Recognition: no theorem link
OSDN: Improving Delta Rule with Provable Online Preconditioning in Linear Attention
Pith reviewed 2026-05-14 19:04 UTC · model grok-4.3
The pith
OSDN augments the Delta Rule with an online diagonal preconditioner equivalent to per-feature key scaling, delivering super-geometric convergence and 39% lower recall residual at 1.3B parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OSDN augments the scalar gate in the Delta Rule with a diagonal preconditioner updated online via hypergradient feedback. This right-preconditioning is algebraically equivalent to a per-feature scaling of the write-side key, allowing the method to preserve the hardware-friendly chunkwise parallel pipeline. By exploiting the exact-quadratic structure of the inner regression loss, OSDN establishes super-geometric convergence against a right-Newton comparator and proves an algorithm-aligned token-local residual contraction bound. Adaptive Preconditioner Forgetting is introduced to handle non-stationary contexts by dynamically refreshing stale calibration.
What carries the argument
The diagonal preconditioner maintained by online hypergradient updates, algebraically equivalent to per-feature scaling of the write-side key in the Delta Rule.
If this is right
- At 340M parameters OSDN improves JRT-style in-context recall by 32 percent over the plain Delta Rule.
- At 1.3B parameters the recall residual ratio drops by 39 percent while perplexity and LongBench scores stay comparable.
- Adaptive Preconditioner Forgetting refreshes the preconditioner on the fly to handle non-stationary contexts.
- The theoretical guarantee is super-geometric convergence to the right-Newton comparator with token-local residual contraction.
- The algebraic equivalence to key scaling lets the algorithm keep its original chunkwise parallel implementation.
Where Pith is reading between the lines
- The same online diagonal scaling could be added to other linear-attention or state-space models that rely on quadratic inner losses.
- Because the change is realized as a simple per-feature multiplication on the key, it can be dropped into existing chunkwise kernels with almost no extra code.
- If the quadratic-loss assumption continues to hold at still larger scales, the method could become a default upgrade for any Delta-Rule-style memory update.
- The Adaptive Preconditioner Forgetting schedule itself may be useful in any online setting where curvature estimates quickly become stale.
Load-bearing premise
The inner regression loss must remain exactly quadratic so that the hypergradient update for the diagonal preconditioner stays valid and the convergence bounds apply.
What would settle it
Measurements at 1.3B scale showing recall-residual improvement below 20 percent or convergence that is only linear instead of super-geometric would falsify the central claim.
Figures




read the original abstract
Linear attention and state-space models offer constant-memory alternatives to softmax attention, but often struggle with in-context associative recall. The Delta Rule mitigates this by writing each token via one step of online gradient descent. However, its step size relies on a single scalar gate that ignores the feature-wise curvature of the inner objective. We propose Online Scaled DeltaNet (OSDN), which augments the scalar gate with a diagonal preconditioner updated online via hypergradient feedback. Crucially, this right-preconditioning is algebraically equivalent to a per-feature scaling of the write-side key. This equivalence allows OSDN to strictly preserve the hardware-friendly chunkwise parallel pipeline of DeltaNet without incurring high-dimensional state overhead. Theoretically, by exploiting the exact-quadratic structure of the inner regression loss, we establish super-geometric convergence against a right-Newton comparator and prove an algorithm-aligned token-local residual contraction bound. To handle non-stationary contexts, we further introduce Adaptive Preconditioner Forgetting (APF) to dynamically refresh stale calibration. Empirically, OSDN demonstrates strong performance across scales. At the 340M-parameter scale, OSDN improves JRT-style in-context recall by 32% over DeltaNet. Scaling to 1.3B parameters, it achieves a 39% reduction in the recall residual ratio while maintaining parity on general downstream tasks (e.g., perplexity and LongBench) -- demonstrating that our online-preconditioning mechanism effectively transfers and amplifies at the billion-parameter scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Online Scaled DeltaNet (OSDN), augmenting the Delta Rule for linear attention with a diagonal preconditioner updated online via hypergradient feedback. This preconditioner is algebraically equivalent to per-feature scaling of the write-side key, preserving the chunkwise parallel pipeline without high-dimensional state. Theoretical results exploit the exact-quadratic inner regression loss to prove super-geometric convergence against a right-Newton comparator and an algorithm-aligned token-local residual contraction bound. Adaptive Preconditioner Forgetting (APF) handles non-stationary contexts. Empirically, OSDN yields a 32% improvement in JRT-style in-context recall at 340M parameters and a 39% reduction in recall residual ratio at 1.3B parameters while maintaining parity on perplexity and LongBench.
