level histograms.IEEE Transactions on Systems, Man, and Cybernetics, 9(1):62–66, 1979. 6
1979
-
[25]
Enhancing visual question answering through question-driven image captions as prompts
¨Ovg¨u ¨Ozdemir and Erdem Akag ¨und¨uz. Enhancing visual question answering through question-driven image captions as prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1562–1571,
-
[26]
NoisyGRPO: Incentivizing Multimodal CoT Reasoning via Noise Injection and Bayesian Estimation
Longtian Qiu, Shan Ning, Jiaxuan Sun, and Xuming He. Noisygrpo: Incentivizing multimodal cot reasoning via noise injection and bayesian estimation.arXiv preprint arXiv:2510.21122, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025
Gabriel Sarch, Snigdha Saha, Naitik Khandelwal, Ayush Jain, Michael J Tarr, Aviral Kumar, and Katerina Fragkiadaki. Grounded reinforcement learning for visual reasoning.arXiv preprint arXiv:2505.23678, 2025. 2
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 1, 2, 7, 3, 6, 9, 14
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Mea- suring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Mea- suring multimodal mathematical reasoning with math-vision dataset.Advances in Neural Information Processing Systems, 37:95095–95169, 2024. 7
2024
-
[31]
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jin- guo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Sheng- long Ye, Xizhou Zhu, et al. Visualprm: An effective pro- cess reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291, 2025. 1, 2
-
[32]
Tengjin Weng, Jingyi Wang, Wenhao Jiang, and Zhong Ming. Visnumbench: Evaluating number sense of multimodal large language models.arXiv preprint arXiv:2503.14939, 2025. 7
-
[33]
Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033,
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A Smith, Mari Ostendorf, and Hannaneh Hajishirzi. Fine-grained human feedback gives better rewards for language model training.Advances in Neural Information Processing Systems, 36:59008–59033,
-
[34]
Realworldqa: Real-world spatial understanding bench- mark
xAI. Realworldqa: Real-world spatial understanding bench- mark. https://x.ai/blog/grok- 1.5v- and- realworldqa, 2024. CC BY-ND 4.0 license. Benchmark dataset released with Grok-1.5 Vision. 7
2024
-
[35]
Jiaer Xia, Yuhang Zang, Peng Gao, Yixuan Li, and Kaiyang Zhou. Visionary-r1: Mitigating shortcuts in vi- sual reasoning with reinforcement learning.arXiv preprint arXiv:2505.14677, 2025. 1, 2, 7
-
[36]
Tong Xiao, Xin Xu, Zhenya Huang, Hongyu Gao, Quan Liu, Qi Liu, and Enhong Chen. Advancing multimodal reasoning capabilities of multimodal large language models via visual perception reward.arXiv preprint arXiv:2506.07218, 2025. 7
-
[37]
Tianrun Xu, Haoda Jing, Ye Li, Yuquan Wei, Jun Feng, Guanyu Chen, Haichuan Gao, Tianren Zhang, and Feng Chen. Defacto: Counterfactual thinking with images for enforcing evidence-grounded and faithful reasoning.arXiv preprint arXiv:2509.20912, 2025. 2
-
[38]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, et al. Qwen2. 5-math technical report: To- ward mathematical expert model via self-improvement.arXiv preprint arXiv:2409.12122, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Beyond the first error: Process reward models for reflective mathematical reasoning
Zhaohui Yang, Chenghua He, Xiaowen Shi, Linjing Li, Qiyue Yin, Shihong Deng, and Daxin Jiang. Beyond the first error: Process reward models for reflective mathematical reasoning. arXiv preprint arXiv:2505.14391, 2025. 3
-
[41]
Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback
Eunseop Yoon, Hee Suk Yoon, SooHwan Eom, Gunsoo Han, Daniel Nam, Daejin Jo, Kyoung-Woon On, Mark Hasegawa- Johnson, Sungwoong Kim, and Chang Yoo. Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback. InFindings of the Association for Computational Linguistics: ACL 2024, pages 14969–14981,
2024
-
[42]
Eunseop Yoon, Hee Suk Yoon, Jaehyun Jang, SooHwan Eom, Qi Dai, Chong Luo, Mark A Hasegawa-Johnson, and Chang D Yoo. Pacr: Progressively ascending confidence reward for llm reasoning.arXiv preprint arXiv:2510.22255, 2025. 1, 2, 3, 7, 6, 9, 14
-
[43]
Bi-mdrg: Bridging image history in multimodal dialogue response generation
Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Kang Zhang, Yu-Jung Heo, Du-Seong Chang, and Chang D Yoo. Bi-mdrg: Bridging image history in multimodal dialogue response generation. InEuropean Conference on Computer Vision, pages 378–396. Springer, 2024. 2
2024
-
[44]
Confpo: Exploiting policy model confidence for critical token selection in prefer- ence optimization
Hee Suk Yoon, Eunseop Yoon, Mark A Hasegawa-Johnson, Sungwoong Kim, and Chang D Yoo. Confpo: Exploiting policy model confidence for critical token selection in prefer- ence optimization. InInternational Conference on Machine Learning, pages 72641–72655. PMLR, 2025. 2
2025
-
[45]
Hear: Hearing enhanced audio response for video-grounded dialogue
Sunjae Yoon, Dahyun Kim, Eunseop Yoon, Hee Yoon, Jun- yeong Kim, and Chang Yoo. Hear: Hearing enhanced audio response for video-grounded dialogue. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 11911–11924, 2023. 2
2023
-
[46]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xi- aochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Ji- aze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, ...