Significance. If the convergence proofs hold rigorously and the hypergradient update preserves O(d) state and chunkwise parallelism, the work would meaningfully advance linear attention and state-space models by addressing associative recall limitations in a hardware-efficient manner. The scaling results to 1.3B parameters indicate practical transferability, offering a potential path to improve in-context learning without softmax attention overhead.
major comments (3)
- [Theoretical Analysis] Theoretical Analysis section: The super-geometric convergence and token-local residual contraction bounds exploit the exact-quadratic structure, but the online hypergradient update for the diagonal preconditioner introduces a second-order term when differentiating the Delta-rule update w.r.t. preconditioner parameters. It is not shown that this term remains O(d) state and compatible with the chunkwise parallel scan, even though the forward-pass equivalence to key scaling is established.
- [§5 Experiments] §5 Experiments: The 39% reduction in recall residual ratio at 1.3B parameters and 32% improvement at 340M parameters are reported without error bars, details on data exclusion criteria, or statistical significance tests, which undermines assessment of the scaling claims and cross-scale consistency.
- [Method] Method section: The Adaptive Preconditioner Forgetting rate is a free parameter whose effect on the provable bounds is not analyzed; the theoretical results assume conditions that APF relaxes, but no adjusted convergence statement is provided.
minor comments (2)
- [Abstract] Abstract: The term 'JRT-style in-context recall' is used without definition or citation, reducing accessibility.
- [Notation] Notation: Ensure the preconditioner matrix and hypergradient symbols are defined consistently before first use in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical Analysis section: The super-geometric convergence and token-local residual contraction bounds exploit the exact-quadratic structure, but the online hypergradient update for the diagonal preconditioner introduces a second-order term when differentiating the Delta-rule update w.r.t. preconditioner parameters. It is not shown that this term remains O(d) state and compatible with the chunkwise parallel scan, even though the forward-pass equivalence to key scaling is established.
Authors: We appreciate this observation. The forward equivalence to per-feature key scaling ensures that the main Delta-rule update preserves chunkwise parallelism and O(d) state. For the hypergradient update of the diagonal preconditioner, the second-order term arises from differentiating through the update rule. Because the preconditioner is strictly diagonal, this differentiation reduces to element-wise operations that can be maintained with O(d) additional state (the current preconditioner and its gradient estimate). We will include a supplementary derivation in the revised Theoretical Analysis section demonstrating that the hypergradient feedback integrates into the existing parallel scan recurrence without increasing state complexity or breaking chunkwise compatibility. revision: yes
-
Referee: [§5 Experiments] §5 Experiments: The 39% reduction in recall residual ratio at 1.3B parameters and 32% improvement at 340M parameters are reported without error bars, details on data exclusion criteria, or statistical significance tests, which undermines assessment of the scaling claims and cross-scale consistency.
Authors: We agree that the empirical results would benefit from additional statistical rigor. In the revised version of §5, we will augment the reported figures with error bars computed over multiple random seeds (at least 3 per scale), specify the data exclusion criteria applied to the JRT-style in-context recall benchmarks, and include statistical significance tests (e.g., paired t-tests) comparing OSDN against the DeltaNet baseline. These additions will better support the scaling claims and cross-scale consistency. revision: yes
-
Referee: [Method] Method section: The Adaptive Preconditioner Forgetting rate is a free parameter whose effect on the provable bounds is not analyzed; the theoretical results assume conditions that APF relaxes, but no adjusted convergence statement is provided.
Authors: APF is a practical heuristic designed to mitigate the effects of non-stationarity in real-world contexts, which the core theoretical analysis assumes away. The super-geometric convergence and residual contraction bounds hold under the stationary quadratic-loss setting without forgetting. Introducing APF relaxes these assumptions to improve empirical robustness, but deriving a modified convergence rate would require additional modeling of the forgetting dynamics. We will add a clarifying paragraph in the Method section explaining this distinction and noting that APF preserves the O(d) state and parallelism while serving as an empirical enhancement. A full theoretical treatment of APF is left for future work. revision: partial
Axiom & Free-Parameter Ledger
free parameters (1)
- Adaptive Preconditioner Forgetting rate
axioms (1)
- domain assumption Exact-quadratic structure of the inner regression loss
Reference graph
Works this paper leans on
-
[1]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InInternational Conference on Learning Representations, 2023
work page 2023
-
[2]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models, 2024. URLhttps://arxiv.org/abs/2312.04927
-
[3]
Simple linear attention language models balance the recall-throughput tradeoff
Simran Arora, Sabri Eyuboglu, Michael Zhang, Aman Timalsina, Silas Alberti, Dylan Zinsley, James Zou, Atri Rudra, and Christopher Ré. Simple linear attention language models balance the recall-throughput tradeoff, 2024. URLhttps://arxiv.org/abs/2402.18668
-
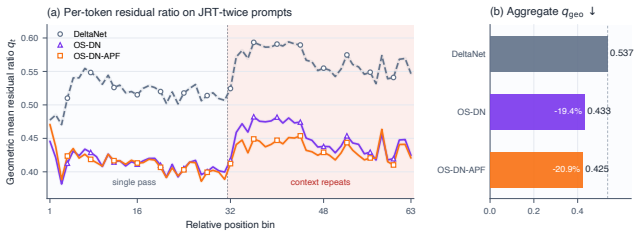
[4]
Just read twice: Closing the recall gap for recurrent language models, 2024
Simran Arora, Aman Timalsina, Aaryan Singhal, Benjamin Spector, Sabri Eyuboglu, Xinyi Zhao, Ashish Rao, Atri Rudra, and Christopher Ré. Just read twice: Closing the recall gap for recurrent language models, 2024. URLhttps://arxiv.org/abs/2407.05483
-
[5]
Hinton, V olodymyr Mnih, Joel Z
Jimmy Ba, Geoffrey E. Hinton, V olodymyr Mnih, Joel Z. Leibo, and Catalin Ionescu. Using fast weights to attend to the recent past. InAdvances in Neural Information Processing Systems, 2016
work page 2016
-
[6]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InAnnual Meeting of the Association for Computational Linguistics, 2024
work page 2024
-
[7]
Online learning rate adaptation with hypergradient descent
Atılım Güne¸ s Baydin, Robert Cornish, David Martínez Rubio, Mark Schmidt, and Frank Wood. Online learning rate adaptation with hypergradient descent. InInternational Conference on Learning Representations, 2018
work page 2018
-
[8]
Maximilian Beck, Korbinian Pöppel, Markus Spanring, Andreas Auer, Oleksandra Prud- nikova, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochre- iter. xLSTM: extended long short-term memory.Advances in Neural Infor- mation Processing Systems, 37:107547–107603, December 2024. doi: 10.52202/ 079017-3417. URL https://proceedings.neurips.cc/...