2025
-
[47]
Self- rewarding language models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E Weston. Self- rewarding language models. InForty-first International Con- ference on Machine Learning, 2024. 2
2024
-
[48]
Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multi- modal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556–9567, 2024. 7
2024
-
[49]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134–15186,
-
[50]
Thomas Zeng, Shuibai Zhang, Shutong Wu, Christian Classen, Daewon Chae, Ethan Ewer, Minjae Lee, Heeju Kim, Wonjun Kang, Jackson Kunde, et al. Versaprm: Multi-domain process reward model via synthetic reasoning data.arXiv preprint arXiv:2502.06737, 2025. 3
-
[51]
OpenPRM: Building open-domain process-based reward mod- els with preference trees
Kaiyan Zhang, Jiayuan Zhang, Haoxin Li, Xuekai Zhu, Ermo Hua, Xingtai Lv, Ning Ding, Biqing Qi, and Bowen Zhou. OpenPRM: Building open-domain process-based reward mod- els with preference trees. InThe Thirteenth International Conference on Learning Representations, 2025. 2
2025
-
[52]
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, et al. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? InEuropean Conference on Computer Vision, pages 169–186. Springer,
-
[53]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Xuandong Zhao, Zhewei Kang, Aosong Feng, Sergey Levine, and Dawn Song. Learning to reason without external rewards. arXiv preprint arXiv:2505.19590, 2025. 2
-
[54]
Calibrated self-rewarding vision language models.Advances in Neural Information Processing Systems, 37:51503–51531, 2024
Yiyang Zhou, Zhiyuan Fan, Dongjie Cheng, Sihan Yang, Zhaorun Chen, Chenhang Cui, Xiyao Wang, Yun Li, Linjun Zhang, and Huaxiu Yao. Calibrated self-rewarding vision language models.Advances in Neural Information Processing Systems, 37:51503–51531, 2024. 2
2024
-
[55]
Yujun Zhou, Zhenwen Liang, Haolin Liu, Wenhao Yu, Kishan Panaganti, Linfeng Song, Dian Yu, Xiangliang Zhang, Haitao Mi, and Dong Yu. Evolving language models without labels: Majority drives selection, novelty promotes variation.arXiv preprint arXiv:2509.15194, 2025. 2
-
[56]
Mingkang Zhu, Xi Chen, Bei Yu, Hengshuang Zhao, and Jiaya Jia. Stratified grpo: Handling structural heterogeneity in reinforcement learning of llm search agents.arXiv preprint arXiv:2510.06214, 2025. 2 PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning Supplementary Material Appendix Contents
-
[57]
Training Procedure Pseudocode 2
-
[58]
Experimental Results on Additional Model Backbone 3
-
[59]
Segmentation Detail 3
-
[60]
Annotation Setup 4 15.2
Label Acquisition for Skill Analysis 4 15.1 . Annotation Setup 4 15.2 . Validation of Label Quality 4 15.3 . Qualitative Examples of Skill Decomposition 5
-
[61]
Training Framework and Hyperparameters 6 16.2
Implementation Details 6 16.1 . Training Framework and Hyperparameters 6 16.2 . Prompt Template for Training and Inference 7
-
[62]
Ablation Study on Visual Dependence Calculation for Skill Decomposition 8
-
[63]
Qualitative Comparisons of Generated Reasoning 9
-
[64]
Limitations and Future Works 14
-
[65]
Broader Impact This work introduces a framework for improving the reasoning capabilities of multimodal Large Language Models. By lever- aging the model’s intrinsic confidence dynamics, our method provides fine-grained, step-level supervision, and decomposes this signal to align with the heterogeneous skills of perception and reasoning. This is achieved wi...
-
[66]
Furthermore, our experiments utilize only publicly available datasets and do not involve the collection of sensitive or personally identifiable information
Ethics Statement This research strictly adheres to academic integrity standards, ensuring all prior work is properly cited and acknowledged. Furthermore, our experiments utilize only publicly available datasets and do not involve the collection of sensitive or personally identifiable information
-
[67]
This pseudocode provides a step-by-step specification of the method summarized in Section 5
Training Procedure Pseudocode We outline our Perception-Decomposed Confidence Reward (PDCR) training procedure in Algorithm 1. This pseudocode provides a step-by-step specification of the method summarized in Section 5. The highlighted lines indicate the additional processing steps introduced in our proposed PDCR compared to PACR [42]. Algorithm 1:Percept...