work page 2024
-
[9]
Titans: Learning to memorize at test time,
Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. Titans: Learning to memorize at test time,
-
[10]
URLhttps://arxiv.org/abs/2501.00663
work page internal anchor Pith review arXiv
-
[11]
Atlas: Learning to optimally memorize the context at test time, 2025
Ali Behrouz, Zeman Li, Praneeth Kacham, Majid Daliri, Yuan Deng, Peilin Zhong, Meisam Razaviyayn, and Vahab Mirrokni. Atlas: Learning to optimally memorize the context at test time, 2025. URLhttps://arxiv.org/abs/2505.23735
-
[12]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InAAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[13]
Rethinking attention with performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum? id=Ua6zuk0WRH
work page 2021
-
[14]
BoolQ: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In North American Chapter of the Association for Computational Linguistics, 2019. 10
work page 2019
-
[15]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try ARC, the AI2 reasoning challenge, 2018. URLhttps://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[16]
Tri Dao and Albert Gu. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. InProceedings of the 41st International Conference on Machine Learning, pages 10041–10071. PMLR, July 2024. URL https://proceedings. mlr.press/v235/dao24a.html
work page 2024
-
[17]
DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs
Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. DROP: A reading comprehension benchmark requiring discrete reasoning over paragraphs. InNorth American Chapter of the Association for Computational Linguistics, 2019
work page 2019
-
[18]
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research, 12:2121–2159, 2011
work page 2011
-
[19]
Gradient methods with online scaling
Wenzhi Gao, Ya Chi Chu, Yinyu Ye, and Madeleine Udell. Gradient methods with online scaling. arXiv preprint arXiv:2411.01803, 2024. URLhttps://arxiv.org/abs/2411.01803
-
[20]
Mamba: linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: linear-time sequence modeling with selective state spaces. August 2024. URLhttps://openreview.net/forum?id=tEYskw1VY2
work page 2024
-
[21]
Efficiently modeling long sequences with structured state spaces
Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. October 2021. URL https://openreview.net/forum?id=uYLFoz1vlAC. shortConferenceName: ICLR
work page 2021
-
[22]
Shampoo: Preconditioned stochastic tensor optimization
Vineet Gupta, Tomer Koren, and Yoram Singer. Shampoo: Preconditioned stochastic tensor optimization. InInternational Conference on Machine Learning, 2018
work page 2018
-
[23]
Foundations and Trends in Optimiza- tion, 2016
Elad Hazan.Introduction to Online Convex Optimization. Foundations and Trends in Optimiza- tion, 2016
work page 2016
-
[24]
Logarithmic regret algorithms for online convex optimization.Machine Learning, 69(2–3):169–192, 2007
Elad Hazan, Amit Agarwal, and Satyen Kale. Logarithmic regret algorithms for online convex optimization.Machine Learning, 69(2–3):169–192, 2007
work page 2007
-
[25]
Samy Jelassi, David Brandfonbrener, Sham M. Kakade, and Eran Malach. Repeat after me: Transformers are better than state space models at copying, 2024. URL https://arxiv.org/ abs/2402.01032
-
[26]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InAnnual Meeting of the Association for Computational Linguistics, 2017
work page 2017
-
[27]
Jungo Kasai, Hao Peng, Yizhe Zhang, Dani Yogatama, Gabriel Ilharco, Nikolaos Pappas, Yi Mao, Weizhu Chen, and Noah A. Smith. Finetuning pretrained transformers into RNNs. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 10630...
-
[28]
Transformers are RNNs: fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: fast autoregressive transformers with linear attention. InProceedings of the 37th International Conference on Machine Learning, pages 5156–5165. PMLR, November 2020. URL https://proceedings.mlr.press/v119/katharopoulos20a.html. shortConfer- enceName: ICML
work page 2020
-
[29]
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015
work page 2015
-
[30]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
work page 2019
-
[31]
arXiv preprint arXiv:2603.15569 , year=
Aakash Lahoti, Kevin Y . Li, Berlin Chen, Caitlin Wang, Aviv Bick, J. Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles, 2026. URL https://arxiv.org/abs/2603.15569
-
[32]
Longhorn: State space models are amortized online learners
Bo Liu, Rui Wang, Lemeng Wu, Yihao Feng, Peter Stone, and Qiang Liu. Longhorn: State space models are amortized online learners, 2024. URLhttps://arxiv.org/abs/2407.14207
-
[33]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Huanru Henry Mao. Fine-tuning pre-trained transformers into decaying fast weights. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 10236–10242, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1...
-
[34]
Pointer sentinel mixture models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. InInternational Conference on Learning Representations, 2017
work page 2017
-
[35]
In-context learning and induction heads
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. InTransformer Circuits Thread, 2022. URL https:// transformer-circuits.pub/2022/in-context-learning-and-induction-heads/ index.html
work page 2022
-
[36]
Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De
Antonio Orvieto, Samuel L. Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. In International Conference on Machine Learning, 2023
work page 2023
-
[37]
The LAMBADA dataset: Word prediction requiring a broad discourse context
Denis Paperno, Germán Kruszewski, Angeliki Lazaridou, Quan Ngoc Pham, Raffaella Bernardi, Sandro Pezzelle, Marco Baroni, Gemma Boleda, and Raquel Fernández. The LAMBADA dataset: Word prediction requiring a broad discourse context. InAnnual Meeting of the Association for Computational Linguistics, 2016
work page 2016
-
[38]
Eagle and finch: RWKV with matrix-valued states and dynamic recurrence
Bo Peng, Daniel Goldstein, Quentin Gregory Anthony, Alon Albalak, Eric Alcaide, Stella Biderman, Eugene Cheah, Teddy Ferdinan, Kranthi Kiran Gv, Haowen Hou, Satyapriya Krishna, Ronald McClelland Jr, Niklas Muennighoff, Fares Obeid, Atsushi Saito, Guangyu Song, Haoqin Tu, Ruichong Zhang, Bingchen Zhao, Qihang Zhao, Jian Zhu, and Rui-Jie Zhu. Eagle and finc...
work page 2024
-
[39]
RWKV-7 “Goose” with expressive dynamic state evolution, 2025
Bo Peng, Ruichong Zhang, Daniel Goldstein, Eric Alcaide, Haowen Du, Xingjian Hou, et al. RWKV-7 “Goose” with expressive dynamic state evolution, 2025. URLhttps://arxiv.org/ abs/2503.14456
-
[40]
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah Smith, and Lingpeng Kong. Random feature attention. October 2020. URL https://openreview.net/forum?id= QtTKTdVrFBB. shortConferenceName: ICLR
work page 2020
-
[41]
Hao Peng, Jungo Kasai, Nikolaos Pappas, Dani Yogatama, Zhaofeng Wu, Lingpeng Kong, Roy Schwartz, and Noah A. Smith. ABC: attention with bounded-memory control. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7469–7483...
work page 2022
-
[42]
Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y . Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models. InInternational Conference on Machine Learning, 2023
work page 2023
-
[43]
HGRN2: gated linear RNNs with state expansion
Zhen Qin, Songlin Yang, Weixuan Sun, Xuyang Shen, Dong Li, Weigao Sun, and Yiran Zhong. HGRN2: gated linear RNNs with state expansion. August 2024. URL https: //openreview.net/forum?id=y6SqbJfCSk
work page 2024
-
[44]
Rae, Anna Potapenko, Siddhant M
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling, 2020. URL https://arxiv.org/abs/ 1911.05507. 12
-
[45]
Hopfield networks is all you need
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlovi´c, Geir Kjetil Sandve, Victor Greiff, David Kreil, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need. InInternational Conference on Learning Representa...