-
[68]
As shown in Table 3, PDCR demonstrates generalization to this stronger backbone, achieving a final average score of 59.1
Experimental Results on Additional Model Backbone We further evaluate PDCR on the recently released Qwen3-VL-8B-Instruct (implementation details are outlined in Appendix 16). As shown in Table 3, PDCR demonstrates generalization to this stronger backbone, achieving a final average score of 59.1. This performance outperforms the sparse GRPO baseline (58.3,...
-
[69]
Step 1:”, “Step 2:
Segmentation Detail A prerequisite for a process-based reward framework is the segmentation of the reasoning trajectory τ (i) into a discrete sequence of steps{h (i) k }Ki k=1. The step is the fundamental unit to which a reward or advantage is assigned. Previous work in process-reward modeling has adopted several strategies to define this unit: • Supervis...
-
[70]
visual perception
Label Acquisition for Skill Analysis To empirically validate the heterogeneous nature of V-L reasoning ([Observation 1] in Section 4) and the effectiveness of our unsupervised skill decomposition (Section 5.1), we required a set of ground truth skill labels. Since no existing dataset provides step-level distinctions between perception and reasoning, we co...
2025
-
[71]
They achieved a Cohen’s Kappa of κ= 0.82 , indicating that the binary distinction between perception and reasoning is well-defined and unambiguous to humans
Human Inter-Annotator Agreement:Two human experts independently annotated a random subset of 100 steps. They achieved a Cohen’s Kappa of κ= 0.82 , indicating that the binary distinction between perception and reasoning is well-defined and unambiguous to humans
-
[72]
Midnight
Model-Human Alignment:We compared the primary gpt-5 annotations against the human consensus on the same subset. The model achieved a Kappa score of κ= 0.79 (Table 4). This high alignment confirms that the model effectively acts as a reliable proxy for human judgment, correctly adhering to the strict definitions provided in the prompt. Table 4.Inter-Annota...
-
[73]
Training Framework and Hyperparameters We perform all experiments using theEasyR1framework
Implementation Details 16.1. Training Framework and Hyperparameters We perform all experiments using theEasyR1framework. Consistent with the R1-Zero style training [ 9], we apply Reinforce- ment Learning with Verifiable Rewards (RLVR) directly on the base model, bypassing any Supervised Fine-Tuning (SFT) stage. This ensures that the reasoning behaviors we...
2048
-
[74]
Visual Perturbation Strategies Evaluated for Skill Decomposition
Ablation Study on Visual Dependence Calculation for Skill Decomposition Figure 7. Visual Perturbation Strategies Evaluated for Skill Decomposition. To calculate the Visual Dependence Score (V (i) k , Eq. 7) , we compare the model’s probability on the(a) Originalimage against four baselines:(b) White(Strategy adopted in main text),(c) Gaussian Blur,(d) Gau...
-
[75]
All examples presented were generated by the final policies trained on theQwen2.5-VL-7B-Instruct backbone
Qualitative Comparisons of Generated Reasoning In this section, we present side-by-side comparisons between our proposed PDCR and baselines (GRPO [28], PACR [42]) on V- L reasoning tasks. All examples presented were generated by the final policies trained on theQwen2.5-VL-7B-Instruct backbone. These examples highlight the core benefit of our decomposed re...
-
[76]
It looks like a pyramid-like structure with a base and layers decreasing upwards
Visual Inspection: The figure appears to be a 3D structure with cubes stacked in a somewhat organized manner. It looks like a pyramid-like structure with a base and layers decreasing upwards
-
[77]
- The next layer up has 5 cubes
Counting Layers: - The base layer looks like it has 6 cubes. - The next layer up has 5 cubes. - The layer above that has 4 cubes. - The top layer has 3 cubes
-
[78]
Summing Up: Adding these together gives us 6 + 5 + 4 + 3 = 18 cubes
-
[79]
(b) 24 is significantly more
Comparison with Options: (a) 17 is close but slightly less. (b) 24 is significantly more. (c) 7 is much less. (d) 39 is much more. Given the visual inspection and the summing up, the closest reasonable estimate is 17.</think> a Generated Sample 2 by PDCR (ours) Question: Which of the following options is a reasonable estimate of the number of cubes in the...
-
[80]
Computational Cost.The primary limitation of our framework is the computational overhead during the training phase
Limitations and Future Works Our work presents a promising direction for self-rewarding V-L models, but has limitations that offer avenues for future research. Computational Cost.The primary limitation of our framework is the computational overhead during the training phase. As shown in Figure 6-(b) of main paper, both PDCR and the dense-reward baseline (...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.