work page 2021
-
[46]
WinoGrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: An adversarial winograd schema challenge at scale. InAAAI Conference on Artificial Intelligence, 2021
work page 2021
-
[47]
SocialIQA: Commonsense reasoning about social interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan Le Bras, and Yejin Choi. SocialIQA: Commonsense reasoning about social interactions. InConference on Empirical Methods in Natural Language Processing, 2019
work page 2019
-
[48]
Linear Transformers Are Secretly Fast Weight Programmers
Imanol Schlag, Kazuki Irie, and Jürgen Schmidhuber. Linear Transformers Are Secretly Fast Weight Programmers. InProceedings of the 38th International Conference on Machine Learning, pages 9355–9366. PMLR, July 2021. URL https://proceedings.mlr.press/ v139/schlag21a.html
work page 2021
-
[49]
Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks.Neural Computation, 4(1):131–139, 1992
work page 1992
-
[50]
Deltaproduct: Increasing the expressivity of DeltaNet through products of householders,
Julien Siems, Timur Carstensen, Arber Zela, Frank Hutter, Massimiliano Pontil, and Riccardo Grazzi. Deltaproduct: Increasing the expressivity of DeltaNet through products of householders,
- [51]
-
[52]
Jimmy T. H. Smith, Andrew Warrington, and Scott Linderman. Simplified state space layers for sequence modeling. September 2022. URL https://openreview.net/forum?id= Ai8Hw3AXqks
work page 2022
-
[53]
Smith, Andrew Warrington, and Scott Linderman
Jimmy T.H. Smith, Andrew Warrington, and Scott Linderman. Simplified state space layers for sequence modeling. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=Ai8Hw3AXqks
work page 2023
-
[54]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, Tatsunori Hashimoto, and Carlos Guestrin. Learning to (learn at test time): RNNs with expressive hidden states, 2024. URL https: //arxiv.org/abs/2407.04620
work page internal anchor Pith review arXiv 2024
-
[55]
Retentive Network: A Successor to Transformer for Large Language Models
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to transformer for large language mod- els.ArXiv, abs/2307.08621, 2023. URL https://api.semanticscholar.org/CorpusID: 259937453
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Richard S. Sutton. Adapting bias by gradient descent: An incremental version of delta-bar-delta. Proceedings of the Tenth National Conference on Artificial Intelligence (AAAI), pages 171–176, 1992
work page 1992
-
[57]
Kimi Team, Yu Zhang, Zongyu Lin, Xingcheng Yao, Jiaxi Hu, Fanqing Meng, Chengyin Liu, Xin Men, Songlin Yang, Zhiyuan Li, Wentao Li, Enzhe Lu, Weizhou Liu, Yanru Chen, Weixin Xu, Longhui Yu, Yejie Wang, Yu Fan, Longguang Zhong, Enming Yuan, Dehao Zhang, Yizhi Zhang, T. Y . Liu, Haiming Wang, Shengjun Fang, Weiran He, Shaowei Liu, Yiwei Li, Jianlin Su, Jiez...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Transformers learn in-context by gradient descent
Johannes von Oswald, Eyvind Niklasson, Ettore Randazzo, João Sacramento, Alexander Mord- vintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. InInternational Conference on Machine Learning, 2023. 13
work page 2023
-
[59]
Johannes von Oswald, Eyvind Niklasson, Maximilian Schlegel, Seijin Kobayashi, Nicolas Zucchet, Nino Scherrer, Nolan Miller, Mark Sandler, Blaise Agüera Y . Arcas, Max Vladymy- rov, Razvan Pascanu, and João Sacramento. Uncovering mesa-optimization algorithms in transformers, 2024. URLhttps://arxiv.org/abs/2309.05858
-
[60]
Johannes von Oswald, Nino Scherrer, Seijin Kobayashi, Luca Versari, Songlin Yang, Maximilian Schlegel, Kaitlin Maile, Yanick Schimpf, Oliver Sieberling, Alexander Meulemans, Rif A. Saurous, Guillaume Lajoie, Charlotte Frenkel, Razvan Pascanu, Blaise Agüera y Arcas, and João Sacramento. MesaNet: Sequence modeling by locally optimal test-time training, 2025...
- [61]
-
[62]
RNNs are not transformers (yet): The key bottleneck on in-context retrieval, 2024
Kaiyue Wen, Xingyu Dang, and Kaifeng Lyu. RNNs are not transformers (yet): The key bottleneck on in-context retrieval, 2024. URLhttps://arxiv.org/abs/2402.18510
-
[63]
Gated Delta Networks: Improving Mamba2 with Delta Rule
Songlin Yang, Jan Kautz, and Ali Hatamizadeh. Gated Delta Networks: Improving Mamba2 with Delta Rule. October 2024. URLhttps://openreview.net/forum?id=r8H7xhYPwz
work page 2024
-
[64]
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated Linear Attention Transformers with Hardware-Efficient Training. InProceedings of the 41st Inter- national Conference on Machine Learning, pages 56501–56523. PMLR, July 2024. URL https://proceedings.mlr.press/v235/yang24ab.html
work page 2024
-
[65]
Parallelizing linear transformers with the delta rule over sequence length
Songlin Yang, Bailin Wang, Yu Zhang, Yikang Shen, and Yoon Kim. Parallelizing linear transformers with the delta rule over sequence length. In A. Globerson, L. Mackey, D. Bel- grave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 115491–115522. Curran Associates, Inc., 2024. doi: 10...
-
[66]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InAnnual Meeting of the Association for Computational Linguistics, 2019
work page 2019
-
[67]
Yu Zhang, Songlin Yang, Ruijie Zhu, Yue Zhang, Leyang Cui, Yiqiao Wang, Bolun Wang, Freda Shi, Bailin Wang, Wei Bi, Peng Zhou, and Guohong Fu. Gated slot attention for efficient linear-time sequence modeling.Advances in Neural In- formation Processing Systems, 37:116870–116898, December 2024. doi: 10.52202/ 079017-3710. URL https://proceedings.neurips.cc/...
work page 2024
-
[68]
Online convex programming and generalized infinitesimal gradient ascent
Martin Zinkevich. Online convex programming and generalized infinitesimal gradient ascent. InInternational Conference on Machine Learning, 2003. 14 Appendix Roadmap The appendix is organized to separate mechanism, implementation, theory, evaluation protocol, additional evidence, and background. Appendix A collects derivations and proof details for the Del...
work page 2003
-
[69]
Since βt ∈(0,1) , the power-mean inequality givesP i(kt)4 i ≤ P i(kt)2 i 2 = 1
Under ∥kt∥2 2 = 1, λmax =β 2 t P i(kt)4 i . Since βt ∈(0,1) , the power-mean inequality givesP i(kt)4 i ≤ P i(kt)2 i 2 = 1. The reported runs use the practical online step size η= 0.003 inside D= [0.5,2.0] K, with reproduc- tion details in Appendix F. Corollary A.2(Monotone descent under bounded box).Assume ∥kt∥2 2 = 1 , βt ∈(0,1) , and dt ∈ D= [d min, dm...
-
[70]
Under ∥kt∥2 = 1, nt = 1 and ∥st∥2 2 =P i k4 t,i; the Cauchy–Schwarz / power-mean inequality gives the displayed bound. Conditional algorithmic regret.Let D ⊂R K be a closed convex set containing the algorithmic iterates {dt}. We assume the online learner producing {dt} admits a sublinear regret bound against any fixed comparator inD: TX t=1 ht(dt)−h t(d) ...
-
[71]
Defining qt :=f t(St)/ft(St−1) on the non-degenerate set{u t ̸= 0}, qt = 1−β t⟨dt, st⟩ 2 ≥0,(20) and Equation (18) with nt = 1 gives qt = 1 + 2ht(dt). (When ut = 0 the ratio is 0/0; we interpret qt = 1sincef t(St) =f t(St−1) = 0, consistent withh t = 0.) Sinceq t ≥0, the AM–GM inequality gives TY t=1 qt ≤ 1 T TX t=1 qt T = 1 + 2 T TX t=1 ht(dt) T . By Equ...
-
[72]
Sublinear-regret online learning gives RT =O( √ T) (or O(logT) under additional curva- ture) soR T /T→0
-
[73]
single” averages FDA, SWDE, and SQuAD, while “repeated
In Theorem D.5, the Rayleigh-quotient inequality (Step 2) provides a constant lower bound |ht(D⋆)| ≥1/(2L) , so the per-step ratio ht(Dt)/ht(D⋆) approaches 1 as the meta-learner converges, driving each rt to zero. In Theorem D.7, the analogous role is played by the AM–GM step, which converts cumulative regret on the per-token surrogate into a contraction ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.